 从量子纠缠的视角审视深度学习从而反馈机器学习的发展
从量子纠缠的视角审视深度学习从而反馈机器学习的发展
1、引言
经典物理学的主角是物质和能量。20 世纪初,爱因斯坦写下E =mc2 ,将质量和能量统一在了一起。而从那之后,一个新角色——信息(Information)——逐渐走向了物理学舞台的中央。信息是关于不确定程度的度量。Shannon 创立信息论的初衷是为了定量化地描述信息的存储和传输。
Jaynes 从信息论的角度研究多粒子体系,重新阐释了统计力学。原来,物理学家所熟知的热力学熵与Shannon 用来衡量信息量的信息熵(Information Entropy)系出同源。Landauer 指出擦除信息会增加热力学熵,从而产生热量。因此,对于信息的一切处理(比如计算)都受到热力学基本定律的约束。这些工作使人们逐渐意识到,信息不是一个单纯的数学概念,而是与物质和能量一样基本的物理概念。
量子力学给物理世界带来了固有的不确定性,从而促生了量子信息理论。量子信息论中最核心的概念是量子纠缠。如果两个微观粒子的整体波函数不能够被写成各部分的直积,那么它们之间就存在纠缠。对于存在量子纠缠的体系,观察其中的一部分能够告诉我们关于另外一部分的信息。类比于经典信息熵, 我们使用纠缠熵(Entanglement Entropy)来度量量子纠缠的大小。量子信息论的视角,特别是量子纠缠的概念在现代物理学的研究中扮演着日趋重要的角色。
凝聚态物理学家用量子纠缠来刻画量子物质态。传统上,他们使用对称性和宏观序参量来区分不同的物质状态。这成功地解释了超流体、超导体、磁性等丰富多彩的自然现象。然而,近些年来人们发现了越来越多仅用对称性难以区分的物质态,比如不同种类的自旋液体态、分数量子霍尔态等等。量子纠缠可以给这些新的物质态一个恰当的标记。
比如,纠缠熵随着体系尺寸的标度行为反映了量子物质态的基本特性。而对于标度行为的修正也可能包含着关于物质态的普适信息。研究量子物质态中纠缠的大小和模式成为现代凝聚态物理的一个核心问题。此外,量子纠缠还指引计算物理学家发展高效的数值算法精确地模拟量子多体现象。
本次专题的另外几篇文章介绍了使用张量网络态(Tensor Network State)方法研究量子多体问题的进展。张量网络算法的成功很大程度上来源于量子物质态典型的纠缠结构:面积定律。很多人们关心的量子体系的两部分之间的纠缠熵仅仅正比于其边界的大小,这使得利用经典计算机高效而精确地研究这些量子多体问题成为可能。
有意思的是,量子态所遵循的面积定律还和黑洞的熵有着深刻的联系。从量子信息的视角审视引力、虫洞以及量子混沌等现象,甚至有可能加深我们关于时空的本源的理解。国际上关于这方面的研究开展得如火如荼。美国的Simons 基金会支持了一项专注于此的合作研究项目。
量子纠缠的深远影响并没有就此止步,一些最新的研究进展表明,它对机器学习(Machine Learning)中的一些问题也可能有启发和指导意义。机器学习的研究目标是让计算机获得一定程度的智能,不需要过多的人为干预就可以高效地解决实际问题。
通常,这种看似神奇的能力是从大量样本的学习中获得的。由于近年来算法和硬件的快速发展以及大量的数据积累,机器学习取得了一系列令人振奋的成果。特别是2016 年3 月Google DeepMind 所制造的AlphaGo 程序战胜了世界围棋冠军李世乭,使得以深度学习(Deep Learning)为代表的新一代机器学习技术走进了大众的视野。
如今,机器学习在图像和语音识别、机器翻译、计算广告、推荐系统等人类生活的方方面面都扮演着日趋重要的角色。而它的应用也在逐渐向天文、物理、化学、材料、生物、医药等众多科学研究领域渗透。具体到本文作者所工作的领域:将机器学习方法应用于量子多体问题,可以从高维空间纷杂的微观构型数据中提取出关键的物理信息。
而将机器学习的思想与传统计算途径相结合,为解决凝聚态和统计物理中的疑难问题提供了新思路。最近的一些尝试包括使用机器学习方法探测相变和分类物质相,探索使用人工神经网络作为量子体系的试探波函数等等。这些尝试让物理学家们有机会仔细审视机器学习领域的核心思想和技术。本文介绍的就是这一方向上新涌现出的一个研究思路:从量子纠缠的视角审视深度学习,从而反馈机器学习的发展。
2、深度学习和量子多体物理中的函数近似
深度学习究竟在做什么?用最简短的话概括,就是函数近似(Function Approximation)。函数近似的目的是用高效经济的方式尽可能精确地描述复杂的函数映射。实际问题中的目标函数可能是图像识别应用中从微观像素到图片类别的映射,可能是AlphaGo 中围棋的局面到最终胜率的估计,也可能是Atari 视频游戏中的画面到最优控制策略的映射等等。
读者也许已经看出来了,以上这几个函数恐怕都很难用一个简洁的方式表达。即使考虑一个极端简化的情形:怎样描述有N 个二进制自变量的多元函数?原则上,我们当然可以存储一个2N 行的表格来精确表达这样一个函数。这个表格的每一行对应了一种可能的输入和输出,函数的计算也就等价于查表。
可是只要N ≳ 70 ,即使用上全世界所有的存储介质,我们也没有能力存下这张表格,更不要说对它进行高效的查找了。
机器学习中的连接主义学派(Connectionism)提倡使用人工神经网络(Artifical Neural Network)来解决这类函数近似问题。连接主义强调复杂的现象(比如智能)不来自于相对简单的组成单元,而来自于这些单元之间的连接。图1(a),(b)展示了两种常见的人工神经网络结构。
图1(a)是前馈神经网络(Feedforward Neural Network)。图中的每一个蓝色圆圈代表一个人工神经元,它接受上一层结果作为输入,加权求和之后通过一个非线性的激活函数传递给下一层。可见,前馈神经网络是通过多层非线性函数的嵌套来表达复杂的多元函数的。
而图1(b)显示了另外一种函数参数化方式:限制玻尔兹曼机(Restricted Boltzmann Machine)。从名字就可以看出,玻尔兹曼机和统计物理有着十分密切的关联。我们可以将它理解成一个统计力学系统,其中包含了两组相互作用的随机变量:显变量(红色)和隐变量(蓝色)。
“玻尔兹曼机”的名字来源于这些随机变量的联合概率分布遵循统计物理中的玻尔兹曼分布。而“限制”这个词来源于图1(b)中所示的特殊网络结构:所有连接都仅在显层和隐层之间。和全连接的玻尔兹曼机相比,这样的结构可以极大地提高计算效率。而对于一个只关心显变量的观察者来说,即便显层内部没有直接的相互作用,隐层神经元所诱导的有效相互作用还是可以将它们关联起来。
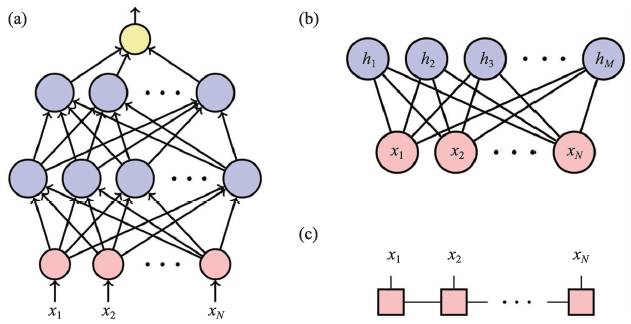
图1 几种参数化多元函数的方式(a)前馈神经网络;(b)限制玻尔兹曼机;(c)矩阵乘积态
与使用一个2N 行的表格相比,图1(a),(b)中所示的两类网络结构都可以用少得多的参数近似表达复杂的多元函数。在实际应用中,我们可以通过调节前馈神经网络中的权重参数,使得它学会从图片像素信息中分辨其中物体的种类。或者,我们也可以调节限制玻尔兹曼机中随机变量之间的相互作用强度,使得显变量的概率分布尽可能重现目标数据集的分布。
训练好的玻尔兹曼机可以生成更多遵循目标概率分布的新样本。以上两类任务分别对应了判别型学习(Discriminative Learning) 和生成型学习(Generative Learning)。打个比方,判别型学习相当于学会认字,而生成型学习的目标是学会写字。正如费曼在他的黑板上留下的那句名言“What I can not create,I do not understand”,学会写可比学会读困难得多,也要求更深层次的理解。判别型学习支撑着大量当下成功的商业应用,而探索生成型学习的模型和算法则代表了深度学习研究的前沿和未来。
在实际应用中,人们希望使用通用的人工神经网络结构表达尽可能复杂多变的函数形式。这自然引出一个问题:图1(a),(b)所示的网络都能够表达什么样的函数形式?为此,人们证明了所谓的“普适表示定理”:随着网络中隐层神经元个数的增加,图1(a)中所示的前馈神经网络结构(即使只有单个隐层)可以任意逼近任何的连续函数。
类似地,通过增加图1(b)中限制玻尔兹曼机的隐层神经元数目,它也可以表达关于显变量任意复杂的概率分布函数。然而遗憾的是,针对一个具体的函数近似问题,以上这些普适表示定理没办法告诉我们至少需要多少隐层神经元,也没办法告诉我们究竟如何确定这些神经元之间的连接权重。而现实中我们关心的首要问题就是:给定有限的计算时间和存储资源,应该如何最优地分配它们呢?
经过多年的摸索实践,人们有一个关键的发现:在参数个数一样的情况下,深层的神经网络比浅层的网络具有更强的表达能力。训练越来越深的神经网络来近似表达复杂的函数形式,是深度学习这个名词中“深度”的来源。当然,神经网络的表达能力也并不是越强越好。
过于复杂的网络结构不仅增加了计算量,还可能造成神经网络过拟合(Over-fitting),这就是典型的“过犹不及”。神经网络的表达能力最好是与需要描述的函数的复杂程度相匹配。为此,人们设计出了种类繁多的神经网络结构。很多这些结构设计主要由工程实践经验驱动,这使得深度学习得到了“经验主义”的名声。
利用人工神经网络作函数近似的初衷是利用它们的通用性,不需要太多的人为介入就可以自动寻找到数据中的关键特征(Feature)。可当神经网络结构变得越来越多样之后,面临网络的人为选择问题,我们又回到了起点。
因此,人们迫切需要一些更具指导意义的判别标准,来帮助我们定量化地界定神经网络的表达能力和数据集的复杂程度,以便在不同结构的神经网络之间作出比较和取舍。为此我们需要对于神经网络所表达的对象——现实世界中的多元函数——有更深刻的理解。
在我们前面的例子中,虽然所有可能的输入原则上有2N 种,但典型的输入其实通常遵循某一特定分布。关于目标数据分布和函数性质的先验知识(Prior Knowledge)有助于指导我们设计合适的神经网络结构。一个最明显的先验知识就是函数的对称性。
比如,在图像识别的例子中,图片的种类与其中物体的具体位置无关。类似地,对于围棋局面的估值对盘面构型也应该具有反演和旋转不变性。在图1(a)的网络中实现这些限制,我们就得到了卷积神经网络(Convolutional Neural Network)。它使用局域感知区(Local Receptive Fields)扫描整张图片寻找特征,通过不同感知区共享权重来保证函数的不变性。如何发掘和利用更多类似的“先验知识”是深度学习成功的关键。
与上述例子类似,量子物理的研究中也常常使用到函数近似。比如,一个量子自旋体系的波函数无非是一个关于自旋构型的多元函数。和深度学习中的目标一样,我们也希望使用尽量简单的参数化方式和尽量少的参数描述尽可能复杂的波函数。
总结一句话,那就是“天网恢恢,疏而不漏”。图1(c)显示量子多体物理研究中常用的一种参数化波函数的方法:矩阵乘积态(Matrix Product State)。它的基本组成单元是红色方块所示的三阶张量。竖线代表物理指标,而方块之间的横线则称为“虚拟键”(Vitual Bond)。横线之间的连接代表对于虚拟键指标的求和。
不难猜测,随着虚拟键维数(Vitual Bond Dimension)的增大,矩阵乘积态可以表达关于物理指标愈加复杂的函数。除了增加虚拟键维数,另一种增加矩阵乘积态表达能力的方法是将图1(c)中所示的方块推广成为更高阶的张量,也就是增加虚拟键的个数。将所有虚拟键连接起来,求和完所有的内部张量指标,就得到了前文提到的张量网络态。
和深度学习中种类繁多的人工神经网络结构一样,物理学家也发明了很多不同结构的张量网络态以及相对应的算法。然而,和深度学习不同的是,物理学家们对于张量网络的表达能力有着更为定量化的理解:关键在于量子纠缠!切割一个张量网络态所断开的虚拟键的个数和维数与这个网络能够描述的纠缠熵直接相关。
而另一方面,虽然量子多体问题的希尔伯特空间非常大,但幸运的是大多数人们感兴趣的量子态只是其中的一个很小的子集。这些态的量子纠缠熵并不是任意的,而是遵循前文提到的面积定律。张量网络态恰好抓住了物理问题的这个重要特性,因而获得成功。
在实际研究中,物理学家们通常针对具体物理问题的纠缠大小和模式来灵活选择设计张量网络态结构。在这个意义下,量子纠缠其实就是指引物理学家们应用张量网络研究量子多体问题的“先验知识”。
3、深度学习助力量子物理
从函数近似的观点看,深度学习和量子物理之间的联系非常显然。即便在上一次连结主义学派研究的低潮期,也曾有过一些使用人工神经网络作为量子体系的变分波函数的尝试。最近,Carleo 和Troyer尝试使用限制玻尔兹曼机作为量子自旋体系的多体变分波函数,得到了非常精确的基态能量和非平衡动力学的结果。
值得注意的是,传统的限制玻尔兹曼机只能表达取值为正的概率分布函数,为了让它们适合于描述带有相位信息的波函数,Carleo 等将限制玻尔兹曼机的参数推广到复数域。另外,实际计算中Carleo 等采用的函数形式其实是多个共享权重的限制玻尔兹曼机的乘积。
这样的结构等价于一个单隐层的卷积神经网络,从而在结构上保证了物理体系的空间平移不变性。Carleo 和Troyer 的结果激起了人们极大的兴趣,沿着这个思路往下:类似的人工神经网络还能够描述其他丰富多彩的物质态吗?
对于这个问题, 邓东灵、李晓鹏和Das Sarma给出了一个构造性的回答。他们举例说明限制玻尔兹曼机的函数形式可以表达几种受到普遍关注的拓扑态。而蔡子直接训练图1(a)所示的前馈神经网络以测试它们能否学会表达一些典型的玻色子、费米子、阻挫磁性态的波函数。
这些尝试进一步展示了人工神经网络作为量子多体波函数的潜力。可是,是否有更一般的理论定量地描述这类人工神经网络变分波函数的优势和局限性呢?为了回答这些问题,邓东灵等人 研究了限制玻尔兹曼机的纠缠表达能力。他们发现稠密连接的限制玻尔兹曼机原则上能够承载超越面积定律的量子纠缠。
本文作者与谢海东、向涛利用等价变换的思路,在玻尔兹曼机和张量网络态之间建立起了一座桥梁。这样就可以通过分析对应的张量网络态来回答前面关于玻尔兹曼机的种种问题。我们发现恢复平移不变的波函数构造是Carleo 等计算成功的一个关键点,这样的构造在不增加变分参数的情况下巧妙地增加了变分波函数表达能力的上限。郜勋和段路明则从计算复杂性理论的角度分析论证了限制玻尔兹曼机的局限性,并指出深层的玻尔兹曼机可以高效地描述几乎所有已知的量子态。
他们的工作表明纠缠熵并非刻画表达能力的唯一标准。还需要注意的是,更强的表达能力并不意味着在实际计算中能够找得到更好的函数近似。另外,黄溢辰和Moore也研究了玻尔兹曼机在量子多体问题中的表达能力。以上这些理论发现,为设计更经济高效的量子多体试探波函数提供了方向性指引。
深度学习的领军人物Yann LeCun也注意到了这一系列来自物理学领域的工作。他在Facebook 上分享了自己对于量子纠缠、黑洞熵以及张量网络态的理解,并在最后总结道:“迷人的联系”。
4、量子纠缠指引深度学习
上述这些工作的研究思路是使用神经网络近似量子多体波函数。有趣的是,使用逆向思维,量子多体物理也能够帮助回答一些关于深度学习的问题。比如,我们可以从量子纠缠的视角来说明深度学习中的深度为什么重要。考虑图2 中所示的两个玻尔兹曼机,它们的隐层神经元个数和权重参数个数都完全相等。不同之处在于图2(a)的隐层神经元呈浅层扁平化排列,而在图2(b)中隐层神经元沿纵深方向排列成了层级结构。
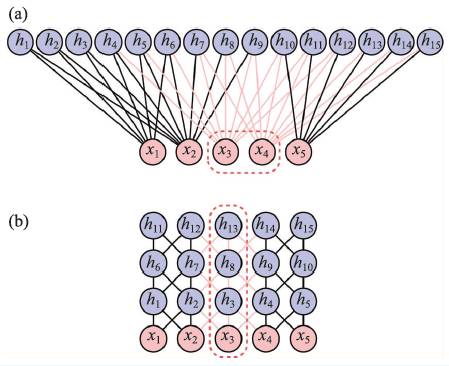
图2 两个不同架构,但参数个数相等的玻尔兹曼机(a)限制玻尔兹曼机;(b)深层玻尔兹曼机。红色虚线框中的神经元承载了网络左右部分的纠缠。一旦去除它们,网络就分成了独立的两部分
为了分析比较图2 中两种网络表达能力的优劣,我们按照文献的思路将它们分别转化成矩阵乘积态。由于是等价转换,相应的矩阵乘积态的虚拟键维数限定了原来的玻尔兹曼机承载纠缠能力的上限。而根据文献,要估计对应的虚拟键维数,只需要检查在玻尔兹曼机中去除多少个神经元就可以将网络从两侧断开。如图2 中虚线方框所示,深层玻尔兹曼机所对应的虚拟键维数更大,从而能够比浅层的玻尔兹曼机负载更大的纠缠。
以上的分析仅依赖于玻尔兹曼机的结构而不涉及到任何权重的数值信息。通过这样的分析,我们从量子纠缠的角度说明了深层结构的重要性:深层玻尔兹曼机在拥有同样参数个数的情况下具有相对更强的表达能力上限。这里,张量网络态不仅仅是一个分析手段。
作为一个副产品,我们也理解了它与玻尔兹曼机在函数近似上的各自优缺点。比如,为了表达同样的量子态,玻尔兹曼机所用的参数个数可以比张量网络态少得多。然而,对于某些特定状态使用限制玻尔兹曼机表达却不如张量网络态方便。
除了帮助分析神经网络的表达能力,量子纠缠也可以作为深度学习应用的“先验知识”:它定量地描述数据集的复杂度,并相应地指导设计人工神经网络的结构。作为一个例子,让我们考虑机器学习里的一个典型数据集:MNIST。如图3 所示,MNIST中包含六万张形态各异的手写数字图片。每一张都是28 × 28 的黑白图像,其像素灰度取值0~255 。所有可能图像的数目是一个天文数字:25628x28 。
然而,可以想象,真正有意义的手写数字图片只占据着这个巨大无比的“像素空间”中的一个小角落。联想到前文所述,大多数物理上有兴趣的量子态同样仅仅占据希尔伯特空间的一个小角落。我们可以将MNIST中的图片看作是对于某一量子波函数测量所得的构型快照。
类比于对量子体系的分析,我们可以将每张图片切成两半,然后研究两部分之间的量子纠缠。注意,如此定义的纠缠熵是对于整个数据集的分布而言的,并非对于单张图片。数据集的纠缠特征指导我们在学习的过程中合理地分配资源。比如,注意到MNIST 数据集中每一张图片的边缘都是黑色的。
这意味着图片边缘像素的取值不依赖于任何其他像素,从而不与它们形成纠缠。假如使用玻尔兹曼机来学习这样的概率分布,就完全不需要使用隐变量来传导它们之间的关联。而另一方面,遮住MNIST图片的一半,还能够猜测出另一半大致的模样。这就意味着图片的这两部分之间存在纠缠。纠缠熵的具体数值定量地告诉我们至少需要多少隐层神经元,以及怎样的连接结构才能描述好这样的数据集。
图3 MNIST数据集中的一些样本
曾获得英特尔国际科学与工程大奖的少年Henry W. Lin 和MIT 的宇宙学家Max Tegmark 等合作指出,深度学习成功的关键不仅仅依赖于数学,更依赖于物理学规律。任何我们关心的实际数据集——无论是自然图像还是语音信号——都是现实世界的反映。这也意味着它们通常表现出局域关联、存在对称性、呈现层级结构等特征。
在本文作者看来,量子纠缠正可以定量化地挖掘和利用这些来自于物理定律的先验知识。虽然,自然数据集的纠缠熵未必遵循面积定律,但它们离最大纠缠的饱和值还应该差得远。这启发我们借用处理量子多体问题的思路,针对数据集的特点相应地设计合适的函数近似手段。
读者也许会感到奇怪,绝大多数现实应用中遇到的数据不都是经典的吗?为什么非要引入量子纠缠的概念呢?经典信息论难道不够用吗?这里我们援引美国计算机科学家和量子信息学家Scott Aaronson 的观点:将量子力学看作是经典概率论的数学推广,而量子纠缠就是一个描述多参数函数性质的实用数学工具。文献就是采用类似的研究思路使用量子纠缠来分析刻画现实世界中的复杂网络的。
以上的讨论都是针对生成型学习而言的,那么,量子纠缠对于理解判别型的学习是否也有类似的帮助呢?考虑到深层的前馈神经网络在现实世界中的广泛应用,这是目前深度学习研究的一个热点问题。这方面一个很有启发的工作来自计算物理学家Stoudenmire和生物物理学家Schwab,他们成功训练了一个矩阵乘积态来识别MNIST 数据集中的数字。
他们的成功说明,从MNIST的像素到数字标记的函数映射的纠缠熵看起来并不大,完全可以被矩阵乘积态有效描述。无独有偶,耶路撒冷希伯来大学的计算机科学家Amnon Shashua 所领导的团队一直致力于使用张量分析的手段研究人工神经网络。经过一系列前期工作的铺垫,他们的注意力最近也被吸引到量子纠缠这个概念上。2017 年4 月初,Shashua 等人在arXiv 上贴出一篇题为“Deep Learning and Quantum Entanglement: Fundamental Connections with Implications to Network Design”的长文。
这篇论文的第一作者Yoav Levine 硕士期间在以色列的魏茨曼科学院(Weizmann Institute of Science)学习理论凝聚态物理,现在则是Shashua的博士生。在这篇文章中,Levine 等人采用与文献类似的策略,将一类特殊的卷积神经网络转化为张量网络态。
这样就可以通过对于张量网络的最小切割(Min-Cut)分析来确定原来的人工神经网络的纠缠表达能力了。作为一个具体的例子,他们考虑了“上宽下窄”和“上窄下宽”两种结构的卷积神经网络,并从理论上证明其性能的优劣取决于目标数据集的纠缠特性。他们在MNIST数据集上设计数值实验,也的确验证了这些理论预言。
可见,在深度学习与量子多体物理的交界处正在形成一个新兴研究方向,量子纠缠正是连接它们的桥梁。一些嗅觉敏锐的研究者已经意识到了对方的思想、方法和技术对于本领域的帮助,正在积极地相互学习。预计随着更多思维活跃的研究者的加入,深度学习和量子多体物理的研究会碰撞出更加灿烂的火花。
5、结语
量子多体物理和深度学习的相遇也许本不应使人惊讶,毕竟,这两个领域都关心大量微观自由度组成的复杂体系中涌现出来的宏观现象。人们为了认识自然界丰富多彩的量子物态所形成的工具,也许可以帮助我们设计出更智能的人工神经网络和学习算法。“量子机器学习”(Quantum Machine Learning)是一个正在蓬勃发展的领域,本文仅介绍了其中的冰山一角。感兴趣的读者可参阅《物理》杂志上的介绍文章和最近的综述。
爱因斯坦有一句名言:“自然是微妙的,可她没有恶意”。隐藏在这个纷繁复杂的世界背后的结构算得上是微妙吧。可一旦抓住诀窍,居然可以用几行简洁美妙的公式理解。深度学习是不是能帮我们捕捉自然的善意呢?我们把这个问题放在这里,期待量子物理和机器学习的邂逅可以帮助我们发现更多自然的微妙!
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4773浏览量
100877 -
语音识别
+关注
关注
38文章
1742浏览量
112706 -
机器学习
+关注
关注
66文章
8423浏览量
132755
原文标题:量子纠缠:从量子物质态到深度学习
文章出处:【微信号:信息与电子工程前沿FITEE,微信公众号:信息与电子工程前沿FITEE】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
人工智能、机器学习和深度学习存在什么区别

AI大模型与深度学习的关系
FPGA做深度学习能走多远?
【《计算》阅读体验】量子计算
深度学习中的时间序列分类方法
深度学习中的无监督学习方法综述
深度学习在工业机器视觉检测中的应用
深度学习与nlp的区别在哪
人工智能、机器学习和深度学习是什么
深度学习与传统机器学习的对比
量子纠缠探测与大小估算研究新突破
【量子计算机重构未来 | 阅读体验】+机器学习的终点是量子计算?
为什么深度学习的效果更好?







 工商网监
工商网监
评论