 蚂蚁测试用例智能生成技术架构与实践
蚂蚁测试用例智能生成技术架构与实践
今年开始,我们看到了越来越多的人开始关注测试用例自动生成这个领域,包括一些Devops产品也在做用例自动生成方面的工作。这里我主要和大家来介绍下测试用例自动生成这个领域的背景、相关研究方向、研究难点,以及在蚂蚁我们是怎么来做测试用例自动生成这件事情的。
1
背景
首先我们来看测试用例自动生成这件事情的背景。随着业务的不断积累和发展,工业界中可以看到大型复杂系统的数量是持续在积累和增长的。在这个过程中,我们对这些复杂系统的测试和维护成本是不断在增加的。不管是开发同学还是测试同学,都需要投入大量的时间在测试用例编写环节。我们也经常会收到一些同学的反馈,比如在一次功能迭代过程中,开发业务代码所需要的时间和开发测试用例所需要的时间可能会达到1 : 1。从这里我们可以看出,开发测试用例环节是存在非常大的提效空间的。
在整个快速迭代的背景之下,我们希望能够通过智能化的手段来解决测试时间的投入,其中单测首当其冲。
PART
单测是质量保障流程中的第一环,单测阶段拦截问题后解决成本最低
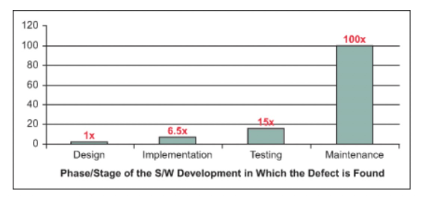
图1 问题修复成本
从图1可以看出,在迭代环节逐步推进的过程中,环节越靠后时问题修复成本越高,因此我们希望把发现问题的环节尽可能提前,单测就是最早的这个阶段。在单测阶段拦截问题,解决问题的成本是最低的。
PART
单测具备Fast 、 Stable、QuickDiagnosis特性,更适合集成至Devops流水线中进行持续回归
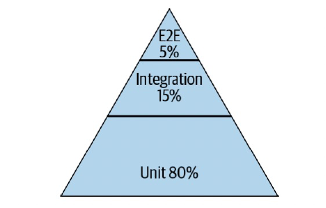
图2 Google测试金字塔
大家应该对Google的测试金字塔比较熟悉,Google测试金字塔中占比最高的是单测用例,达到了80%,再往上才是集成测试、端到端测试。为什么单测能够作为大底座这样的存在呢?主要原因在于单测具备Fast 、 Stable、QuickDiagnosis特性,这些特性使得单测更适合于集成到Devops流水线里面去做持续回归,在我们的项目里面更多比例的测用例也应该是单元测试用例。
PART
实际研发流程中单测比例低,面临开发成本高、运维难等问题
然而,在实际研发流程中,我们看到更多的并不是一个正金字塔,反而是一个倒金字塔。实际项目中单测用例占比往往很低,更多的测试被推到了集成测试、甚至是联调测试阶段。我们发现造成这种现象的主要原因是单测的开发成本、运维成本普遍很高。如何能够智能化地提升单测环节的效能呢?关键的技术方向就是去做测试用例的自动生成。
2
相关研究
测试用例自动生成其实在学术界一直是比较热门的研究方向,这里和大家一起分享下目前学术界已有的研究方向和相关成果。

图3 测试用例自动生成相关研究
PART
模糊测试Fuzzing
Fuzzing的主要思路是通过构造大量的测试输入来去发现软件里面存在的问题。2013年AFL工具发布,AFL首次在Fuzzing里使用了通过插装获取代码覆盖,从而来引导Fuzzing的方式。随后以覆盖率为引导的Fuzzing也被使用到了测试用例自动生成领域。
PART
符号执行
符号执行是一个程序分析非常经典的概念,主要是通过解析程序的执行路径,用符号模拟输入并获得输出。很多研究者也在尝试通过使用符号执行的结果来进行测试用例自动生成。
PART
基于搜索 Search Based Software Testing
Search Based Software Testing的思路是从问题解空间出发,通过一些启发式的搜索算法来去解决测试用例生成的问题。SBST的可扩展性很高,在整体的算法框架之下,可以随意切换搜索算法,比如遗传算法、爬山算法、多目标搜索算法等等,都可以很好的融入到这个框架里面来去做这个用例生成。
3
难点和挑战
当我们将已有研究成果去落地到实际系统时,会遇到什么样的难点和挑战呢?这里列出了三大类挑战,涵盖了测试用例自动生成、执行、运维的整个生命周期。

图4 测试用例自动生成的难点和挑战
PART
测试用例生成
测试用例生成是最基础、最核心的环节。在实际系统中进行测试用例生成通常会面临复杂数据类型、复杂语言特性的情况。对于复杂情况的处理能力决定了生成用例的覆盖率效果。除了复杂语法外,断言生成也是测试用例生成的难点之一。我们的测试用例之所以能够有效地发现问题,是因为用例中包含断言,因此测试用例自动生成需要能够包括断言的生成能力。
PART
测试用例执行
测试用例生成后,就来到了执行这个环节。执行环节最重要的是有一个稳定的运行环境。相信大家肯定都会遇到这种场景,测试用例跑不通或者多次运行结果不一致,本质都是用例不稳定。为了保证用例能够稳定运行,是需要去做很多Mock的。比如代码获取了当前机器的IP,需要通过对IP的mock来确保无论测试用例跑在哪台机器上都能够得到稳定的返回值。用例运行稳定之后,要考虑运行效率和运行稳定性。系统越复杂,对应测试用例的量级也越高。大规模单元测试用例的运行过程中,需要保证运行效率和稳定性,才能融入DevOps流水线进行持续回归。
PART
测试用例运维
最后是测试用例的运维。测试用例的运维包括了:1)存量用例汰换。被测代码变更后,部分旧的测试用例会失效。比如,被测代码的某个方法在变更过程中被删除了,那么涉及到这个方法的测试用例都会失效。对于失效用例,我们需要能够把它们汰换掉。2)增量用例生成。迭代变更时会有新的代码进来,对于新增的代码需要能够触发用例生成,将增量用例补充进来。3)回归分析。在历史存量用例的回归过程中,会出现用例失败报错的情况。针对这些失败的情况,我们需要进行降噪处理过滤掉无效失败,从而去发现真正的代码变更导致的问题。
4
测试用例智能生成SmartUnit
上面讲了测试用例自动生成这项技术在实际系统中落地会遇到的很多难点和挑战,在这部分就来介绍我们在蚂蚁所做的测试用例智能生成产品SmartUnit。
01
产品能力介绍
SmartUnit是智能单元测试用例生成产品,致力于解决单元测试环节里测试用例的自动生成执行态化和管理,SmartUnit的产品能力包括了快速提升覆盖率和智能探测异常。
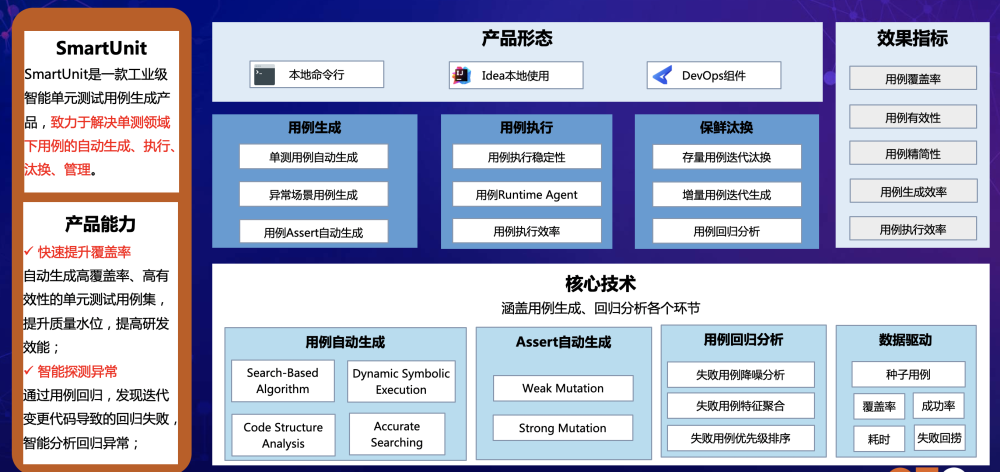
图5 SmartUnit能力大图
SmartUnit产品提供了三种使用方式,涵盖Local测试和回归测试阶段:
PART
本地命令行
提供核心能力Jar包,用户可以通过本地java -jar来执行jar包做用例生成。这种使用方式适用于Local测试阶段,在开发同学写完代码后,直接在本地就可以生成用例,进行单测验证。
PART
IDEA插件
IDEA插件与本地命令行一样,也适用于Local测试。相比于本地命令行,IDEA插件给用户带来了操作方式上的便捷。不需要执行多条命令,而是仅仅右键单击被测类,即可一键生成测试用例。
PART
DevOps组件
为减轻用例运维成本,我们提供了DevOps组件。通过DevOps组件,可以跟随每一次的变更,每一次的PR或者MR来去自动触发这个组件,自动去做这个用例生成与汰换。下图展示了我们与蚂蚁Devops融合后的流水线全生命周期管理示例。
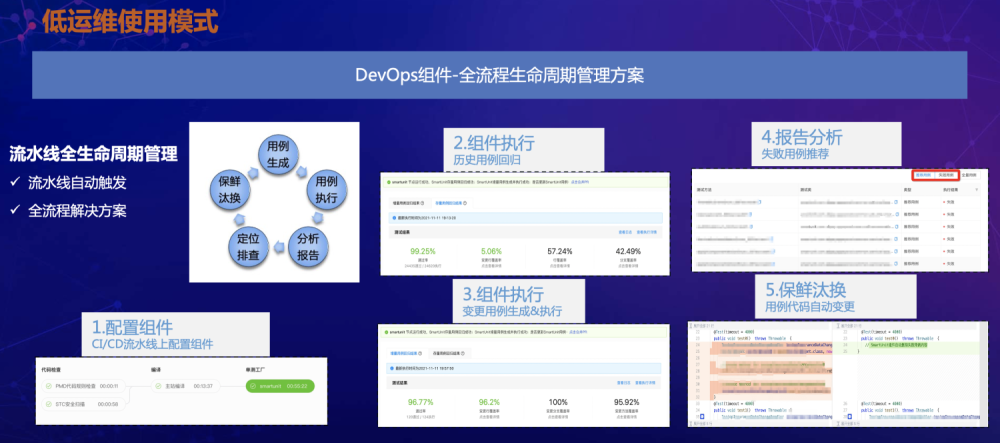
图6 SmartUnit与蚂蚁Devops流水线融合
对于SmartUnit这类测试用例自动生成产品,我们认为核心评价指标应该包括五个:
PART
用例覆盖率
我们不管去怎么做测试这个环节,最终希望的都是都能够对代码有更深度的覆盖,对代码有更完整的测试。目前SmartUnit自动生成用例的覆盖率超过60%,在部分系统上可达到80%。
PART
用例有效性
用例有效性用于度量用例到底有没有作用,会不会在代码变更的情况下出现执行失败。我们度量有效性的方式是基于源码攻击,对于源码进行模拟变更,测试用例是否能够发现变更。目前SmartUnit自动生成用例的有效性超过60%,高于人工手写的测试用例。
PART
用例精简性
单元测试用例一般是精简的,甚至于是可读的。只有精简的用例才能够合并到代码库中持续进行维护。因此用例的精简性也是非常重要的指标。目前SmartUnit对生成的用例会进行以行覆盖/分支覆盖为指标的精简,确保保留下来的用例都是对覆盖率有正向影响的。
PART
用例生成效率
用例生成效率用来评价自动用例生成产品的提效能力,通过自动生成的效率提升,从而提升单测环节的效能。
PART
用例执行效率
单元测试用例的量级相对会比较大,针对大规模的单测用例,需要保障用例执行效率才不会阻塞CI流水线。面对2~3万的测试用例量级,SmartUnit可以在30min内执行完。
02
自动生成用例示例
我们说了这么久用例自动生成,这里直观看一下SmartUnit自动生成用例的样子。SmartUnit用例包含以下四大部分:
用例注释:直观的告诉大家这个用例在测那些被测代码、使用什么样的入参、校验什么样的返回值;
Mock数据:单测用例里最为基本的一部分,也是占比最大的一部分。SmartUnit会通过Mock的方式屏蔽掉依赖;
方法调用:请求被测方法,获取返回值;
结果校验:对方法返回值进行Assert。
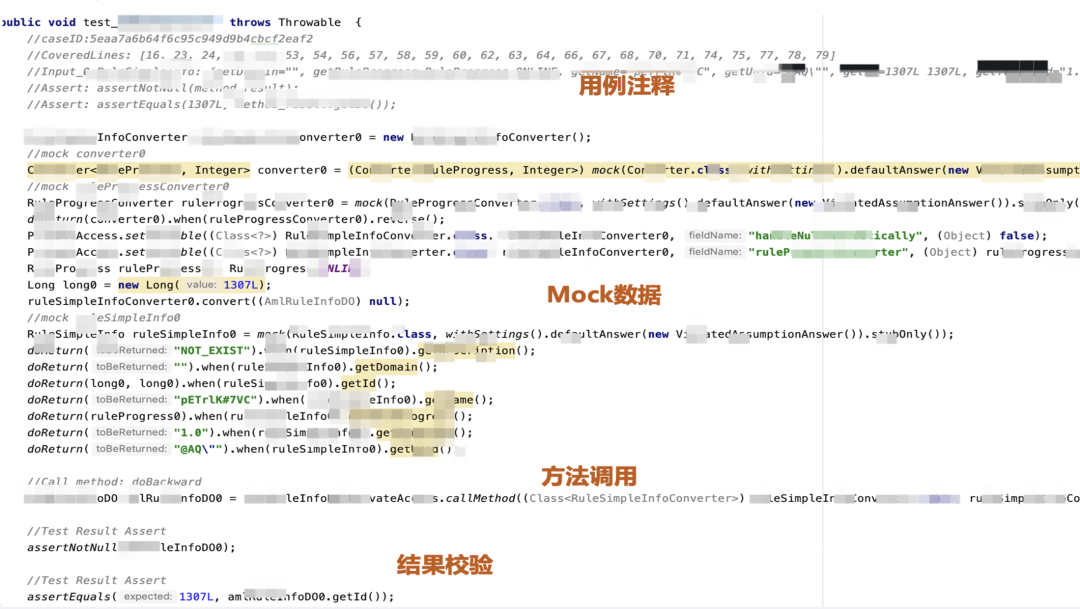
图7 SmartUnit自动生成用例示意
03
核心算法和技术
为了达成我们在产品能力上的目标,SmartUnit底层具备完整的核心算法架构来确保自动生成用例的覆盖率、有效性等指标水位。下图是SmartUnit从0到1进行用例生成的算法架构。
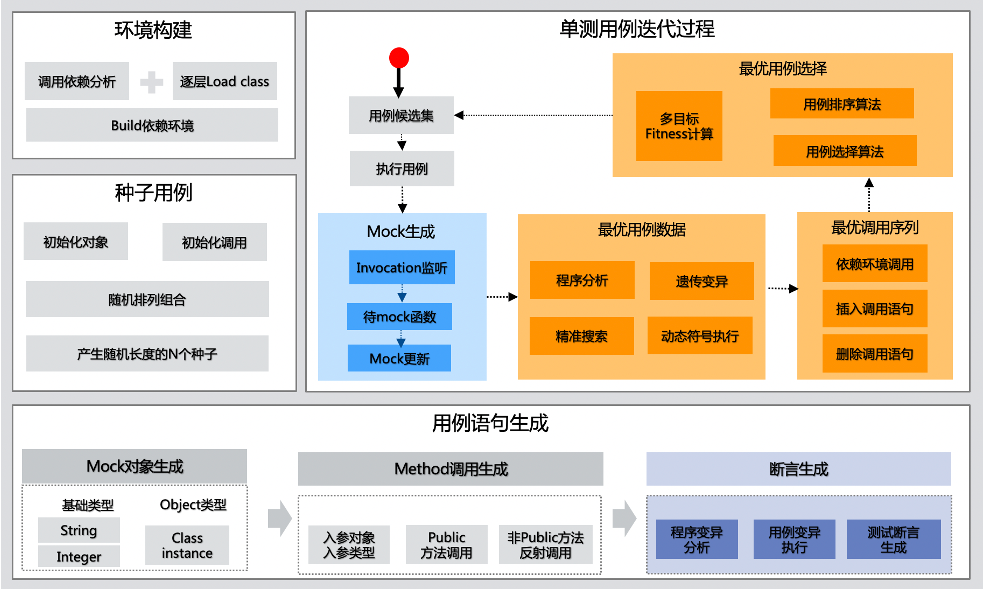
图8 SmartUnit算法架构
SmartUnit使用动态多目标搜索作为主体算法框架,结合程序分析、符号执行等技术共同完成从0到1进行用例生成。从整体框架上包含环境构建、种子用例生成、单测用例迭代、用例语句生成。
PART
环境构建
通过加载被测类和被测类的依赖,从而构建出一套可运行环境。后续的算法迭代强依赖于环境构建是否成功。
PART
种子用例生成
有了可运行环境后,会进行种子用例的生成。种子用例一般比较简单,只包含一些初始化的对象和调用。
PART
单测用例迭代
种子用例作为单测迭代的初始状态被传入到真正的用例迭代流程中,在用例迭代流程中对种子不断地修改、优化、迭代,最终产出我们需要的测试用例集。在用例迭代过程中,通过Mock动态生成算法、最优用例数据生成算法、最优调用序列算法来对用例的完整性进行填充,包括Mock语句和方法调用语句。最终,需要执行用例来确定它的覆盖效果,根据覆盖率效果进行最优用例选择。选择出来的用例作为下一次迭代的种子,一代一代地迭代下去。
整个迭代过程有两个终止条件。第一个是覆盖率达到了预期的值,第二个是达到了设置的时间域值。
PART
用例语句生成
与整个单测用例迭代过程相配合的,是用例语句生成。用例语句生成包括Mock语句、Method调用语句、Assert语句。其中值得一提的是Assert语句自动生成,在SmartUnit中使用基于Mutate的断言自动生成算法,这也是目前在学术界比较广泛认可的断言生成方式。
04
落地效果
最后介绍在蚂蚁SmartUnit的落地效果。目前SmartUnit已经在蚂蚁多个BU中使用,接入系统数据1000+。
用例覆盖率维度上,SmartUnit自动生成用例可以达到60%+的效果,结合历史存量用例后平均覆盖率达到80%+;
用例有效性维度上,SmartUnit作为底层能力支持了蚂蚁内部编程活动。针对活动中提交的PR,67%的PR发现了问题,共发现34个问题,包括7个有效BUG和27个健壮性问题。
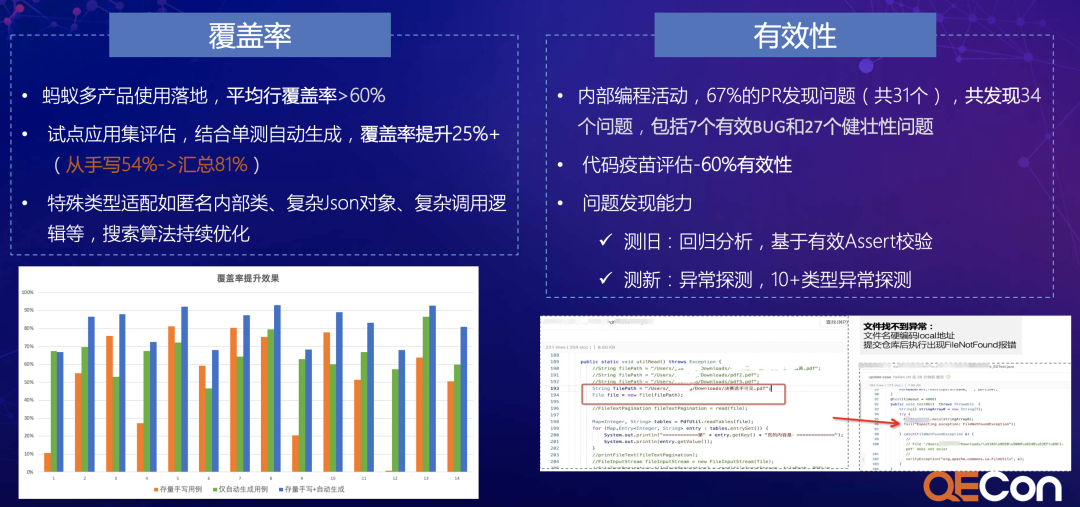
图9 SmartUnit落地效果
05
总结与展望
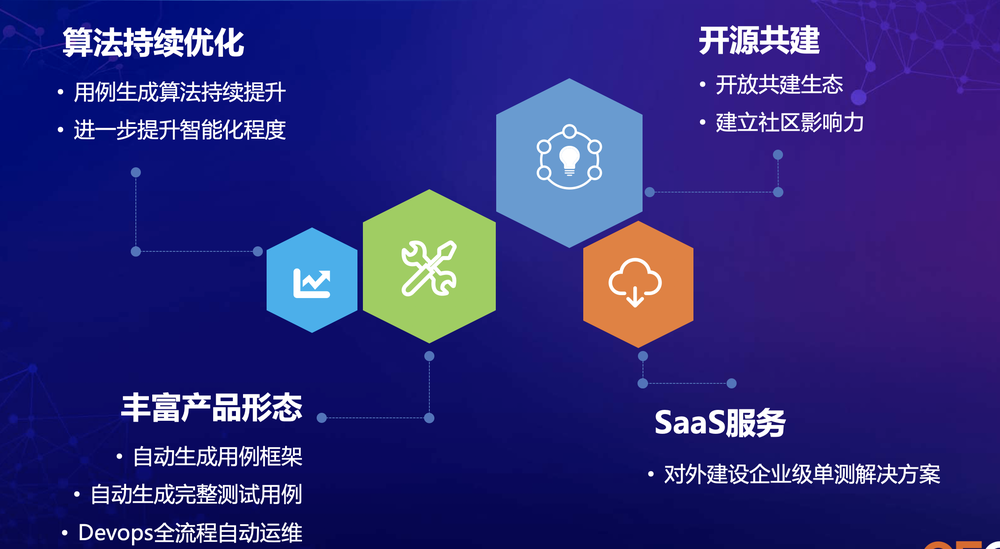
图10 总结与展望
面向未来发展,SmartUnit的发力方向包括:算法持续优化、丰富产品形态、开源共建、SaaS服务。
审核编辑 :李倩
-
智能化
+关注
关注
15文章
5054浏览量
56467 -
代码
+关注
关注
30文章
4865浏览量
69755 -
数据类型
+关注
关注
0文章
236浏览量
13715
原文标题:蚂蚁测试用例智能生成技术架构与实践
文章出处:【微信号:软件质量报道,微信公众号:软件质量报道】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
直流充电测试负载关键技术解析
是德科技携手Alea成功验证3GPP EUTRA任务关键型测试用例
蚂蚁集团宣布新一轮组织架构调整
是德科技助力三星电子验证FiRa 2.0安全测距测试用例
边缘计算架构设计最佳实践
端到端测试用例怎么写
TSMaster 测试报告生成器操作指南

是德科技获得5G NR FR1 1024-QAM 解调测试用例的认证
鉴源实验室·ISO 26262中测试用例的得出方法-等价类的生成和分析






 工商网监
工商网监
评论