 一种提高网络泛化能力的概率方法
一种提高网络泛化能力的概率方法
1. 论文信息
题目:Uncertainty Modeling for Out-of-Distribution Generalization
作者:Xiaotong Li, Yongxing Dai, Yixiao Ge, Jun Liu, Ying Shan, Ling-Yu Duan
论文链接:https://arxiv.org/abs/2202.03958v1
代码链接:https://github.com/lixiaotong97/DSU
2. 引言
Deep neural networks 在Computer Vision领域取得了非常大的成功,但严重依赖于训练和测试的domain遵循 identical distribution的假设。然而,这一假设在许多实际应用中并不成立。例如,当将在晴天训练的分割模型用于雨天和雾天环境时,或用在照片上训练的模型识别艺术绘画时,在这种非分布部署场景中常常可以观察到不可避免的性能下降。
因此,以提高网络在各种不可见测试域上的鲁棒性为目标的领域泛化问题就显得十分重要。本文就主要聚焦,如何在分布发生偏移变化的时候,让模型仍能比较好的work。
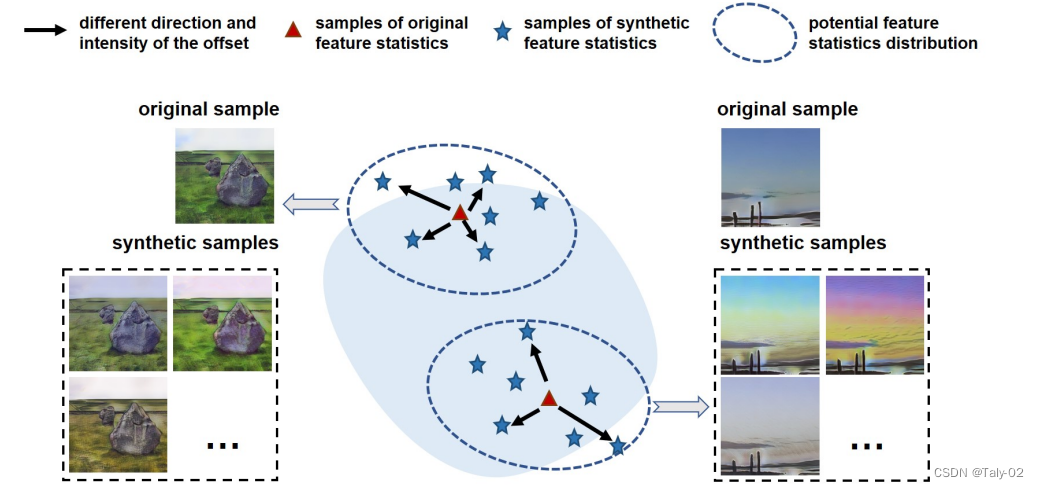
之前的许多工作都已经阐述了,特征数据其实算是可以比较好的建模训练数据中抽象出来的特征。domain的feature主要是指对单个领域更具体但与任务目标相关性较小的信息,如物体识别中的照片风格和捕获环境信息。因此,具有不同数据分布的域通常具有不一致的特征统计。所以我们只需要根据 Empirical Risk Minimization的原则来最小化训练集损失误差就可以了。
但是其实这些之前的方法都会有一个缺陷,就是这些方法在测试阶段中没有明确考虑潜在的domain偏移引起的不确定统计差异。因此可能带来模型无法处理一部分的out-of-distribution数据,而在训练集中提供的OOD样本数过拟合。所以,在训练阶段引入一定的uncertain statistics对于模型泛化性能的提升是非常关键,且有必要的。
概括来讲,本文的核心idea就是:将特征的统计数据进行分析计算,把它建模成一个不确定的分布,在分布中特征统计量的根据这种uncertain进行不同的采样,从而生成各种不同的风格的图像,来提升模型在不同目标域的泛化性。我们提出的方法简单而有效地缓解了domain shift引起的性能下降,并且可以很容易地集成到现有的网络中,而不带来额外的模型参数或loss的约束。在广泛的视觉任务上的综合实验证明了该方法的优越性,充分的实验表明在特征统计中引入uncertainty可以很好地提高模型对域偏移的泛化能力。
3. 方法
首先,是对一个mini-batch中的特征进行建模:
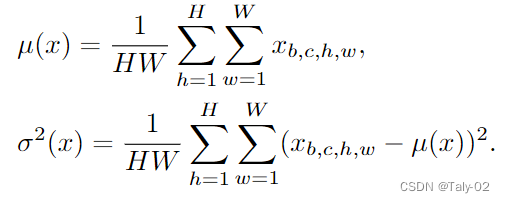
在非分布场景下,由于域特征不同,特征统计量往往与训练域不一致,不适合于非线性层和归一化层等深度学习模块,降低了模型的泛化能力。然而,大多数深度学习方法只将特征统计量视为从特征中测量出的确定性值,而没有明确考虑到潜在的不确定统计差异。
由于模型固有的易受这种差异的影响,学习到的表示的泛化能力受到了限制。尽管之前一些利用特征统计来解决领域泛化问题取得了成功,但它们通常采用成对样本的线性操作(即交换和插值)来生成新的特征统计量,这限制了合成变化的多样性。
具体而言,它们的变异方向由所选参考样本决定,这种内部操作限制了它们的变化强度。因此,这些方法在处理现实世界中不同的、不确定的domain shift时是效果有限的。对于具有uncertainty的特征统计偏移方向的任意的test domain,如何正确建模domain的shift就是解决域泛化问题的重要任务。
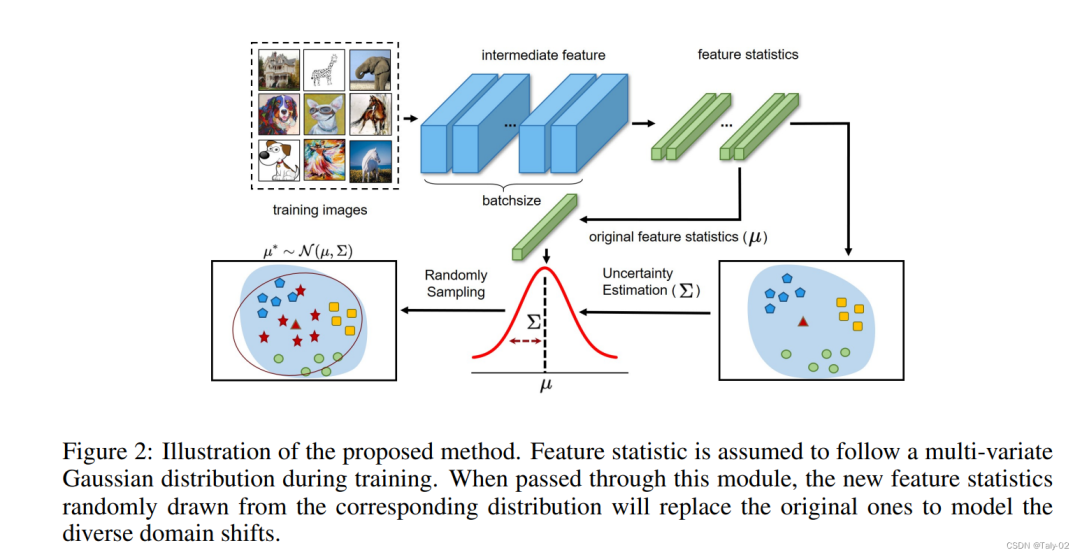
这篇文章提出的方法是在建模 Domain Shifts with Uncertainty (DSU)。通过对目标域的不确定性进行建模,来解决域泛化性能有限的问题。假设特征统计量都服从多元高斯分布,然后计算他们的方差,把这种方差定义为不确定性:
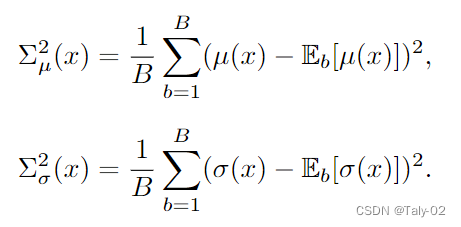
我们得到了每个铜套的不确定性后,在原有的分布上加一定的高斯噪声,利用重参数来建模统计量:
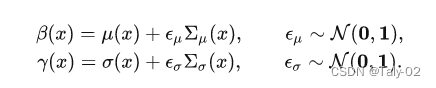
通过利用给定的高斯分布,随机采样可以生成不同方向和强度组合的新特征统计信息。然后就是利用经典的
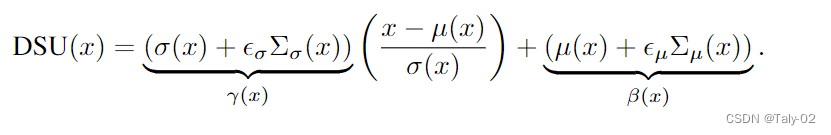
以上操作可以作为一个灵活的模块集成在网络的各个位置。注意,该模块只在模型训练期间工作,可以在测试时可以不适用。为了权衡这个模块的强度,论文还设置了一个超参数p,表示使用这个模块的概率,具体的算法细节描述在附录中可以更好地参考。利用该方法,经过不确定特征统计量训练的模型对潜在的统计量偏移具有更好的鲁棒性,从而获得更好的泛化能力。
4. 实验
本文提出的方法其实是和内容无关的,所以为了说明方法的有效性和迁移性,作者在图像分类、语义分割、实例检索和 robustness to corruptions 等任务上都做了实验。
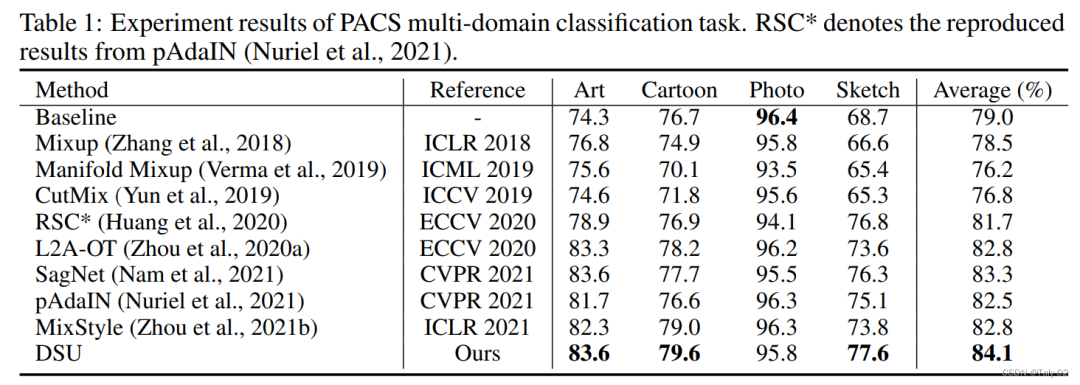
首先是Multi-domain classification的PACS数据集结果,包含了画作、卡通、照片和素描四种风格的图像。使用标准的leave-one-domain-out 的protocal,在三种风格上训练,在剩下一种风格上测试。
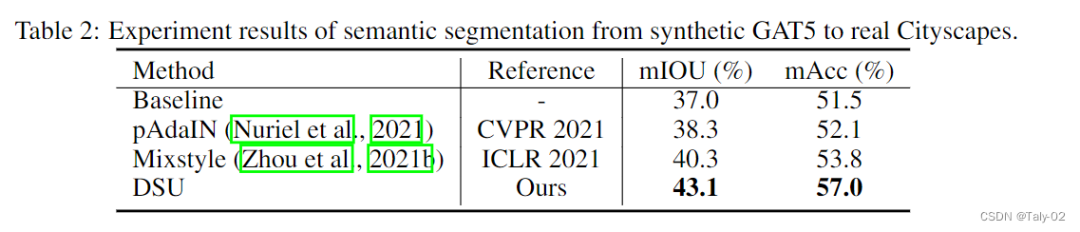
然后是在分割数据集上的表现:
可视化效果也非常不错:

更多的消融实验可以参考原文。
然后作者又利用PACS数据集,把art painting作为未知目标域,其他三种风格作为源域。作者backbone的中间特征,测量并可视化特征统计量的分布。可以看到DSU可以带来更少的domain shift:
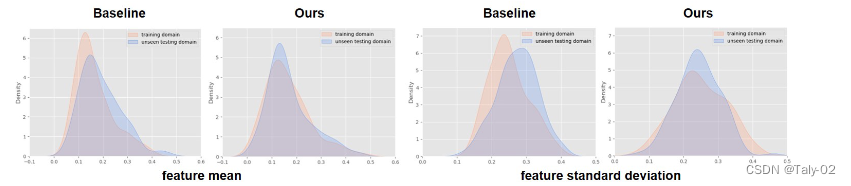
5. 结论
本文提出了一种提高网络泛化能力的概率方法,通过在训练过程中综合特征统计量对领域偏移的不确定性进行建模。每个特征统计量假设遵循一个多变量高斯分布,以建模不同的domain shift。由于生成的特征统计量具有不同的分布的uncertainty,该模型对不同的domain shift具有更好的鲁棒性。实验结果证明了该方法在提高网络泛化能力方面的有效性。
审核编辑:刘清
-
深度学习芯片
+关注
关注
0文章
3浏览量
2430
原文标题:ICLR 2022 基于不确定性的域外泛化
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种网络攻击路径重构方案
一种基于区域访问概率的容迟网络路由算法
容差模拟电路软故障诊断的小波与量子神经网络方法设计
求一种数字信道化IFM接收机的高效实现方案
一种基于机器学习的建筑物分割掩模自动正则化和多边形化方法
一种基于综合几何特征和概率神经网络的HGU轴轨识别方法
介绍一种解决overconfidence简洁但有效的方法
一种基于概率模型的特征补偿算法
一种新的自适应提升的概率矩阵分解算法
基于粒子群优化的条件概率神经网络的训练方法
一种基于联合概率矩阵分解的群推荐方法

一种社交网络用户兴趣点个性化推荐方法






 工商网监
工商网监
评论