 知识图谱——技术与行业应用
知识图谱——技术与行业应用

从一开始的Google搜索,到现在的聊天机器人、大数据风控、证券投资、智能医疗、自适应教育、推荐系统,无一不跟知识图谱相关。
随着移动互联网的发展,万物互联成为了可能,这种互联所产生的数据也在爆发式地增长,而且这些数据恰好可以作为分析关系的有效原料。如果说以往的智能分析专注在每一个个体上,在移动互联网时代则除了个体,这种个体之间的关系也必然成为我们需要深入分析的很重要一部分。 在一项任务中,只要有关系分析的需求,知识图谱就“有可能”派的上用场。
知识图谱的表示
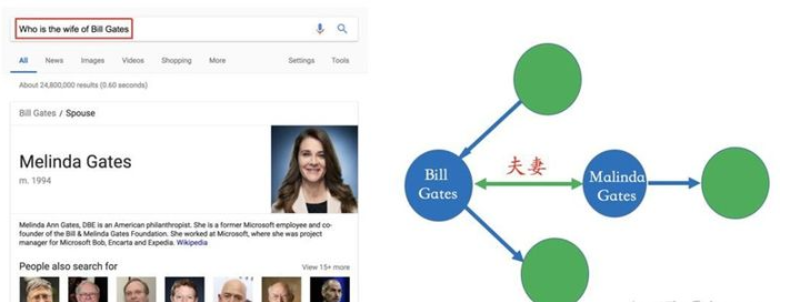
知识图谱应用的前提是已经构建好了知识图谱,也可以把它认为是一个知识库。这也是为什么它可以用来回答一些搜索相关问题的原因,比如在Google搜索引擎里输入“Who is the wife of Bill Gates?”,我们直接可以得到答案-“Melinda Gates”。这是因为我们在系统层面上已经创建好了一个包含“Bill Gates”和“Melinda Gates”的实体以及他俩之间关系的知识库。所以,当我们执行搜索的时候,就可以通过关键词提取("Bill Gates", "Melinda Gates", "wife")以及知识库上的匹配可以直接获得最终的答案。这种搜索方式跟传统的搜索引擎是不一样的,一个传统的搜索引擎它返回的是网页、而不是最终的答案,所以就多了一层用户自己筛选并过滤信息的过程。
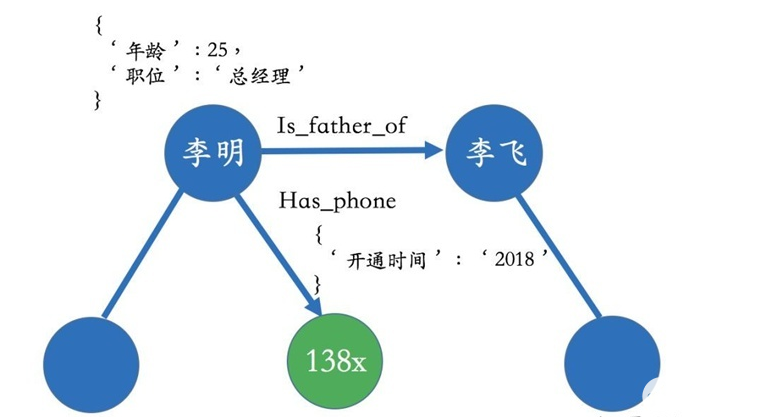
在现实世界中,实体和关系也会拥有各自的属性,比如人可以有“姓名”和“年龄”。当一个知识图谱拥有属性时,我们可以用属性图(Property Graph)来表示。下面的图表示一个简单的属性图。李明和李飞是父子关系,并且李明拥有一个138开头的电话号,这个电话号开通时间是2018年,其中2018年就可以作为关系的属性。类似的,李明本人也带有一些属性值比如年龄为25岁、职位是总经理等。
这种属性图的表达很贴近现实生活中的场景,也可以很好地描述业务中所包含的逻辑。除了属性图,知识图谱也可以用RDF来表示,它是由很多的三元组(Triples)来组成。RDF在设计上的主要特点是易于发布和分享数据,但不支持实体或关系拥有属性,如果非要加上属性,则在设计上需要做一些修改。目前来看,RDF主要还是用于学术的场景,在工业界我们更多的还是采用图数据库(比如用来存储属性图)的方式。感兴趣的读者可以参考RDF的相关文献,在文本里不多做解释。
知识抽取
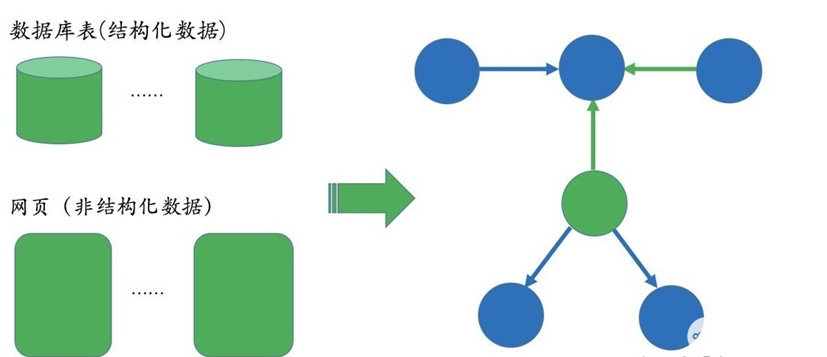
知识图谱的构建是后续应用的基础,而且构建的前提是需要把数据从不同的数据源中抽取出来。对于垂直领域的知识图谱来说,它们的数据源主要来自两种渠道:一种是业务本身的数据,这部分数据通常包含在公司内的数据库表并以结构化的方式存储;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在所以是非结构化的数据。
前者一般只需要简单预处理即可以作为后续AI系统的输入,但后者一般需要借助于自然语言处理等技术来提取出结构化信息。比如在上面的搜索例子里,Bill Gates和Malinda Gate的关系就可以从非结构化数据中提炼出来,比如维基百科等数据源。
信息抽取的难点在于处理非结构化数据。在下面的图中,我们给出了一个实例。左边是一段非结构化的英文文本,右边是从这些文本中抽取出来的实体和关系。在构建类似的图谱过程当中,主要涉及以下几个方面的自然语言处理技术:
a. 实体命名识别(Name Entity Recognition)
b. 关系抽取(Relation Extraction)
c. 实体统一(Entity Resolution)
d. 指代消解(Coreference Resolution)
知识图谱的存储
知识图谱主要有两种存储方式:一种是基于RDF的存储;另一种是基于图数据库的存储。它们之间的区别如下图所示。RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上。其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。

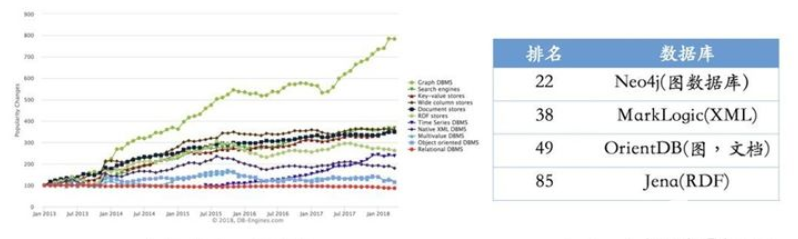
根据最新的统计(2018年上半年),图数据库仍然是增长最快的存储系统。相反,关系型数据库的增长基本保持在一个稳定的水平。同时,我们也列出了常用的图数据库系统以及他们最新使用情况的排名。 其中Neo4j系统目前仍是使用率最高的图数据库,它拥有活跃的社区,而且系统本身的查询效率高,但唯一的不足就是不支持准分布式。相反,OrientDB和JanusGraph(原Titan)支持分布式,但这些系统相对较新,社区不如Neo4j活跃,这也就意味着使用过程当中不可避免地会遇到一些刺手的问题。如果选择使用RDF的存储系统,Jena或许一个比较不错的选择。
知识图谱在其他行业中的应用
除了金融领域,知识图谱的应用可以涉及到很多其他的行业,包括医疗、教育、证券投资、推荐等等。其实,只要有关系存在,则有知识图谱可发挥价值的地方。 在这里简单举几个垂直行业中的应用。
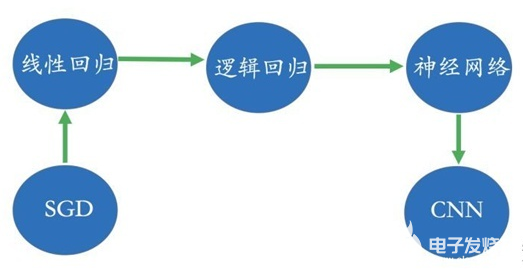
比如对于教育行业,我们经常谈论个性化教育、因材施教的理念。其核心在于理解学生当前的知识体系,而且这种知识体系依赖于我们所获取到的数据比如交互数据、评测数据、互动数据等等。为了分析学习路径以及知识结构,我们则需要针对于一个领域的概念知识图谱,简单来讲就是概念拓扑结构。在下面的图中,我们给出了一个非常简单的概念图谱:比如为了学习逻辑回归则需要先理解线性回归;为了学习CNN,得对神经网络有所理解等等。所有对学生的评测、互动分析都离不开概念图谱这个底层的数据。
在证券领域,我们经常会关心比如“一个事件发生了,对哪些公司产生什么样的影响?” 比如有一个负面消息是关于公司1的高管,而且我们知道公司1和公司2有种很密切的合作关系,公司2有个主营产品是由公司3提供的原料基础上做出来的。
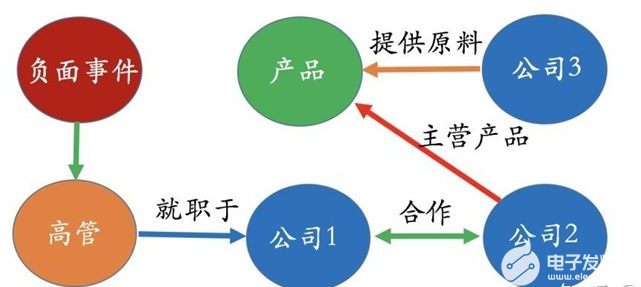
其实有了这样的一个知识图谱,我们很容易回答哪些公司有可能会被这次的负面事件所影响。当然,仅仅是“有可能”,具体会不会有强相关性必须由数据来验证。所以在这里,知识图谱的好处就是把我们所需要关注的范围很快给我们圈定。接下来的问题会更复杂一些,比如既然我们知道公司3有可能被这次事件所影响,那具体影响程度有多大? 对于这个问题,光靠知识图谱是很难回答的,必须要有一个影响模型、以及需要一些历史数据才能在知识图谱中做进一步推理以及计算。
实践上的几点建议
首先,知识图谱是一个比较新的工具,它的主要作用还是在于分析关系,尤其是深度的关系。所以在业务上,首先要确保它的必要性,其实很多问题可以用非知识图谱的方式来解决。
知识图谱领域一个最重要的话题是知识的推理。 而且知识的推理是走向强人工智能的必经之路。但很遗憾的,目前很多语义网络的角度讨论的推理技术(比如基于深度学习,概率统计)很难在实际的垂直应用中落地。其实目前最有效的方式还是基于一些规则的方法论,除非我们有非常庞大的数据集。
最后,还是要强调一点,知识图谱工程本身还是业务为重心,以数据为中心。不要低估业务和数据的重要性。
总之知识图谱是一个既充满挑战而且非常有趣的领域。只要有正确的应用场景,对于知识图谱所能发挥的价值还是可以期待的。我相信在未来不到2,3年时间里,知识图谱技术会普及到各个领域当中。
审核编辑 黄昊宇
-
数据库
+关注
关注
7文章
4092浏览量
68656 -
知识图谱
+关注
关注
2文章
132浏览量
8368
发布评论请先 登录
万里红入围嘶吼2026网络安全产业图谱
行业洞察篇__数字孪生IOC的“智能体”时刻:智慧城市公共服务的演进逻辑
上海3月26-28日《EMC设计整改与仿真应用》公开课安排来袭!

实力认证!行云创新入围《AI 中国生态图谱 2025》大模型开放平台板块

2026年度《EMC设计整改与仿真应用》公开课安排来袭!

润和软件入选大模型一体机产业图谱

华为联合发布宜兴“天机镜”大模型知识图谱
云知声荣获2025人工智能治理示范案例
光伏组件IV曲线测试仪:解锁光伏组件性能的“能量图谱仪”

AI与工业互联网的发展趋势怎么样
【「DeepSeek 核心技术揭秘」阅读体验】书籍介绍+第一章读后心得
中软国际入选中国信通院AI Agent智能体产业图谱1.0
造物数科亮相华为开发者大会2025 | 技术创新与数字服务,加速电子电路产业数智化转型




评论