 “实时”对工程决策意味着什么
“实时”对工程决策意味着什么
实时数据无处不在,由嵌入在各种技术(包括自动驾驶汽车、制造设备和医疗设备)中的传感器生成。但是,“实时”对工程决策的真正含义是什么,更重要的是,如何使用实时数据?
许多工程师可能认为这些数据的主要用途是预测性维护,监测产生所述数据的设备的长期可行性。虽然这肯定是这种数据的一种潜在用途,但它不是主要用途。实时数据最好由机器学习模型处理,这些模型能够在收到数据时尽快分析数据。然后,此数据用于生成见解,这些见解将快速或“实时”发送到数据库、仪表板或设备。
然而,工程师面临的一个共同挑战是处理实时数据,因为原始形式的数据太混乱,无法进行有效分析。使用机器学习模型来处理这些数据是有帮助的,但更重要的是,工程师必须在将实时数据放入这些模型之前有效地准备这些数据。
考虑汽车发动机的温度计。从理论上讲,从仪表收集的数据每秒捕获一个温度。但是,发动机的温度由多个传感器测量,每个传感器的测量速率略有不同 - 称为采样率或时间步长 - 必须将其同步到单个数据集中,然后才能由模型进行分析。那么,工程师应该从哪里开始使用实时数据呢?
尝试同步数据
在宏观层面上,同步数据的目标与同步手表的目标相同 - 将一个不同的时间与另一个不同的时间对齐,以便它们一起流动。在微观层面上,目标是将多个不同的数据点(本质上是几个不同步的手表测量的秒数)实时合并到一个数据集中。然而,每个数据点都是如此的微不足道,它们之间的差距是如此细化,以至于将它们同步在一起需要仔细准备。
同步实时数据的第一步是对齐。它可以帮助工程师从所需的目标开始 - 特定的时间步长或采样率,例如每小时或每10秒。但是,实时数据模型通常设计为一次仅处理 1 秒的数据。因此,同步原始设备数据需要创建一个运行在 0 到 1 秒之间的时间向量,时间步长为 0.001 秒,然后对数据进行“重采样”以匹配新时间。
考虑到这一点,下一步是数据同步的艺术所在,因为工程师必须决定如何在时间不匹配的地方填写数据点。这通常是通过对原始数据重新采样来完成的。几种常见的重采样方法包括最近邻、聚合和插值,最佳选择取决于初始时间矢量对齐和应用要求。
当工程师不确定数据集之间的时间对齐时,常见的解决方案是用恒定值或缺失数据填充空白。这在涉及许多传感器时尤其有用,因为浏览和可视化结果数据可以帮助确定如何继续分析其余数据。如果时间紧密对齐,则可以使用所记录的任何重采样方法。如果时间不紧密对齐,工程师应聚合或插值数据。
想象一下,将每小时的数据转换为每日数据。如何在单个数据点中表示 24 小时内的所有数据?此方案中的一个适当示例是数据聚合,例如每日平均值。对于非数值数据,模式、计数或最近邻方法更为常见。
在处理实时传感器数据时,特别是在时间仅略微错位的情况下,许多工程师使用插值,因为它有助于提供数据趋势的知识,因为需要填充的时间空间更少。如果在处理实时传感器数据时点较远,则多项式或样条插值是更准确的方法。
下面是使用温度、压力和电流传感器预测设备故障的示例。
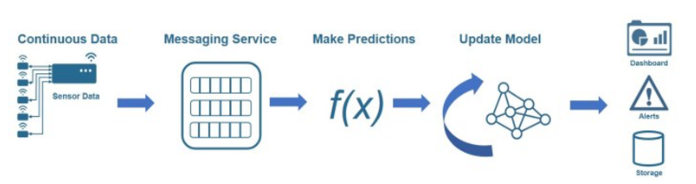
图 1:流式处理工作流的图示。© 1984–2020 数学工程公司
在此示例中,消息传递服务处理原始传感器数据,然后将其应用于模型,该模型用于实时生成预测。生成预测后,模型将更新并应用于下一组实时传感器数据。这些结果会持续且反复地实时发送到仪表板。
实时数据和通用数据的区别
概述的准备实时数据的过程可能听起来很有挑战性。但是,对于工程师来说,它很常见,可以内置到大多数数据科学平台的API和模块中。由于与数据科学平台的常见集成,在执行此过程时,在使用实时传感器数据构建模型之前,通常需要解决最少的额外数据准备注意事项。
其中一个考虑因素应该是规划一个系统,这意味着在构建任何东西之前捕获所有需求并建立参数。此外,在流程早期构建完整的流式处理原型也会有所帮助,因为它允许工程师在分析实时数据的同时返回调整算法。时间窗口可能是另一个需要考虑的好参数,因为这些参数通常控制进入系统的数据量。
构建模型时,工程师通常会对数据集进行平滑和缩减采样。使用实时数据,可以添加频域,从而创建一个新参数,以便在模型分析数据之前考虑这些参数。一旦原始数据被组织到具有匹配时间的单个数据集中,就更容易执行其他分析。
总体而言,随着自动驾驶汽车和医疗设备以及制造设备和其他设备继续嵌入各种传感器,实时数据将变得更加普遍。随着工程师希望继续为系统提供有价值的基于数据的见解,有效地导航传感器数据的“实时”方面将非常重要。
审核编辑:郭婷
-
传感器
+关注
关注
2550文章
51045浏览量
753118 -
发动机
+关注
关注
33文章
2473浏览量
69275 -
自动驾驶
+关注
关注
784文章
13786浏览量
166404
发布评论请先 登录
相关推荐
ADS8671 datasheet里写的是小信号输入-3db带宽为15KHz,是不是意味着正常信号超过10K衰减已经很厉害了?
在ADS8320的规格书里,Tcsd最大为0ns,请问这是不是意味着Dclock极性只能是空闲为低?
ADC的数据表给出了±VREF的输入范围,是否意味着可以测量相对于接地的负电压?
ADS1262浮空测量波动大,是否意味着连接上信号实测波动也会很大?
超级电容的出现意味着储能技术的突破

电子设备有陶瓷电容意味着什么?

电子设备有陶瓷电容意味着什么?
想要对脉宽3ns的脉冲信号进行放大,是不是意味着我选放大器时的响应时间要小于3ns?
解析OrangePi AIpro:什么是 NPU?它对你意味着什么?

芯耀辉科技解读高速互连对于AI和大算力芯片而言意味着什么?
CTA进网许可认证对于无线产品意味着什么?

以应用为导向的芯片设计趋势,对EDA厂商意味着什么?






 工商网监
工商网监
评论