 GAT模型如何来编码依存关系
GAT模型如何来编码依存关系
本文贡献有如下两点:
提出了一个面向方面的树结构,通过重塑和修剪普通的依存树来关注目标方面。
提出了一个新的GAT模型来编码依存关系,建立方面和意见词之间的联系。
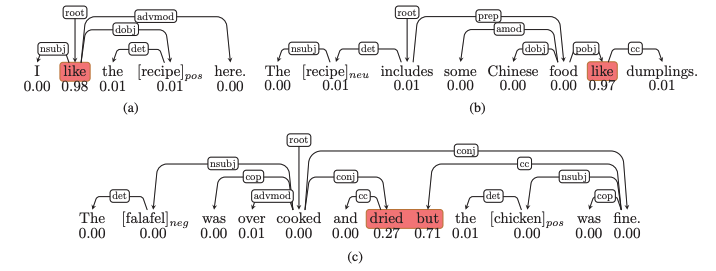
餐厅评论中的三个例子来说明 ABSA 中方面aspect、注意力和句法之间的关系。Labeled edges表示依存关系,每个单词下的分数表示由LSTM分配注意力权重。具有高注意力权重的词在「红色框」中突出显示,括号中的词是目标方面target aspect,后面是它们的情感标签。
面向方面的树的构建
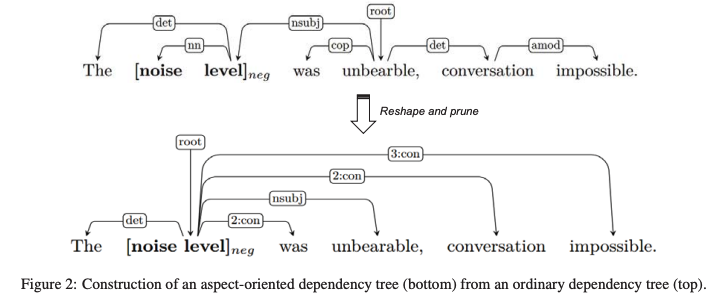
输入:原来的解析结果以及句子和方面。(原文有伪代码)
「第一步」 将目标方面放在根节点
「第二步」 我们将与方面有直接连接的节点设置为子节点,保留原始的依存关系
「第三步」 舍弃了其他的依存关系,取而代之的是一个从aspect到每个对应节点的虚拟关系n:con,其中n表示两个节点之间的距离。
注意 如果句子包含多个方面,我们为每个方面构建一个唯一的树。
根据是前人研究证明只关注在语法上接近目标方面的一小部分上下文词就足够了。好处是每个方面都有自己的依存树,可以减少不相关节点和关系的影响,同时这种统一的树结构不仅使模型专注于方面和情感词之间的联系,而且在训练过程中便于批量操作和并行操作。
R-GAT
为了对上述树进行编码,在GAT的基础上提出了一个新的R-GAT:relation graph attention network
GAT实现的是:
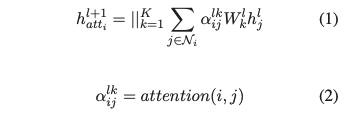
每个结点只对邻居结点进行注意力计算权重。这个得到的是。注意 表明一共使用了个做转换矩阵,最后将它们得到的结果拼接到一起。
作者认为没有考虑到和相邻接点的依存关系是存在不同的,不可以用同样方法去计算。因此引入了考虑不同的依存关系的R-GAT来补充信息。大致的思想相同,只是对于(1)中的有考虑进新的信息,也就是不同的依存关系。
「R-GAT」:
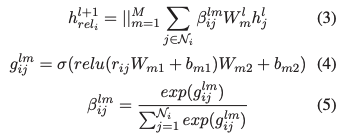 作者将各种依存关系映射到嵌入中,结点i和结点j之间的就是
作者将各种依存关系映射到嵌入中,结点i和结点j之间的就是
也就是先将依存关系经过两层线性层,然后对一个结点的所有边的结果归一化,变成对应的系数。
整个网络结构
结构很简单如下:
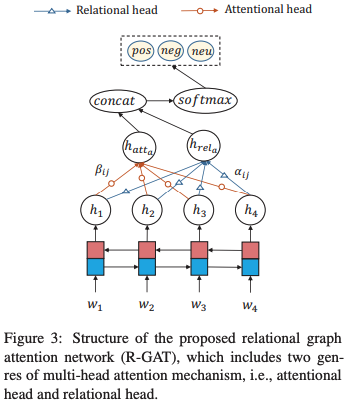
具体来说首先需要把句子的依存分析结果通过变换得到面向方面的数,这个结果将参与后续的图编码。
「第一步」,将句子的词嵌入经过BiLSTM编码得到,利用另一个BiLSTM编码方面词作为根节点嵌入的初始化。
「第二步」,利用GAT和R-GAT分别去处理h,得到和,注意相当于只用处理一个根节点。将得到的结果拼接到一起,再经过一个线性层就是该方面词的表达。
「第三步」,softmax分类得到方面词预测结果。
Loss Function
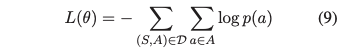
实验和分析
不同方法在三个数据集上的实验: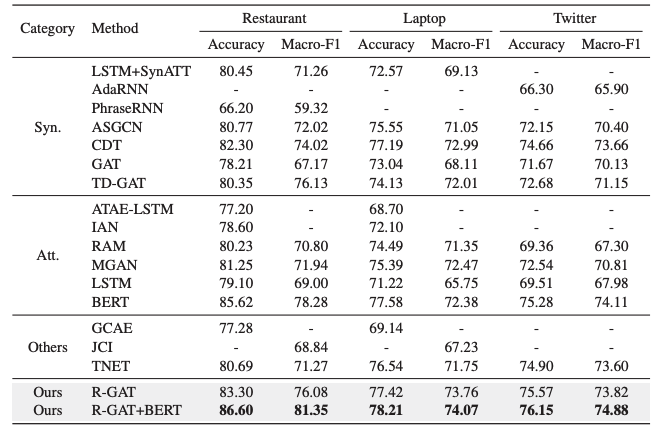
多方面分析结果,表明距离较近的方面往往导致准确度得分较低: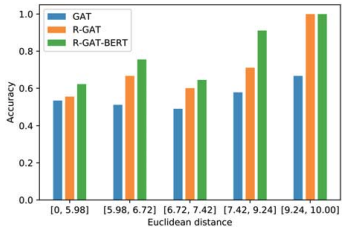
不用Parser的影响:
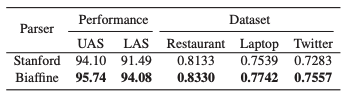
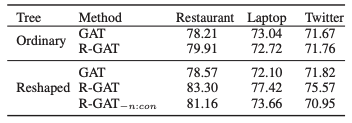
消融研究的结果,其中“Ordinary”表示使用普通依存树,“Reshape”表示使用面向方面的树,“*-n:con”表示不使用n:con的面向方面的树:
R-GAT 和 R-GAT+BERT 对来自Restaurant数据集的 100 个错误分类示例的错误分析结果。原因分为四类,并给出了样本。上表对应 R-GAT 的结果,下表对应 R-GAT+BERT:
-
编码
+关注
关注
6文章
935浏览量
54759 -
模型
+关注
关注
1文章
3158浏览量
48701 -
GAT
+关注
关注
0文章
7浏览量
6328
原文标题:中山大学&阿里巴巴提出:用于基于Aspect的情感分析的关系图注意网络(GAT)
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
依存句法分析器的简单实现
pyhanlp两种依存句法分类器
基于CRF序列标注的中文依存句法分析器的Java实现
swi的功能号是如何来的?它和LR寄存器的值是何关系
swi的功能号是如何来的?它和LR寄存器的值是何关系?
联栅晶体管(GAT)是什么意思?
仪表放大器(INA)偏移电压与增益之间的关系
电力信息-物理相互依存网络脆弱性评估

列表解释关系模型
一种端到端的序列多任务法律判决预测模型






 工商网监
工商网监
评论