 使用神经处理单元集群转换边缘AI
使用神经处理单元集群转换边缘AI
随着人工智能领域获得牵引力,这些设备变得越来越计算和耗电。随后,边缘设备上的处理负载随着系统架构的性能和复杂性而显著增加。因此,在系统中灌输了更高分辨率的图像和更复杂的算法,随着对AI处理的需求不断增长,以实现高TOPS性能,这需要进一步优化。
Synopsys 发布了神经处理单元 (NPU)、知识产权 (IP) 内核和工具链,以满足 AI 片上系统 (SoC) 中日益复杂的神经网络模型的性能需求。其新的设计软件 ARC NPX6 和 NPX6FS NPU IP 可处理实时计算的需求,同时为 AI 应用消耗超低功耗。此外,该公司的新 MetaWare MX 开发工具提供了一个完整的编译环境,具有自动化神经网络算法分区,可最大限度地提高最新 NPU 上应用软件开发的资源效率。
使用新的设计软件 ARC NPX6 和 NPX6FS NPU IP 以及元软件 MX 开发工具包,设计人员可以利用最新的神经网络模型,满足不断升级的性能期望,并加快其下一代智能 SoC 的上市时间。ARC NPX6 NPU IP 系列包括许多处理深度学习算法覆盖的产品,包括对象识别、图像质量增强和场景分割等计算机视觉任务,以及音频和自然语言处理等大型 AI 应用。设计中的单个内核可以从 4K MAC 扩展到 96K MAC,以实现超过 250 TOPS 和超过 440 TOPS 的单个 AI 引擎性能,并且很少。
NPX6 NPU IP 包含对多达 8 个 NPU 的多 NPU 群集的硬件和软件支持,稀疏性为 3500 TOPS。由于硬件和软件中的高级带宽功能以及内存层次结构(每个内核中包含L1内存以及用于访问常见L2内存的高性能,低延迟连接),可以扩展到大量MAC数量。对于受益于神经网络内部 BF16 或 FP16 的应用,提供了可选的张量浮点单元。
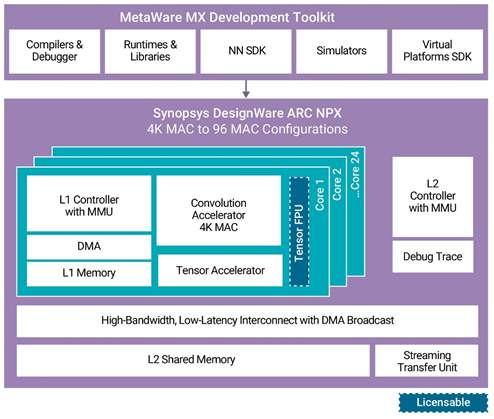
MetaWare MX 开发工具包为应用软件开发提供了软件编程环境,包括神经网络软件开发工具包 (NN SDK) 和虚拟模型支持。NN SDK 会自动将使用流行框架(如巨炬、张量流或 ONNX)训练的神经网络转换为 NPX 优化的可执行代码。
这个概念是,NPX6 NPU处理器IP随后可用于制造各种产品,从几个TOPS到数千个TOPS,所有这些都可以使用单个工具链编写。
可扩展的实时 AI/神经处理器 IP,具有多达 3,500 个 TOPS 的性能,支持 CNN、RNN/LSTM、变压器、推荐器网络和其他神经网络。
功率效率(高达 30 TOPS/W)在业界无与伦比。
卷积加速器的 1-24 个内核,增加了 4K MAC/内核
张量加速器,支持张量运算符集体系结构并允许变量激活 (TOSA)
软件开发套件
用于自动混合模式量化的工具
降低带宽的架构和软件工具特性
通过并行处理各个层来减少延迟。
设计软件 ARC VPX 矢量 DSP 无缝集成。
生产力很高。张量流和巨炬框架,以及ONNX交换标准,由元软件MX开发工具包支持。
此外,ARC NPX6FS NPU IP 符合 ISO 26262 ASIL D 标准,用于随机硬件故障检测和系统功能安全开发流程。这些处理器具有符合 ISO 26262 的特定安全机制,可处理下一代区域性设计的混合关键性和虚拟化需求,以及全面的安全文档。
ARC 元软件 MX 开发工具包包括神经网络软件开发工具包 (SDK)、编译器和调试器、虚拟平台 SDK、运行时和库以及高级仿真模型。它提供了一个统一的工具链环境来加速应用程序开发,并在MAC资源之间智能地划分算法以实现最佳处理。MetaWare MX 安全开发工具包包含安全手册和安全指南,可帮助开发人员满足 ISO 26262 标准,并为安全关键型汽车应用的 ISO 26262 合规性测试做准备。
利用 NPU 集群加速边缘 AI 应用
为了满足人工智能应用不断增长的性能和复杂需求,恩智浦NPU IP核提供高性能、可扩展的实时人工智能和神经处理IP,具有多达3500个TOPS,支持各种神经网络,如CNN、RNN/LSTM、变压器和推荐器网络。
此外,它通过并行处理各个层来减少延迟。此外,高生产力的元软件 MX 开发工具包支持张量流和巨魔框架以及 ONNX 交换格式。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
19286浏览量
229852 -
神经网络
+关注
关注
42文章
4771浏览量
100772 -
人工智能
+关注
关注
1791文章
47279浏览量
238511
发布评论请先 登录
相关推荐
AI模型部署边缘设备的奇妙之旅:如何实现手写数字识别
HZHY-AI100G:适配鸿蒙系统的AI边缘计算智能盒

使用 ADI 的 MAX78002 MCU 开发边缘 AI 应用


基于FPGA的类脑计算平台 —PYNQ 集群的无监督图像识别类脑计算系统
边缘AI网关,将具备更强大的计算和学习能力
ai边缘盒子有哪些用途?ai视频分析边缘计算盒子详解

边缘计算单元多接入能力怎么算
AI边缘计算盒子优势有哪些?如何实现低延迟处理?

面向边缘AI应用的全新RZ/V2H
risc-v多核芯片在AI方面的应用
全新AMD锐龙8000F系列处理器整机正式发售 配备神经处理单元(NPU)






 工商网监
工商网监
评论