 使用张量板进行机器学习模型分析
使用张量板进行机器学习模型分析
这些模型针对特定数据集进行了训练,并经过准确性和处理速度的验证。在部署之前,开发人员需要评估 ML 模型,并确保其满足特定的阈值并按预期运行。有很多实验可以提高模型性能,在设计和训练模型时,可视化差异变得至关重要。TensorBoard有助于可视化模型,使分析变得不那么复杂,因为当人们可以看到问题所在时,调试变得更加容易。
训练 ML 模型的一般做法
一般的做法是使用预先训练的模型并执行迁移学习,以便为类似的数据集重新训练模型。在迁移学习期间,神经网络模型首先在类似于正在解决的问题上进行训练。然后,在针对感兴趣的问题进行训练的新模型中,将使用训练模型中的一个或多个层。
大多数情况下,预训练模型以二进制格式出现,这使得获取内部信息并立即开始工作变得困难。从组织的业务角度来看,拥有一些工具来深入了解模型以减少项目交付时间表是有意义的。
有几个可用选项可用于获取模型信息,例如层数和相关参数。“模型摘要”和“模型绘图”是基本选项。这些选项非常简单,考虑到很少的实现行,并提供非常基本的详细信息,如层数,层类型以及每层的输入/输出。
但是,模型摘要和模型图对于以协议缓冲区的形式了解任何大型复杂模型的每个细节并不那么有效。在这种情况下,使用张量板,张量流提供的可视化工具更有意义。考虑到它提供的各种可视化选项,如模型,标量和指标(训练和验证数据),图像(来自数据集),超参数优化等,它非常强大。
用于可视化自定义模型的模型图
此选项尤其有助于以协议缓冲区的形式接收自定义模型,并且需要在进行任何修改或训练之前了解它。如下图所示,连续 CNN 的概览在电路板上可视化。每个块代表一个单独的图层,选择其中一个将在右上角打开一个包含输入和输出信息的窗口。
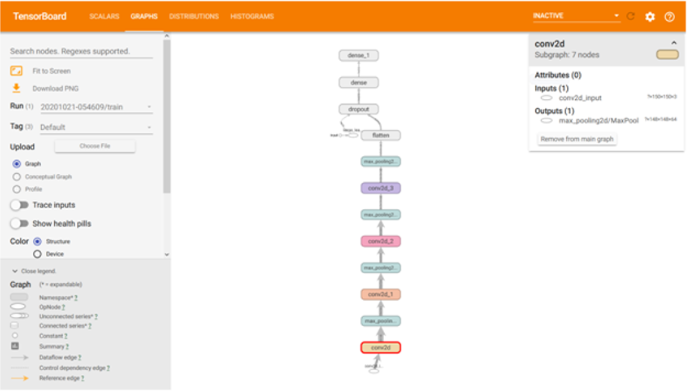
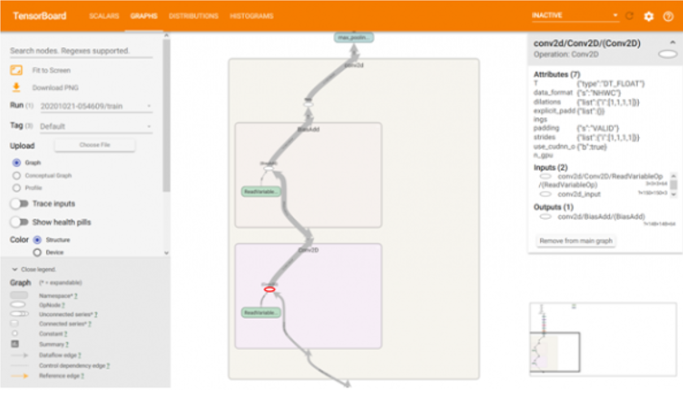
如果需要进一步的信息,关于各个块内部有什么,可以简单地双击块,这将展开块并提供更多详细信息。请注意,一个块可以包含一个或多个可以逐层扩展的块。在选择任何特定操作后,它还将提供有关相关处理参数的更多信息。
用于分析模型训练和验证的标量和指标
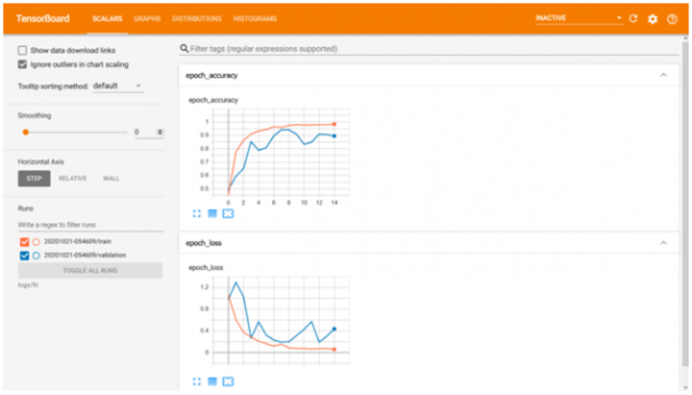
机器学习的第二个重要方面是分析给定模型的训练和验证。从精度和速度的角度来看,性能对于使其适用于现实生活中的实际应用非常重要。在下图中,可以看出模型的准确性随着 epoch/迭代次数的增加而提高。如果训练和测试验证不符合标准,则表明某些事情不对劲。这可能是欠拟合或过拟合的情况,可以通过修改图层/参数或改进数据集或两者来纠正。
图像数据,用于可视化数据集中的图像
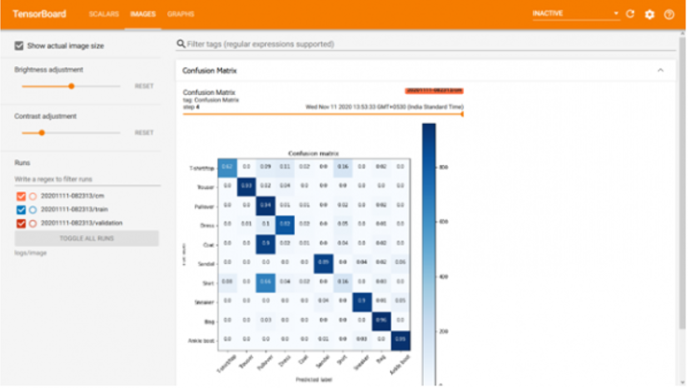
顾名思义,它有助于可视化图像。它不仅限于可视化数据集中的图像,而且还以图像的形式显示混淆矩阵。此矩阵指示检测各个类的对象的准确性。如下图所示,模特将外套与套头衫混淆。为了克服这种情况,建议改进特定类的数据集,以便将可区分的特征提供给模型,以便更好地学习,从而提高准确性。
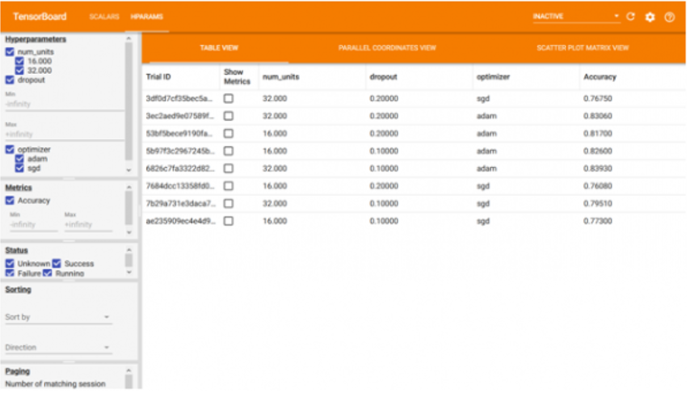
超参数调优以实现所需的模型准确性
模型的准确性取决于输入数据集、层数和相关参数。在大多数情况下,在初始训练期间,精度永远不会达到预期的精度,并且除了数据集之外,还需要使用层数,层类型,相关参数。此过程称为超参数优化。
在此过程中,提供了一系列超参数供模型选择,并且使用这些参数的组合运行模型。每个组合的准确性都记录在电路板上并可视化。它纠正了手动训练模型时会消耗的精力和时间,用于每个可能的超参数组合。
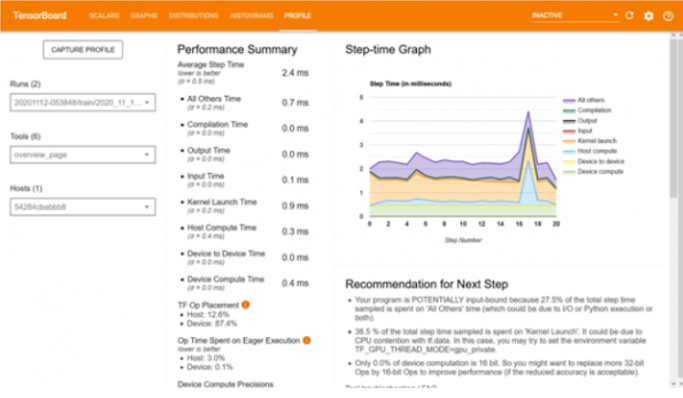
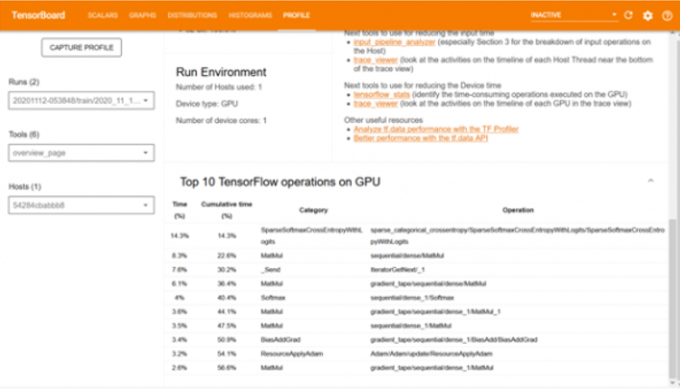
用于分析模型处理速度的分析工具
除了准确性之外,处理速度也是任何模型的一个同样重要的方面。有必要分析单个块消耗的处理时间,以及是否可以通过进行一些修改来减少。分析工具提供了具有不同 epoch 的每个操作所消耗的时间的图形表示。通过这种可视化,人们可以轻松查明消耗更多时间的操作。一些已知的开销可能是调整输入大小,从Python转换模型代码,或者在CPU而不是GPU中运行代码。处理这些事情将有助于实现最佳性能。
总体而言,张量板是帮助开发和训练过程的绝佳工具。来自标量和指标、图像数据和超参数优化的数据有助于提高准确性,而分析工具有助于提高处理速度。TensorBoard还有助于减少所涉及的调试时间,否则这肯定会是一个很大的时间框架。
审核编辑:郭婷
-
机器学习
+关注
关注
66文章
8453浏览量
133166 -
数据集
+关注
关注
4文章
1210浏览量
24865
发布评论请先 登录
相关推荐
机器学习模型市场前景如何
RK3568国产处理器 + TensorFlow框架的张量创建实验案例分享
什么是机器学习?通过机器学习方法能解决哪些问题?

AI大模型与深度学习的关系
AI大模型与传统机器学习的区别

构建语音控制机器人 - 线性模型和机器学习





 工商网监
工商网监
评论