 如何在NVIDIA GPU上实现基于embedding 的深度学习模型
如何在NVIDIA GPU上实现基于embedding 的深度学习模型
Embedding 在深度学习推荐模型中起着关键作用。它们被用于将输入数据中的离散特征映射到向量,以便下游的神经网络进行处理。Embedding 通常构成深度学习推荐模型中的大部分参数,大小可以达到 TB 级。在训练期间,很难将它们放入单个 GPU 的内存中。因此,现代推荐系统可能需要模型并行和数据并行的分布式训练方法组合,以最佳利用 GPU 计算资源来实现最好的训练性能。
NVIDIA Merlin Distributed-Embeddings,可以方便TensorFlow 2 用户用短短几行代码轻松完成大规模的推荐模型训练。
背景
在数据并行分布式训练中,整个模型被复制到每个 GPU 上。在训练过程中,一批输入数据在多个 GPU 中分割,每张卡独立处理其自己的数据分片,从而允许计算扩展到更大批量的数据。在反向传播期间,计算的梯度通过 reduction 算子(例如, horovod.tensorflow.allreduce ) 来同步更新多个 GPU 间的参数。
另一方面,模型并行分布式训练中,模型参数被分割到多个 GPU 上。这种方法更适合分布存储大型 embedding。训练中,每个 GPU 通过 alltoall 通信算子(例如, horovod.tensorflow.alltoall) 访问不在本机中的参数。
在之前的相关文章中, 用 TensorFlow 2 在 DGX A100 上训练 100B + 参数的推荐系统 , Tomasz 讨论了如何将 1130 亿参数的 DLRM 模型中的 embedding 分布到多个 NVIDIA GPU 进行训练,并相比纯 CPU 的方案实现 672 倍的性能提升。这一重大突破可以将训练时间从几天缩短到几分钟!这是通过模型并行 embedding 层和数据并行 MLP 层来实现的。和 CPU 方案相比,这种混合并行的方法能够有效利用 GPU 的高内存带宽加速内存受限的 embedding 查找,并同时利用多个 GPU 的算力加速 MLP 层。作为参考, NVIDIA A100-80GB GPU 具有超过 2 TB / s 的带宽和 80 GB HBM2 存储)。
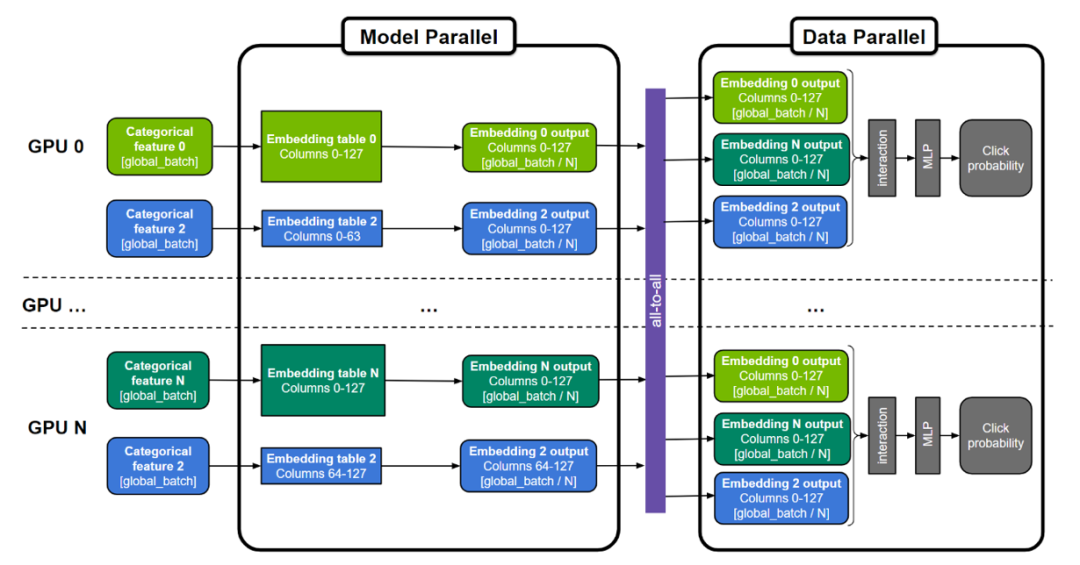
图 1. 用于训练大型推荐系统的通用“混合并行”方法
embedding 表可以按表为分割单位(图中表 0 和 N ),按“列”分割(图中表 2),或者按”行”分割。MLP 层跨所有 GPU 复制,而数字特征则可以直接输入 MLP 层。
然而,实现这种复杂的混合并行训练方法并不简单,需要领域内专家设计数百行底层代码来开发和优化。为了使其更普适,NVIDIA Merlin Distributed-Embeddings 提供了一些易于使用的 TensorFlow 2 的封装,让所有人都只需三行 Python 代码即可轻松实现模型并行。它提供了一些涵盖并拓展原生 TensorFlow 功能的高性能 embedding 查找算子。在此基础上,它提供了一个可规模化的模型并行封装函数,帮助用户自动将 embedding 分布于多个 GPU 上。下面将展示它如何实现混合并行。
分布式模型并行
NVIDIA Merlin Distributed-Embeddings 提供了
distributed_embeddings.dist_model_parallel 模块。它有助于在多个 GPU 之间分布embedding而无需任何复杂的代码来处理跨GPU间的通信(如 all2all )。下面的代码示例显示了此 API 的用法:

要使用 Horovod 以数据并行方式运行 MLP 层,请将 Horovod的 Distributed GradientTape 和 broadcast 方法替换成 NVIDIA Merlin Distributed-Embeddings 里同等的 API。以下示例直接取自 Horovod 文档,并进行了相对应修改。
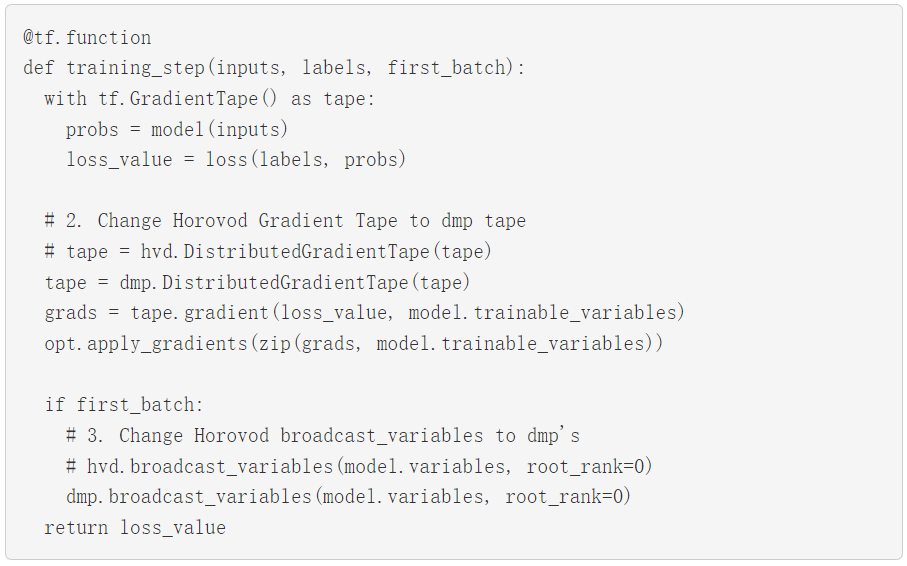
通过这些微小的改变,您就可以使用混合并行训练了!
我们还提供了以下完整示例: 使用 Criteo 1TB 点击日志数据训练 DLRM 模型以及扩展到 22.8 TiB 的合成数据模型。
性能
为了展示 NVIDIA Merlin Distributed-Embeddings 的性能,我们在 Criteo 1TB 数据集 DLRM 模型和最高达到 3 TiB embedding 的合成模型上进行了模型训练的基准测试。
Criteo 数据集上的 DLRM 模型基准测试
测试表明,我们使用更简单的 API 取得了近似于专家代码的性能。NVIDIA 深度学习 DLRM TensorFlow 2 示例代码现已更新为使用 NVIDIA Merlin Distributed-Embeddings 进行分布式混合并行训练,更多信息请参阅我们之前的文章, 用 TensorFlow 2 在 DGX A100 上训练 100B + 参数的推荐系统。README 中的基准测试部分提供了对性能结果的更多详述。
我们对 1130 亿个参数( 421 个 GiB 大小)的 DLRM 模型在 Criteo TB 点击日志数据集上用三种不同的硬件设置进行了训练:
仅 CPU 的解决方案。
单 GPU 解决方案,其中 CPU 内存用于存储最大的 embedding 表。
使用 NVIDIA DGX A100-80GB 的 8 GPU 的混合并行解决方案。此方案利用了 NVIDIA Merlin Distributed-Embeddings 里提供的模型并行 api 和 embedding API 。
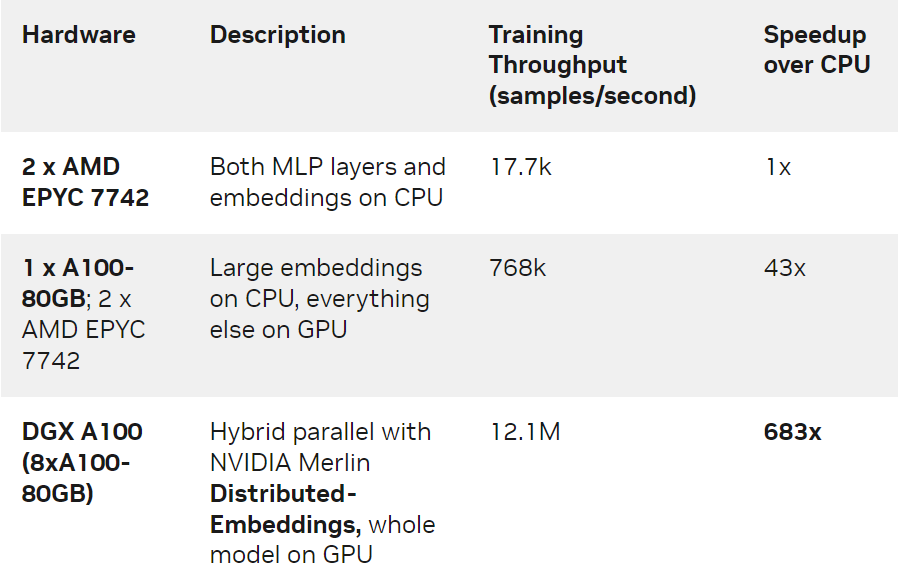
表 1. 各种设置的培训吞吐量和加速
我们观察到, DGX-A100 上的 NVIDIA Merlin Distributed-Embeddings 方案比仅使用 CPU 的解决方案提供了惊人的 683 倍的加速!我们还注意到与单 GPU 方案相比,混合并行的性能也有显著提升。这是因为在 GPU 显存中存储所有 embedding 避免了通过 CPU-GPU 接口查找 embedding 的开销。
合成模型基准测试
为了进一步演示方案的可规模化,我们创建了不同大小的合成数据以及对应的 DLRM 模型(表 2 )。有关模型生成方法和训练脚本的更多信息,请参见 GitHub NVIDIA-Merlin/distributed-embeddings 代码库。
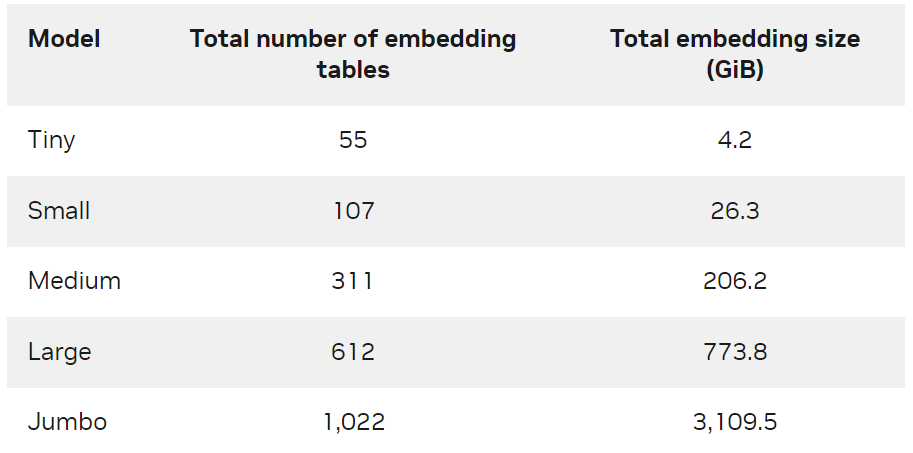
表 2. 合成模型尺寸
每个合成模型使用一个或多个 DGX-A100-80GB 节点进行训练,全局数据 batch 大小为 65536 ,并使用 Adagrad 优化器。从表 3 中可以看出, NVIDIA Merlin Distributed-Embeddings 可以在数百个 GPU 上轻松训练 TB 级模型。
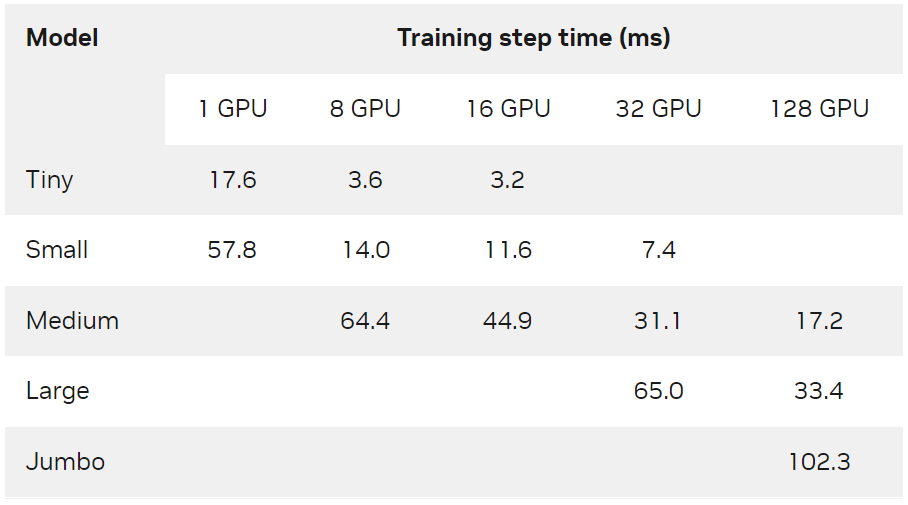
表 3. 各种硬件配置下合成模型的训练步长时间( ms )
另一方面,与传统的数据并行相比,即使对于可以容纳在单个 GPU 中的模型,多 GPU 分布式模型并行仍然提供了显著加速。表 4 显示了上述 Tiny 模型在 DGX A100-80GB 上的性能对比。
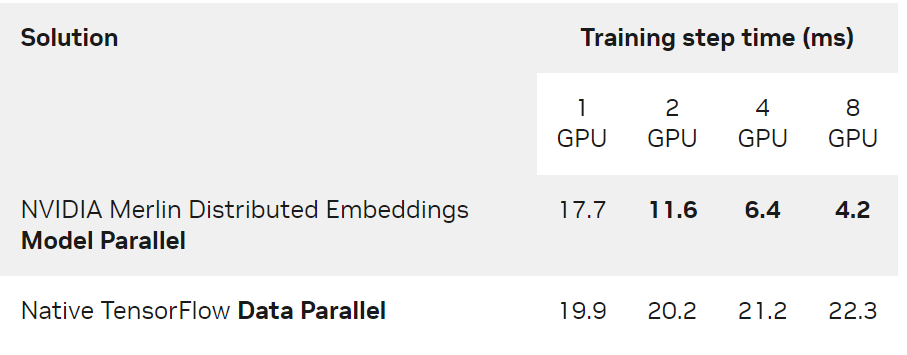
表 4. Tiny模型( 4.2GiB )的训练步长时间( ms )比较 NVIDIA Merlin Distributed-Embeddings 模型并行和原生 TensorFlow 数据并行
本实验使用了 65536 的全局批量和 Adagrad 优化器。
结论
在这篇文章中,我们介绍了 NVIDIA Merlin Distributed-Embeddings,仅需几行代码即可在 NVIDIA GPU 上实现基于 embedding 的深度学习模型,并进行可规模化,高效率地模型并行训练。欢迎尝试以下使用合成数据的可扩展训练示例和基于 Criteo 数据训练 DLRM 模型示例。
-
NVIDIA
+关注
关注
14文章
5108浏览量
104475 -
gpu
+关注
关注
28文章
4831浏览量
129780 -
模型
+关注
关注
1文章
3417浏览量
49479 -
深度学习
+关注
关注
73文章
5527浏览量
121882
原文标题:NVIDIA Merlin Distributed-Embeddings 轻松快速训练 TB 级推荐模型
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA在深度学习应用中或将取代GPU
【「基于大模型的RAG应用开发与优化」阅读体验】+Embedding技术解读
如何在vGPU环境中优化GPU性能
labview调用深度学习tensorflow模型非常简单,附上源码和模型
Nvidia GPU风扇和电源显示ERR怎么解决
在Ubuntu上使用Nvidia GPU训练模型
Mali GPU支持tensorflow或者caffe等深度学习模型吗
什么是深度学习?使用FPGA进行深度学习的好处?
NVIDIA GPU加快深度神经网络训练和推断
何时使用机器学习或深度学习
深度学习如何挑选GPU?

学习资源 | NVIDIA TensorRT 全新教程上线






 工商网监
工商网监
评论