 Transformer常用的轻量化方法
Transformer常用的轻量化方法
本文梳理了一些Transformer常用的轻量化方法,并分领域的介绍了一些主流的轻量化Transformer。
引言:近年来,Transformer模型在人工智能的各个领域得到了广泛应用,成为了包括计算机视觉,自然语言处理以及多模态领域内的主流方法。尽管Transformer在大部分任务上拥有极佳的性能,其过大的参数量限制了在现实场景下的应用,也给相关研究带来了困难,由此带来了Transformer轻量化领域的发展。笔者首先梳理了一些Transformer常用的轻量化方法,并分领域的介绍了一些主流的轻量化Transformer。欢迎大家批评指正,相互交流。
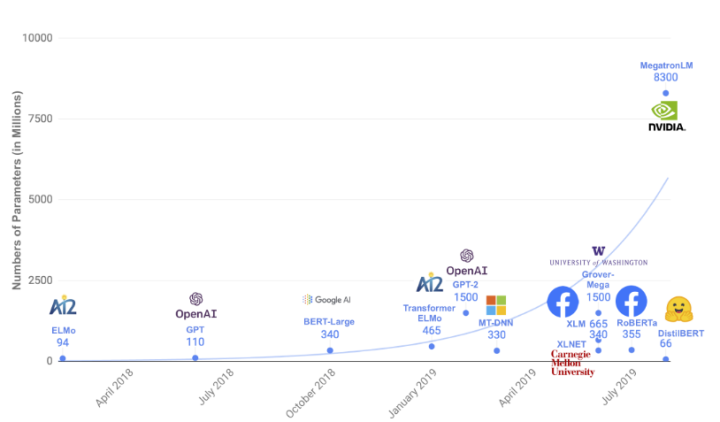
预训练模型参数量增长趋势
1.Transformer中常用的模型压缩方法
量化:量化的基本思想即利用低比特的数据类型来替代原本的高比特数据类型,同时对数据的存储空间与计算的复杂度进行轻量化。简单的训练后量化,即直接对训练好的模型参数进行量化会带来很大的误差,目前主要会采用量化感知训练(Quantized-Aware Training, QAT)的方式,在训练时全精度优化,仅模拟低精度的推理过程,很好的降低了量化过程的性能损失。
剪枝:剪枝方法基于lottery ticket假设,即模型中只有小部分参数起了核心作用,其他的大部分参数是无效参数,可以去除掉。剪枝可以分为非结构化剪枝与结构化剪枝。非结构化剪枝即定位参数矩阵中接近于0或者有接近0趋势的参数,并将这些参数归零,使参数矩阵稀疏化。结构化剪枝即消减模型中结构化的部分,如多头注意力中不需要的注意力头,多层Transformer中不需要的若干层等等。
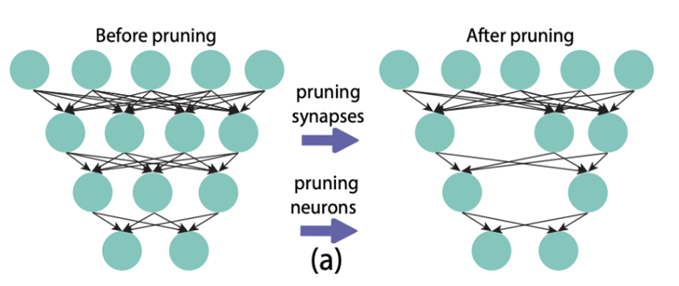
非结构化剪枝
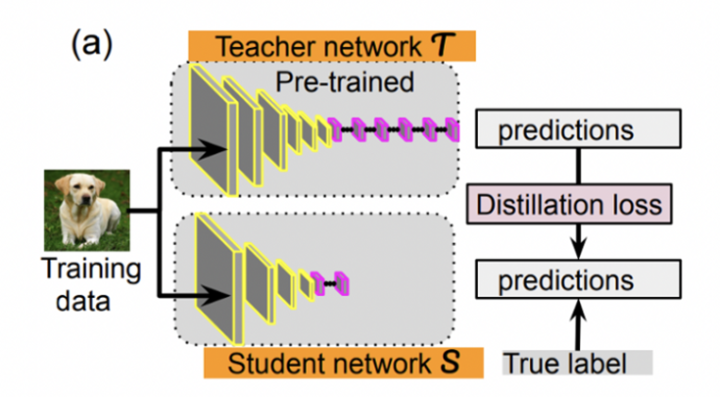
知识蒸馏:知识蒸馏通常在一个大的老师模型与一个小的学生模型之间进行。通过老师模型在监督数据上输出的“软标签分布”来训练学生模型。这种“软标签”的学习能够很好的克服监督数据中标签偏差的问题,带来了很好的知识迁移的能力。
参数共享:在模型同质的部分间共享参数。
2.预训练语言模型中的轻量化Transformer
Transformer最早在自然语言领域中得到广泛的应用,其强大的能力带来了预训练领域的快速发展,并在相关领域带来了革新。但是随着预训练模型规模的不断增大,训练与部署一个预训练模型的代价也不断提升,预训练语言模型轻量化的研究方向应运而生。由于以Bert为代表的预训练语言模型的主流架构仍是Transformer,因此Transformer的轻量化也成为了当前NLP领域的一个重要课题。以下是笔者整理的几篇经典的预训练语言模型中的轻量化工作,供读者参考。
Q8BERT: Quantized 8Bit BERT
https://arxiv.org/pdf/1910.06188.pdf
Q8BERT是量化方法在Bert上的朴素运用。除了采用了基本的量化感知训练方式外,Q8BERT还采用了指数滑动平均的方式平滑QAT的训练过程。最终,在压缩了近4倍参数量,取得4倍推理加速的前提下,Q8BERT在GLUE与SQUAD数据集上取得了接近Bert的效果,证明了量化方法在Bert上的有效性。
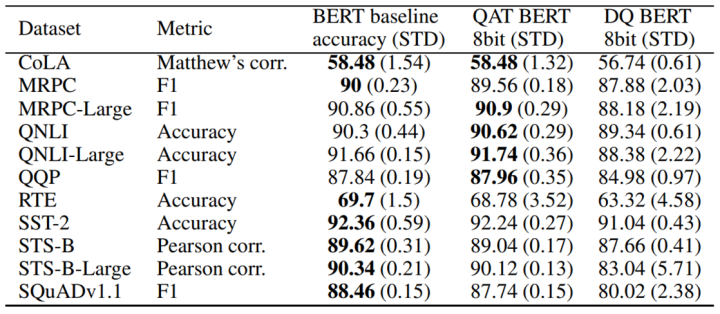
Q8BERT在下游任务上的表现
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
https://arxiv.org/pdf/1910.01108.pdf
DistillBERT是huggingface发布的一个小版本的Bert模型,它只在输出层面采用了软标签的蒸馏,将Bert的层数压缩到了原本的1/2,并在各个下游任务上取得了不错的结果。
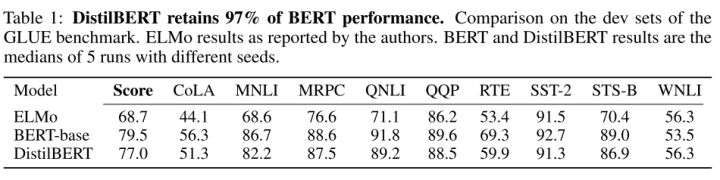
在GLUE上,DisitlBERT只用了60%的参数,保留了97%的性能
TinyBERT: Distilling BERT for Natural Language Understanding
https://arxiv.org/pdf/1909.10351.pdf
与DistilBERT相同,TinyBERT同样是知识蒸馏在Bert压缩上的应用。不同于DistillBERT只在预训练阶段采用知识蒸馏,TinyBERT同时在预训练和微调阶段采用了两阶段的知识蒸馏,使得小模型能够学到通用与任务相关的语义知识。
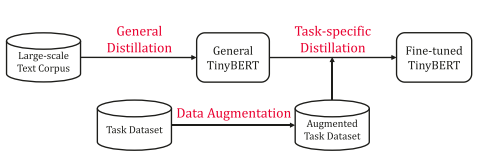
TinyBERT蒸馏策略
同时,TinyBERT采用了更加细粒度的知识蒸馏方式,对embedding层的输出,Transformer每一层中隐藏层与注意力计算的输出以及整个模型的软标签进行了知识蒸馏,得到了更加精准的知识迁移效果。
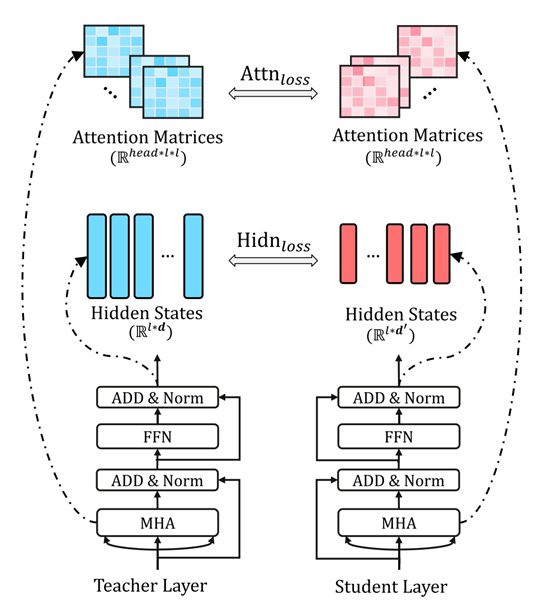
更加细粒度的蒸馏方式
最终,TinyBERT将BERT模型蒸馏成了一个4层且隐藏层维度更小的模型,并取得了不亚于更高参数量的DistilBERT的效果。
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
https://arxiv.org/pdf/1909.11942.pdf
ALBERT是Google在ICLR2020上的一篇工作。它首先采用了词表矩阵分解的方法,由于Bert采用了一个很大的词表,因此词表的embedding层包含了很大的参数量,ALBERT采用了参数分解(Factorized embedding parameterization)的方式减少这部分的参数量。具体而言,对于一个包含V 个单词的词表,假如词表的隐藏层大小E 与模型的隐藏层大小H 相等,则embedding层包含的参数量为V × E 。考虑到V通常较大,embedding的总参数量也会较大。为了减少参数量, 与直接对one-hot的词向量映射到 H 维空间不同,ALBERT首先将词向量映射到较小的E 维空间,再映射到H 维空间。将参数量从O(V × H)降低到了O(V × E + E × H) ,实现了embedding层的压缩。
除此之外,ALBERT还进行了Transformer内跨层的参数压缩,通过跨Tranformer层的完全参数共享,ALBERT对参数量进行了充分的压缩,在低参数量的条件下取得了与Bert-base相似的效果,同时在相近的参数量下可以保证模型更深,隐藏层维度更大,在下游任务下的表现更好。
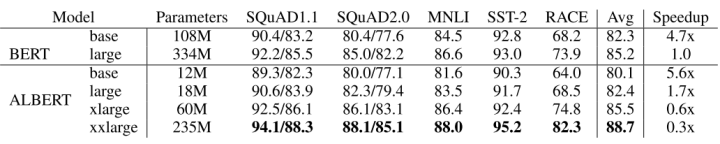
ALBERT的参数量及下游任务表现
3.计算机视觉中的轻量化Transformer
尽管Transformer在计算机视觉领域的应用相较于NLP领域稍慢一步,但Vision Transformer的横空出世使得Transformer也占据了视觉模型的主流。后期基于MAE与BEiT的预训练方法更加巩固了Transformer在计算机视觉领域的地位。与自然语言理解领域相同,计算机视觉中的Transformer同样面临着参数量过多,部署困难的问题,因此也需要轻量化的Transformer来高效的完成下游任务。以下是笔者整理的几篇近年来计算机视觉领域中的轻量化工作,供读者参考。
Training data-efficient image transformers & distillation through attention
http://proceedings.mlr.press/v139/touvron21a/touvron21a.pdf
DeiT是Facebook在2021年的一篇工作,模型的核心方法是通过知识蒸馏对视觉Transformer进行压缩。DeiT采用了两种蒸馏方法实现了老师模型到学生模型的知识迁移:
Soft Distillation:通过老师模型输出的软标签进行知识蒸馏。
Hard-label Distillation:通过老师模型预测出的实际标签进行知识蒸馏,意义在于纠正可能存在的有监督数据的标签偏差。
DeiT在蒸馏过程中引入了Distillation token的概念,其作用与Class token类似,但Class token用于在原数据上利用交叉熵进行训练,Distillation token用于模拟老师模型的软分布输出或利用老师模型预测的hard-label进行训练。
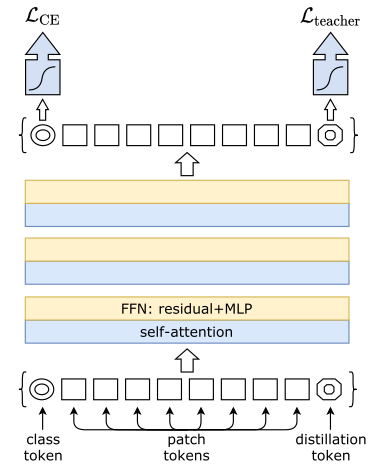
Disillation token
通过在老师模型上的蒸馏过程,DeiT拥有更小的参数规模和更快的推理速度的条件下,取得了比ViT更好的效果。
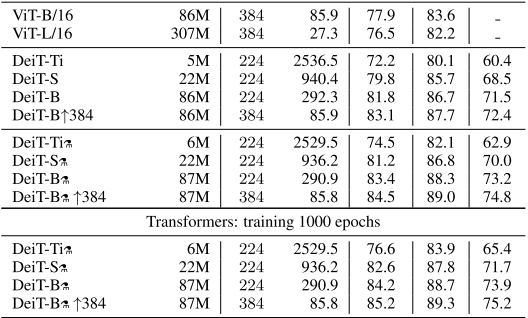
TinyViT: Fast Pretraining Distillation for Small Vision Transformers
https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136810068.pdf
TinyViT是微软在2022年的一篇工作,这篇工作的核心依然是知识蒸馏,但是在工程实现上进行了一些优化,使得小模型能够在更大的数据规模下通过知识蒸馏获取到大模型的知识。DeiT采用的知识蒸馏方法是相当昂贵的,因为在蒸馏过程中,教师模型与老师模型会同时占用GPU的内存,限制了batch_size的增加与学生模型的训练速度。且软标签在老师模型输出端到学生模型输出端的迁移也会带来一定的计算资源损耗。
为了解决这个问题,TinyViT提出了一种软标签预生成的方法,即解耦软标签的生成与学生模型的训练过程。先进行软标签的生成与预存储,再利用预存储的软标签对学生模型进行训练。由于预存储软标签向量会带来极大的存储损耗,考虑到这些向量大部分是稀疏的(因为对于一个训练好的老师模型,给定一张图片,只有极小部分类别会存在成为正确标签的概率),作者采用了存储稀疏标签的策略,即只存储top-k概率的标签以及其对应的概率。在训练学生模型时将这样的稀疏标签还原成完整的概率分布,并进行知识蒸馏。整个pipeline如下图所示:
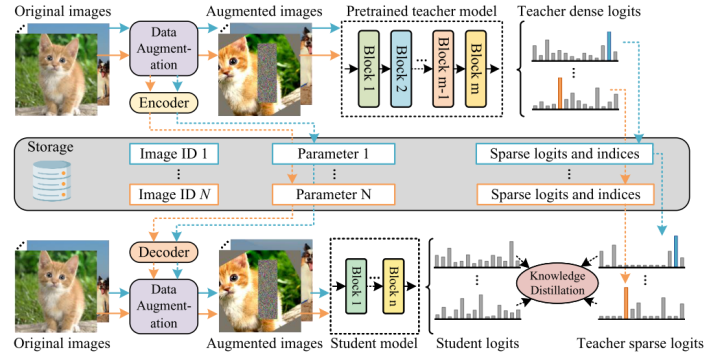
TinyViT的蒸馏流程
在相同的模型规模下,TinyViT提高了知识蒸馏的速度与数据量,并取得了分类任务上的提升。
MiniViT: Compressing Vision Transformers with Weight Multiplexing
https://openaccess.thecvf.com/content/CVPR2022/papers/Zhang_MiniViT_Compressing_Vision_Transformers_With_Weight_Multiplexing_CVPR_2022_paper.pdf
MiniViT是微软在CVPR2022的一篇工作,采用了权重复用的方法来压缩模型的参数。与ALBERT不同的是,作者发现单纯的权重复用会导致每层梯度l2范数的同质化以及最后几层输出特征相关性的降低。为了解决这个问题,MiniViT采用了Weight Transformation与Weight Distillation的方法来解决这个问题。Weight Transformation,即在每一层之间插入小型的类似Adapter的结构,以保证每层的输出不会因为参数量相同而同质化。Weight Distillation,即采用一个老师模型来引导MiniViT的输出以增强模型性能。整体的pipeline如下所示:
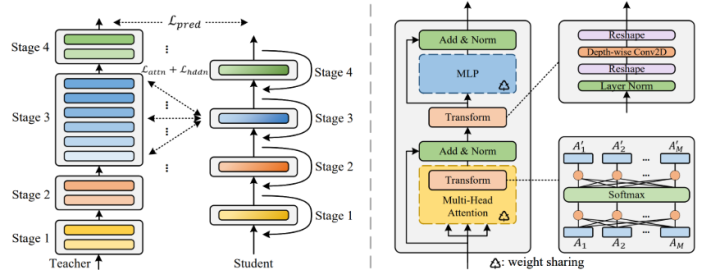
作为一个通用的压缩方法,作者在DeiT与Swin-Transformer上进行了测试。在更小的参数量下,在ImageNet数据集上,Mini版本的模型均取得了不亚于甚至更好的效果。
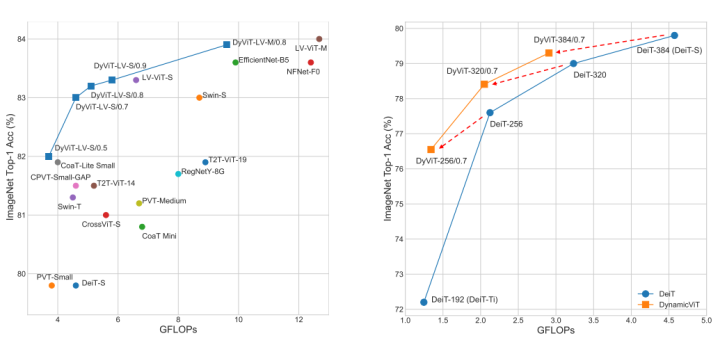
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
https://proceedings.neurips.cc/paper/2021/file/747d3443e319a22747fbb873e8b2f9f2-Paper.pdf
本文是清华大学在Nips2021上的一篇工作,其借鉴了模型压缩中剪枝的思想,但是是对Transformer每一层的输入token进行了稀疏化。Token稀疏化的基本假设在于:对于一张图片,一定会存在一些冗余部分对模型的预测结果影响很小,对这些部分的削减可以很大程度的增加模型的推理速度。
DynamicViT的具体做法是:通过在每一层间增加一个轻量化的预测模块,预测哪一些部分的token是可以被丢弃掉的。在预测完后通过一个二进制的决策掩码来完成对token的丢弃。同时,作者修改了训练的目标函数,保证了每一层丢弃的token数量是有限的。
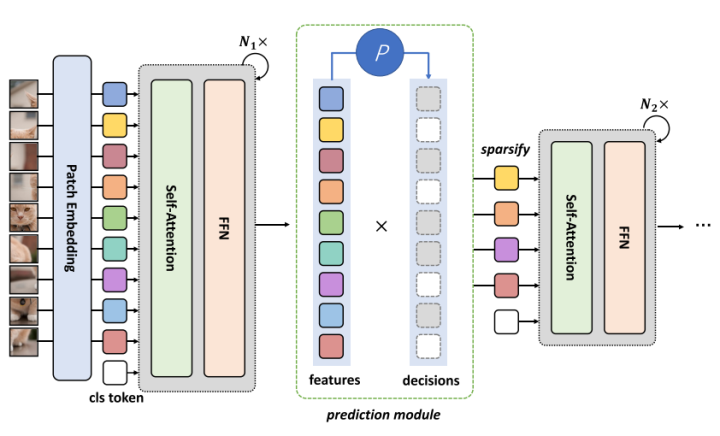
DynamicViT的稀疏化模块
最终,在上述的稀疏化策略下,DynamicViT在原始的ViT基础上取得了很好的加速,并在模型性能与推理速度之间达到了一个很好的平衡。
4.多模态中的轻量化Transformer
多模态模型往往同时参考了视觉模型与语言模型的设计,因此也会以Transformer作为其主流架构。但多模态中的轻量化工作较少,笔者整理了比较有代表性的几篇多模态轻量化工作供读者参考。
MiniVLM: A Smaller and Faster Vision-Language Model
https://arxiv.org/pdf/2012.06946.pdf
MiniVLM是微软在Oscar模型上的轻量化工作。MiniVLM的轻量化基于一个观察假设:即在大多数多模态任务中,多模态模型的视觉端不需要特别强的目标检测信息,而目标检测器往往是模型的瓶颈部分。因此,用一个不那么精确的目标检测器可以有效的压缩模型的参数量与加快推理速度,同时尽可能的减少性能损失。
为了达到上述效果,MiniVLM采用了一个基于EfficientNet与Bi-FPN的轻量化目标检测器。同时,为了进行进一步压缩,MiniVLM对多模态Tranformer端也进行了压缩,将原本的Bert结构更换到了更加轻量化的MiniLM,其结构如下所示:
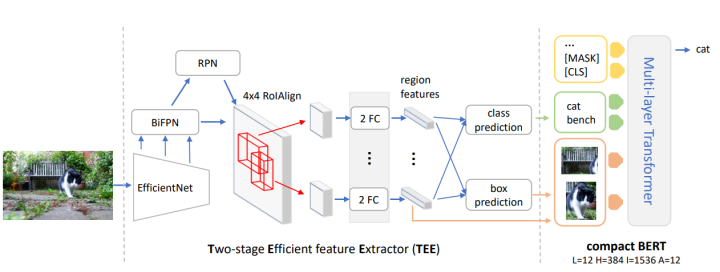
轻量化目标检测器
最终,在可接受的精度损失范围内,相较于原本的OSCAR模型,MiniVLM对推理速度进行了极大的提升:
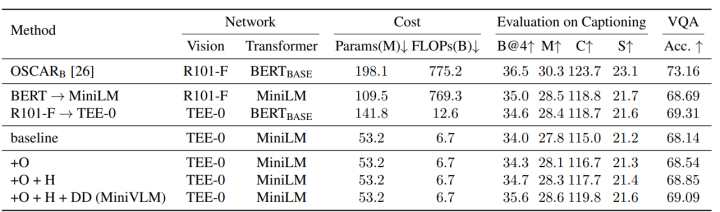
MiniVLM的加速效果与下游任务性能
Compressing Visual-linguistic Model via Knowledge Distillation
https://arxiv.org/pdf/2104.02096
DistilVLM是MiniVLM工作的延续。不同的是,在更换目标检测器与Transformer架构的同时,DistilVLM同时采用了知识蒸馏来保持模型的性能。DistilVLM的蒸馏策略与TinyBERT相同,同样是进行预训练阶段和微调阶段的两阶段蒸馏:
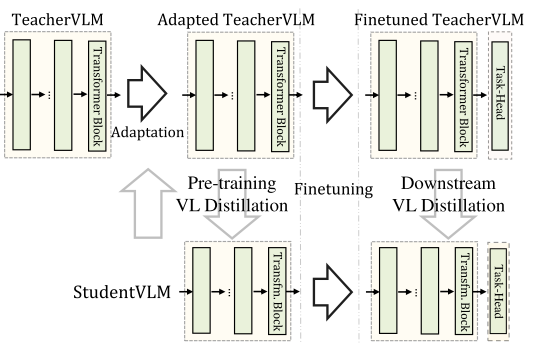
DistilVLM的蒸馏策略
由于采用了不同的目标检测器,在检测得到的目标区域不同的前提下,后续的知识蒸馏均是无效的。为了解决这个问题,DistilVLM采用了视觉token对齐的方式,老师模型和学生模型均采用相同的目标检测器,使得两个模型的检测区域对齐,保证了后续知识蒸馏的有效性。
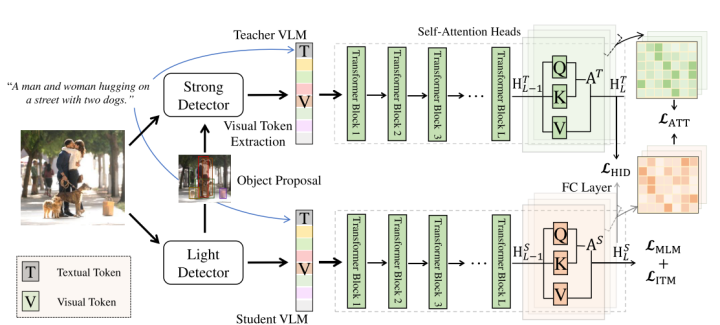
视觉对齐
最终,在与MiniVLM相同参数和推理速度的前提下,DistilVLM取得了不错的性能提升。
-
数据
+关注
关注
8文章
6885浏览量
88818 -
计算机视觉
+关注
关注
8文章
1696浏览量
45927 -
Transformer
+关注
关注
0文章
141浏览量
5980
原文标题:Fast and Effective!一文速览轻量化Transformer各领域研究进展
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
碳纤维为何能实现汽车轻量化?
汽车轻量化采用3D打印
客车车身轻量化分析
汽车轻量化技术
PACK轻量化设计介绍及电芯选择
常见的轻量化材料的分类与汽车轻量化材料的应用

低速电动车轻量化的作用和蕴含的技术分析
“新能源汽车轻量化的整体解决方案”主题演讲
康得搭建碳纤维轻量化平台来推动国内纤维轻量化产业的发展
日产全新轻量化技术获突破,减重75%
浅谈轻量化设计:材料、创新技术及未来解决方案
分析汽车车灯轻量化技术研究

最新专利深入“轻量化”!华为这样做?
5G轻量化网关是什么






 工商网监
工商网监
评论