 目标检测YOLO系列算法的发展过程
目标检测YOLO系列算法的发展过程
本文中将简单总结YOLO的发展历史,YOLO是计算机视觉领域中著名的模型之一,与其他的分类方法,例如R-CNN不同,R-CNN将检测结果分为两部分求解:物体类别(分类问题),物体位置即bounding box(回归问题)不同,YOLO将任务统一为一个回归问题。也就是相对于R-CNN系列的“看两眼”(候选框提取与分类),YOLO只需要 You Only Look Once。
目标检测
我们人类只需要看一眼图像就能知道图像里面包含了那些物体,能够知道这些物体在哪里,以及他们之间的相互关系。这是人类进行目标检测的过程,但是当谈到人工智能计算机视觉中的视频和图像分析时,目标检测是一个有趣和不断发展的主题,它从图像和视频中提供有意义和有价值的信息,可以为医疗保健、产品优化、人脸识别、自动驾驶,卫星图像分析等不同领域提供巨大的帮助。检测一个对象并从图像中获得高层次的语义或理解将通过3个步骤:
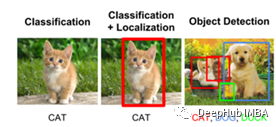
1、分类:这是一个有监督的学习任务,它将训练一个模型,如支持向量机(SVM), AdaBoost来理解一个对象是否在图像中
2、定位:通过边界框来区分对象图像,显示对象是否在图像中(分类)
3、检测:精确检测物体所在的位置(物体定位)和它们所属的组(物体分类)的过程。
下图显示了目标检测模型的结构。像人工智能中的所有算法一样,它从输入层开始(输入一个图像),目标检测的两个主要部分是Backbone和Head。Backbone的作用是提取特征,提供输入的特征映射表示,一般都会使用ImageNet上的预训练模型。Head基于特征进行训练,预测图像中物体的类别及其边界框。
在两阶段目标检测模型中, Faster R-CNN (Region-based Convolutional Neural Networks),使用区域建议网络在第一阶段和第二阶段生成和选择感兴趣区域,并将区域建议向下发送并使用卷积神经网络进行目标分类和边界框回归。两阶段检测器模型具有最高的准确率,但通常较慢,因为必须对每个选定区域进行预测。因此很难将其用作实时对象检测器。
单阶段目标检测器,本文的YOLO(You Only Look Once),通过创建输入图像的特征图、学习类别概率和整个图像的边界框坐标,将目标识别视为一个简单的回归问题。算法只运行一次。这样的模型虽然准确率稍微有所下降,但比两阶段目标检测器快得多,通常用于实时目标检测任务。
YOLO Version 1; 统一的实时目标检测框架
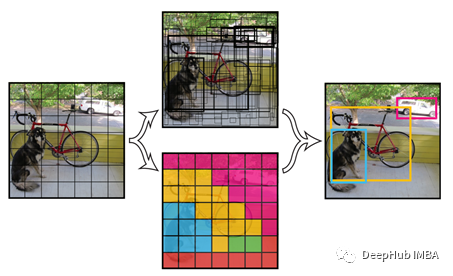
YOLO 是一个简单的且不复杂的对象检测模型,它对图片进行分析只需要“看一眼”,就可以预测目标对象及其在输入图片上的位置。该算法将目标检测定义为单个回归问题。将每个给定的图像划分为一个 S * S 网格系统,该网格系统是图像的子集或一部分,每个网格通过预测网格内对象的边界框数量来识别对象。
YOLO 执行一个神经卷积网络来识别网格中的对象,预测对象周围的边界框以及它们属于哪个类别的概率。概率被用作置信水平。卷积网络的初始层从图像中提取特征,全连接层预测概率。YOLO 工作流程如下图所示:

为了识别图像中的不同对象及其位置,使用多尺度滑动窗口扫描整个图像,因为对象可以在图像的每个部分以不同的大小显示。提取滑动窗口的最佳大小和数量是很重要的,而且这是计算密集型的因为不同数量的候选或不相关的候选会影响结果。通过这种方式YOLO可以与传统算法相媲美,并且速度更快。这些步骤的示例如下图所示。
YOLO V1的优势:可以高速实时检测物,能够理解广义对象表示,模型也不太复杂。
YOLO V1 的局限性:如果小对象以集群或组的形式出现,则模型效果,例如下图所示

YOLO V1 训练是基于损失函数来展示检测性能的,而损失函数没有考虑窗口的大小,大框中的小错误是显而易见的,但其实小框中的错误其实应该更加被关注,因为他对交并比的影响更大,交并比是一种评估指标,用于衡量数据集上对象检测器模型的准确性 [6]。
YOLO Version 2;YOLO9000:更快,更好,更强
对象检测模型应该快速、准确,并且可以识别各种对象类别。基于这个想法YOLO V2 出现了,与 YOLO V1 相比,在速度、准确性和检测大量物体的能力方面有各种改进。这个新版本训练了 9000 个新类别,所以被称作 YOLO9000。它将不同的数据集 ImageNet 和 COCO 结合起来,以提供更大量的分类数据,扩大检测模型的范围,并提高召回率 。COCO 用于目标检测,包含 80 个类别的 100,000 张图像。
YOLO V2 结构中使用Softmax 为每个边界框提供客观性分数。Softmax为每一类多类分类任务分配一个在0到1之间的十进制概率,在YOLO V2中,它也为图像中的对象提供了多类分类的可能性。召回率则衡量正确检测到真值对象的概率。YOLO V2 在分类和检测数据集上联合训练。该方法对图像进行标记以进行检测,识别边界框和对常见对象进行分类。还是用仅具有类标签的图像用于扩展算法可以检测的类别。YOLO V2 中一个有趣的点,除了试图提供更好和准确的结果外,还提供了一个比 YOLO V1 更简单的模型。
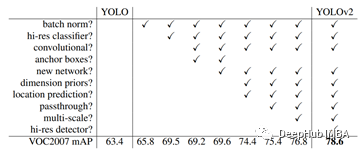
上表中看到,V2中增加了BN的操作。通过BN层对来自前一层的输入执行标准化和规范化,将输入值缩放转换。在Yolo V2中,Yolo V1的所有卷积层上添加BN,从而在Yolo V2中获得2%以上的精度提升。BN还有助于稳定训练,加速收敛,并在不过度拟合的情况下从模型中去除dropout。另一种提高准确率的技术是使用更高分辨率的输入,将输入尺寸从224*224更改为448*448,这将提高4%的MAP(平均平均精度)。
YOLO Version 3;小改进,大提升

在YOLO V3[9]中,只对YOLO的设计添加了一些更改,从而实现了更准确、更好和更快的设计。在预测边界的新结构中,继续使用V2的结构,但是增加了逻辑回归用于预测每个边界框的得分。当一个边界框在与真实对象重叠之预测结果比任何其他边界框都多时,预测结果就为 1。当边界框不是最佳但与真实对象重叠超过阈值时,预测则被忽略,并且还引入了Faster R -CNN的方法,在 YOLO V3 中将优先只考虑一个边界框。
下图显示了YOLO V3 上的性能对比
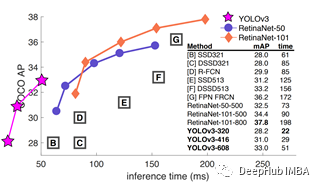
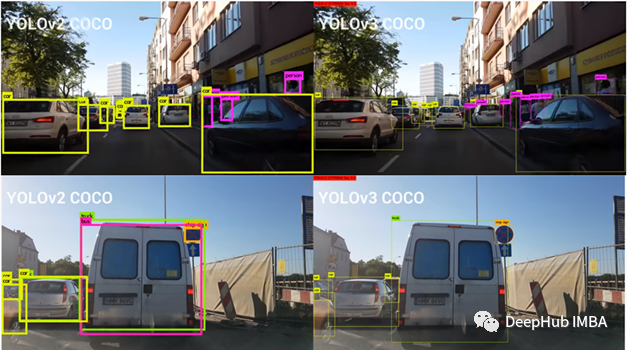
下图则对 YOLO v2 与 V3 的比较。很在 YOLO V3 中可以检测到一些较小的对象,而 V2 无法检测到。
除了准确性和比较之外,Redmon 和 Farhadi 在他们的论文中提到的重要一点是道德和计算机视觉的使用。由于军事研究小组非常关注这一领域,他们希望人们使用他们的新技术不是为了杀人,而是为了让别人快乐,让他们的生活更美好。这是论文中的原话:
we have a responsibility to at least consider the harm our work might be doing and think of ways to mitigate it. We owe the world that much.
这也是 Joseph Redmon 退出目标检测领域研究的原因,有兴趣的可以去搜下他TED的演讲。
YOLO Version 4;最佳速度和准确性
目标检测研究的重点是改进在该领域执行的模型的速度。随着时间的推移,YOLO 的应用在全球范围内不断增长,研究领域也增加了许多新的变化,在卷积神经网络 (CNN) 中,一些想法可以提高模型的准确性。YOLO V4 的主要目标是开发一种速度更快的目标检测器,并且具有易于训练和使用的并行计算能力。通过添加和组合一些新功能,例如加权残差连接 (WRC)、跨阶段部分连接 (CSP)、跨小批量标准化 (CmBN)、自我对抗训练 (SAT)、Mish激活函数、Mosaic 数据增强、DropBlock 正则化和 CIoU 损失等等,在 YOLO V4中实现了更好更快的模型。YOLO V4 讨论的一个重要主题是一个实时传统神经网络模型,该模型只需要传统 GPU 进行训练,从而为使用一般 GPU 的任何人提供训练、测试、实现实时、高质量的可能性,以及令人信服的目标检测模型。
下面是 YOLO V4 。这个新版本速度更快,并且表现出可比的性能。
在 YOLO V4 中,Alexey Bochkovskiy 等人总结了他们的主要贡献:
开发了一个高效而强大的目标检测模型,这使得每个使用 1080 Ti 或 2080 Ti GPU 的人都可以训练和测试一个超快速、实时、准确的目标检测模型。
他们在训练期间验证了最先进的 Bag-of-Freebies 和 Bag-of-Specials 检测方法的影响。
修改了state-of-the-art的方法,包括(Cross-iteration batch normalization)、PAN(Path aggregation network)等,使它们更高效,更适合单GPU训练。
总结
如果你查看 YOLO 的结构、源代码和包,就会发现它们结构良好、文档齐全且免费使用。
审核编辑:郭婷
-
计算机
+关注
关注
19文章
7494浏览量
87949 -
人工智能
+关注
关注
1791文章
47274浏览量
238479
原文标题:目标检测YOLO系列算法的进化史
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI模型部署边缘设备的奇妙之旅:目标检测模型
助力AIoT应用:在米尔FPGA开发板上实现Tiny YOLO V4
YOLOv10自定义目标检测之理论+实践
《DNK210使用指南 -CanMV版 V1.0》第四十一章 YOLO2物体检测实验
《DNK210使用指南 -CanMV版 V1.0》第四十章 YOLO2人手检测实验
《DNK210使用指南 -CanMV版 V1.0》第三十九章 YOLO2人脸检测实验
使用OpenVINO C# API部署YOLO-World实现实时开放词汇对象检测

慧视小目标识别算法 解决目标检测中的老大难问题

安全帽佩戴检测算法

OpenVINO™ C# API部署YOLOv9目标检测和实例分割模型
纵观全局:YOLO助力实时物体检测原理及代码
【EASY EAI Nano】RV1126实时读取摄像头并进行yolo检测显示
深入浅出Yolov3和Yolov4
在英特尔AI开发板上用OpenVINO NNCF优化YOLOv7






 工商网监
工商网监
评论