 不同种类的anchor-based和anchor-free的相关算法
不同种类的anchor-based和anchor-free的相关算法
前言
由于在学习和应用目标检测算法时,不可避免的接触到正负样本的生成策略等知识点,并且正负样本的区分策略对算法最终效果至关重要。因此,通过参考他人的文章资料,本文将目标检测中正负样本的区分策略进行汇总。为了能将主要篇幅集中在不同算法生成正负样本的策略上,本文不对每个算法完整结构进行详细介绍。本文涉及了不同种类的anchor-based和anchor-free的相关算法(共5个算法)。并且会在后续文章中,继续补充其他算法(例如yolo系列、centernet、ATSS等)。
一、正负样本的概念
目前,许多人在看相关目标检测的论文时,常常误以为正样本就是我们手动标注的GT(ground truth),这个理解是错误的,正确的理解是这样的:
首先,正样本是想要检测的目标,比如检测人脸时,人脸是正样本,非人脸则是负样本,比如旁边的窗户、红绿灯之类的其他东西。其次,在正负样本选取时,要注意:正样本是与GT的IOU值大于阈值时的取值,负样本是小于阈值的,其他的则把它去除即可。
总之,正负样本都是针对于程序生成的框而言,非GT数据[^1]。
二、为什么要进行正负样本采样?
需要处理好正负样本不平衡问题:在ROI、RPN等过程中,整个图像中正样本区域少,大部分是负样本[^2]。
提高网络收敛速度和精度:对于目标检测算法,主要需要关注的是对应着真实物体的 正样本 ,在训练时会根据其loss来调整网络参数。相比之下, 负样本对应着图像的背景,如果有大量的负样本参与训练,则会淹没正样本的损失,从而降低网络收敛的效率与检测精度。
三、anchor-free和anchor-based
二者的区别在于是否利用anchor提取候选框[^2]
从anchor回归属于anchor-based类,代表如faster rcnn、retinanet、YOLOv2 v3、ssd等,
从point回归属于anchor-free类,代表如cornernet、extremenet、centernet等,
二者融合代表如fsaf、sface、ga-rpn等。
四、典型算法
1、MTCNN
论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
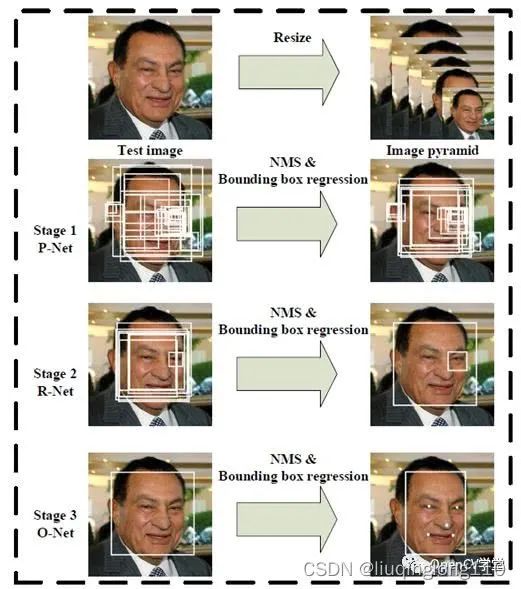
算法推理流程图
MTCNN算法训练过程:[^3]:
PNet的输入尺寸为, RNet的输入尺寸为, ONet的输入尺寸为。
由于PNet输入是一个大小的图片,所以训练前需要把生成的训练数据(通过生成bounding box,然后把该bounding box 剪切成大小的图片),转换成的结构。其他网络输入尺寸如下图所示:
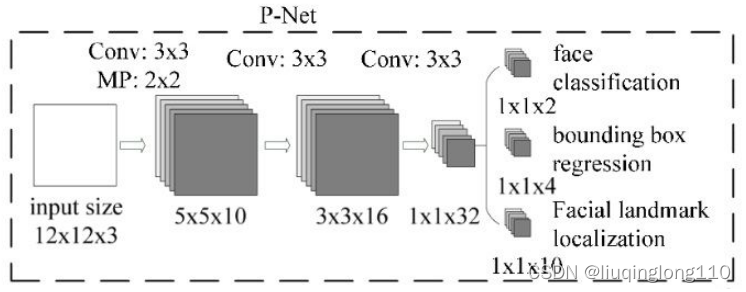
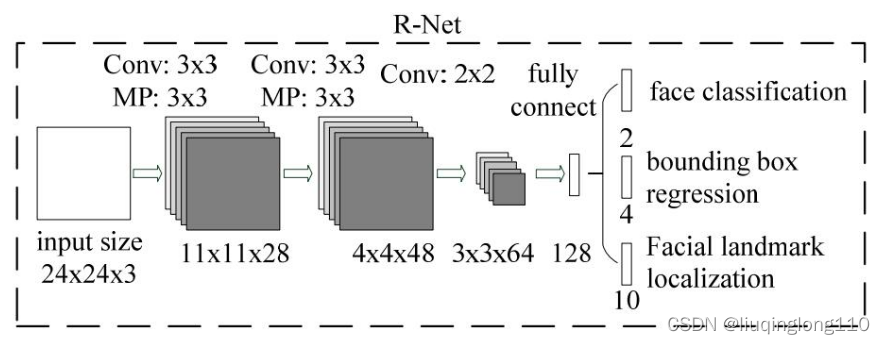
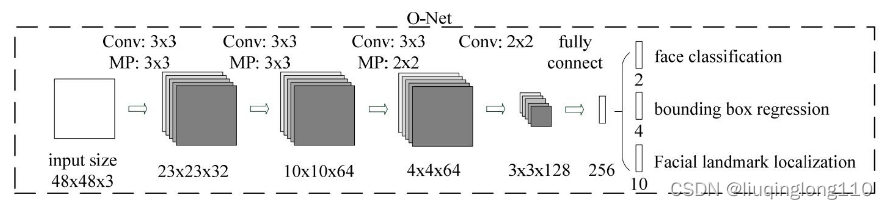
1)正负样本的定义
训练数据可以通过和GT的 IOU 的计算生成一系列的 bounding box。可以通过滑动窗口或者随机采样的方法获取训练数据,训练数据分为三种正样本,负样本,中间样本[^4]。
正样本:IOU > 0.65部分样本:0.4 < IOU < 0.65负样本: IOU < 0.3
如下图所示,为依据图片中人脸框的坐标信息生成正样本和部分样本:由于篇幅原因,下图中IOU的计算过程没有截图,可以参考[^4]的源码。
注意:代码中的 w、h 分别是GT的尺度。
此处生成正样本的脚本,除了对生成的矩形框尺度进行约束,还约束了矩形框的中心点坐标范围。笔者认为,这样做主要是为了提高生成正样本的效率:因为一张图片中正样本的数量是非常有限的,要确保生成的矩形框与GT的IOU大于一定阈值才能成为正样本。
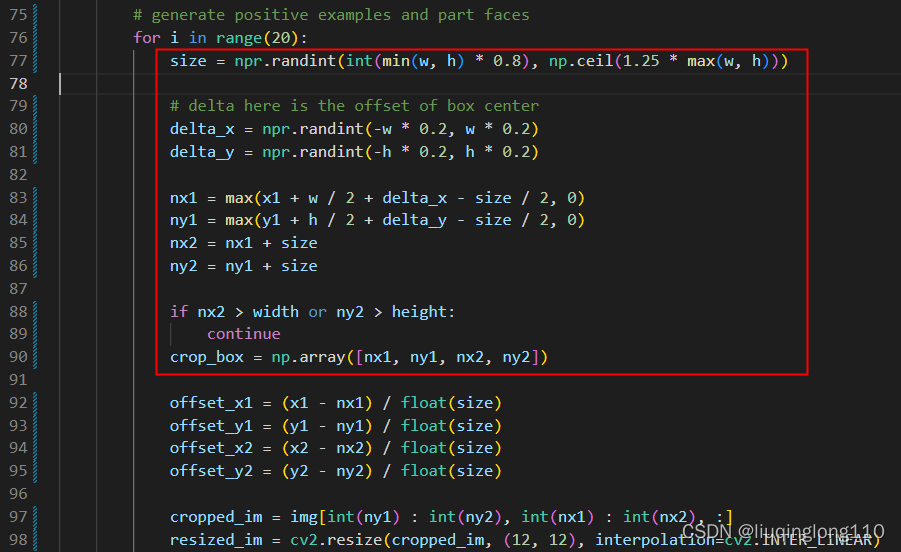
如下图所示,使用随机采样的方式生成负样本:红色框为crop_box计算方法,相对正样本的生成方式更简单。
注意:代码中的 width、height 分别是原始图像的尺度。
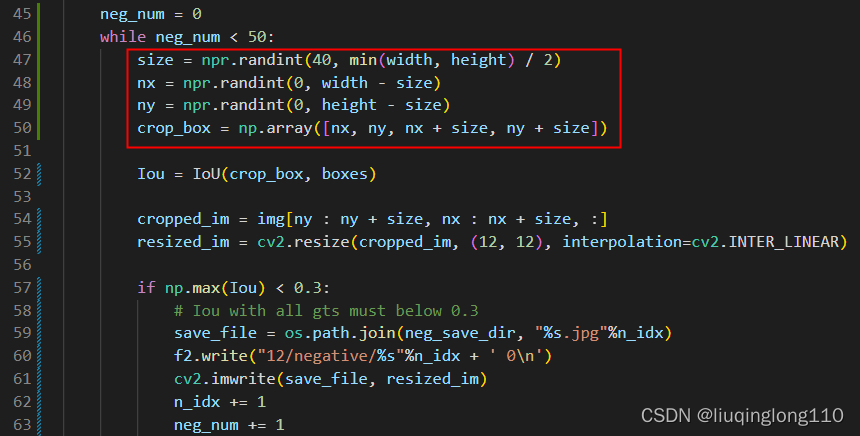
训练样本包含:正样本,负样本,部分样本,关键点样本。比例为 1 : 3 : 1 : 2
训练主要包括三个任务:
人脸分类任务:利用正样本和负样本进行训练,
人脸边框回归任务:利用正样本和部分样本进行训练,
关键点检测任务:利用关键点样本进行训练。
MTCNN算法测试过程:[^3]:
1、首先整张图像经过金字塔,生成多个尺度的图像(图像金字塔),然后输入PNet,PNet由于尺寸很小,所以可以很快的选出候选区域。但是准确率不高,不同尺度上的判断出来的人脸检测框,然后采用NMS算法,合并候选框。
2、根据候选框提取图像,之后缩放到的大小,作为RNet的输入,RNet可以精确的选取边框,一般最后只剩几个边框。
3、最后缩放到的大小,输入ONet,判断后选框是不是人脸,ONet虽然速度较慢,但是由于经过前两个网络,已经得到了高概率的边框,所以输入ONet的图像较少,然后ONet输出精确的边框和关键点信息,只是在第三个阶段上才显示人脸特征定位;前两个阶段只是分类,不显示人脸定点的结果。
2、Faster rcnn
论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
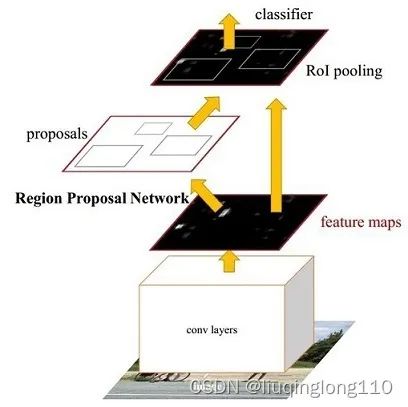
算法整体结构
1)Anchor概念
Anchor(锚框):
Anchor本质上是在原图上预先定义好(这个预先定义十分关键)的一系列大小不一的矩形框[^5]。
为什么要引入Anchor呢?
这是因为之前的目标检测都是模型直接回归边框的位置,而通过引入Anchor相当于加入了强先验信息,然后通过锚框再去筛选与修正,最后再得到预测框。这样做的好处在与是在Anchor的基础上做物体检测,这样要比从无到有的直接拟合物体的边框容易一些。
具体的做法就是:让模型去预测Anchor与真实边框的偏移值,而不是直接预测边框的坐标[^5]。
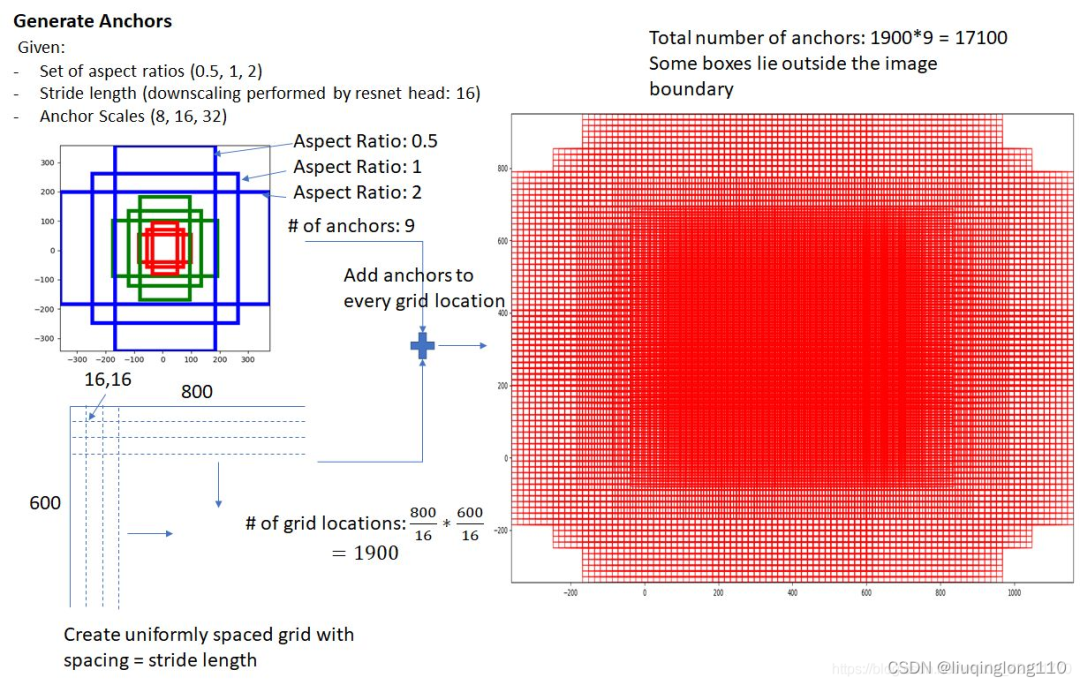
如何生成Anchor呢?

从图片到卷积特征图
特征图(feature map)上的每一个点都生成一组锚点。注意:即使我们是在特征图上生成的锚点,这些锚点最终是要映射回原始图片的尺寸(参考下图感受野的相关概念[^7])。

因为我们只用到了卷积和池化层,所以特征图的最终维度与原始图片是呈比例的。数学上,如果图片的尺寸是,那么特征图最终会缩小到尺寸为 和,其中 r 是次级采样率。如果我们在特征图上每个空间位置上都定义一个锚点,那么最终图片的锚点会相隔 r 个像素,在 VGG 中,,此处可以参考文章最后的文献[^6]。 所以,feature map上一点对应到原图的大小为的区域。

原始图片的锚点中心
在目标检测中,需要检测的目标形态大小各异,如果统一以固定大小的窗口进行检测,肯定会影响检测效果,降低精度。因此Faster R-CNN算法为每个滑动窗口位置配置了9个基准矩形框来适配各种目标。即,对于每张输入的特征图像的每一个位置,使用9种尺度的候选窗口:三种面积{, , },三种比例{1 : 1, 1 : 2, 2 : 1},目的是尽可能的将尺度大小不一的特定目标区域特征检测出来,并判断候选窗口是否包含感兴趣的目标。
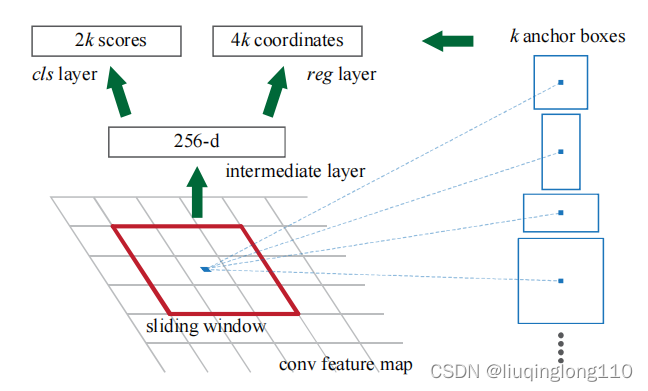
Anchor原理图(如上图所示)
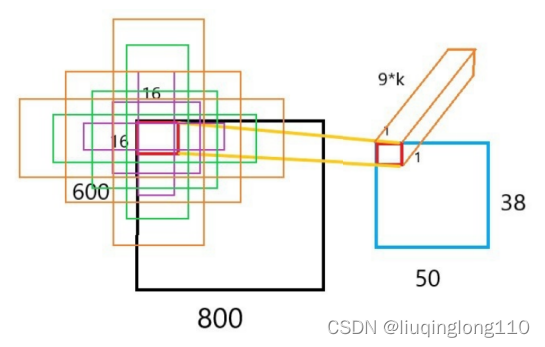
原始图片的锚点中心生成的9种候选框(如上图所示)
原始图片中所有anchor可视化(如上图所示)

左侧:锚点、中心:特征图空间单一锚点在原图中的表达,右侧:所有锚点在原图中的表达(如上图所示)
2)正负样本的定义[^8]
faster rcnn中正负样本是根据anchors的标定规则来生成的。
(1)正样本的生成:
如果某个anchor和其中一个GT的最大iou大于pos_iou_thr,那么该anchor就负责对应的GT;
如果某个GT和所有anchor的iou中最大的iou会小于pos_iou_thr,但是大于min_pos_iou,则依然将该anchor负责对应的gt。通过本步骤,可以最大程度保证每个GT都有anchor负责预测,如果还是小于min_pos_iou,那就没办法了,只能当做忽略样本了;
(2)负样本的生成:
如果anchor和GT的iou低于neg_iou_thr的,那就是负样本,其应该包括大量数目;
其余的anchor全部当做忽略区域,不计算梯度。
该最大分配策略,可以尽最大程度的保证每个GT都有合适的高质量anchor进行负责预测。
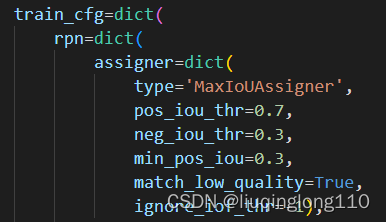
RPN中正负样本定义
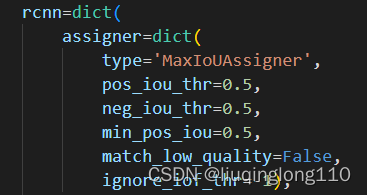
RCNN中正负样本定义
3)正负样本的采样
虽然上文中的最大分配策略可以区分正负样本和忽略样本,但是依然存在大量的正负样本不平衡问题。
解决办法可以通过正负样本采样或者loss上面一定程度解决,faster rcnn默认是需要进行正负样本采样的。 rpn head和rcnn head的采样器都比较简单,就是随机采样,阈值不一样而已。
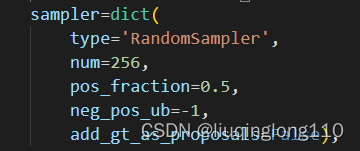
RPN head采样器
注意:RPN中的add_gt_as_proposals=False
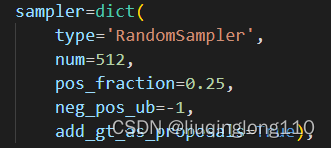
rcnn head采样器
注意:rcnn中的add_gt_as_proposals=True
dict函数中各个参数具体含义:
num表示采样后样本总数,包括正负和忽略样本。
pos_fraction表示其中的正样本比例。
neg_pos_ub表示正负样本比例,用于确定负样本采样个数上界,例如我打算采样1000个样本,正样本打算采样500个,但是可能实际正样本才200个,那么正样本实际上只能采样200个,如果设置neg_pos_ub=-1,那么就会对负样本采样800个,用于凑足1000个,但是如果设置为neg_pos_ub比例,例如1.5,那么负样本最多采样个,最终返回的样本实际上不够1000个。默认情况neg_pos_ub=-1。
由于rcnn head的输入是rpn head的输出,在网络训练前期,rpn无法输出大量高质量样本,故为了平衡和稳定rcnn训练过程,通常会对rcnn head部分添加gt作为proposal。因此,上述两个采样器还有一个参数add_gt_as_proposals。
3、SSD
论文:SSD: Single Shot MultiBox Detector
SSD是最典型的多尺度预测结构,是非常早期的网络。
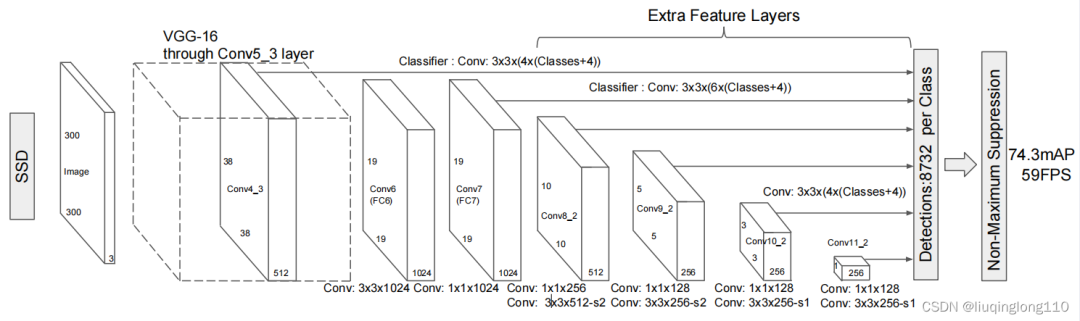
可以通过如下网络结构对比图,大致理解SSD解决多尺度问题的思路与其他网络的区别。
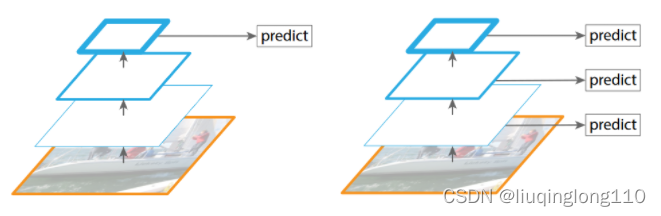
左侧:仅在一种尺度的特征图上进行检测,例如Faster rcnn。右侧:在多种尺度特征上进行检测,例如SSD。
1)SSD核心设计思路[^9]:
(1)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图(feature map),CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小。
下图所示,一个比较大的特征图和一个比较小的特征图,他们都用来做检测。这样做的好处是:比较大的特征图用来检测相对较小的目标,而小的特征图负责检测大目标,的特征图可以划分更多的单元,但是其每个单元的default box尺度比较小。
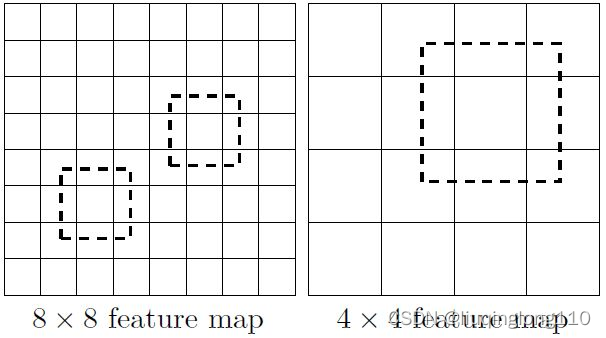
左侧:的特征图上设置尺寸小的先验框。右侧:的特征图上设置尺寸大的先验框
特别注意:上述两个特征图尺寸是不一样的,的尺寸比的尺寸大,但是,的特征图中每个小格子,即feature map cell的感受野都比小,即,每个小格子映射回原图时对应的图片区域。一块区域就可以看做一组特征。然后对这些特征进行分类和回归。
(2)采用卷积进行检测
SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为的特征图,只需要采用这样比较小的卷积核得到检测值。此处主要是与yolo最后采用全连接层的方式进行对比。
(3)设置先验框(default boxes)
SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框(default boxes),预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。
一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如下图所示,可以看到每个单元使用了4个不同的default boxes(SSD中不同尺度的特征图可以设置不同个数的先验框),图片中猫和狗分别采用最适合它们形状的先验框来进行训练,后面会详细讲解训练过程中的先验框匹配原则。
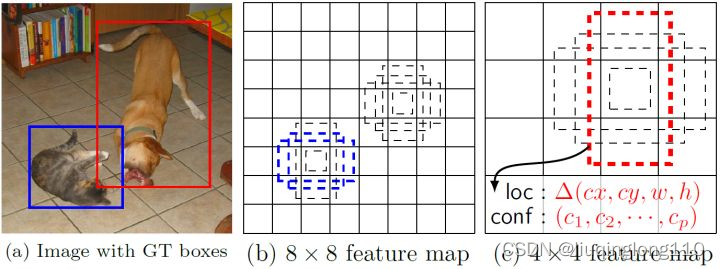
如上图所示,在不同尺度的特征图上设置不同尺度和长宽比的先验框
每一个feature map中的每一个小格子(cell)都包含多个default box,同时每个box对应loc(位置坐标)和conf(每个种类的得分)。
default box长宽比例默认有四个和六个:四个default box是长宽比(aspect ratios)为(1:1)、(2:1)、(1:2)、(1:1);六个则是添加了(1:3)、(3:1)。
为什么会有两个(1:1)呢?
这时候就要讲下论文中Choosing scales and aspect ratios for default boxes这段内容了。作者认为不同的feature map应该有不同的比例(一个大框一个小框,长宽比相同,但是不同feature map 相对于原图的尺寸比例不同)。这是什么意思呢?代表的是default box中这个1在原图中的尺寸是多大的。
(4)计算先验框min_sizes和max_sizes的方式
对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加。计算公式如下所示:
****即代表在300*300输入中的比例,表示第k层feature map上生成的先验框大小相对于图片的比例。
****代表的是特征图索引。
为当前的网络结构中可以生成先验框的feature map层数。特别注意:,因为一共有6个feature map,但是第一层(Conv4_3层)是单独设置的。
和代表的是第一层和最后一层所占的比例,比例的最小值和最大值,在ssd300中为0.2-0.9。
实际上是:对于第一个特征图Conv4_3,其先验框的尺度比例一般设置为 ,故第一层的。输入是300,故conv4_3的min_size=30。对于从第二层开始的特征图,则利用上述公式进行线性增加,然后再乘以图片大小,可以得到各个特征图的尺度为60、111、162、213、264。最后一个特征图conv9_2的size是直接计算的,。 以上计算可得每个特征的min_size和max_size,如下:
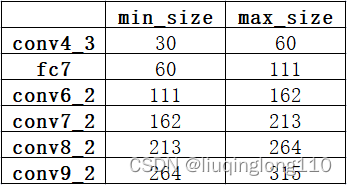
具体实现代码:ssd_pascal.py 下图注释中提到的博客:关于SSD默认框产生的详细解读
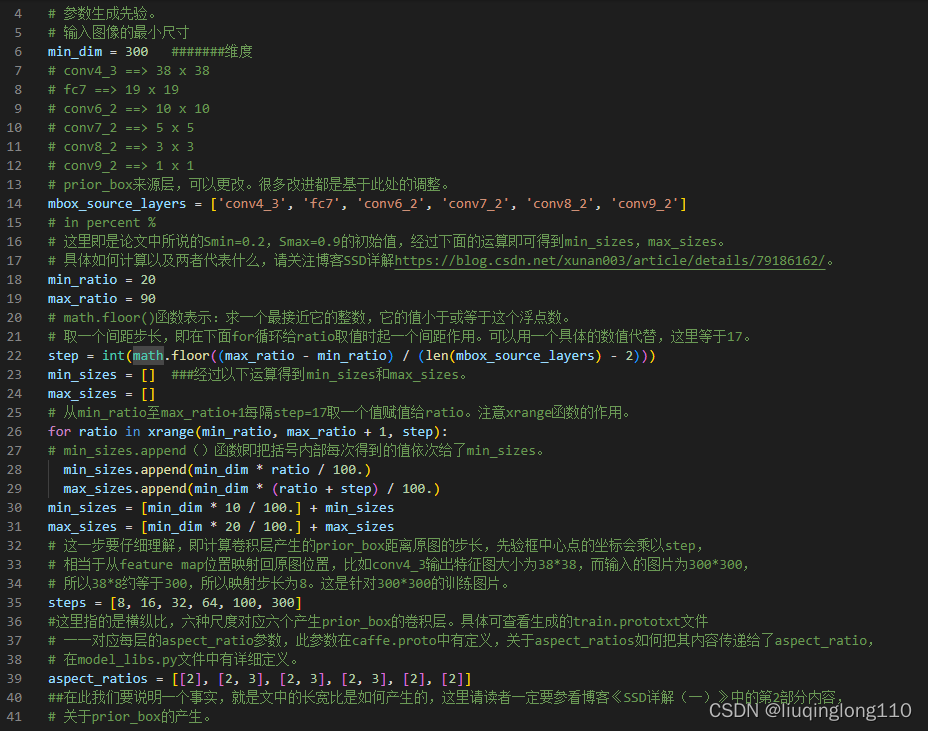
接下来,补充回答为什么default box的size有两个(1:1)[^9]?
作者在这有引入了一个,也就是每个特征图都设置了两个长宽比为1大小不同的正方形default box。有的小伙伴可能会有疑问,这有了则需要多出来一部分的啊,是的没错,最后一个特征图需要参考来计算,因此每个特征图(的每个cell)都有6个default box(aspect ratios),但是在实现时, Conv4_3,Conv10_2,Conv11_2仅仅使用4个先验框(default box),不使用长宽比为的先验框(default box)。作者的代码中就添加了两层,第一层取0.1,最后一层取1。
那么S怎么用呢?按如下方式计算先验框的宽高(这里的Sk是上面求得的各个特征图的先验框的实际size,不再是尺度比例):
ar代表的是之前提到的先验框default box(aspect ratios)比例,即
对于先验框default box中心点的值取值为:
其中i,j代表在feature map中的水平和垂直的第几格。
fk代表的是feature map的size。
每个单元的先验框中心点分布在各单元的中心。
(5)计算先验框的大小的方式
下图所示为每个cell生成4个先验框的方法,生成6个先验框的方式类似,只需要增加1:3和3:1两个比例的矩形框即可。
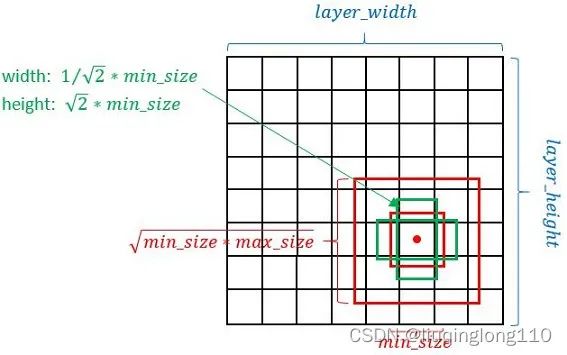
如上图所示,先验框计算方式
2)正负样本的定义
SSD采用的正负样本定义器依然是MaxIoUAssigner,但是由于参数设置不一样,故有了不同的解释。
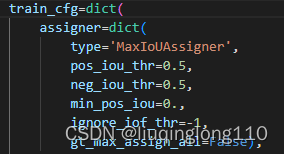
正负样本定义规则为[^2]:
(1)正样本的生成:
anchor和某个GT的最大iou大于0.5,则认为是正样本。
GT和所有anchor的最大iou值,如果大于0.0,则认为该最大iou anchor是正样本。
(2)负样本的生成:
anchor和所有GT的iou都小于0.5,则认为是负样本。
没有忽略样本,即每个GT一定会和某个anchor匹配上,不可能存在GT没有anchor匹配的情况。
3)正负样本的采样
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对于先验框还是太少了,所以负样本会很多。为保证正负样本尽量均衡,SSD采用了hard negative mining,先将每一个物体位置上对应 predictions(default boxes)是 negative 的 boxes 进行排序,按照先验框的confidence的大小。 选择最高的几个,保证最后 negatives、positives 的比例接近3:1。
4、FPN
论文:Feature Pyramid Networks for Object Detection
下图展示了4种利用特征的形式:(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。(b)像SPPnet,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
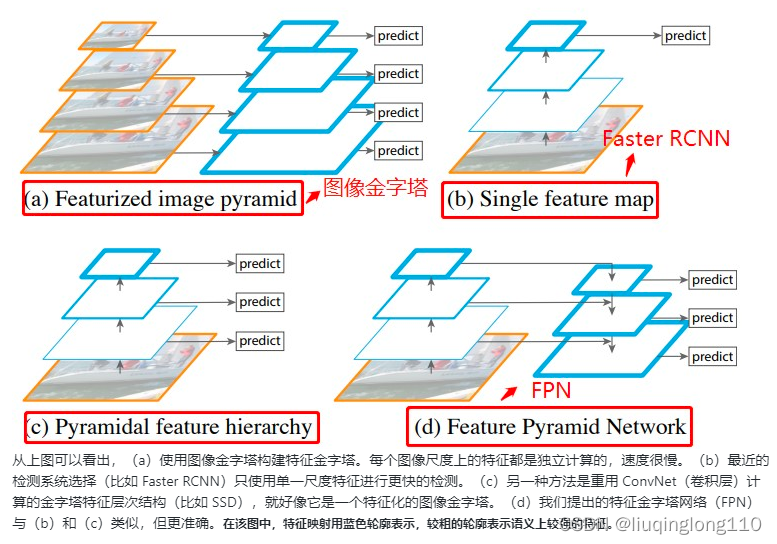
FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。通过高层特征进行上采样和低层特征进行自顶向下的连接,而且每一层都会进行预测。
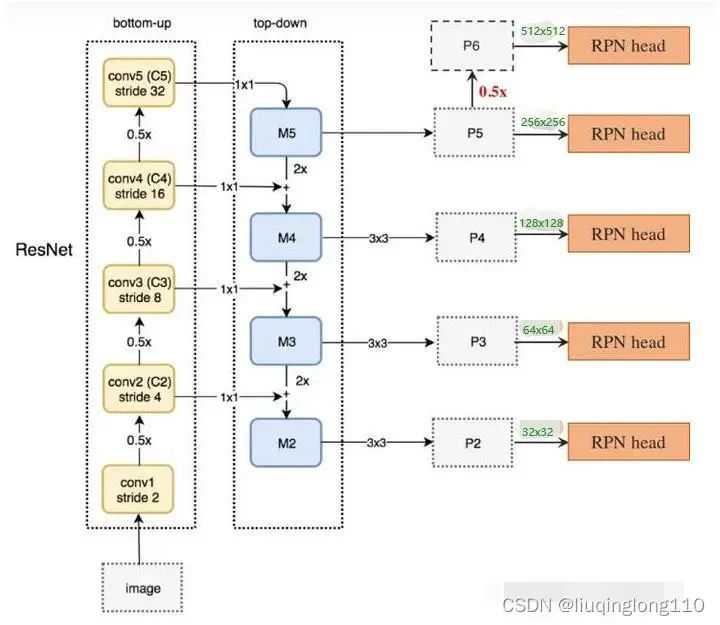
FPN算法大致结构:一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。下图中放大的区域就是横向连接,这里的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
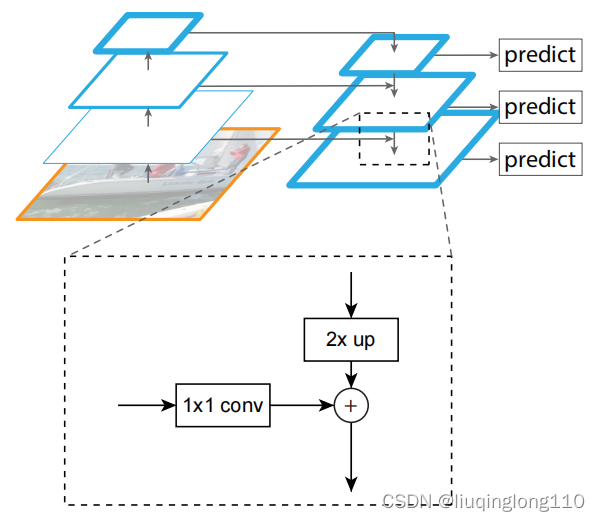
如上图所示,FPN+RPN结构
在横向连接中,采用的卷积核进行连接(减少特征图数量)。将FPN和RPN结合起来,那RPN的输入就会变成多尺度的feature map,那我们就需要在金字塔的每一层后边都接一个RPN head(一个卷积,两个卷积),如下图所示.其中,P6是通过P5下采样得到的。
1)设置先验框(default boxes)
在生成anchor的时候,因为输入是多尺度特征,就不需要再对每层都使用3种不同尺度的anchor了,所以在每一个scale层,都定义了不同大小的anchor。对于P2,P3,P4,P5,P6这些层,定义anchor的大小为、、、、,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor,如上图所示。
anchor的正负样本定义和Faster R-CNN中的定义相同,即如果某个anchor和GT有最大的IoU,或者IoU大于0.7,那这个anchor就是正样本,如果IoU小于0.3,那就是负样本。此外,需要注意的是每层的RPN head都参数共享的。
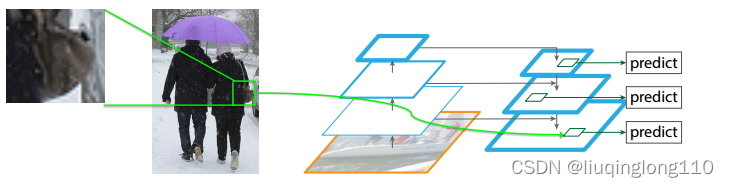
但是,生成的anchor(注意:此时的anchor已经经历了一轮筛选)如何确定映射到哪一个特征图上呢?这是有公式计算的,如下图:
表示映射到哪一层的作为特征层传入到ROI Pooling层中。是基准值,设置为4。和表示RPN给出的Region Proposal的宽和高。此处的224是在ImageNet上训练时resize的大小。
例如,和都是112,则(值做取整处理),对应P3特征层和Region Proposal传入到ROI Pooling,得到一个尺寸为的特征,再经过flatten之后输入到全连接层。
2)正负样本的定义
如1)所述,正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
5、FCOS
论文:FCOS: Fully Convolutional One-Stage Object Detection
本文提出一种基于像素级预测一阶全卷积目标检测(FCOS)来解决目标检测问题,类似于语义分割。目前大多数先进的目标检测模型,例如RetinaNet、SSD、YOLOv3、Faster R-CNN都依赖于预先定义的锚框。相比之下,本文提出的FCOS是anchor free,而且也是proposal free,就是不依赖预先定义的锚框或者提议区域。通过去除预先定义的锚框,FCOS完全的避免了关于锚框的复杂运算,例如训练过程中计算重叠度,而且节省了训练过程中的内存占用。更重要的是,本文避免了和锚框有关且对最终检测结果非常敏感的所有超参数。由于后处理只采用非极大值抑制(NMS),所以本文提出的FCOS比以往基于锚框的一阶检测器具有更加简单的优点[^10]。
FCOS的骨架和neck部分是标准的resnet+FPN结构,和Retinanet完全相同。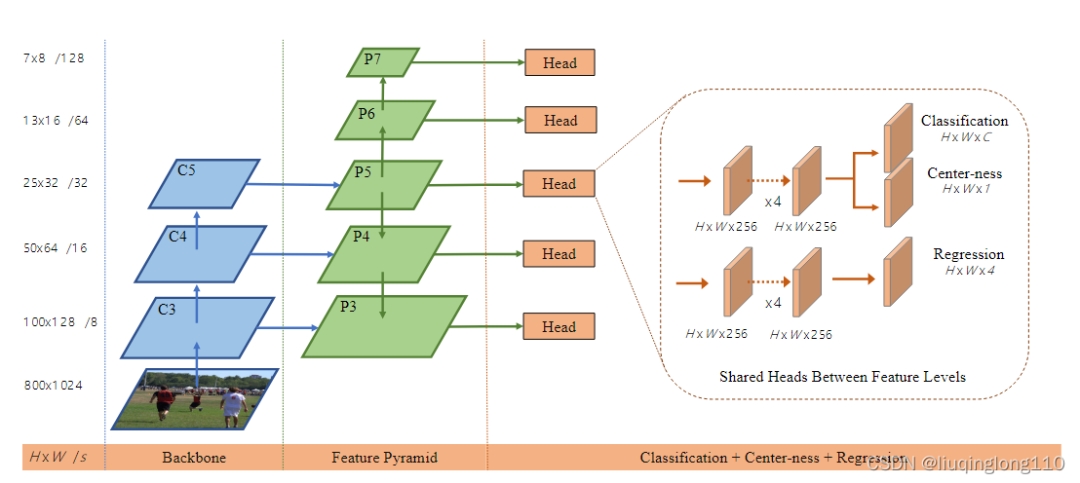
我们仅仅考虑head部分。除去center-ness分支,则可以看出和retinanet完全相同。
1)锚框(anchor-based)缺点
超参数设置难度大:检测表现效果对于锚框的尺寸、长宽比、数目非常敏感,因此锚框相关的超参数需要仔细的调节。
anchor的设置缺乏灵活性:锚框的尺寸和长宽比是固定的,因此,检测器在处理形变较大的候选对象时比较困难,尤其是对于小目标。预先定义的锚框还限制了检测器的泛化能力,因为,它们需要针对不同对象大小或长宽比进行设计。
容易产生正负样本不平衡问题:为了提高召回率,需要在图像上放置密集的锚框。而这些锚框大多数属于负样本,这样造成了正负样本之间的不均衡。
计算量大:大量的锚框增加了在计算交并比时计算量和内存占用。
2)正负样本的定义
作为Anchor-free的方法,FCOS直接对feature map中每个位置对应原图的边框都进行回归,如果位置 (x,y) 落入任何真实边框,就认为它是一个正样本,它的类别标记为这个真实边框的类别[^11]。可以理解为他是基于物体的一个key point点进行回归的。在实际的anchor-free中也会遇到一些问题,为了解决这些问题,FCOS做了如下工作:
1)为了解决anchor-free的方式在真实边框重叠带来的模糊性和低召回率(不像anchor-based可以有多重不同尺寸的anchor),FCOS采用类似FPN中的多级检测,就是在不同级别的特征层检测不同尺寸的目标。
2)为了解决距离目标中心较远的位置产生很多低质量的预测边框,FCOS提出了一种简单而有效的策略来抑制这些低质量的预测边界框,而且不引入任何超参数。具体来说,FCOS添加单层分支,与分类分支并行,以预测"Center-ness",可以这这个理解成为一个度量值,于中心距离的一个度量值,与中心点较远,则度量值较低,与中心点越近,度量值越高,以此来让置信度更高的像素产生更高的贡献。
正负样本匹配方式的实现:
1、分配目标给哪一层预测。 根据目标的尺寸将目标分配到不同的特征层上进行预测。
具体实现:引入了min_size和max_size,具体设置是0, 64, 128, 256, 512和无穷大。例如,对于输出的第一个预测层而言,其stride=8,负责最小尺度的物体,对于该层上面的任何一个点,如果有GT bbox映射到特征图上,满足0 < max(中心点到4条边的距离) < 64,那么该GT bbox就属于第1层负责,其余层也是采用类似原则。
总结来说就是第1层负责预测尺度在0~ 64范围内的GT,第2层负责预测尺度在64~128范围内的GT,以此类推。通过该分配策略就可以将不同大小的GT分配到最合适的预测层进行学习。
2、确定正负样本区域。 对于每一层feature map,设定一个以GT中心为圆心,固定半径的圆,如果像素落在该圆内,则标记为positive样本,否则为negative。
具体实现:通过center_sample_radius**(基于当前stride参数)**参数,确定在半径范围内的样本都属于正样本区域,其余区域作为负样本。默认配置center_sample_radius=1.5。例如,第1层的stride=8,那么在该输出层上,对于任何一个GT,基于GT bbox中心点为起点,在半径为个像素范围内点都属于正样本区域。
3、centerness找到目标的中心点。 为了使靠近GT中心的像素能学到更多的信息,故给予他更高的权重,而离GT中心越远的点,贡献则递减。
具体实现:使得离目标中心越近,输出值越大,反之越小。Center-ness的定义如下公式:
可见最中心的点的centerness为1,距离越远的点,centerness的值越小。在推测的时候直接将中心度分数centerness乘到分类分数上,将偏离很远的检测框分值进行惩罚。
center-ness本质就是对正样本区域按照距离GT bbox中心来设置权重,这是作者的做法,还有很多类似做法,不过有些是在Loss上面做文章,例如在ce loss基础上乘上一个类似预center-ness的权重来实现同样效果。
center-ness效果如下:
3)总结:
FCOS采用物体center的匹配方式来进行回归,在正负样本匹配的时候,采用了top-k的策略进行匹配,并且使用centerness来对不同距离的匹配样本进行不同程度的惩罚,以达到资源倾斜于贡献最佳者的目的。
-
数据
+关注
关注
8文章
7221浏览量
90112 -
网络
+关注
关注
14文章
7643浏览量
89572
原文标题:目标检测算法是如何生成正负样本的(一)
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
百度飞桨PP-YOLOE ONNX 在LabVIEW中的部署推理(含源码)

【米尔RK3576开发板评测】+项目名称百度飞桨PP-YOLOE
不同种类激光在医疗行业的应用分析
介绍一篇实时性好准确率高的论文:CornerNet-Lite

卷积神经网络 物体检测 YOLOv2
YOLO的另一选择,手机端97FPS的Anchor-Free目标检测模型NanoDet
嵌入式AI快讯:移植ncnn到RISC-V TF Object Detection支持TF2

不同种类电容的失效分析资料下载

基于深度学习的发动机零件检测算法
解读目标检测中的框位置优化
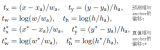
CVPR2020 | MAL:联合解决目标检测中的定位与分类问题,自动选择最佳anchor
基于AX650N部署DETR
无Anchor的目标检测算法边框回归策略

基于Yolov5+图像分割的车牌实时检测识别系统





 工商网监
工商网监
评论