 MLPerf:边缘AI推理的新行业基准
MLPerf:边缘AI推理的新行业基准
这些数字重要吗?它们中的大多数都是在实验室类型的环境中生产的,其中理想的条件和工作负载允许被测设备(SUT)产生用于营销目的的最高分数。另一方面,大多数工程师可能不太关心这些理论可能性。他们更关心的是技术如何影响其推理设备的准确性、吞吐量和/或延迟。
将计算元素与特定工作负载进行比较的行业标准基准测试更有用。例如,图像分类工程师可以确定满足其性能要求的多个选项,然后根据功耗、成本等对其进行缩减。语音识别设计人员可以使用基准测试结果来分析各种处理器和内存组合,然后决定是在本地还是在云中合成语音。
但是,AI和ML模型,开发框架和工具的快速引入使这种比较复杂化。如图 1 所示,AI 技术堆栈中越来越多的选项也意味着可用于判断推理性能的排列呈指数级增长。这是在考虑模型和算法可以针对给定系统架构进行优化的所有方法之前。

图 1.AI开发堆栈中越来越多的选项使行业标准基准测试变得复杂。
毋庸置疑,制定这样一个全面的基准超出了大多数公司的能力或愿望。即使有人能够完成这一壮举,工程界真的会接受它作为“标准基准”吗?
更广泛地说,在过去几年中,工业界和学术界已经开发了几个推理基准,但他们倾向于关注新兴人工智能市场的更多利基领域。一些例子包括EEMBC用于嵌入式图像分类和对象检测的MLMark,苏黎世联邦理工学院的AI基准测试,针对Android智能手机上的计算机视觉,以及哈佛的Fathom基准测试,强调各种神经网络的吞吐量,但不是准确性。
对 AI 推理格局的更完整评估可以在 MLPerf 最近发布的推理 v0.5 基准测试中找到。MLPerf 推理是社区开发的测试套件,可用于测量 AI 硬件、软件、系统和服务的推理性能。这是来自30多家公司的200多名工程师合作的结果。
正如您对任何基准测试所期望的那样,MLPerf 推理定义了一套标准化工作负载,这些工作负载被组织成图像分类、对象检测和机器翻译用例的“任务”。每个任务都由与正在执行的功能相关的 AI 模型和数据集组成,其中图像分类任务支持 ResNet-50 和 MobileNet-v1 模型,对象检测任务利用具有 ResNet34 或 MobileNet-v1 主干的 SSD 模型,以及使用 GNMT 模型的机器转换任务。
除了这些任务之外,MLPerf 推理开始偏离传统基准测试的规范。由于准确性、延迟、吞吐量和成本的重要性在不同用例中具有不同的权重,因此 MLPerf 推理通过在移动设备、自动驾驶汽车、机器人和云这四个关键应用领域中根据质量目标对推理性能进行分级来权衡。
为了在尽可能接近在这些应用领域中运行的真实系统的上下文中有效地对任务进行分级,MLPerf 推理引入了一个负载生成器工具,该工具根据四种不同的方案生成查询流量:
样本大小为 1 的连续单流查询,在移动设备中很常见
连续的多流查询,每个流有多个样本,就像在延迟至关重要的自动驾驶汽车中发现的那样
请求随机到达的服务器查询,例如在延迟也很重要的 Web 服务中
执行批处理且吞吐量是一个突出考虑因素的脱机查询
负载生成器在测试准确性和吞吐量(性能)的模式下提供这些方案。图 2 描述了 SUT 如何从负载生成器接收请求,相应地将数据集中的样本加载到内存中,运行基准测试并将结果返回到负载生成器。然后,准确性脚本将验证结果。
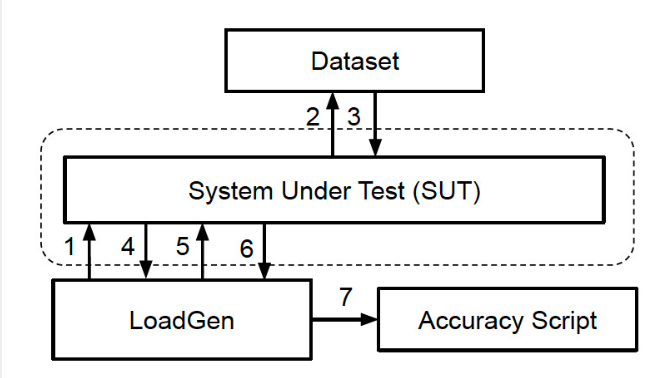
图 2. MLPerf 推理基准测试依赖于负载生成器,该负载生成器根据许多实际方案查询被测系统 (SUT)。
作为基准测试的一部分,每个 SUT 必须执行最少数量的查询,以确保统计置信度。
提高灵活性
如前所述,人工智能技术市场中使用的各种框架和工具是任何推理基准测试的关键挑战。前面提到的另一个考虑因素是调整模型和算法,以从AI推理系统中挤出最高的准确性,吞吐量或最低延迟。就后者而言,量化和图像重塑等技术现在是常见的做法。
MLPerf 推理是一种语义级基准测试,这意味着,虽然基准测试提供了特定的工作负载(或一组工作负载)以及执行它的一般规则,但实际实现取决于执行基准测试的公司。公司可以优化提供的参考模型,使用他们想要的工具链,并在他们选择的硬件目标上运行基准测试,只要它们保持在特定的指导方针之内。
但是,重要的是要注意,这并不意味着提交公司可以对MLPerf模型或数据集采取任何和所有自由,并且仍然有资格获得主要基准。MLPerf 推理基准分为两个部分 - 封闭式和开放式 - 封闭式部门对可以使用哪些类型的优化技术以及其他禁止的优化技术有更严格的要求。
要获得封闭分区的资格,提交者必须使用提供的模型和数据集,但允许量化。为了确保兼容性,封闭部门的参赛者不能使用重新训练或修剪的模型,也不能使用缓存或已调整为基准或数据集感知的网络。
另一方面,开放式划分旨在促进AI模型和算法的创新。仍需要向开放分区提交以执行相同的任务,但可以更改模型类型、重新训练和修剪其模型、使用缓存等。
尽管封闭式划分可能听起来很严格,但超过 150 个条目成功获得了 MLPerf 推理 v0.5 发布资格。图3和图4展示了参赛者使用的AI技术堆栈的多样性,这些堆栈几乎涵盖了从ONNX和PyTorch到TensorFlow,OpenVINO和Arm NN的各种处理器架构和软件框架。
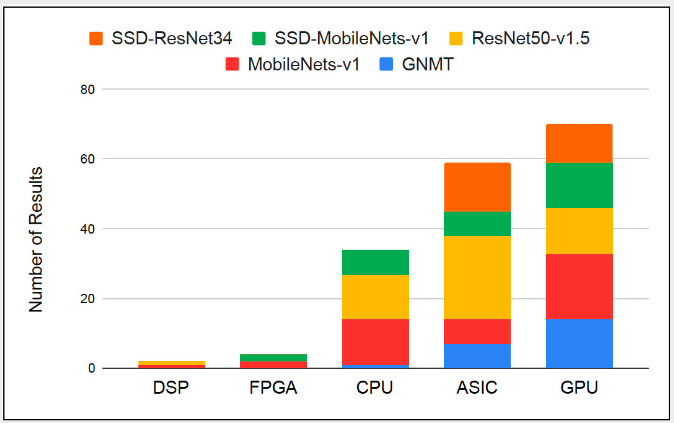
图 3.数字信号处理器、FPGA、CPU、ASIC 和 GPU 都成功完成了 MLPerf 推理封闭式除法要求。
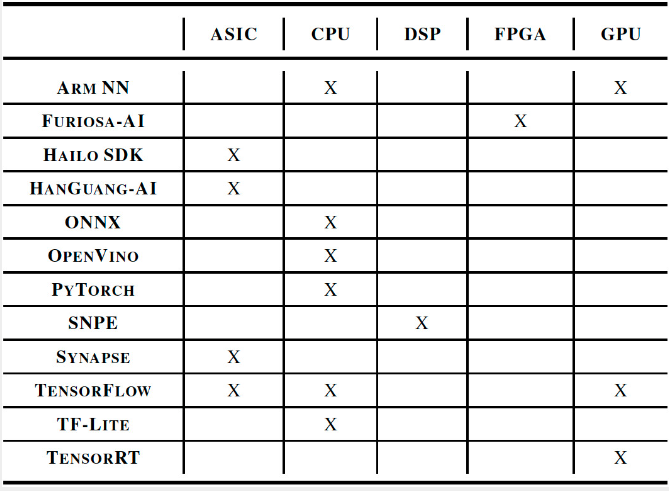
图 4. 人工智能软件开发框架,如 ONNX、毕拓、张量流、OpenVINO、Arm NN 等,被用于开发符合封闭分区基准测试的 MLPerf 推理系统。
消除评估中的猜测
虽然 MLPerf 推理的初始版本包含一组有限的模型和用例,但基准测试套件是以模块化、可扩展的方式构建的。这将使MLPerf能够随着技术和行业的发展而扩展任务,模型和应用领域,并且组织已经计划这样做。
最新的AI推理基准显然是目前可用的最接近真实世界AI推理性能的衡量标准。但随着它的成熟并吸引更多的提交,它也将成为成功部署的技术堆栈的晴雨表,以及新实施的试验场。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19461浏览量
231423 -
AI
+关注
关注
87文章
31845浏览量
270677 -
人工智能
+关注
关注
1797文章
47867浏览量
240882
发布评论请先 登录
相关推荐
AI赋能边缘网关:开启智能时代的新蓝海

生成式AI推理技术、市场与未来

新品| LLM630 Compute Kit,AI 大语言模型推理开发平台

汉威科技集团推出Ai200边缘计算网关,引领智慧监测新潮流
MLCommons推出AI基准测试0.5版
浪潮信息AS13000G7荣获MLPerf™ AI存储基准测试五项性能全球第一

智能边缘放大招!英特尔举办2024网络与边缘计算行业大会,边缘AI创新助力多元化应用

如何基于OrangePi AIpro开发AI推理应用

ai边缘盒子有哪些用途?ai视频分析边缘计算盒子详解

边缘侧AI芯片提供商超星未来完成数亿元 Pre-B轮融资
开发者手机 AI - 目标识别 demo
UL Procyon AI 发布图像生成基准测试,基于Stable Diffusion
基于EdgeX+OpenVINO™的边缘智能融合网关YiFUSION实战





 工商网监
工商网监
评论