 groupby功能的大多数用例
groupby功能的大多数用例

groupby是Pandas在数据分析中最常用的函数之一。它用于根据给定列中的不同值对数据点(即行)进行分组,分组后的数据可以计算生成组的聚合值。 如果我们有一个包含汽车品牌和价格信息的数据集,那么可以使用groupby功能来计算每个品牌的平均价格。 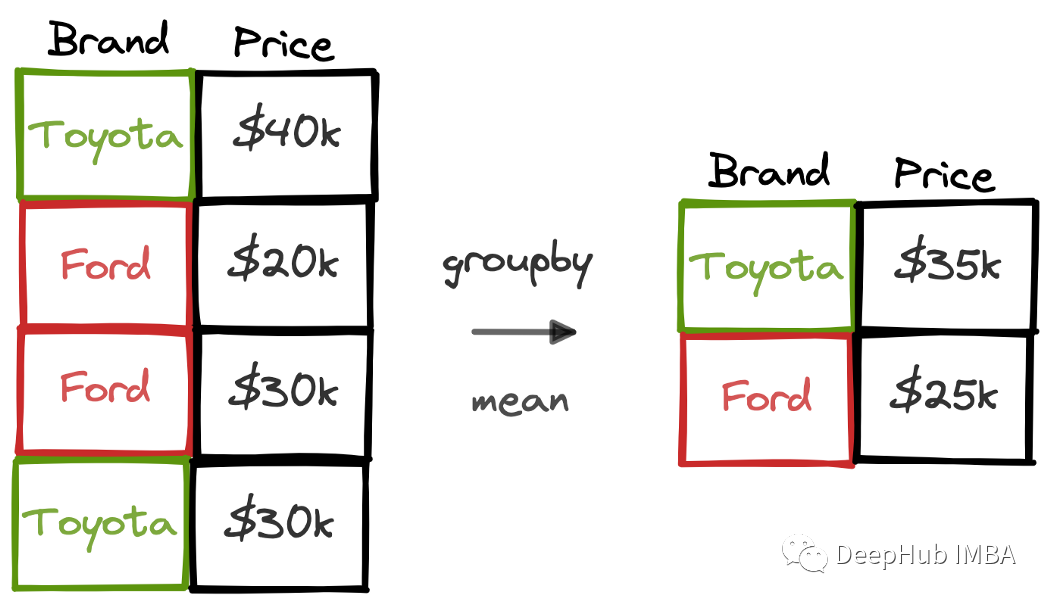 在本文中,我们将使用25个示例来详细介绍groupby函数的用法。这25个示例中还包含了一些不太常用但在各种任务中都能派上用场的操作。 这里使用的数据集是随机生成的,我们把它当作一个销售的数据集。
在本文中,我们将使用25个示例来详细介绍groupby函数的用法。这25个示例中还包含了一些不太常用但在各种任务中都能派上用场的操作。 这里使用的数据集是随机生成的,我们把它当作一个销售的数据集。
importpandasaspd sales=pd.read_csv("sales_data.csv") sales.head()
 1、单列聚合 我们可以计算出每个店铺的平均库存数量如下:
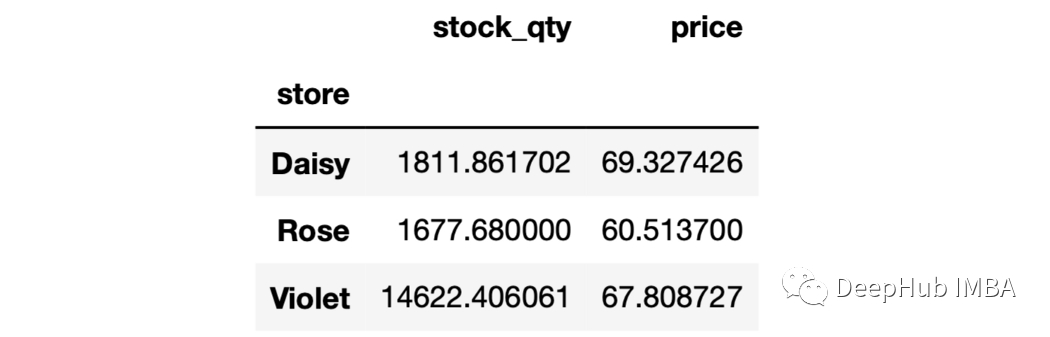
1、单列聚合 我们可以计算出每个店铺的平均库存数量如下:
sales.groupby("store")["stock_qty"].mean()
#输出
store
Daisy1811.861702
Rose1677.680000
Violet14622.406061
Name:stock_qty,dtype:float64
2、多列聚合
在一个操作中进行多个聚合。以下是我们如何计算每个商店的平均库存数量和价格。
sales.groupby("store")[["stock_qty","price"]].mean()sales.groupby("store")[["stock_qty","price"]].mean()
 3、多列多个聚合 我们还可以使用agg函数来计算多个聚合值。
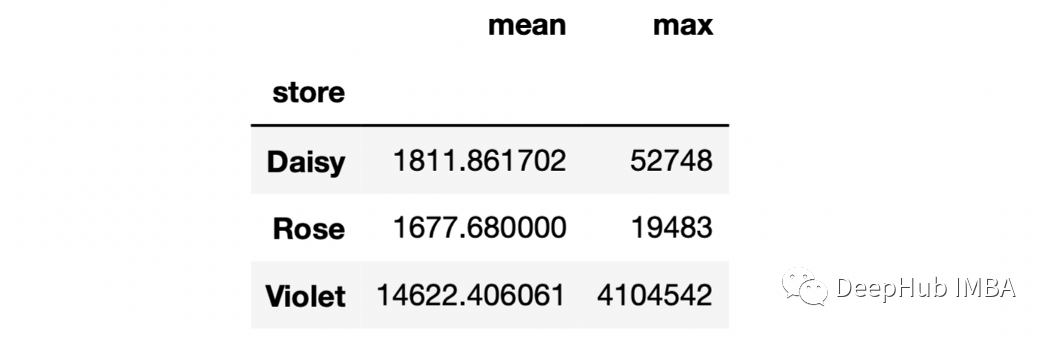
3、多列多个聚合 我们还可以使用agg函数来计算多个聚合值。
sales.groupby("store")["stock_qty"].agg(["mean","max"])
 4、对聚合结果进行命名 在前面的两个示例中,聚合列表示什么还不清楚。例如,“mean”并没有告诉我们它是什么的均值。在这种情况下,我们可以对聚合的结果进行命名。
4、对聚合结果进行命名 在前面的两个示例中,聚合列表示什么还不清楚。例如,“mean”并没有告诉我们它是什么的均值。在这种情况下,我们可以对聚合的结果进行命名。
sales.groupby("store").agg(
avg_stock_qty=("stock_qty","mean"),
max_stock_qty=("stock_qty","max")
)
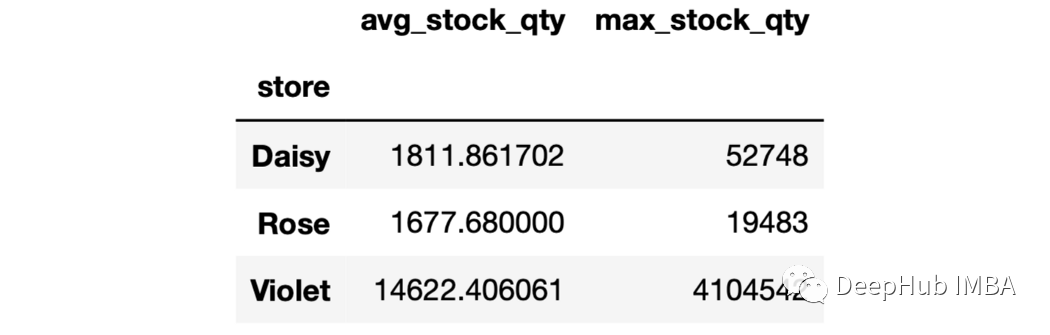 要聚合的列和函数名需要写在元组中。 5、多个聚合和多个函数
要聚合的列和函数名需要写在元组中。 5、多个聚合和多个函数
sales.groupby("store")[["stock_qty","price"]].agg(["mean","max"])
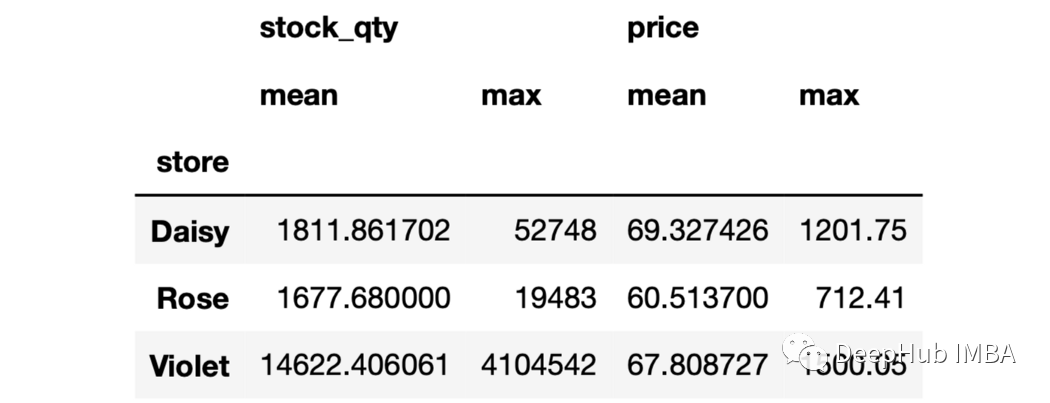
6、对不同列的聚合进行命名
sales.groupby("store").agg(
avg_stock_qty=("stock_qty","mean"),
avg_price=("price","mean")
)
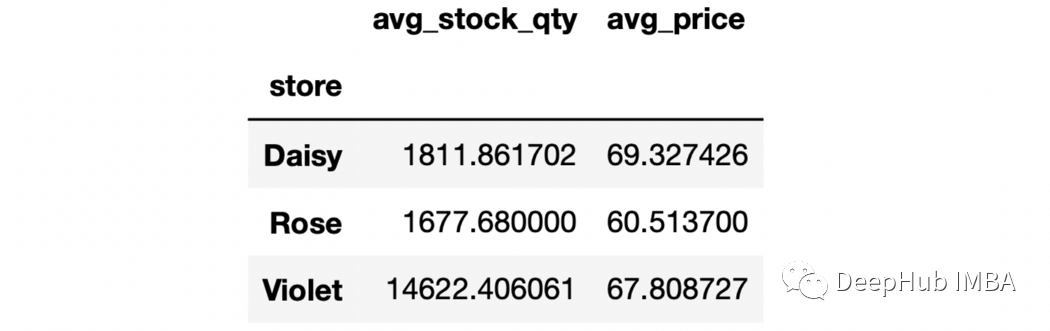 7、as_index参数 如果groupby操作的输出是DataFrame,可以使用as_index参数使它们成为DataFrame中的一列。
7、as_index参数 如果groupby操作的输出是DataFrame,可以使用as_index参数使它们成为DataFrame中的一列。
sales.groupby("store",as_index=False).agg(
avg_stock_qty=("stock_qty","mean"),
avg_price=("price","mean")
)
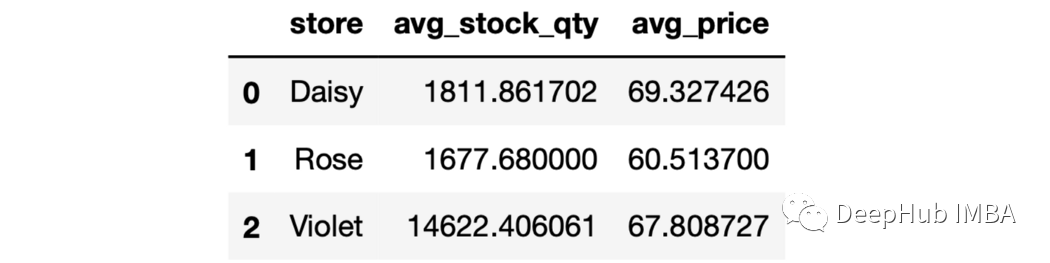 8、用于分组的多列 就像我们可以聚合多个列一样,我们也可以使用多个列进行分组。
8、用于分组的多列 就像我们可以聚合多个列一样,我们也可以使用多个列进行分组。
sales.groupby(["store","product_group"],as_index=False).agg(
avg_sales=("last_week_sales","mean")
).head()
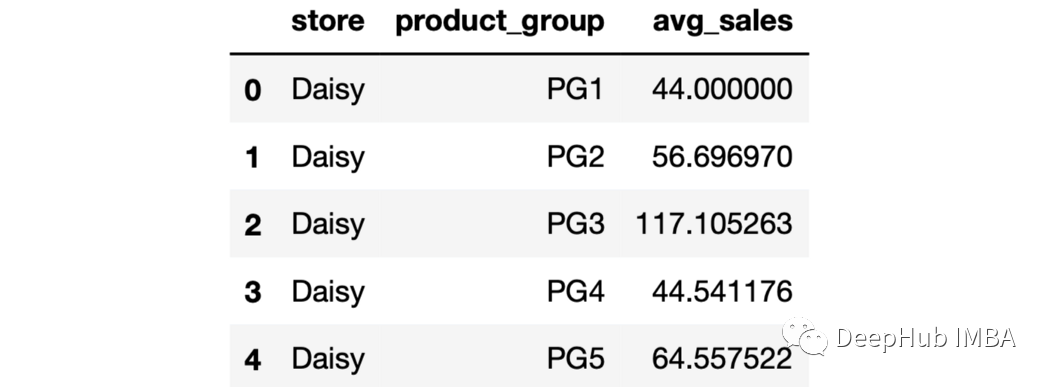 每个商店和产品的组合都会生成一个组。 9、排序输出 可以使用sort_values函数根据聚合列对输出进行排序。
每个商店和产品的组合都会生成一个组。 9、排序输出 可以使用sort_values函数根据聚合列对输出进行排序。
sales.groupby(["store","product_group"],as_index=False).agg(avg_sales=("last_week_sales","mean")
).sort_values(by="avg_sales",ascending=False).head()
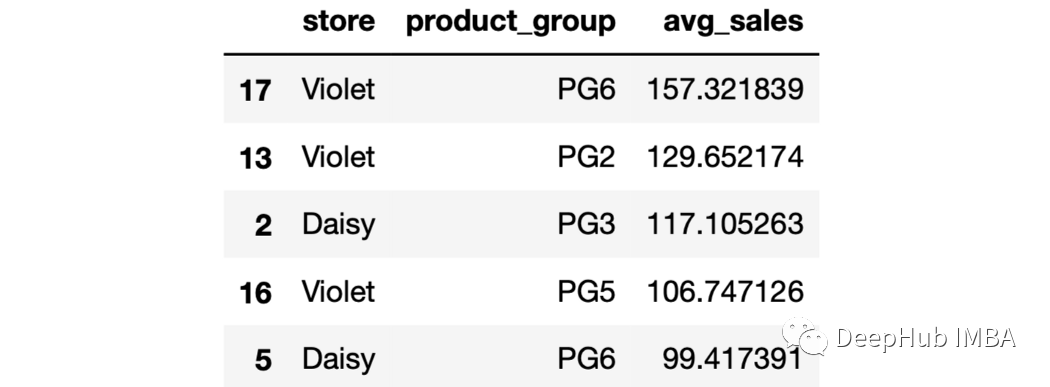 这些行根据平均销售值按降序排序。 10、最大的Top N max函数返回每个组的最大值。如果我们需要n个最大的值,可以用下面的方法:
这些行根据平均销售值按降序排序。 10、最大的Top N max函数返回每个组的最大值。如果我们需要n个最大的值,可以用下面的方法:
sales.groupby("store")["last_week_sales"].nlargest(2)
store
Daisy4131883
231947
Rose948883
263623
Violet9913222
3392690
Name:last_week_sales,dtype:int64
11、最小的Top N
与最大值相似,也可以求最小值
sales.groupby("store")["last_week_sales"].nsmallest(2)
12、第n个值
除上面2个以外,还可以找到一组中的第n个值。
sales_sorted=sales.sort_values(by=["store","last_month_sales"],ascending=False,ignore_index=True)
找到每个店铺上个月销售排名第五的产品如下:
sales_sorted.groupby("store").nth(4)
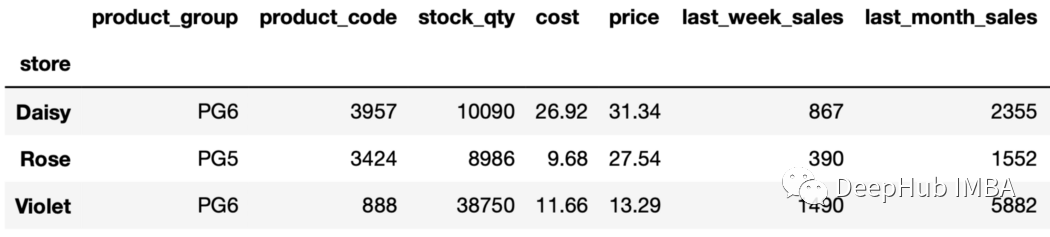 输出包含每个组的第5行。由于行是根据上个月的销售值排序的,所以我们将获得上个月销售额排名第五的行。 13、第n个值,倒排序 也可以用负的第n项。例如," nth(-2) "返回从末尾开始的第二行。
输出包含每个组的第5行。由于行是根据上个月的销售值排序的,所以我们将获得上个月销售额排名第五的行。 13、第n个值,倒排序 也可以用负的第n项。例如," nth(-2) "返回从末尾开始的第二行。
sales_sorted.groupby("store").nth(-2)
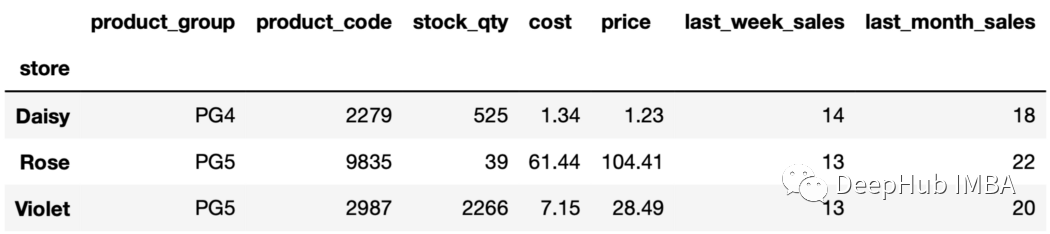 14、唯一值 unique函数可用于查找每组中唯一的值。例如,可以找到每个组中唯一的产品代码如下:
14、唯一值 unique函数可用于查找每组中唯一的值。例如,可以找到每个组中唯一的产品代码如下:
sales.groupby("store",as_index=False).agg(
unique_values=("product_code","unique")
)
 15、唯一值的数量 还可以使用nunique函数找到每组中唯一值的数量。
15、唯一值的数量 还可以使用nunique函数找到每组中唯一值的数量。
sales.groupby("store",as_index=False).agg(
number_of_unique_values=("product_code","nunique")
)
 16、Lambda表达式 可以在agg函数中使用lambda表达式作为自定义聚合操作。
16、Lambda表达式 可以在agg函数中使用lambda表达式作为自定义聚合操作。
sales.groupby("store").agg(
total_sales_in_thousands=(
"last_month_sales",
lambdax:round(x.sum()/1000,1)
)
)
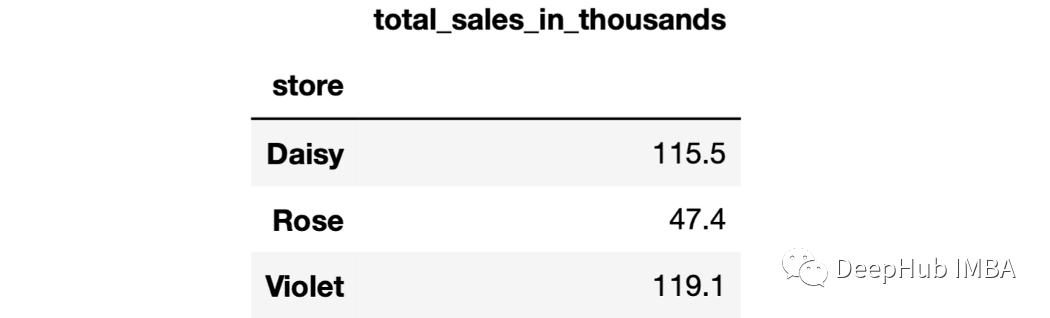 17、apply函数 使用apply函数将Lambda表达式应用到每个组。例如,我们可以计算每家店上周销售额与上个月四分之一销售额的差值的平均值,如下:
17、apply函数 使用apply函数将Lambda表达式应用到每个组。例如,我们可以计算每家店上周销售额与上个月四分之一销售额的差值的平均值,如下:
sales.groupby("store").apply(
lambdax:(x.last_week_sales-x.last_month_sales/4).mean()
)
store
Daisy5.094149
Rose5.326250
Violet8.965152
dtype:float64
18、dropna
缺省情况下,groupby函数忽略缺失值。如果用于分组的列中缺少一个值,那么它将不包含在任何组中,也不会单独显示。所以可以使用dropna参数来改变这个行为。 让我们首先添加一个缺少存储值的新行。
sales.loc[1000]=[None,"PG2",10000,120,64,96,15,53]
然后计算带有dropna参数和不带有dropna参数的每个商店的平均价格,以查看差异。
sales.groupby("store")["price"].mean()
store
Daisy69.327426
Rose60.513700
Violet67.808727
Name:price,dtype:float64
看看设置了缺失值参数的结果:
sales.groupby("store",dropna=False)["price"].mean()
store
Daisy69.327426
Rose60.513700
Violet67.808727
NaN96.000000
Name:price,dtype:float64
groupby函数的dropna参数,使用pandas版本1.1.0或更高版本。 19、求组的个数 有时需要知道生成了多少组,这可以使用ngroups。
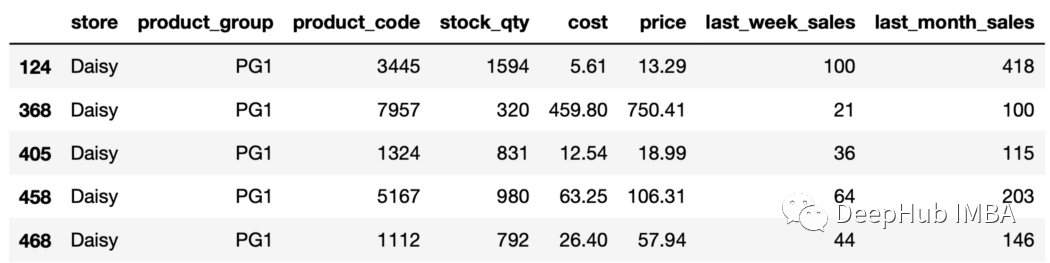
sales.groupby(["store","product_group"]).ngroups 18在商店和产品组列中有18种不同值的不同组合。 20、获得一个特定分组 get_group函数可获取特定组并且返回DataFrame。 例如,我们可以获得属于存储“Daisy”和产品组“PG1”的行如下:
aisy_pg1=sales.groupby( ["store","product_group"]).get_group(("Daisy","PG1") ) daisy_pg1.head()
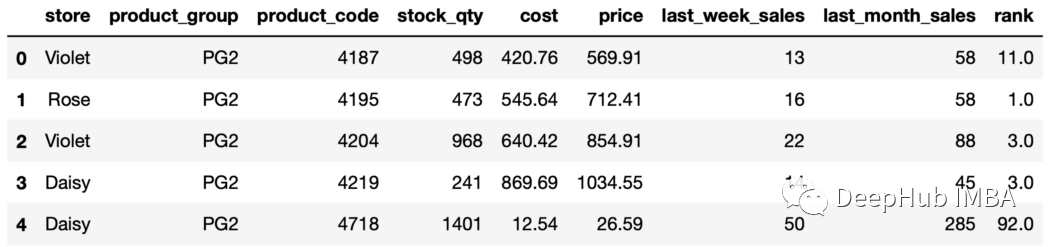
 21、rank函数 rank函数用于根据给定列中的值为行分配秩。我们可以使用rank和groupby函数分别对每个组中的行进行排序。
21、rank函数 rank函数用于根据给定列中的值为行分配秩。我们可以使用rank和groupby函数分别对每个组中的行进行排序。
sales["rank"]=sales.groupby("store"["price"].rank(
ascending=False,method="dense"
)
sales.head()
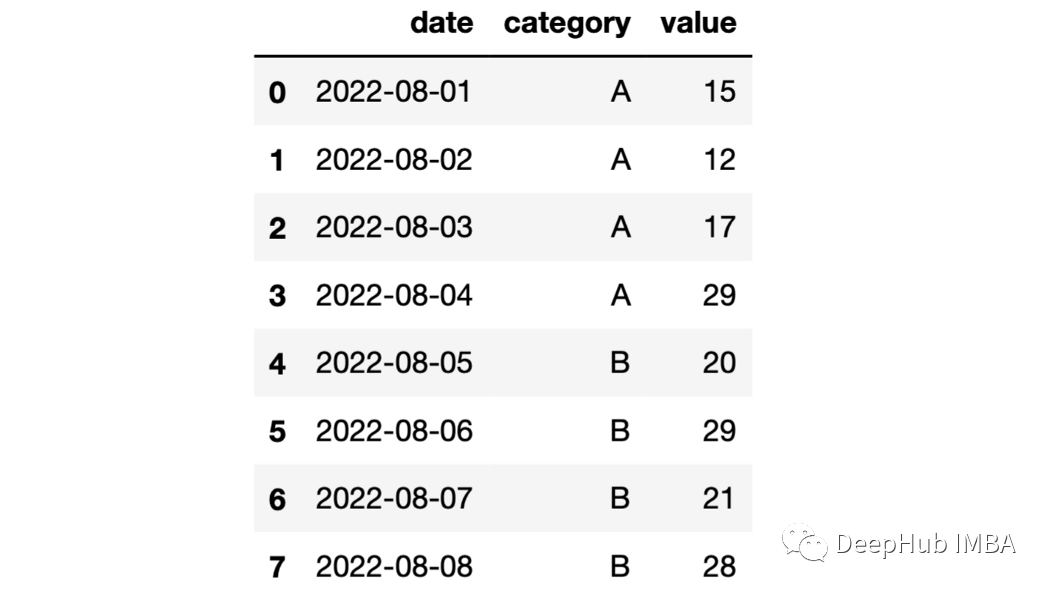
 22、累计操作 们可以计算出每组的累计总和。
22、累计操作 们可以计算出每组的累计总和。
importnumpyasnpdf=pd.DataFrame(
{
"date":pd.date_range(start="2022-08-01",periods=8,freq="D"),
"category":list("AAAABBBB"),
"value":np.random.randint(10,30,size=8)
}
)
 我们可以单独创建一个列,包含值列的累计总和,如下所示:
我们可以单独创建一个列,包含值列的累计总和,如下所示:
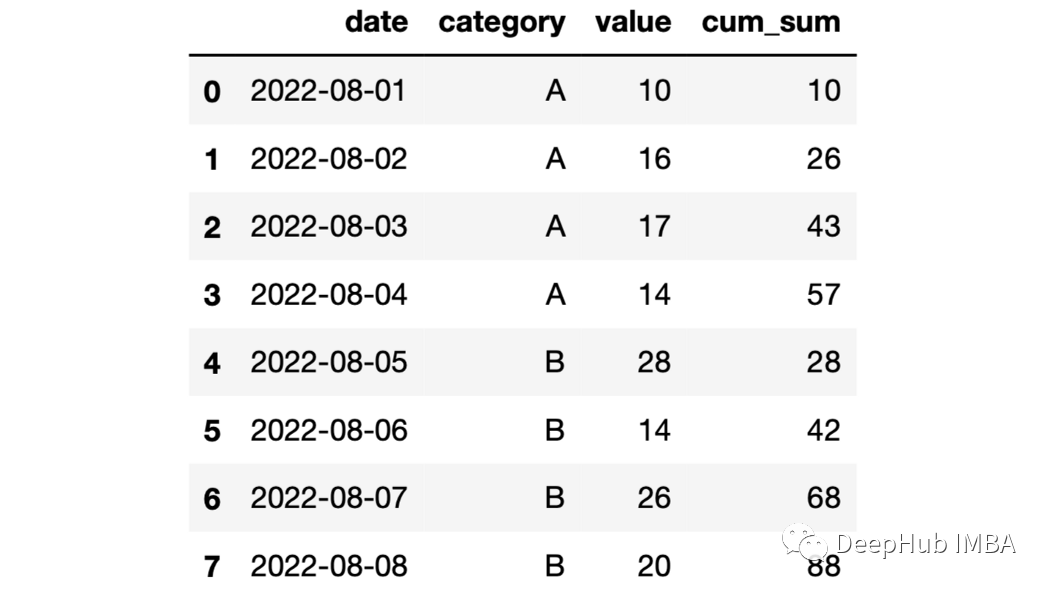
df["cum_sum"]=df.groupby("category")["value"].cumsum()
 23、expanding函数 expanding函数提供展开转换。但是对于展开以后的操作还是需要一个累计函数来堆区操作。例如它与cumsum 函数一起使用,结果将与与sum函数相同。
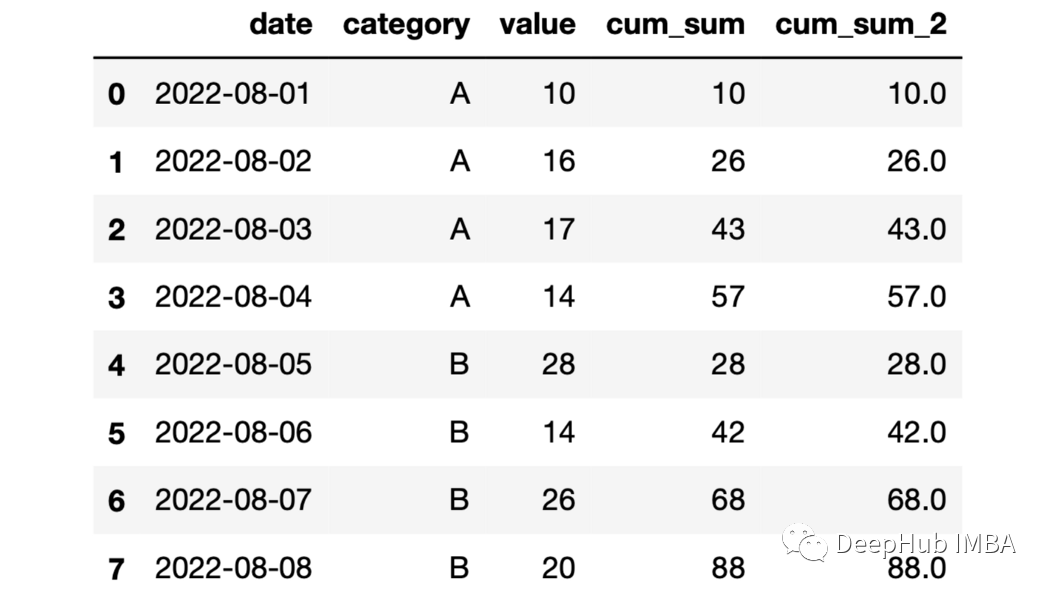
23、expanding函数 expanding函数提供展开转换。但是对于展开以后的操作还是需要一个累计函数来堆区操作。例如它与cumsum 函数一起使用,结果将与与sum函数相同。
df["cum_sum_2"]=df.groupby( "category" )["value"].expanding().sum().values
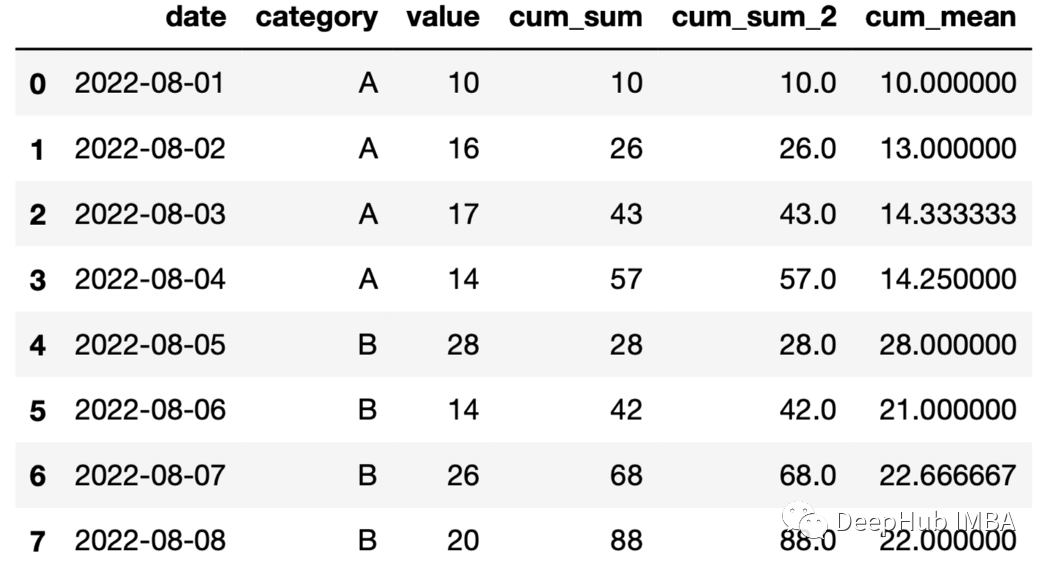
 24、累积平均 利用展开函数和均值函数计算累积平均。
24、累积平均 利用展开函数和均值函数计算累积平均。
df["cum_mean"]=df.groupby( "category" )["value"].expanding().mean().values
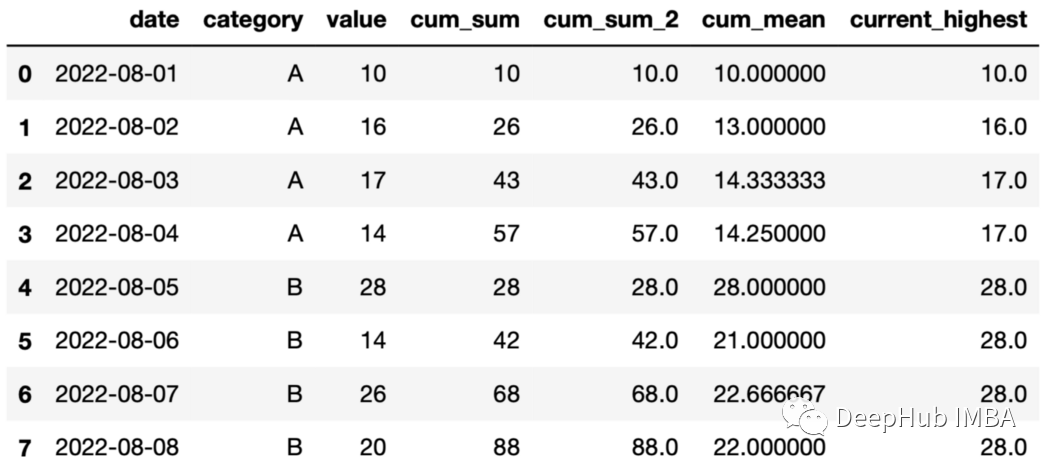
 25、展开后的最大值 可以使用expand和max函数记录组当前最大值。
25、展开后的最大值 可以使用expand和max函数记录组当前最大值。
df["current_highest"]=df.groupby( "category" )["value"].expanding().max().values
 在Pandas中groupby函数与aggregate函数共同构成了高效的数据分析工具。在本文中所做的示例涵盖了groupby功能的大多数用例,希望对你有所帮助。
在Pandas中groupby函数与aggregate函数共同构成了高效的数据分析工具。在本文中所做的示例涵盖了groupby功能的大多数用例,希望对你有所帮助。
审核编辑:彭静
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
函数
+关注
关注
3文章
4421浏览量
67819 -
数据分析
+关注
关注
2文章
1523浏览量
36355 -
数据集
+关注
关注
4文章
1240浏览量
26259
原文标题:25 个例子学会 Pandas Groupby 操作!
文章出处:【微信号:DBDevs,微信公众号:数据分析与开发】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
为什么图腾柱电路大多数用三极管来实现的呢
本帖最后由 梦想号 于 2014-7-18 22:13 编辑
怎么我见到很多的图腾柱电路大多数都是用npn+pnp来实现的。三极管不是有比较大的压降的吗,还有三极管的速度不怎么快,输出电流不够
发表于 07-18 22:08
为什么现在大多数四轴飞行器都采用的是X型布局
`四轴飞行器不单单只有X型,还有十型和H型。为什么现在大多数四轴飞行器都采用的是X型布局呢?据我了解,十字型布局更加简单,更容易上手?`
发表于 05-06 16:49
如何解决大多数电源完整性问题
。有时候,只需要用四层电路板上的一个电源层和一个地层,就可以解决大多数电源完整性问题。除了电源层以外,还可以为每只IC去耦,以解决设计中繁琐的电源问题。不过,现在的PCB空间(还有成本与你的日程)都很紧...
发表于 12-28 08:08
大多数为单指令周期
大多数为单指令周期
ATtiny10/11/12特点1. AVR RISC 结构2. AVR 高性能低功耗RISC 结构90 条指令大多数为单指令周期32 个8 位通用工作寄存器工作在 8MHz
发表于 03-26 16:51
•23次下载
大多数用户并不习惯在智能音箱上收听新闻
听音乐、播报新闻、查询天气等被视为智能音箱最常用的功能,但实际上功能调取的频率与用户的感受并不一定高度相关。近日,外媒公布的最新报告显示,大多数用户实际上并不习惯在智能音箱上收听新闻。
发表于 11-20 14:31
•1845次阅读
为什么大多数加密货币没有存在的必要
大多数人穷尽一生都在寻找自我存在的理由。这是个非常有趣的论点,但本文的重点是寻找加密货币(大多数,不是所有)存在的理由。我将首先解释竞争币存在的主要原因,然后再介绍比特币及其目前和未来的发展,最后会说明为什么大多数竞争币可能没有
发表于 07-04 10:34
•1125次阅读
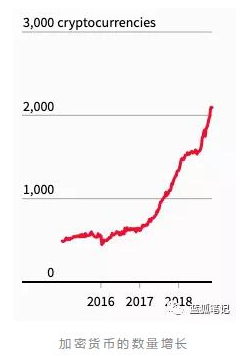
大多数加密数字货币都存在什么问题
据加密数字货币分析师Willy Woo在推特上发布的最新数据显示,大多数加密数字货币项目都严重缺乏市场流动性,这使许多严肃的投资者望而却步。
发表于 11-28 10:07
•2013次阅读
大多数企业担忧5G技术带来的网络安全风险
据外媒报道,德勤(Deloitte)的一项调查显示,大多数专业人士表示,他们所在的企业担心采用5G技术带来的网络安全风险。

满足大多数倒计时控件的视图教程
CountDownView是一个具有倒计时功能的View,满足大多数倒计时控件需求。 集成 方式一: 通过library生成har包,添加har包到libs文件夹内 在entry的gradle内添加
发表于 04-01 11:03
•1次下载
为何大多数PLC采用ARM架构CPU
因为大多数PLC使用ARM架构的芯片就够用了啊!不仅如此,如果你拆开PLC的外壳查看设备的PCB会发现,不仅其架构是ARM的,而且还是很多年前版本的,这是为什么呢?简单来聊聊。
大多数人5G随身WiFi用户被商家引导,如何避免“劣质”随身WiFi?
大多数5G随身WiFi商家,所吹捧的宣传点,基本和网速快慢及稳定性完全不相关。我们以电商平台上,随机4款5G随身WiFi产品详情为例。




评论