 边缘AI的模型压缩技术
边缘AI的模型压缩技术

深度学习在模型及其数据集方面正在以惊人的速度增长。在应用方面,深度学习市场以图像识别为主,其次是光学字符识别,以及面部和物体识别。根据 Allied 的市场调查,2020 年全球深度学习市场规模为 68.5 亿美元,预计到 2030 年将达到 1799.6 亿美元,从 2021 年到 2030 年的复合年增长率为 39.2%。
在某个时间点,人们认为大型和复杂的模型表现更好,但现在它几乎是一个神话。随着边缘AI的发展,越来越多的技术将大型复杂模型转换为可以在边缘上运行的简单模型,所有这些技术结合在一起执行模型压缩。
什么是模型压缩?
模型压缩是在具有低计算能力和内存的边缘设备上部署SOTA(最先进的)深度学习模型的过程,而不会影响模型在准确性,精度,召回性等方面的性能。模型压缩广泛地减少了模型中的两件事,即大小和延迟。大小减小侧重于通过减少模型参数使模型更简单,从而减少执行中的 RAM 要求和内存中的存储要求。减少延迟是指减少模型进行预测或推断结果所花费的时间。模型大小和延迟通常是一起的,大多数技术都会减少两者。
流行的模型压缩技术
修剪:
修剪是模型压缩的最流行的技术,它通过删除冗余和无关紧要的参数来工作。神经网络中的这些参数可以是连接器、神经元、通道,甚至是层。它很受欢迎,因为它同时减小了模型的大小并改善了延迟。
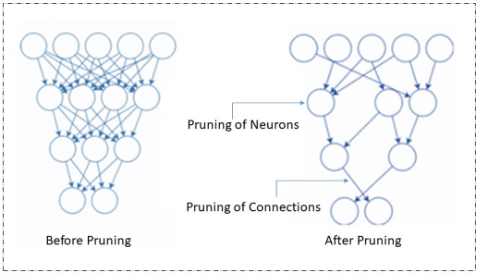
修剪
修剪可以在训练模型时或在训练后完成。有不同类型的修剪技术,包括重量/连接修剪,神经元修剪,过滤器修剪和层修剪。
量化:
当我们在修剪中移除神经元,连接,过滤器,层等以减少加权参数的数量时,权重的大小在量化过程中减小。在此过程中,较大集中的值将映射到较小集中的值。与输入网络相比,输出网络的值范围较窄,但保留了大部分信息。
知识提炼:
在知识提炼过程中,一个复杂而大型的模型在一个非常大的数据集上被训练。微调大型模型后,它可以很好地处理看不见的数据。一旦实现,这些知识就会转移到较小的神经网络或模型中。同时使用教师网络(较大模型)和学生网络(较小模型)。这里存在两个方面,知识提炼,其中我们不调整教师模型,而在迁移学习中,我们使用确切的模型和权重,在一定程度上改变模型,并针对相关任务进行调整。
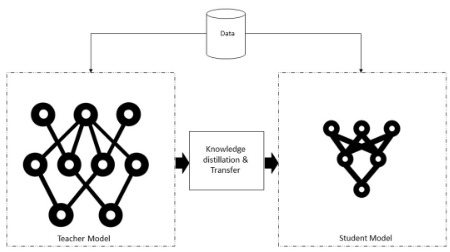
知识蒸馏系统
知识、蒸馏算法和师生架构模型是典型知识蒸馏系统的三个主要部分,如上图所示。
低矩阵分解:
矩阵构成了大多数深度神经架构的大部分。该技术旨在通过应用矩阵或张量分解并将它们变成更小的矩阵来识别冗余参数。当应用于密集 DNN(深度神经网络)时,此技术可降低 CNN(卷积神经网络)层的存储要求和因式分解,并缩短推理时间。具有二维且具有秩 r 的权重矩阵 A 可以分解为更小的矩阵,如下所示。
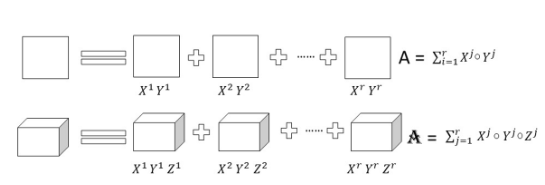
低矩阵因式分解
模型准确性和性能在很大程度上取决于正确的因式分解和秩选择。低秩因式分解过程中的主要挑战是更难实现,并且计算密集型。总体而言,与全秩矩阵表示相比,密集层矩阵的因式分解可导致更小的模型和更快的性能。
由于边缘AI,模型压缩策略变得非常重要。这些方法相互补充,可以在整个AI管道的各个阶段使用。像张量流和Pytorch这样的流行框架现在包括修剪和量化等技术。最终,该领域使用的技术数量将会增加。
审核编辑:郭婷
-
连接器
+关注
关注
105文章
16347浏览量
147841 -
RAM
+关注
关注
8文章
1400浏览量
120975 -
深度学习
+关注
关注
73文章
5604浏览量
124609
发布评论请先 登录
AI大模型微调企业项目实战课
论马斯克的预言:AI使人类边缘化
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
意法半导体STM32 AI模型库助力边缘AI落地应用
直播有礼 | 瑞萨边缘AI线上技术月——AI MCU/MPU产品及边缘AI案例集

影像仪AI自动寻边技术精准捕捉边界测量,检测效率翻倍!
AI 边缘计算网关:开启智能新时代的钥匙—龙兴物联
Nordic收购 Neuton.AI 关于产品技术的分析
边缘AI实现的核心环节:硬件选择和模型部署

边缘AI的优势和技术基石




评论