 TOIST借助COCO掩码将问题扩展到实例分割问题实现更精细的定位
TOIST借助COCO掩码将问题扩展到实例分割问题实现更精细的定位

0. 引言
归功于大规模视觉语言模型,名词指代表达理解模型已经取得了巨大的进展。然而,在像智能服务机器人这样的现实交互中,系统输入通常较为隐晦(比如舒服得坐下这样的动作),现代视觉语言模型设计是否能有效地理解动词所指仍然有待探索。
1. 论文信息
2. 摘要
目前的指代表达理解算法可以有效地检测或分割名词所指的对象,但如何理解动词指代仍然是一个有待探索的问题。因此,我们研究了具有挑战性的面向任务的检测问题,该问题旨在找到最好地由动词所指示动作的对象,如舒适地坐在上面。为了更好地为机器人交互等下游应用服务,我们将问题扩展到面向任务的实例分割。这项任务的一个独特要求是在可能的备选方案中选择首选候选方案。因此,我们求助于transformer体系结构,它自然地对成对查询关系进行建模,这构建了TOIST方法。为了利用预先训练的名词指代表达理解模型,以及我们可以在训练期间访问特权名词基础事实的事实,提出了一种新的名词-代词提取框架。名词原型以无监督的方式生成,并且上下文代词特征被训练来选择原型。因此,网络在推理过程中保持名词不可知。我们在面向任务的大规模数据集COCO-Tasks上进行测试并实现比最佳报告结果高出10.9%。提出的名词代词提取可以将mAPbox和mAPmask分别提高2.8%和3.8%。
3. 算法分析
3.1 任务描述
TOIST这篇文章目的是解决面向任务的检测问题,那么什么是面向任务呢?如图1右上角所示,当输入为“涂抹黄油”时,系统会输出叉子的检测框,因为叉子可用于涂抹黄油。当然这只是COCO-Tasks提出的目标检测问题,TOIST还借助现有的COCO掩码将问题扩展到实例分割问题,以此来实现更精细的定位。例如当输入为“舒服得坐着”时,系统会分割出沙发。因此,TOIST提出的面向任务的实例分割方案(图1底部)可以很好得在点云分割和三维重建等领域发挥作用,对于下游机器人的交互应用具有重要意义。 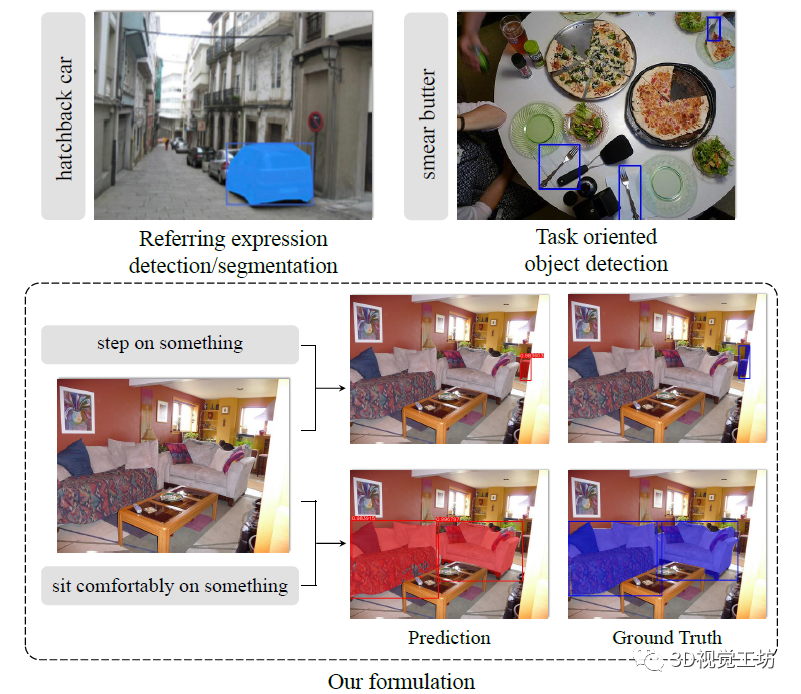 图1 左上:名词指代表达理解,右上:面向任务的检测,下部:面向任务的实例分割。 当然了,面向任务的检测/分割方法的一个有趣且具有挑战性的特征是内在歧义。例如,在图1的右上图中,比萨饼皮也可以用来涂抹黄油。如果我们手边既没有叉子也没有比萨饼皮,仍然可以用盘子涂抹黄油。以及如图1底部所示。当我们考虑要踩的物体时,椅子是更好的选择,因为沙发很软,桌子移动起来很重。当需要舒适地坐着时,沙发显然是最好的选择。换句话说,提供动词的对象是不明确的,算法需要对偏好进行建模。
图1 左上:名词指代表达理解,右上:面向任务的检测,下部:面向任务的实例分割。 当然了,面向任务的检测/分割方法的一个有趣且具有挑战性的特征是内在歧义。例如,在图1的右上图中,比萨饼皮也可以用来涂抹黄油。如果我们手边既没有叉子也没有比萨饼皮,仍然可以用盘子涂抹黄油。以及如图1底部所示。当我们考虑要踩的物体时,椅子是更好的选择,因为沙发很软,桌子移动起来很重。当需要舒适地坐着时,沙发显然是最好的选择。换句话说,提供动词的对象是不明确的,算法需要对偏好进行建模。
3.2 算法原理
近年来Transformer大火,TOIST的作者认为注意力机制可以很好得对候选对象之间的相对偏好进行建模,因此设计了一种面向任务的实例分割Transformer。 众所周知,训练Transformer需要大量数据,而大规模的具有相对偏好的动词参考数据非常少见。因此作者从另一个角度出发,探索了在名词指代表达理解模型中重用知识的可能性,即使用代词如某物作为代理,并从聚类生成的名词嵌入原型中提取知识。 具体来说,TOIST首先使用特权名词训练具有动词-名词输入的TOIST模型(例如,踩在图1底部的底部面板的椅子上)。但是在推理过程中,不能访问名词椅子,因此用动词代词输入(例如,踩在某物上)训练第二个TOIST模型,并从第一个TOIST模型中提取知识。因此,第二TOIST模型在推理期间保持名词不可知,并且比直接用动词-代词输入训练模型获得更好的性能。这个框架被称为名词-代词提炼。总体来说,将特权名词信息提取为代词特征的想法非常新颖! 如图2所示为TOIST网络的具体架构,TOIST包含三个主要组成部分:多模态编码器(棕色)用于提取标记化特征,Transformer编码器(绿色)用于聚合两个模态的特征,Transformer解码器(蓝色)用于预测具有注意力的最合适对象,其中cluster loss和soft binary target loss分别用于提取特权名词知识和偏好知识。 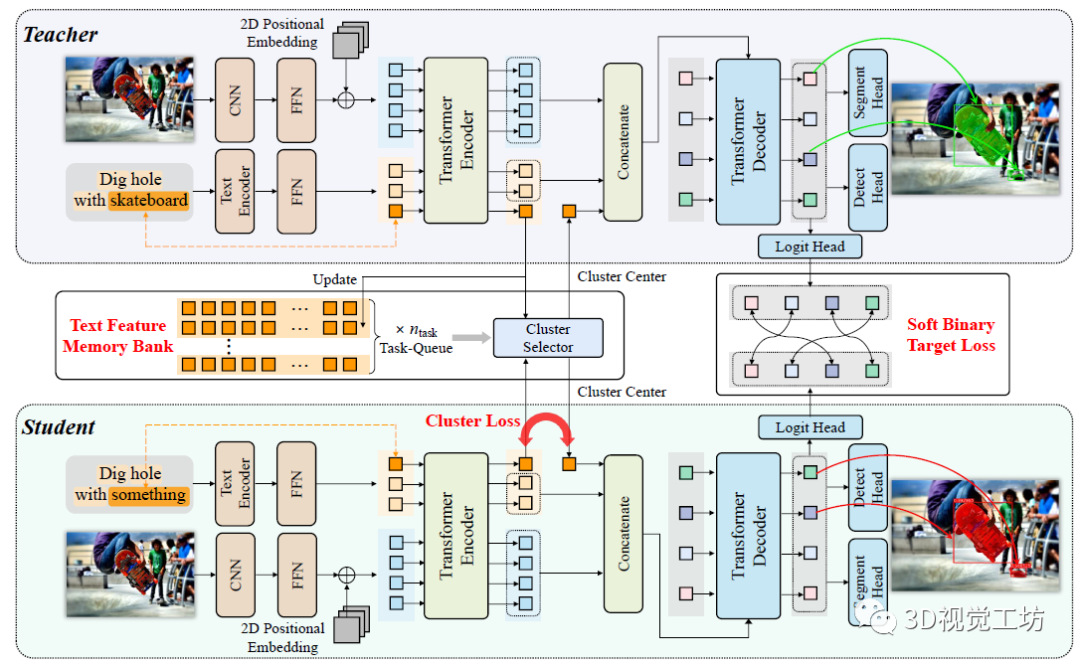 图2 TOIST网络架构和名词-代词提炼框架 概括起来,TOIST这篇文章有以下四个方面的贡献: (1) 第一次将面向任务的检测任务升级为面向任务的实例分割,这个新的解决方法对机器人交互应用有实用价值。 (2) 不同于现有的两阶段模型(先检测对象然后排序),TOIST提出了第一个基于Transformer的方法来进行面向任务的检测/分割。它只有一个阶段,并且自然地在对象查询上用自注意力来模拟相对偏好。 (3) 为了利用名词指代表达理解模型中的特权信息,TOIST提出了一个新的名词-代词提取框架。它在mAP box和mAP mask分别提升了+2.8%和+3.8%。 (4) 在COCO-Tasks数据集上取得了SOTA结果,比mAP box的最佳结果高出10.9%。
图2 TOIST网络架构和名词-代词提炼框架 概括起来,TOIST这篇文章有以下四个方面的贡献: (1) 第一次将面向任务的检测任务升级为面向任务的实例分割,这个新的解决方法对机器人交互应用有实用价值。 (2) 不同于现有的两阶段模型(先检测对象然后排序),TOIST提出了第一个基于Transformer的方法来进行面向任务的检测/分割。它只有一个阶段,并且自然地在对象查询上用自注意力来模拟相对偏好。 (3) 为了利用名词指代表达理解模型中的特权信息,TOIST提出了一个新的名词-代词提取框架。它在mAP box和mAP mask分别提升了+2.8%和+3.8%。 (4) 在COCO-Tasks数据集上取得了SOTA结果,比mAP box的最佳结果高出10.9%。
3.3 名词代词提炼
TOIST有两种输入形式,作者发现由于目标名称(名词)的特权信息,使用动名词输入的TOIST在mAP box和mAP mask上的表现提升了11.8 %和12.0 %,结果如表1所示。作者还进行了另外两个预实验:将动词-名词模型中的代词特征lpron或ltr直接替换为动词-名词模型中对应的名词特征lnoun或ltr,这种替换直接提高了性能。但是在推理过程中,基本真值对象的名词是不可用的,作者认为一个合理的名词-名词蒸馏框架可以在不违反名词不可知性约束的前提下利用动词-名词模型的丰富知识。 表1 与文本相关的几种不同设置下的定量结果 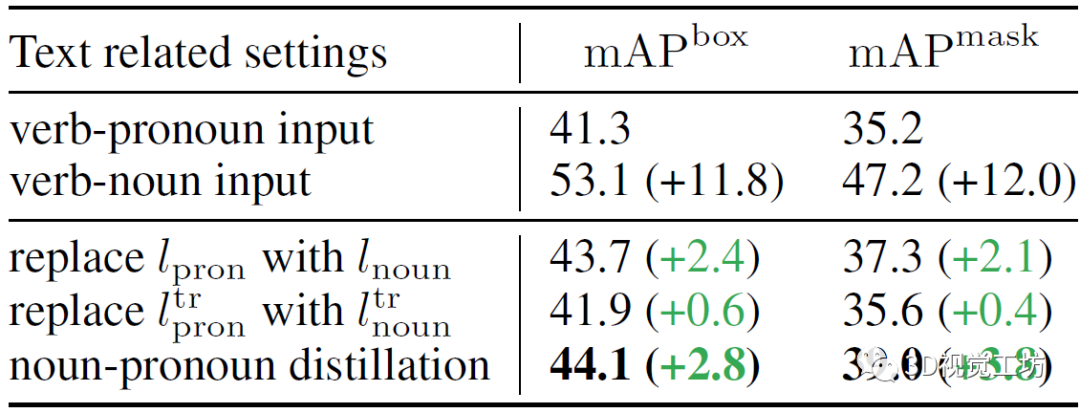 在图2所示的网络框架中,两个TOIST模型被同时训练。教师(图2顶部)和学生(图2底部)分别将动词-名词和动词-代词描述作为输入,并使用具有记忆库和聚类提取方法来提取从名词到代词的优先的以对象为中心的知识(图2左中)。作者还使用一个软二进制目标损失来提取偏好知识(图2中右),其中Gpred是用于计算偏好得分Spred的对数。此外,由于一个任务可以由许多不同类别的对象承担,因此作者建立了一个文本特征记忆库来存储名词特征,通过它可以选择一个原型来代替代词特征和提取知识,作者称这个过程为聚类蒸馏。
在图2所示的网络框架中,两个TOIST模型被同时训练。教师(图2顶部)和学生(图2底部)分别将动词-名词和动词-代词描述作为输入,并使用具有记忆库和聚类提取方法来提取从名词到代词的优先的以对象为中心的知识(图2左中)。作者还使用一个软二进制目标损失来提取偏好知识(图2中右),其中Gpred是用于计算偏好得分Spred的对数。此外,由于一个任务可以由许多不同类别的对象承担,因此作者建立了一个文本特征记忆库来存储名词特征,通过它可以选择一个原型来代替代词特征和提取知识,作者称这个过程为聚类蒸馏。
4. 实验
TOIST模型在COCO-Tasks数据集上进行实验,这应该是唯一涉及实例级偏好的数据集。COCO-Tasks数据集包含14个任务。对于每个任务,有3600个训练图像和900个测试图像。在每个图像中,首选对象(一个或多个)的框被用作检测的基础事实标签。基于现有的COCO掩码,作者将数据集扩展到实例分割版本。
4.1 与SOTA方法的比较
表2显示,在COCO-Tasks上,带有名词-代词蒸馏的TOIST取得了最好结果。TOIST提出的一阶段方法达到了41.3%的mAP box和35.2% mAP mask,比之前最好的结果(Yolo+GGNN和Mask-RCNN+GGNN)分别提高了8.1%和2.8%。名词-代词蒸馏将TOIST的性能进一步提升至44.1% (+10.9%)的mAP box和39.0% (+6.6%)的mAP mask。 表2 在扩展的COCO-Tasks数据集上,TOIST与SOTA基线的比较。 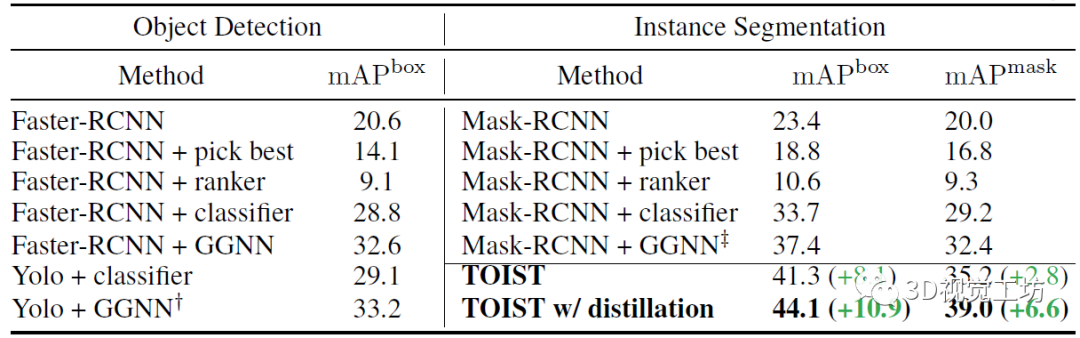
4.2 影响因素
图3(a)验证了自注意力机制能够自然地建模偏好的能力,其中两个普通的TOIST模型分别训练,其中一个不包含自注意力。需要注意的是,移除自注意力不会影响参数的数量。作者认为,对于具有自注意力的TOIST,随着偏好分数的来源变得更加深入,性能逐渐提升:从29.6% mAP box和25.0% mAP mask提升到41.3%和35.2%。TOIST解码器中的自注意力建模了对象候选之间的成对相对偏好。随着解码器的深入,对象候选之间的偏好关系逐渐被自注意力提取出来。在表3 (b)中,与基线相比,带有软二元目标损失的偏好蒸馏获得了2.1% mAP box和2.8% mAP mask的提升。 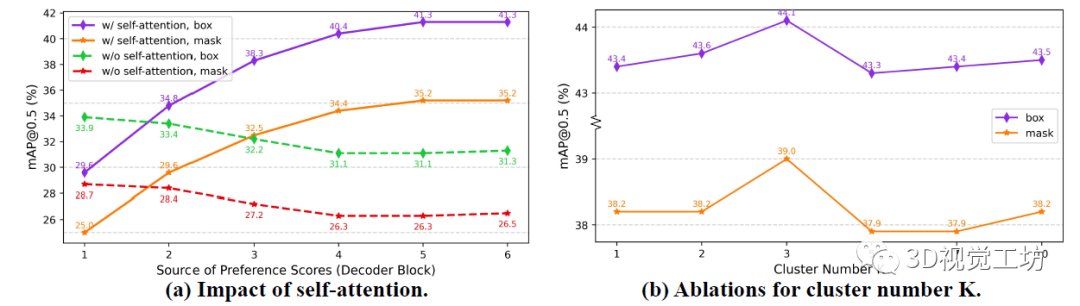 图3 (a)自注意力和(b)集群数量影响的实验 表3展示了使用聚类损失和用聚类中心(名词原型)替换代词特征的效果。在(c)和(e)中,单独使用两个成分比基准(a)分别增加了0.7% mAP box、1.9% mAP mask和0.7% mAP box、1.8% mAP mask。在(g)中性能提升1.0% mAP box和2.3% mAP mask。这些结果表明,聚类蒸馏方法可以提高学生的TOIST和增强动词指称表达式的理解。 表3 针对聚类的消融实验
图3 (a)自注意力和(b)集群数量影响的实验 表3展示了使用聚类损失和用聚类中心(名词原型)替换代词特征的效果。在(c)和(e)中,单独使用两个成分比基准(a)分别增加了0.7% mAP box、1.9% mAP mask和0.7% mAP box、1.8% mAP mask。在(g)中性能提升1.0% mAP box和2.3% mAP mask。这些结果表明,聚类蒸馏方法可以提高学生的TOIST和增强动词指称表达式的理解。 表3 针对聚类的消融实验 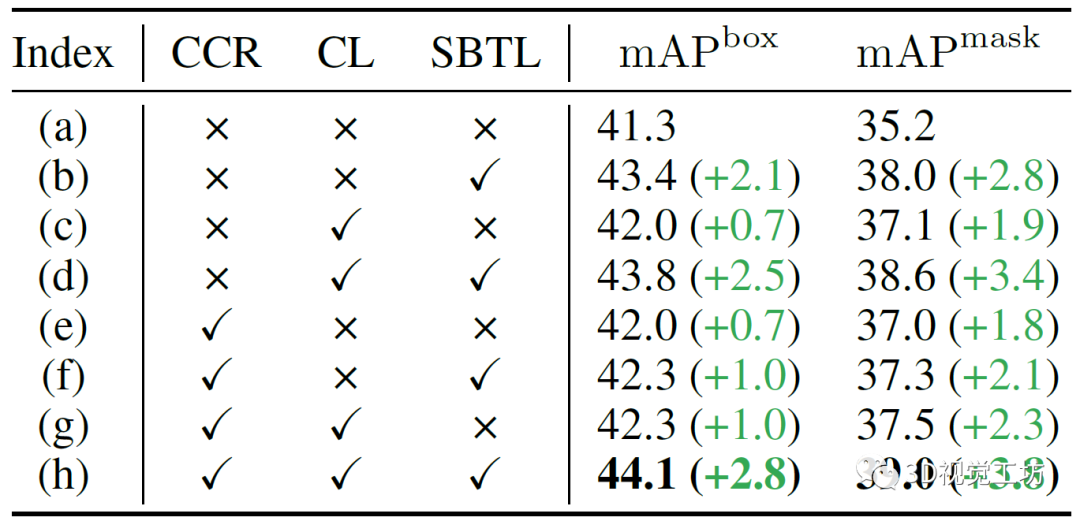 在图4中,作者可视化了预测结果(通过0.9的偏好阈值过滤)和代词标记的注意力图。在第一行中,当没有聚类蒸馏时,TOIST错误地偏好花朵而不是杯子,注意图也证实了这一点。但是聚类蒸馏的TOIST正确地选择了杯子,而对花的注意力被削弱了。这表明聚类蒸馏使学生TOIST能够减少动词-代词指称表达式的歧义。在第二行中,刀的边界框由两个模型正确检测。然而,在没有蒸馏的情况下,在盒子内的勺子和叉子上预测额外的实例面具。相反,随着蒸馏,TOIST预测的面具集中在刀上,注意力更集中在它上面。这表明,在集群蒸馏的情况下,TOIST可以更好地将任务研磨到对象框内的像素。同时,即使盒子是正确的,预测的掩模也可能是不准确的,这一事实使得机器人在执行特定任务时准确地抓住优选的物体具有挑战性。这证明了将面向任务的对象检测扩展到实例分割的重要性。
在图4中,作者可视化了预测结果(通过0.9的偏好阈值过滤)和代词标记的注意力图。在第一行中,当没有聚类蒸馏时,TOIST错误地偏好花朵而不是杯子,注意图也证实了这一点。但是聚类蒸馏的TOIST正确地选择了杯子,而对花的注意力被削弱了。这表明聚类蒸馏使学生TOIST能够减少动词-代词指称表达式的歧义。在第二行中,刀的边界框由两个模型正确检测。然而,在没有蒸馏的情况下,在盒子内的勺子和叉子上预测额外的实例面具。相反,随着蒸馏,TOIST预测的面具集中在刀上,注意力更集中在它上面。这表明,在集群蒸馏的情况下,TOIST可以更好地将任务研磨到对象框内的像素。同时,即使盒子是正确的,预测的掩模也可能是不准确的,这一事实使得机器人在执行特定任务时准确地抓住优选的物体具有挑战性。这证明了将面向任务的对象检测扩展到实例分割的重要性。 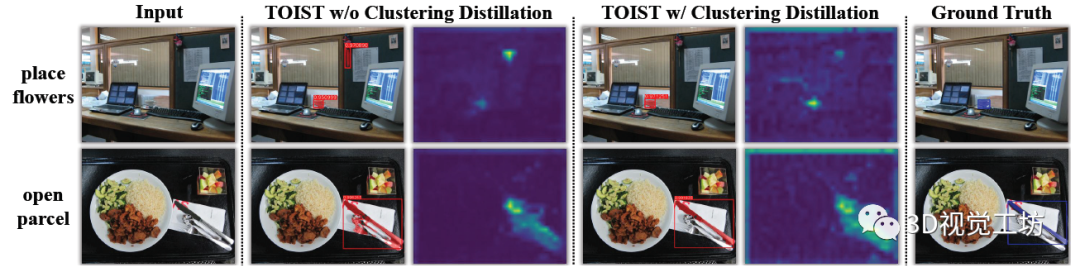 图4 代词标记的预测结果和注意力图的可视化
图4 代词标记的预测结果和注意力图的可视化
4.3 消融研究和定性结果
表4显示了不同代词输入下的TOIST结果。在普通TOIST和带有蒸馏的TOIST中,使用某物、它或它们会导致类似的结果。而一个毫无意义的字符串abcd产生较少的改进,证明了鲁棒性。 表4 针对代词输入的消融实验 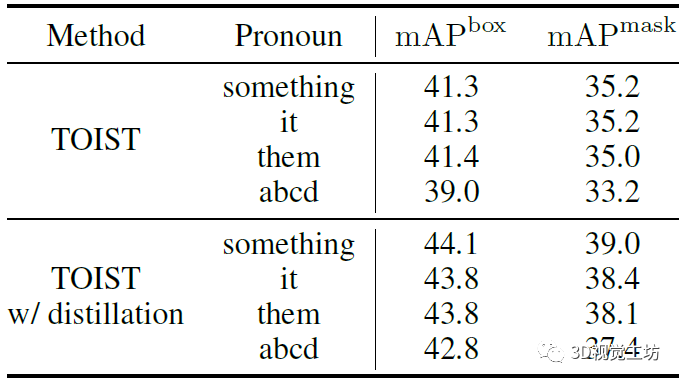 表5显示了不同任务数的消融研究,其中第一行对应于没有蒸馏的纯TOIST,其他行显示了不同数目下蒸馏的结果。总体而言,较小的n会带来更好的性能,这是因为不同任务之间的交互更少而降低了问题的复杂性,这使得通过名词-代词蒸馏更容易提高模型理解动词的能力。 表5 面向任务的目标检测任务数消融实验
表5显示了不同任务数的消融研究,其中第一行对应于没有蒸馏的纯TOIST,其他行显示了不同数目下蒸馏的结果。总体而言,较小的n会带来更好的性能,这是因为不同任务之间的交互更少而降低了问题的复杂性,这使得通过名词-代词蒸馏更容易提高模型理解动词的能力。 表5 面向任务的目标检测任务数消融实验 
5. 结论
在2022 NeurIPS论文“Centroid Distance Keypoint Detector for Colored Point Clouds”中,作者基于Transformer研究了面向任务的实例分割问题。TOIST在COCO-Tasks数据集上取得了SOTA结果,虽然没有更大数据集上的评估,但这对于许多机器人交互应用来说已经足够。
-
机器人
+关注
关注
213文章
31391浏览量
223550 -
模型
+关注
关注
1文章
3810浏览量
52253 -
数据集
+关注
关注
4文章
1240浏览量
26261
原文标题:NIPS2022开源!TOIST:通过蒸馏实现面向任务的实例分割Transformer
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何将范围从万到FFFF扩展到FRQQUPWM=44100
如何利用BTA06-600C将BT131的负载能力120W扩展到200W以上?
可以将ESP Basic扩展到ESP32吗?

AMD称其融聚渠道计划将扩展到行业与OEM渠道
苹果将iPhone 的保修范围扩展到全球
三星借助MicroLED技术可扩展到292英寸,显示屏与周围环境无缝融合!
苹果可能正在寻求将苹果地图的范围扩展到其iDevices之外
AN-1529:使用AD9215高频VGA将10位65 MSPS ADC的动态范围扩展到100 dB以上

用于实例分割的Mask R-CNN框架
将5G安全地扩展到战场空间
基于通用的模型PADing解决三大分割任务

基于SAM设计的自动化遥感图像实例分割方法

通过应用频率将TPS92210的调光范围扩展到通用AC范围



评论