 深度学习——如何用LSTM进行文本分类
深度学习——如何用LSTM进行文本分类
简介
主要内容包括
如何将文本处理为Tensorflow LSTM的输入
如何定义LSTM
用训练好的LSTM进行文本分类
代码
导入相关库
#coding=utf-8
importtensorflowastf
fromtensorflow.contribimportlearn
importnumpyasnp
fromtensorflow.python.ops.rnnimportstatic_rnn
fromtensorflow.python.ops.rnn_cell_implimportBasicLSTMCell
数据
# 数据
positive_texts=[
"我 今天 很 高兴",
"我 很 开心",
"他 很 高兴",
"他 很 开心"
]
negative_texts=[
"我 不 高兴",
"我 不 开心",
"他 今天 不 高兴",
"他 不 开心"
]
label_name_dict={
0:"正面情感",
1:"负面情感"
}
配置信息
配置信息
embedding_size=50
num_classes=2
将文本和label数值化
# 将文本和label数值化
all_texts=positive_texts+negative_textslabels=[0]*len(positive_texts)+[1]*len(negative_texts)
max_document_length=4
vocab_processor=learn.preprocessing.VocabularyProcessor(max_document_length)
datas=np.array(list(vocab_processor.fit_transform(all_texts)))
vocab_size=len(vocab_processor.vocabulary_)
定义placeholder(容器),存放输入输出
# 容器,存放输入输出
datas_placeholder=tf.placeholder(tf.int32, [None, max_document_length])
labels_placeholder=tf.placeholder(tf.int32, [None])
词向量处理
# 词向量表
embeddings=tf.get_variable("embeddings", [vocab_size, embedding_size],initializer=tf.truncated_normal_initializer)
# 将词索引号转换为词向量[None, max_document_length] => [None, max_document_length, embedding_size]
embedded=tf.nn.embedding_lookup(embeddings, datas_placeholder)
将数据处理为LSTM的输入格式
# 转换为LSTM的输入格式,要求是数组,数组的每个元素代表某个时间戳一个Batch的数据
rnn_input=tf.unstack(embedded, max_document_length,axis=1)
定义LSTM
# 定义LSTM
lstm_cell=BasicLSTMCell(20,forget_bias=1.0)
rnn_outputs, rnn_states=static_rnn(lstm_cell, rnn_input,dtype=tf.float32)
#利用LSTM最后的输出进行预测
logits=tf.layers.dense(rnn_outputs[-1], num_classes)
predicted_labels=tf.argmax(logits,axis=1)
定义损失和优化器
# 定义损失和优化器
losses=tf.nn.softmax_cross_entropy_with_logits(
labels=tf.one_hot(labels_placeholder, num_classes),
logits=logits
)
mean_loss=tf.reduce_mean(losses)
optimizer=tf.train.AdamOptimizer(learning_rate=1e-2).minimize(mean_loss)
执行
withtf.Session()assess:
# 初始化变量
sess.run(tf.global_variables_initializer())
训练# 定义要填充的数据
feed_dict={
datas_placeholder: datas,
labels_placeholder: labels
}
print("开始训练")
forstepinrange(100):
_, mean_loss_val=sess.run([optimizer, mean_loss],feed_dict=feed_dict)
ifstep%10==0:
print("step ={}tmean loss ={}".format(step, mean_loss_val))
预测
print("训练结束,进行预测")
predicted_labels_val=sess.run(predicted_labels,feed_dict=feed_dict)
fori, textinenumerate(all_texts):
label=predicted_labels_val[i]
label_name=label_name_dict[label]
print("{}=>{}".format(text, label_name))
审核编辑 黄昊宇
-
LSTM
+关注
关注
0文章
60浏览量
3874
发布评论请先 登录
相关推荐
pyhanlp文本分类与情感分析
NLPIR平台在文本分类方面的技术解析
基于apiori算法改进的knn文本分类方法
运用多种机器学习方法比较短文本分类处理过程与结果差别
textCNN论文与原理——短文本分类
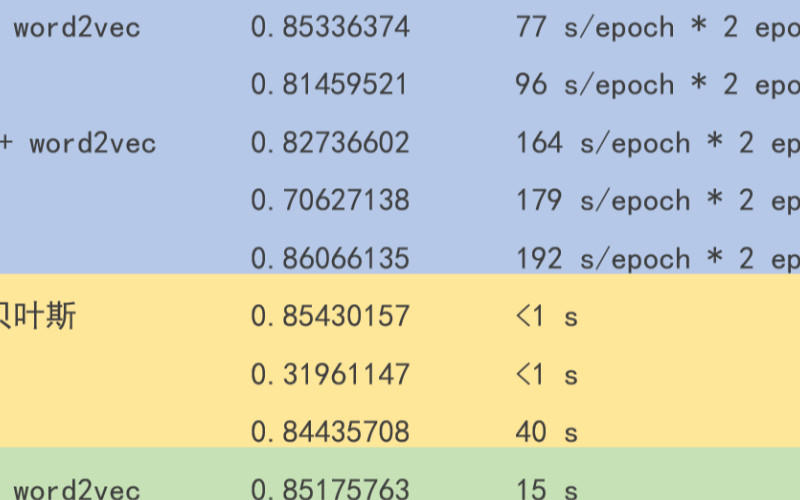
文本分类的一个大型“真香现场”来了
基于深度神经网络的文本分类分析

集成WL-CNN和SL-Bi-LSTM的旅游问句文本分类算法

融合文本分类和摘要的多任务学习摘要模型






 工商网监
工商网监
评论