 分布式数据库系统与物联网的相关性
分布式数据库系统与物联网的相关性
分布式数据库系统是将属于单个逻辑数据库的数据分发到两个或多个物理数据库的系统。除了这个简单的定义之外,关于数据何时、如何以及为什么分发,还有许多令人困惑的可能性。有些适用于边缘和/或雾计算,有些适用于雾和/或云计算,有些适用于边缘,雾和云计算的整个范围。
本文将介绍边缘、雾和云计算背景下分布式数据库系统的类型,解释“何时、如何以及为什么”数据是分布式的,以及为什么这些细节使某些分布式数据库系统适用于(或不适用)边缘、雾和云计算中的特定需求。
定义
维基百科的作者在定义分布式数据库时采取了集体尝试:“分布式数据库是存储设备并非全部连接到公共处理器的数据库。它可以存储在位于同一物理位置的多台计算机中;或者可能分散在互连的计算机网络上。与处理器紧密耦合并构成单一数据库系统的并行系统不同,分布式数据库系统由松散耦合的站点组成,这些站点不共享任何物理组件。该定义本身部分来自与美国商务部相关的电信科学研究所。
这个定义实际上相当狭窄。在“分布式数据库”的一般标题下,我至少会问到其他三个用例:高可用性,集群数据库和区块链。维基百科的定义,高可用性和集群都适用于物联网。此外,我认为分布式数据库的分片可以存在于同一台物理计算机上。使数据库分布式的原因是,各个分区由数据库系统的单独实例管理,而不是由这些分区的物理位置管理。第六节将对此进行详细介绍。
高可用性
要使数据库系统实现高可用性 (HA),它需要在单独的硬件实例中实时维护物理数据库的相同副本。通过维护,我的意思是保持副本与主副本的一致性。在这种情况下,(至少)有两个数据库副本,我们称之为主数据库和从数据库(有时称为副本)。应用于主数据库的操作(即插入、更新、删除操作)必须在从属数据库上复制,并且从站必须准备好随时将其角色更改为主数据库。这称为故障转移。主站和副本通常部署在不同的物理系统上,但在电信中,常见的 HA 设置是机箱内的多个板:主控制器板、备用控制器板和一些数量的线卡,每个线卡都为某种协议(BGP、OSPF 等)提供服务。在这里,主数据库由主控制器板上的进程维护。数据库系统将更改复制到备用控制器板上的从数据库,该从属数据库具有相同的进程,等待在主控制器板发生故障(或只是在热插拔设置中被移除)时接管处理。在物联网中,高可用性对于任务关键型工业系统是可取的,以保持网关的可用性,以及在云中,以确保即使在面对硬件故障时也可以继续执行实时分析。
集群数据库
群集数据库是在整个数据库有多个保持同步的物理副本的数据库。与 HA 的不同之处在于,数据库的任何物理实例都可以修改,并且会将其修改复制到集群中的其他数据库实例。这也称为主-主配置,与 HA 的主-从配置相反。这就是数据库集群实现之间的相似之处结束的地方。从广义上讲,有两种实现模型:ACID和最终一致性。在 ACID 实现中,修改在两阶段提交协议中同步复制,以确保一旦提交,更改就会立即反映在数据库的每个物理实例中。换句话说,所有数据库实例始终是一致的。此体系结构消除了发生冲突的可能性(或者,更确切地说,在事务成功提交到群集之前解决冲突)。使用最终一致性时,可能会在原始节点将更改提交到数据库很久之后异步复制更改。这意味着某种协调过程,以解决由两个或多个节点发起的冲突更改。使用最终一致性,必须编写应用程序以应对它们所附加到的数据库的物理实例中存在过时数据的可能性。例如,考虑一个全球在线书商。库存中可能有一本特定书籍的副本;纽约和悉尼的买家都会看到这本书有货,两者都可以把书放在购物车里结账。系统将不得不弄清楚谁真正拿到了这本书,谁的订单被延期了。用户已经接受了这一点。但是,这种模式永远不适用于需要验证用户是否订阅了某种服务或拥有足够资金的蜂窝电话网络。这种类型的系统需要一致的数据库视图。由于 ACID 实现所需的同步复制的性质,水平可伸缩性受到限制,但实现非常简单(无需解决冲突)。最终一致性实现的可伸缩性相当高,但复杂性也很高。集群实现在物联网中比比皆是。例如,可以群集 IoT 网关以提高可伸缩性和可靠性。参见图1。每个网关群集中的节点数适中,因此即时一致性和最终一致性模型都适用。群集可以处理来自边缘设备的流量,而不是单个网关所能处理的流量,并且可靠性/可用性得到提高(即时一致性模型的可伸缩性固有限制不会在小型群集中发挥作用)。
区块链
术语“分布式数据库”通常与区块链技术相关联(比特币是最知名的)。它与“分布式账本”同义使用,后者更合适(在作者看来)。我在区块链技术的背景下使用术语分布式数据库的问题是,“分布式数据库”意味着分布式数据库管理系统。但区块链中很少涉及数据库管理系统。不是要详细阐述这一点,但重要的是要区分数据库和数据库管理系统。数据库只是数据的集合,这些数据可能是分布式的,也可能是不分布的。数据库管理系统是管理数据库的软件。区块链实际上是一个分布式数据库。但是,如前所述,在创建/维护区块链分布式账本时,很少涉及数据库管理系统。
分区数据库
维基百科定义“。..存储在多台计算机中,位于同一物理位置。..”是俗称的数据库分片。分片与 HA 和集群分布式数据库之间的主要区别在于,每个物理数据库实例(分片)仅包含所有数据的一小部分。所有分片共同表示单个逻辑数据库,该数据库在许多物理分片中体现出来。我同意维基百科的定义,因为分片不需要存储在多台计算机中即可获得分片的好处。从逻辑上讲,目的是相同的:可伸缩性。分片是分布在各个服务器上,还是在单个服务器上进行分区以利用多个 CPU 或 CPU 内核,这并不重要。在所有情况下,处理都是并行的。分片的物理分布方式是一个不重要的工件。例如,在我们自2012年以来进行的STAC-M3发布的基准测试中,我们利用了具有24个内核的单个服务器,创建了72个分片,我们使用了4到6个服务器,每个服务器有16到22个内核,创建了64到128个分片。在所有情况下,目标都是使 I/O 通道饱和,以便将数据放入 CPU 内核进行处理。虽然STAC-M3是资本市场(刻度数据库)基准,但这些原则同样适用于物联网的大数据分析。物联网数据绝大多数是时间序列数据(例如传感器测量值),就像刻度数据库是时间序列数据一样。
对数据库进行分片意味着支持分布式查询处理。每个分片都由其自己的数据库服务器实例管理。由于每个分片/服务器都表示整个逻辑数据库的一部分,因此任何分片返回的查询结果都可能只是部分结果集,需要与所有其他分片/服务器的部分结果集合并,然后才作为完整的结果集呈现给客户端应用程序。如果数据以最佳方式在分片之间分布,则可以在单个分片上找到给定查询的所有数据,并且查询可以分发到管理该分片的特定服务器实例。通常,必须支持这两种方法。例如,考虑一个跨越多个园区的大型智能建筑物联网部署,每个园区都有多栋建筑。我们可能会选择在多个物理数据库中分发有关每个园区的(分片)信息。如果我们想计算特定建筑物的某些指标(例如,15分钟窗口中的功耗),我们只需要查询包含该建筑物数据的分片。但是,如果我们想为多个建筑物和/或跨校园计算相同的指标,那么我们需要将该查询分发到许多分片/服务器,这就是并行性发挥作用的地方。每个服务器实例都与所有其他服务器实例并行处理其部分问题。
数据库分片还支持垂直可扩展性(即能够存储 10 或 100 的 TB、PB 及以上)。要创建单个 100 TB 的逻辑数据库,我可以创建 50 个 2 TB 物理数据库的实例。分布式数据库系统通常支持“弹性”可伸缩性,允许我添加分片,这也可能意味着向分布式系统添加服务器,以便系统在垂直和水平维度上都是可伸缩的。垂直和水平可扩展性对于生成大量数据的大型物联网系统至关重要。您需要纵向可扩展性来处理不断增长的数据量,并且需要水平可扩展性来保持及时处理/分析数据的能力,因为数据从 1TB 增长到 100TB,再到 PB 级甚至更高。
物联网复制
虽然严格来说,不是分布式数据库实现,但如果我们不谈论物联网系统中的数据分布,我们将是失职的。物联网生态系统通常由“边缘”,“网关”和“云”组成,数据库存在于所有位置。物联网数据最初是在边缘生成的,需要从那里分发到网关,从网关分发到云。边缘数据通常用于实时控制某些“事物”,例如在工业物联网系统中打开或关闭螺线管。在企业层面,在许多情况下(如果不是大多数的话),物联网系统的目标之一是从数据中获取和提取价值。通常,这意味着数据的某种“货币化”。这可以以提高效率或减少维护成本或工业环境中的停机时间的形式出现,或者与客户进行更智能的互动,从而更有效地从钱包中提取资金。
物联网系统的数据分发意味着将数据从边缘通过一个或多个网关移动到私有云或公共云。这种数据移动充满了它自己的问题:
连接
边缘设备可以处于脱机状态,无论是出于设计还是由于通信基础结构中的故障。例如,电池供电的边缘设备在设计上处于脱机状态,并且仅按计划连接到网关。或者,它们可以是进出网关或蜂窝塔范围的移动设备。或者,通信链路可以简单地断开。在任何情况下,设备都必须具有将数据排队以供以后传输的智能。
安全
安全性是这十年中物联网系统的首要考虑因素,并且很可能在未来十年中一直存在。传输中的数据需要得到保护。这可以像使用 SSL/TLS 一样简单。
带宽
边缘设备可用的通信通道的带宽可能非常有限。例如,低功耗蓝牙 (BLE) 为 1 或 2 兆位/秒 (Mbit/s)。Zigbee 的范围为 20 到 250 千位每秒 (kbit/s)。这与10 Mbit/s时最慢的以太网相比。为了最大化可用带宽,应在将数据放入通信通道之前对其进行压缩。
范围
物联网系统设计人员需要考虑的一些问题:是否会将所有数据从边缘推送到云端?还是某些数据仅在边缘有用?数据是在传输之前聚合,还是仅传输原始粒度数据?
在 eXtremeDB 中,我们已经在主动复制结构™中预见并解决了这些问题。
总之,术语分布式数据库包括三种不同的数据库系统安排,用于三个不同的目的。高可用性数据库系统将 master 数据库分发给一个或多个副本,其明确目的是在发生故障时保持系统的可用性。集群数据库系统分发数据库以实现大规模/全局可伸缩性(最终一致性)或用于在相对较少的节点(ACID)之间进行协作计算。分片将逻辑数据库分区为多个分片,以促进并行处理和水平可扩展性。所有功能都是部署可扩展且可靠的物联网系统不可或缺的一部分。
这些分布式数据库机制通常结合使用。再次参考上面的图 1,我们看到网关群集,群集中的每个节点都聚合来自一定数量的设备的数据。如果群集节点发生故障,则其所服务的设备可以连接到群集中的另一个网关并维护操作。在服务器级别,描述了一个分片数据库,每个分片从其中一个网关集群接收数据。分片共同表示单个逻辑数据库。每个分片由一个主/副本 HA 对组成。这是可取的,因为如果没有 HA,如果任何分片发生故障,逻辑数据库的完整性就会受到损害。
审核编辑:郭婷
-
云计算
+关注
关注
39文章
7840浏览量
137573 -
物联网
+关注
关注
2910文章
44781浏览量
374842 -
数据库
+关注
关注
7文章
3827浏览量
64527
发布评论请先 登录
相关推荐
基于ptp的分布式系统设计
PingCAP推出TiDB开源分布式数据库
分布式云化数据库的优缺点分析
软件系统数据库的分库分表设计
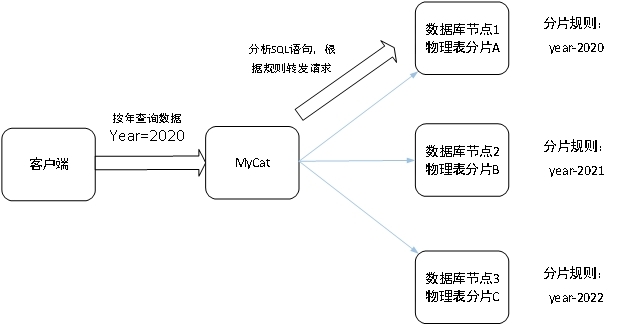
恒讯科技分析:跨境电商网站有哪些数据库系统是推荐使用的?
基于英特尔至强6能效核处理器优化原生分布式数据库OceanBase
小米试点业务系统上线OceanBase,数据库性能飞跃新高度
小米携手OceanBase实现数据库升级
鸿蒙开发接口数据管理:【@ohos.data.distributedData (分布式数据管理)】


鸿蒙HarmonyOS开发实例:【分布式关系型数据库】






 工商网监
工商网监
评论