 如何充分挖掘预训练视觉-语言基础大模型的更好零样本学习能力
如何充分挖掘预训练视觉-语言基础大模型的更好零样本学习能力
融入了Prompt的新模式大致可以归纳成”pre-train, prompt, and predict“,在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有Masked Language Model, 在文本情感分类任务中,对于 "I love this movie." 这句输入,可以在后面加上prompt "The movie is ___" 这样的形式,然后让PLM用表示情感的答案填空如 "great"、"fantastic" 等等,最后再将该答案转化成情感分类的标签,这样以来,通过选取合适的prompt,我们可以控制模型预测输出,从而一个完全无监督训练的PLM可以被用来解决各种各样的下游任务。
因此,合适的prompt对于模型的效果至关重要。大量研究表明,prompt的微小差别,可能会造成效果的巨大差异。研究者们就如何设计prompt做出了各种各样的努力——自然语言背景知识的融合、自动生成prompt的搜索、不再拘泥于语言形式的prompt探索等等。
而对于视觉领域的prompt,最近在视觉语言预训练方面的进展,如CLIP和ALIGN,prompt为开发视觉任务的基础模型提供了一个有前途的方向。这些基础模型在数百万个有噪声的图像-文本对上进行训练后编码了广泛的视觉概念,可以在不需要任务特定的训练数据的情况下以零目标的方式应用于下游任务。这可以通过适当设计的prompt提示实现。
以CLIP为例,如下图红色方框强调所示,可以完成对“class label”的拓展,使得模型具有较为丰富的视觉信息。然后,可以使用CLIP对图像进行分类,以度量它们与各种类描述的对齐程度。因此,设计这样的提示在以zero-shot方式将基础模型应用到下游任务中起着至关重要的作用。
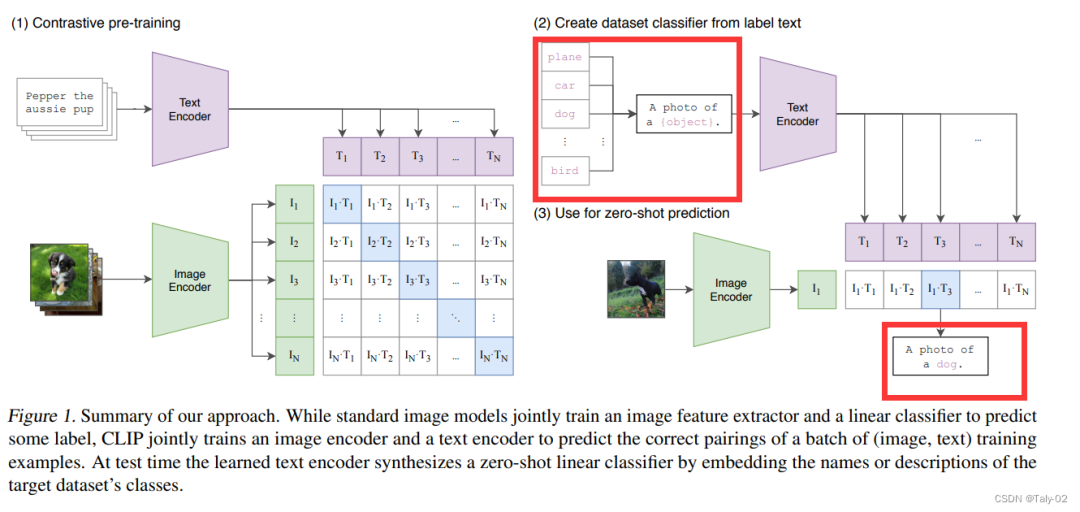
然而,这种手工制作的prompt需要特定于领域的灵感,因此可能较难设计,所以如何设计一种模式,可以让让模型自适应地学习到有关prompt的一些参数和设定是非常有必要的。与手工制作的prompt相比,这种方法可以找到更好的prompt,但学习到的prompt仅限于与训练数据对应的分布和任务,除此之外的泛化可能有限。
此外,这种方法需要带注释的训练数据,这可能非常昂贵,而且不能很好地应用于zero-shot的相关任务中。为了解决上述的挑战, 论文提出在测试阶段使用test-time prompt tuning(TPT),只使用给定的测试样本对prompt进行调整。由于避免了使用额外的训练数据或标注,TPT仍然遵守了zero-shot的设置。
. 方法
论文首先简单回顾了CLIP和基于CLIP的一些可学习参数的prompts获取方法。对于为何要优化prompt,论文是这样描述的:CLIP包含了丰富的知识,从前期的训练中获得了海量的知识和不同的数据感知能力。然而,如何更有效地提取这些知识仍然是一个开放的问题。一个简单的策略是直接对模型进行微调,无论是端到端的还是针对的一个子集层,对一类的输入。然而,先前的工作表明,这种微调策略导致特定于领域的行为失去了非分布泛化和鲁棒性的基础模型。
因此,这项工作的目标是利用现有的CLIP知识来促进其泛化到zero-shot的厂家中去。因此,调整prompt就是实现这一目标的理想途径。此外,我们将测试时提示调优视为为模型提供上下文的一种方法为单个测试样本量身定制,有助于精确检索CLIP知识。
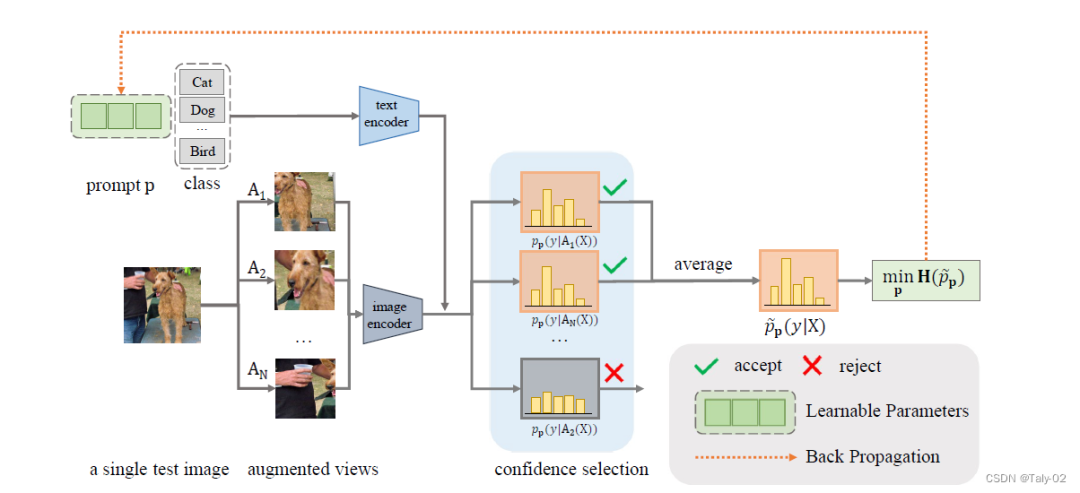
论文的目的很简单,就是在测试阶段得不到测试样本ground-truth标注的时候,进行一定的训练,具体表现为
因为标签不能用于测试阶段的优化,所以我们如果想在测试阶段进行优化就必须选择用于能够提供一定hint的无监督损失函数来指导优化。因此,论文设计了TPT目标来促进采用不同数据增强下,模型的一致性。通过对给定测试相同图像的不同增强类型的特征,来依照他们预测的差值来进行训练。具体来说,我们使用一个随机增广cluster生成测试图像的N个随机augumention视图,最小化平均预测概率分布的熵:
这里 是根据物体不同prompt and the -th augmented view of the test image预测出的概率。
值得一提的是,为了减少随机增强的噪声(也就是说增强之后模型很难再预测出正确的分类信息,如删去了图像非常关键的content),本文还引入了一个新的机制:confidence selection,来选择过滤增强产生的低置信度预测的view。数学表达式体现为:
实验
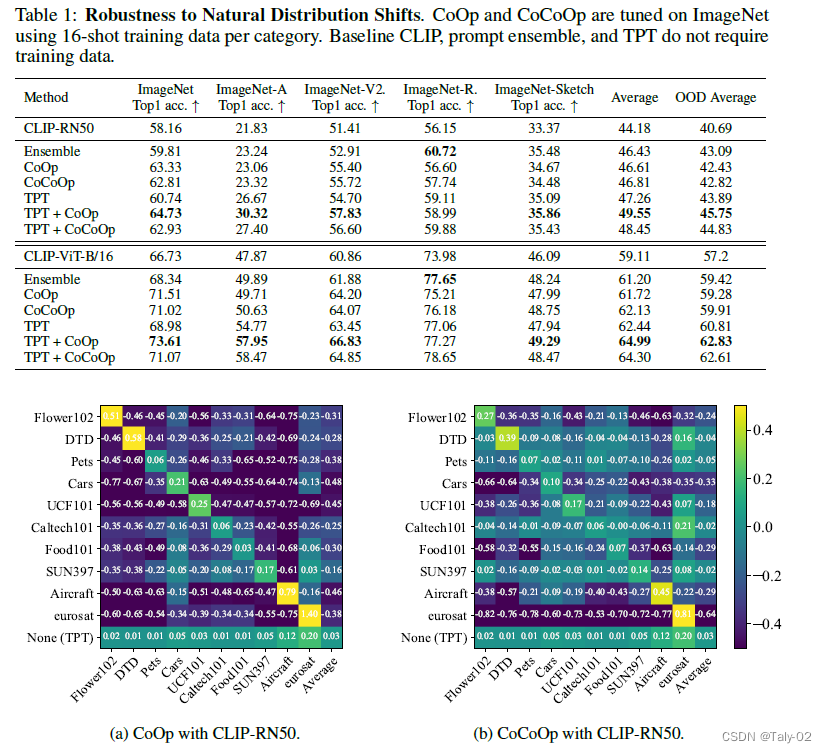
首先论文根据CoOp 和 CoCoOp的混淆矩阵可视化来判断这两种可学习的prompt参数化方式在不同数据集上的迁移性很差,有增加参数量过拟合的嫌疑。所以其实在训练阶段,增加参数量来做相应的操作不见得合理。因此才更能体现本文这种基于测试阶段方法提出方法的优越性。
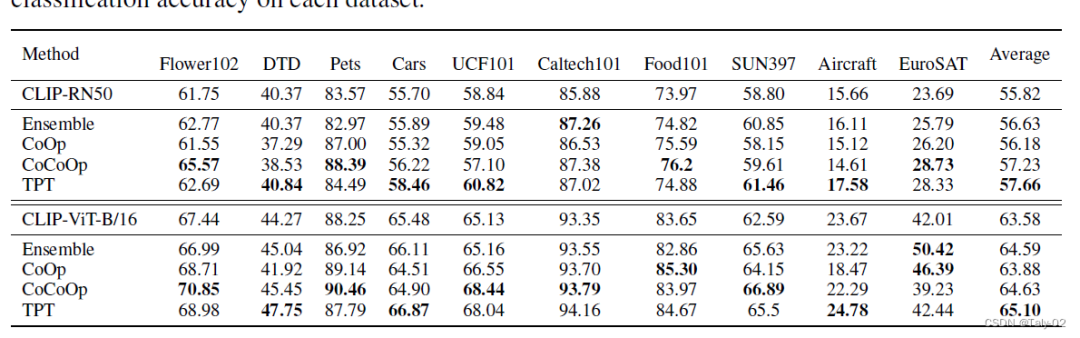
可以发现,本文提出的这种方法在不同数据集之间的迁移性非常之好。
结论
本文研究了如何充分挖掘预训练视觉-语言基础大模型的更好零样本学习能力。论文提出了Test-time Prompt Tuning, TPT),这种新的prompt调整方法,可以使用单个测试样本动态学习自适应提示。我们证明了该方法对自然分布变化的鲁棒性跨数据集泛化,使用CLIP作为基础模型。不需要任何训练数据或标注,TPT提高了CLIP的zero-shot的泛化能力。
-
模型
+关注
关注
1文章
3243浏览量
48842 -
数据集
+关注
关注
4文章
1208浏览量
24703 -
Clip
+关注
关注
0文章
31浏览量
6667 -
自然语言
+关注
关注
1文章
288浏览量
13350 -
大模型
+关注
关注
2文章
2450浏览量
2713
原文标题:面向测试阶段的prompt搜索方式
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【大语言模型:原理与工程实践】大语言模型的预训练
【大语言模型:原理与工程实践】大语言模型的应用
基于深度学习的自然语言处理对抗样本模型
基于预训练视觉-语言模型的跨模态Prompt-Tuning


如何更高效地使用预训练语言模型
预训练数据大小对于预训练模型的影响
一个通用的自适应prompt方法,突破了零样本学习的瓶颈


什么是零样本学习?为什么要搞零样本学习?





 工商网监
工商网监
评论