 密码密钥硬编码检查
密码密钥硬编码检查
1. 密钥的重要性
1.1. 看风
我们还是先说故事。话说2006年有一个柳云龙的电视连续剧《暗算》分为三部曲《听风》、《看风》、《捕风》。很有意思的是三个故事里都有个“风”字。你看过风吗?我没看到,只看见树叶飘动,才知道风来过。风,来无影,去无踪,无孔不入,又无处不在。三部曲分别对应:侦听、破译和谍报。故事描述了老一辈情报人员(一群与风打交道的人),与敌斗智斗勇的故事,信仰的力量让他们无所畏惧、勇往直前,看得人荡气回肠,催人泪下。
由于平时很少看电视,去年正在为一个算法发愁,偶然看到这个剧,感同身受,便一口气看完了,里面一些对加密算法逻辑的一些看法,还是给了当时的我很大的启发,让我完成了当时的算法,还特意发了微博纪念。个人比较喜欢《看风》破译密码这个章节,里面有句经典的台词:风是看不见的,破译密码就是看见了风,密码是兵器,是兵器中的暗器。
1.2. 保密通信模型
· 保密通信模型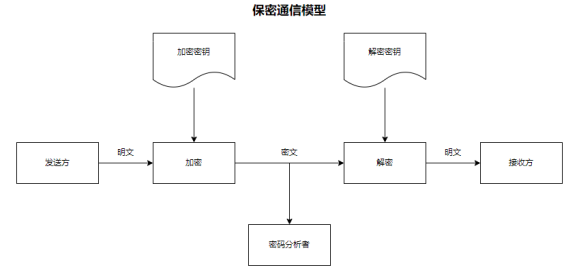
密码学有一个重要的产物——密钥。密钥作为信息在传播时用来加密的工具起着非常重要的作用。主流的六种密码技术,就是围绕密钥展开的:对称密码、非对称密码、单向散列函数、消息认证码、数字签名、伪随机数生成器。
1.3. 密钥的重要性
· 古典密码学(1949年之前)
数据的安全主要是基于算法的保密。
送你一首小诗:
我画蓝江水悠悠,
爱晚亭上枫叶愁。
秋月溶溶照佛寺,
香烟袅袅绕经楼。
如果不告诉你这是首藏头诗,你还真的很难猜到唐伯虎对秋香的表白:“我爱秋香”。 藏头诗就是加密算法的一种。
由于西方文字是由字母组成,字母又是有序的字符集。所以在对文字加密时,密码算法很容易想到采用:替代密码、置换密码或替代与置换密码的组合,来完成完成信息的加密。公元前1世纪古罗马的凯撒密码,就是对文字中的字母,采用它在字母表中之后的第k个字母来代换,从而变成密文。在解密时,反向移动k个字母进行还原。
这个时代将密码发展到巅峰的,要算二战时期德军用机械实现的转轮机(RotorMachine)ENIGMA密码,很多的谍战片都是围绕这个机器展开的。
这个时期的密码存在很多的问题:
· 不适合大规模生产
· 不适合较大的或者人员变动较大的组织
· 用户无法了解算法的安全性
奥古斯特·柯克霍夫在19世纪提出了密码学上的柯克霍夫原则(Kerckhoffs’s principle)由:即使密码系统的任何细节已为人悉知,只要密钥(key)未泄漏,它也应是安全的。 这个原则指导了以后的密码学算法的发展。
· 近代密码学(1949-1975)
数据的安全基于密钥,而不是算法的保密。
香农在20世纪40年代末发表的一系列论文,特别是1949年的《保密系统通信理论》,把密码学推向了基于信息论的科学轨道。
这阶段的发展主要是对称加密算法。对称加密是发送方使用某种公开的算法使用密钥对明文进行加密,接收方使用之前发送方给予的密钥对密文进行解密得到明文。近代密码发展中一个重要突破是“数据加密标准”(DES)的出现。
· 现代密码学(1976-)
公钥密码使得发送端和接收端无密钥传输的保密通信成为可能。
1976 年 Diffie 和 Hellman 的公钥密码的思想提出,标志着现代密码学的诞生。这是密码学发展史上具有里程碑意义的大事件,自此提出了许多种公钥密码体制 ,如基于分解大整数的困难性的密码体制——RSA 密码体制及其变种、基于离散对数问题的公钥密码体制。
1.4. 密钥泄露的危害
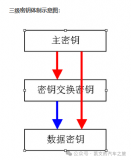
影响密码系统安全性的基本因素:密码算法复杂度、密钥机密性、密钥长度。其中密钥机密性与主要与密钥的管理相关。如何保护好密钥的安全就成了信息安全的非常重要的一个部分。
在现在的应用系统中,密码、密钥往往被作为一种访问密钥(access key)或凭证(Credentials),用于系统之间建立链接,避免了用户密码的明文传输。很多时候访问密钥等同于密码。
例如我们熟悉的GitHub的访问密钥。当我们获得Github某个库的地址访问密钥,就可以在Windows的凭证管理或本地Git的凭证管理里添加这个访问密钥,本地git和远端的访问库地址就建立了信任链接,不再需要每次都输入密码。
但密钥本地化,也会导致密钥分散在代码、配置文件中。一旦缺乏对密钥的统一管理, 就容易导致密钥泄露。员工不慎将密钥泄漏到开源网站导致重要数据丢失事件时有发生。
2018年某酒店集团共140G约5亿条个人信息遭泄露,被发现泄露的信息在境外黑市中售卖。究其原因,是该集团对员工的安全意识缺乏足够的教育培训,导致开发人员在无意识的情况下将公司测试平台的账号密码发到 GitHub上,使得黑客下载了整个数据。
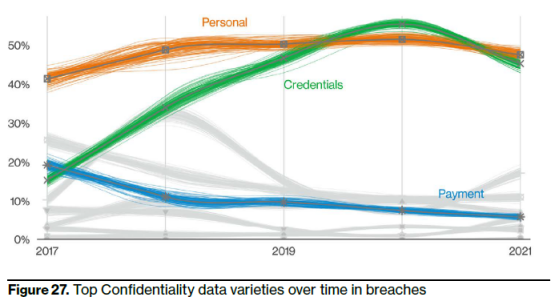
我们从Verizon(美国最大的有线通信和语音通信提供商),每年发布的《数据泄露调查报告(Data Breach Investigations Report(DBIR))》,来看下密码密钥在信息泄露中被黑客利用的情况。
·
《2020数据泄露调查报告(DBIR)》
使用偷窃的信用凭证、利用员工误发送、员工误配置是数据泄露的主要威胁。内部员工操作不规范、没有养成良好的工作行为习惯以及疏忽大意等,已成为多起严重网络安全事件发生的根本原因。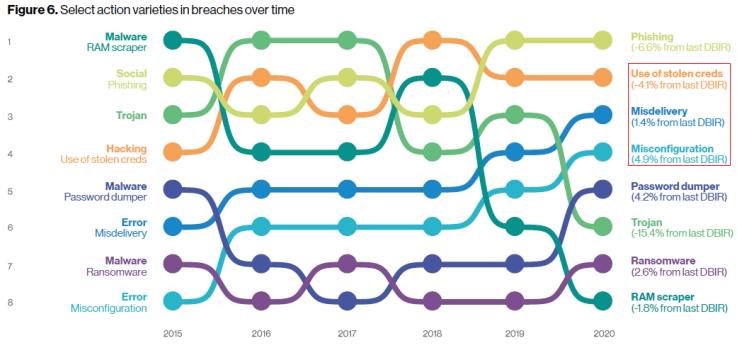
《2021数据泄露调查报告(DBIR)》
61%的数据泄露涉及凭证数据,凭证的泄露是信息泄露的主要途径,防止凭证泄露对信息保护有着重要的作用。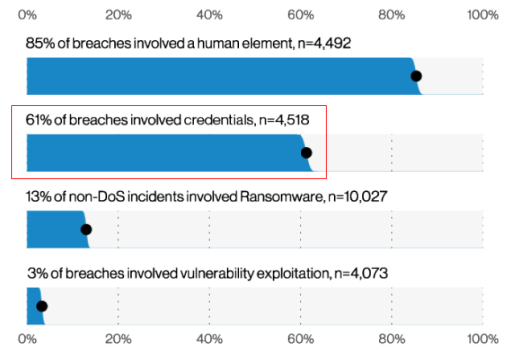
《2022数据泄露调查报告(DBIR)》
凭证是发起攻击的最重要的手段。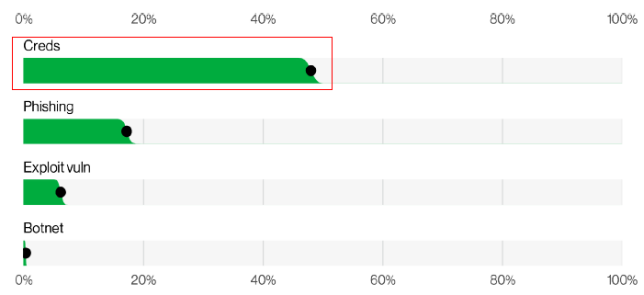
凭证和个人数据是黑客最喜欢获取的两类数据
报告指出:我们长期以来一直认为,凭证是犯罪分子最喜欢的数据类型,因为它们对于伪装成系统上的合法用户非常有用。就像谚语中披着羊皮的狼一样,它们的行为在攻击之前显得无害。
o
2. 密码密钥硬编码的检查
接下来我们看下如何防范密码密钥在带码中由于硬编码导致的泄露。
先来看些如何鉴别密码密钥。
2.1. 香农熵(Shannon entropy)
密钥的长度决定了密钥空间(keyspace),通常以位为单位。密钥空间越大,密钥被攻破的难度就越大。
密钥是由密钥空间的随机值构成。对于任意一个随机变量X,它的熵定义如下:
H(X) = - \\sum_{x=1}^nP(x_i)log_2[P(x_i)]∑ x =1n P (xi)log2[ P (xi)]
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
· P(x_i) P (x**i) : 指的是单个样本变量所属的变量种类的个数占据所有变量个数的比例。
举例 :数据data有六个值,分为别为:[a,b,c,a,b,a];
样本总个数是6,变量种类数3;分别为[a:3, b:2, c:1]
所以对应的pi分别为[a:1/2, b:1/3, c:1/6]
公式计算log以2为底数的pi的对数值,然后再乘以pi的负数,再计算其加和,得到的便是香农熵的值:1.4591479170272448。
/**
- Base on shannon entropy return bits of entropy represented in string.
- @param str input string
- @return entropy
/public * static double getShannonEntropy(String str**)** **{
** int num = **0;
** Map
** **// count char in string
** char cx**;
** for (int l = 0; l < str**.length();** ++ l ) **{
** cx = str**.charAt( l );
** if ( pi .containsKey( cx )) **{
** pi**.put( cx ,** pi**.get( cx )** + **1);
** } else **{
** pi**.put( cx ,** **1);
** **}
** num = num + **1;
** **}
** double entropy = **0.0;
** for (Map.Entry
** cx = entry**.getKey();
** double p = (double) entry**.getValue()** / num**;
** entropy = entropy + p ***** (Math.log( p ) / **Math.log(2));
** **}
** return **- entropy ;}
· 同等长度的字符串,通常密钥的熵值更高
密钥为避免彩虹攻击,在取值上更加的离散,会尽量采用不重复的字符。就像我们为了增加密码的复杂性,要求长度不小于8,必须包含大小写、特殊字符、以及数字一样的道理,所以密钥的熵值会比一般的文本要高的多。我们就是利用这点来识别字符串是否是密钥。
2.2. 工具的检查逻辑
对于密码密钥的硬编码检查可以采用静态分析工具来完成。工具的检查过程通常包含四个过程:输入文件准备、检查、过滤和报告输出。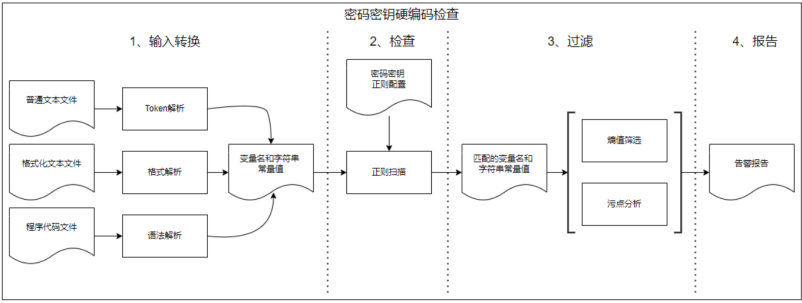
2.2.1. 输入文件转换
· 输入文件分类
我们需要检查的文本文件进行分类,通常包括以下几种类型:
o 程序语言:C、C++、Java、Python、Go、Js等;
o 有统一格式的文件:属性文件、yaml、csv、json、xml等;
o 文本文件:没有固定格式的文本文件。
分类的目的是为了更好的识别文件中的字符串常量,充分利用字符串常量的上下文关联,以便在分析中最大程度的减少误报。
· 输入文件转换
o 程序语言:通过各语言的语法解析器,解析成抽象语法树,提取语法树中的等于字符串的常量,以及对应的变量名;
o 有统一格式的文件:照格式转换成变量名和字符串常量值;
o 文本文件:采用token的方式分割成一个个的token,变成一个各的字符串常量。
2.2.2. 密码密钥检查
在我们得到大量的变量名和字符串常量后,主要通过正则表达式匹配的方式完成目标的筛选。
由于检查密码密钥的种类和类型不同,可以通过配置文件来提高检查能力的可扩展性。
· 检查配置选项主要包括以下内容:
| 信息 | 描述 | 选项 |
|---|---|---|
| 检查类型 | 可分为:变量名、字符串常量、或两个都检查 | 必选 |
| 密码密钥的类型 | 用于区分不同类型的密码密钥;同时用于告警时区分具体检测到的密码密钥类型 | 必选 |
| 正则表达式 | 主要设定匹配的长度,每个字符的可选类型 | 必选 |
| 熵值的阈值 | 用于精确的识别密码密钥的类型,降低误报 | 可选 |
例如:
· 检查硬编码的口令:检查变量名中包含:password、passwd、pwd的变量,且变量等于字符串常量;正则表达式可以设置成为:".*(password|passwd|pwd)$"。
· 检查GitHub的个人凭证:检查字符串常量;这个凭证是以"ghp_"开头的,跟随长度为36的字符串,且每个字符可以为数字和字母;正则表达式可以设置成为:“ghp_[0-9a-zA-Z]{36}”。
2.2.3. 密码密钥过滤
静态分析能很大程度上减少了人工审核的工作量,但由于检查模式的不确定性,也会带来不少的误报。误报会给用户在审核过程中带来很多的负面情绪,从而不愿继续使用工具。为了进一步降低误报,我们可以通过下面的方式来降低误报:
·
密码密钥熵值的计算
前面讨论过密码密钥的特点,可以通过检测密码密钥的信息熵的方式来降低误报。有些密码密钥设定了最低的阈值,但还是有很多密码密钥并未给出具体的阈值,这个就需要通过经验积累来设定,目前业界也有通过机器学习来完善这个阈值的设定。
·
·
污点分析
在代码中,对于口令的变量的取名上,很多并不会遵守可读性和可维护性来设定变量名,通过前面正则表达式的方式来查找硬编码密码的方式,会造成很多的漏报。这里还可以通过污点分析的方法,来推导出密码是否采用了硬编码。例如检查jdbc连接的密码参数,查看该参数是否为字符串常量。
·
2.2.4. 报告输出
将经过过滤后的结果,输出告警,给出可能泄露的文件名和变量或可能为密码密钥的常量字符串位置,便于人工的排查。
审核编辑:汤梓红
-
通信
+关注
关注
18文章
5969浏览量
135844 -
编码
+关注
关注
6文章
935浏览量
54759 -
密钥
+关注
关注
1文章
137浏览量
19739
发布评论请先 登录
相关推荐
艾体宝洞察 一文读懂最新密码存储方法,揭秘密码存储常见误区!
ESP是否可以接受ASCII十六进制的安全密钥来连接到AP,而不是密码?
鸿蒙开发:Universal Keystore Kit密钥管理服务 密钥派生介绍及算法规格
鸿蒙开发:Universal Keystore Kit密钥管理服务 密钥派生C、C++

鸿蒙开发:Universal Keystore Kit 密钥管理服务 密钥协商 C、C++
鸿蒙开发:Universal Keystore Kit 密钥管理服务 密钥协商ArkTS
鸿蒙开发:Universal Keystore Kit密钥管理服务 加密导入密钥C、C++
鸿蒙开发:Universal Keystore Kit 密钥管理服务 加密导入密钥 ArkTS

鸿蒙开发:Universal Keystore Kit密钥管理服务简介
abb机器人系统密钥在哪
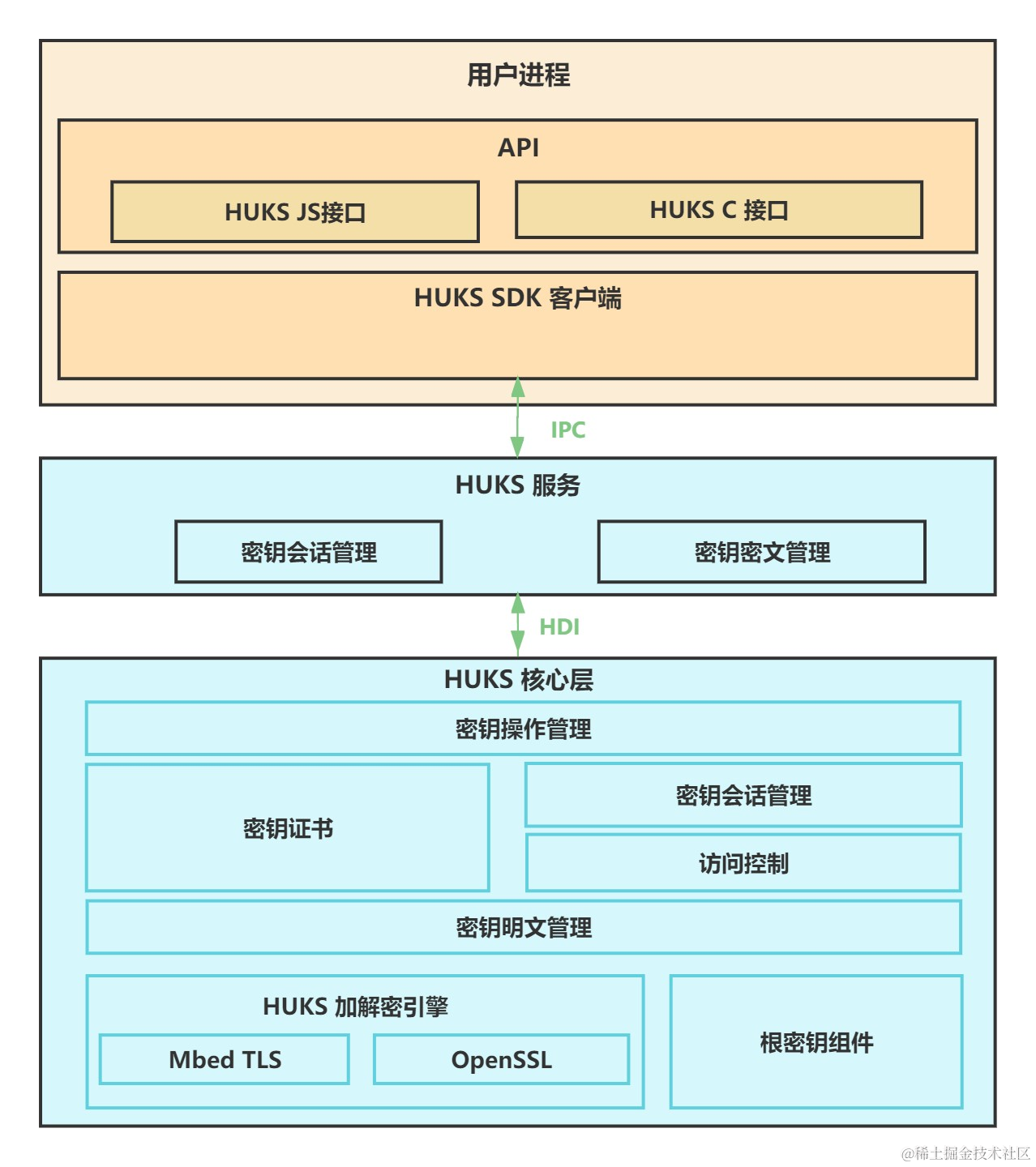
鸿蒙开发接口安全:【@ohos.security.huks (通用密钥库系统)】






 工商网监
工商网监
评论