 基于BIO序列标注的方法和基于片段的图解析方法
基于BIO序列标注的方法和基于片段的图解析方法
主要贡献:片段语义角色标注目前的两种主流方法分别为:基于BIO序列标注的方法和基于片段的图解析方法。该论文提出一种新的基于词的图解析方法,将片段图解析方法的搜索空间从O(n^3)降低到O(n^2),从而大幅度提升了模型的训练和解码效率,且性能超过了前人结果。
-01-
摘要
该论文的出发点是将端到端基于片段的(span-based)语义角色标注(SRL)转换为基于词的(word-based)图解析(graph parsing)任务。其中主要的挑战是如何在词级别上表示片段信息。该论文通过借鉴中文分词(CWS)和命名实体识别(NER)的研究成果,提出了四种不同的图表示方案,即BES、BE、BIES和BII。此外,根据SRL结构的约束,作者还提出了一个简单的约束Viterbi过程,以保证输出图的合法性。作者在两个广泛使用的CoNLL05和CONLL12基准数据集上进行了实验。结果表明,在端到端和谓词给定的所有设置下,在没有和有预训练语言模型的情况下,该论文提出的基于word的图解析方法都取得了比以前方法更好的性能。更重要的是,该论文提出的方法推理速度很快,在不使用预训练模型(PLMs)的情况下,每秒可以解析669个句子;在使用PLMs的情况下,每秒可以解析252个句子。
-02-
背景介绍
语义角色标注是自然语言处理(NLP)中一个必不可少的任务,它使用谓词-论元的结构去表示一个浅层的句子语义。SRL结构能够帮助解决很多下游NLP任务,比如机器翻译和问答。
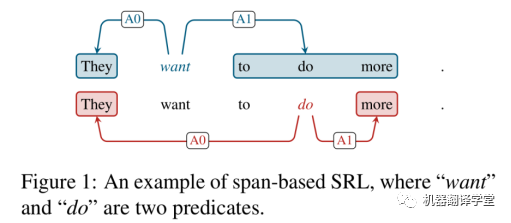
SRL存在两个形式,分别基于词(word-based)和片段(span-based),划分依据取决于一个论元是包含单个单词还是一个片段。对比基于word的SRL来说,基于span的SRL是更加复杂的。上图1也展示了一个基于span的样例,语义角色被边的标签所划分,比如施事(agent)“A0”和受事(patient)“A1”。
随着深度学习的发展,尤其是预训练模型的提出,基于span的SRL近些年也取得了巨大的进展,吸引了研究人员们的关注。该工作主要关注端到端基于span的SRL任务,并提出了一个模型可以同时识别输入句子中的谓词和论元。这里端到端是指一个句子中所有的谓词和论元都是通过单个模型同时推断得到的。
基于span的图解析方法直接把所有的词片段考虑为候选论元节点,并将他们链接到谓词节点上。然而,对于一个句长为n的句子,计算候选谓词和候选论元的复杂度分别为O(n)和O(n^2),从而导致了一个非常大的搜索空间O(n^3),使得这种方法效率较低。在以往的一些工作,通常使用启发式剪枝技术来提高效率。
针对端到端基于span的 SRL,该论文首次提出了一种基于word的图解析方法。由于图网络中的每个节点只对应于单个单词,关键的挑战是如何在基于单词的图中表示基于span的论元。一旦解决了这个问题,就可以在现有的基于单词的图解析模型基础上构建解析器。该工作的主要贡献点如下:
1: 提出了一种新的基于word的图解析方法,可以用于端到端基于span的SRL。通过简单的修改,该方法也可以应用于谓词给定的设置。
2: 借鉴中文分词(CWS)和命名实体识别(NER)的研究思路,作者提出了4个图方案,其中BES方案稳定优于其他方案。
3: 同时,由于图解析模型可能会输出不合法的图,不能正确地转换为SRL结构。为了解决这一问题,作者提出了一个简单的约束Viterbi过程(constrained Viterbi procedure),用于非法图的后处理。
4: 作者在CoNLL05和CoNLL12基准数据集上进行了实验。在端到端和谓词给定的所有设置下,无论是否使用PLMs,该论文提出的方法都能取得比以前方法更好的性能。并且模型推断速度要快得多,在不使用PLMs和使用PLMs的情况下,每秒分别可以分析669/252个句子。
-03-
方法
3.1 图构造方案
该工作把端到端基于span的SRL看作是一个基于word的图解析任务。但是所面临的一个关键挑战是需要设计一个合适的图方案使得在不产生歧义的情况下,让所有的谓词和基于span的论元能够在同一个图中被正确表示。并且,这个图在没有性能损失的情况下,也可以被转换成其对应SRL结构。方案具体设计如下所述。
3.1.1 SRL-Graph转换
该工作设计了四种不同的方案来将基于span的SRL结构转换为基于word的图。其基本的想法是连接论元的词语到其对应的谓词,并且标记出语义角色标签和词在论元中的位置。具体来讲,该工作在句子的开头添加一个伪“Root”节点,并且把所有的谓词连接到这个节点,其所构造的边为“PRD”。这样的设计能够实现通过一个端到端的方式直接预测谓词和论元。通过借鉴CWS和NER的思想,该工作提出两种论元到其对应谓词的策略:boundary-attach和all-attach。boundary-attach表示仅仅连接论元开头和结尾的词语到对应的的谓词上。而all-attach表示连接论元中所有的单词到其对应谓词。该工作又分别为这两种策略设计了两个连接的方案,对应如下:
Boundary-attach:BES和BE
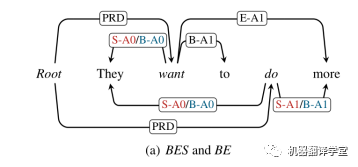
如上图所示,对应了该工作所设计的boundary-attach的两种方案BES和BE,分别为红色和蓝色。当论元包含多个单词的时候,两种方案均只需要把论元的开头和结尾的单词连接到对应谓词,并使用“B-r”和“E-r”作为对应的边标签,其中r表示这个原始的语义角色标签。
当论元只有一个单词的时候, BE方案仅仅使用“B-r”作为标签。而为了区分论元包含多个词和单个词的情况,BES方案使用额外的“S-r”作为标签。
All-attach: BIES 和 BII
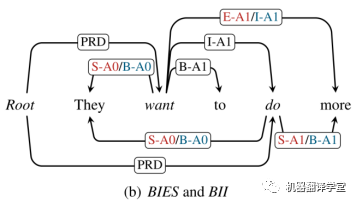
如上图所示,对应了该工作所设计的all-attach的两种方案BIES和BII,分别为红色和蓝色。在这个BII方案中,第一次词被标记为“B-r”,然后后面的词语被标记为“I-r”。对于BIES方案,其开头词语和结尾词语的标记方法和BES类似,仍为“B-r”和“E-r”,中间的单词被标记为“I-r”。
3.1.2 SRL-Graph恢复
在评估阶段,输入一个句子,图解析模型根据选择的方案,输出一个最优的图。这之后的主要工作是如何将这个图恢复到对应的SRL结构。
假如该输出的图是没有标签冲突的,那么可以直接进行恢复。比如对应BES方案,图中“Root”节点的全部孩子节点(word)可以被认为是谓词。然后对应每一个谓词,使用边标注来恢复所有其对应的论元。一个论元对应成对的标签,比如“B-A0”和“E-A0”,或者是一个单独的标签,比如“S-A0”。
但是在实际过程中,保证被输出图的合法性是非常困难的,往往并不能直接根据上述的规则将图恢复为SRL结构。为了解决这个问题,该工作基于一个受约束的Viterbi解码方法提出了一个简单并且高效的后处理方法,具体描述在章节3.3中。
3.2 模型
基于上面提出的方案,我们可以将基于span的作为基于word的图解析任务进行处理。该论文的模型框架包括两个阶段: 1)预测所有边 2)为边分配标签。
3.2.1 编码器
双向LSTM:模型的输入单词w_{i}是由三部分组成,
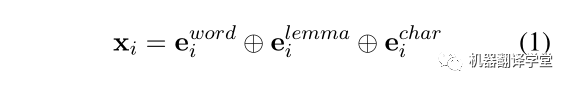
从左至右依次是词向量、引理向量(lemma embedding)和char LSTM表示向量。将送入三层BiLSTM编码器中,计算得到每个单词的表示。
预训练模型:该论文也尝试分别使用ELMo和BERT两个预训练模型作为编码器。其中,使用ELMo三层输出的和作为表示,使用BERT最后四层输出的和作为表示。
3.2.2 边预测
在语义依存图解析(SDGP)中,边的预测问题被看作是0/1的二分类问题。这里的1代表在给定的单词对之间存在一条边,0则代表给定的单词对之间不存在边。当计算得到的存在边的概率大于0.5时,就认为两个单词之间存在边。
对于该论文提出的方法来说,仅仅使用一阶子树是不够的,原因在于一阶模型做了强假设,即边是相互独立的,因此在计算logits的时候只需要关注当前两个单词之间的信息。然而,在该论文的例子中,图中的边通常具有很强的相关性。例如,在BE方案中,一条“B-*”的边通常调用一条“E-*”的边,反之亦然,以形成一个完整的论元。所以该论文通过增加二阶子树的三种情况将模型从一阶扩展至二阶。该论文使用MFVI(mean field variational inference,平均场变分推断)来计算logits。(注:这部分内容读者可以参考论文《Second-order semantic dependency parsing with end-to-end neural networks》(https://arxiv.org/pdf/1906.07880.pdf);一阶、二阶子树参考下图例子。
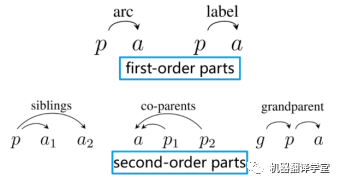
(图片源自【王新宇- Second-Order Semantic Dependency Parsing with End-to-End Neural Networks】 https://www.bilibili.com/video/BV1bE411f7b9))
logits的计算分成两部分:第一部分是一阶分数s(i,j),使用两个MLP和BiAffine计算得到。第二部分是二阶分数,使用三个MLP和TriAffine计算得到。如下图所示。
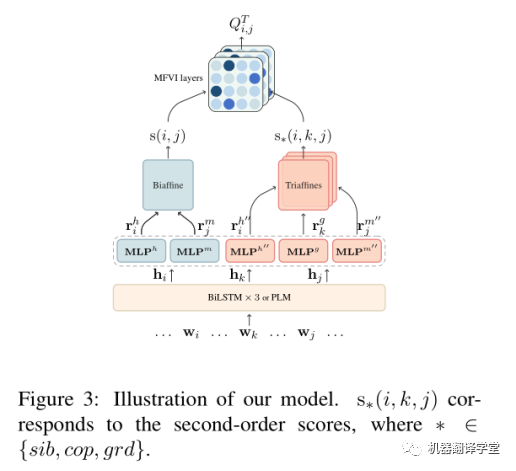
有了一阶和二阶分数之后,再使用MFVI方法迭代聚合得到最终的和。(注:MFVI的迭代计算过程可以参考这个视频(https://www.bilibili.com/video/BV1bE411f7b9))
3.2.3标签预测
类似于计算边的分数,该论文使用两个MLP和多个BiAffine来计算标签分数。每一个标签的分数都由一个独立的BiAffine计算得到。
3.2.4模型训练
整个模型的损失由边预测和标签预测两个模块组成,如下所示.给定一句话X和对应的真实答案图G,C代表X全连接的图,CG代表不正确的边的集合。第一个公式计算边预测的损失,其含义为让模型预测出正确边概率更大的同时,让模型预测错误的边的概率更小。第二个公式计算标签预测的损失。
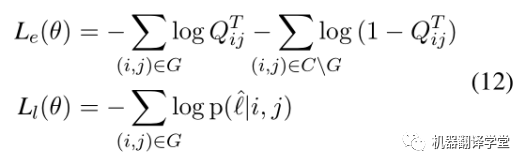
最后,对两个损失通过超参λ加权,这里λ= 0.06。
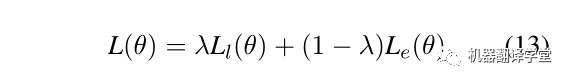
3.3冲突消除
在使用图解析模型预测出结果后,该工作使用一个简单的过程检查是否生成图是合法的。具体操作为,对于每一个谓词,首先扫描这个谓词的所有边从左到右。例如,在这个BES方案下,一个“B-*”边后面必须是一个“E-*”边;“S-*”边和“E-*”后面可以是一个“B-*”边,或者是一个“S-*”边。假如该生成图是合法的,可以直接使用前面章节中所描述的过程将其恢复成一个SRL结构。
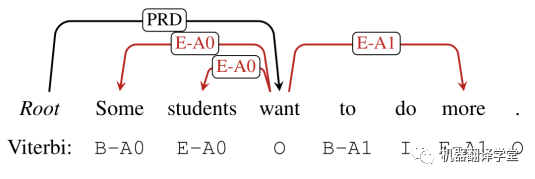
然而,在实际中,所生成图有可能会包含冲突。如上图所示的一个例子,红色的边包含了冲突关系。如果两条边都被标记为“E-*”,其将不可能恢复为相应的论元。另外一个冲突为,仅仅存在一个单独的边标记“B-*”或“E-*”,比如上图中的“E-A1”。
约束Viterbi
该工作使用一个约束解码方法来解决对应的冲突。在恢复一个论元的过程中,如果发生冲突,则重新标记句子中所有的谓词。但是,将约束Viterbi应用于SDGP框架中并不简单。
拿BES方案举例来说(其他方案对应的处理过程也是类似的),在第一阶段中,表示这个该边在最终图中存在的概率;但是在第二阶段中,表示这个边被标记为的概率。可以看出没有包含“I”和“O”,二者分别表示这个词分别在一个论元或者不在任何论元中,在这个序列标注过程中它们是不可缺少的。
为了解决该问题,该工作添加两个伪标签“O/I”到标签集合中,并重新分配标签的概率分布:
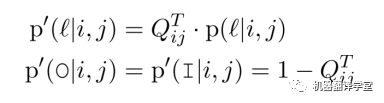
这里,是类似“B-A0”这些标准标签的概率。由于“O”和“I”意味着没有边指向这个词,所以和的概率相同,但是“I”有一个额外的含义:左边有一个不成对的“B-*”。因此,可以通过控制转换矩阵来解决冲突。
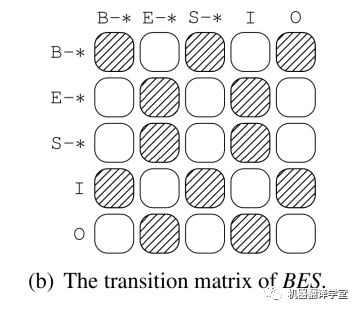
如上图,不允许从“E-*”到“E-*”的转换。所以上述例子中的“Some”和“students”的标签要重新进行标记为“B-A0”和“E-A0”。最终,得到了语义角色为“A0”的论元span“Some students”。
-04-
实验
该论文在CoNLL05和CoNLL12两个数据集上进行了实验。作者首先在CoNLL05数据集上面测试了四种构建方案。结果如下表所示,从整体上来看,我们可以得到结论:BES > BE > BIES > BII。
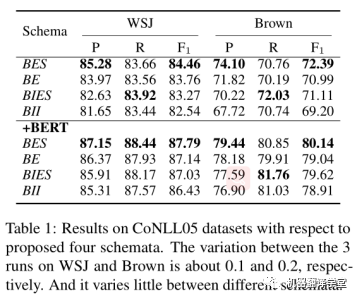
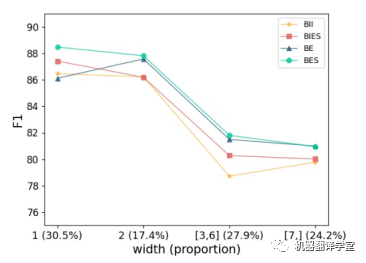
如下图所示,作者根据论元的宽度将论元分为四类,给出了每个类别在真实答案数据中的比例,并报告每一类的F1值。首先,可以看到BES和BIES在1-width论元上要好得多。这表明,用“S-r”单独表示宽度为1的论元是必要的。然后,可以发现BE和BES在包含多个单词的论元上比BII和BIES表现更好。我们知道BE和BES是边界附加策略的结果,它更关注边界信息。因此,可以得出结论,边界信息对多词论元的识别更有帮助。
同时,作者还测试了该论文所提方法与其他方法推理速度的对比,结果如下表所示。该论文所提出的方法相比之前基于span的SRL模型,推理效率得到大幅度提高。

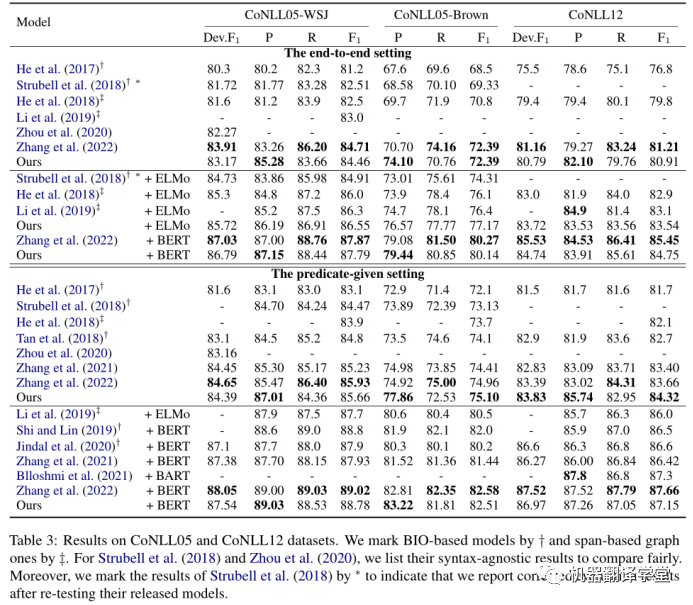
最后,作者还将该论文的方法分别在CoNLL05和CoNLL12两个数据集上面与其他同类型方法进行对比。结果如下表所示。
-05-
总结
该论文提出了四种新的图表示方案,用于将原始的基于span的SRL结构转换为基于word的图。基于此方案,该论文将基于span的SRL转换为一个基于word的图解析任务,并得到了一个更快更准的解析器。此外,作者还提出了一种简单的基于约束Viterbi的后处理方法来处理输出图中的冲突。实验表明,该论文提出的解析器:1)相比之前的解析器效率大幅度提高,每秒可以解析600多个句子;2)在CoNLL05和CoNLL12数据集上的性能始终优于之前的结果。对四种方案的深入对比表明,边界信息在识别论元时起着重要作用。此外,区分单词论元和多词论元也可以提高最终的性能。这些发现可能有助于研究人员在未来从新的角度思考SRL。
-
BIO
+关注
关注
0文章
6浏览量
9386 -
数据集
+关注
关注
4文章
1209浏览量
24799 -
nlp
+关注
关注
1文章
489浏览量
22086 -
训练模型
+关注
关注
1文章
36浏览量
3883
原文标题:COLING'22 Best Paper | 苏大提出:又快又准的端到端跨语义角色标注作为基于词的图解析
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
PAD贴片电阻识别标注方法
科学数据时间序列的预测方法
DNA片段拼接中的预归并重复序列屏蔽方法
基于运行序列的软件故障诊断方法
AutoCAD内常用术语的自动标注方法
新闻图像人脸标注方法
NLP:序列标注
汽车电路图的标注及阅读方法
基于强化学习的壮语词标注方法
基于序列标注的实体识别所存在的问题
焊接符号标注实例及方法





 工商网监
工商网监
评论