 普通视觉Transformer(ViT)用于语义分割的能力
普通视觉Transformer(ViT)用于语义分割的能力

本文探讨了普通视觉Transformer(ViT)用于语义分割的能力,并提出了SegViT。以前基于ViT的分割网络通常从ViT的输出中学习像素级表示。不同的是,本文利用基本的组件注意力机制生成语义分割的Mask。
具体来说,作者提出了Attention-to-Mask(ATM)模块,其中一组可学习 class tokens和空间特征映射之间的相似性映射被转移到Segmentation masks。
实验表明,本文提出的使用ATM模块的SegViT优于在ADE20K数据集上使用普通ViT主干的同类算法,并在COCO-Stuff-10K和PASCAL上下文数据集上实现了最新的性能。
此外,为了降低ViT主干的计算成本,提出了基于查询的下采样(QD)和基于查询的上采样(QU)来构建收缩结构。使用建议的收缩结构,该模型可以节省多达40%的计算,同时保持竞争力。
1、简介
语义分割是计算机视觉中的一项密集预测任务,需要对输入图像进行像素级分类。全卷积网络(FCN)在最近最先进的方法中得到了广泛的应用。这种模式包括作为编码器/主干的深度卷积神经网络和提供密集预测的面向分段的解码器。通常将1×1卷积层应用于代表性特征图以获得像素级预测。为了获得更高的性能,以前的工作侧重于丰富上下文信息或融合多尺度信息。然而,由于感受野有限,在FCN中很难明确建模空间位置之间的相关性。
最近,利用空间注意力机制的视觉Transformer(ViT)被引入计算机视觉领域。与典型的基于卷积的主干不同,ViT具有一个简单的非层次结构,可以始终保持特征图的分辨率。缺少下采样过程(不包括图像token化)给使用ViT主干进行语义分割任务的体系结构带来了差异。基于ViT主干的各种语义分割方法由于从预训练的主干中学习到的强大表示,已经取得了良好的性能。然而,注意力机制的潜力尚未得到充分发掘。

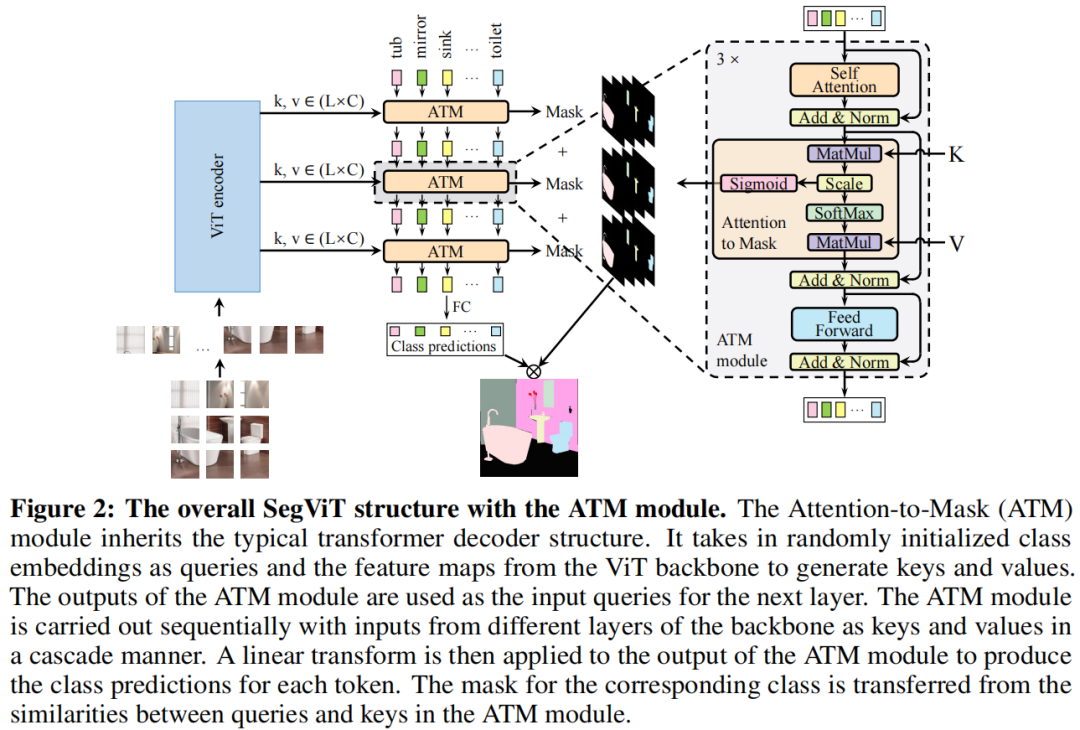
与以前的逐像素分类范式不同,本文考虑学习一个有意义的 class tokens,然后找到与之相似性较高的局部patch。为了实现这个目标,作者提出了Attention-to-Mask(ATM)模块。更具体地说,使用了一个transformer block,它将可学习 class tokens作为query,并将空间特征映射作为key和value进行传输。点积运算符计算query和key之间的相似性映射。
作者鼓励属于同一类别的区域为相应类别(即特定类别tokens)生成更大的相似性值。图1显示了特征与“Table”和“Chair”标记之间的相似性映射。通过简单地应用Sigmoid操作,可以将相似性映射转移到mask。同时,在设计了一个典型的transformer block后,还将Softmax操作应用于相似性图,以获得交叉注意力图。然后,“Table”和“Chair”标记像在任何常规transformer 解码器中一样,通过以交叉注意力图作为权重的值的加权和进行更新。由于Mask是定期仔细计算的副产品,因此在操作过程中涉及的计算可以忽略不计。
在这个高效的ATM模块的基础上,提出了一种新的具有普通ViT结构的语义分割范式,称为SegViT。在该范式中,在不同的层上使用多个ATM模块,通过将不同层的输出相加得到最终的Segmentation masks。SegViT的性能优于基于ViT的同类算法,计算成本更低。然而,与以前使用分层网络作为编码器的编码器-解码器结构相比,作为编码器的ViT主干通常更重。为了进一步降低计算成本,采用了一种收缩结构,由基于查询的下采样(QD)和基于查询的上采样(QU)组成。QD可插入ViT主干以将分辨率降低一半,QU与主干平行以恢复分辨率。收缩结构与作为解码器的ATM模块一起可以减少多达40%的计算量,同时保持具有竞争力的性能。
主要贡献总结如下:
提出了一个注意力掩码(ATM)解码器模块,该模块对于语义分割有效且高效。首次利用注意力图中的空间信息为每个类别生成Mask预测,这可以作为语义分割的一种新范式。
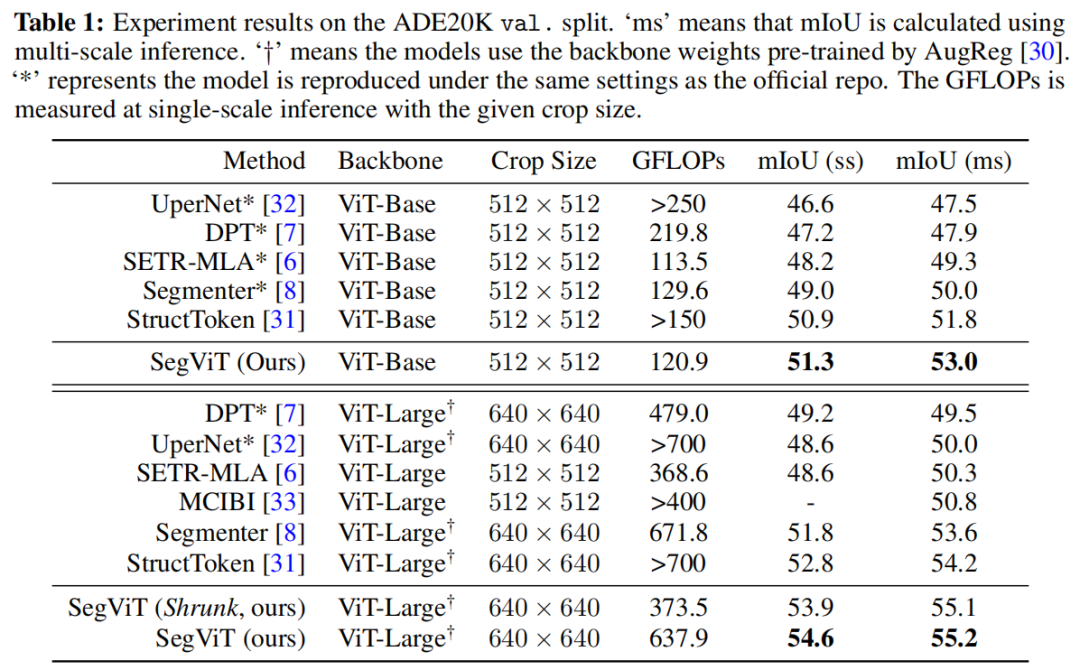
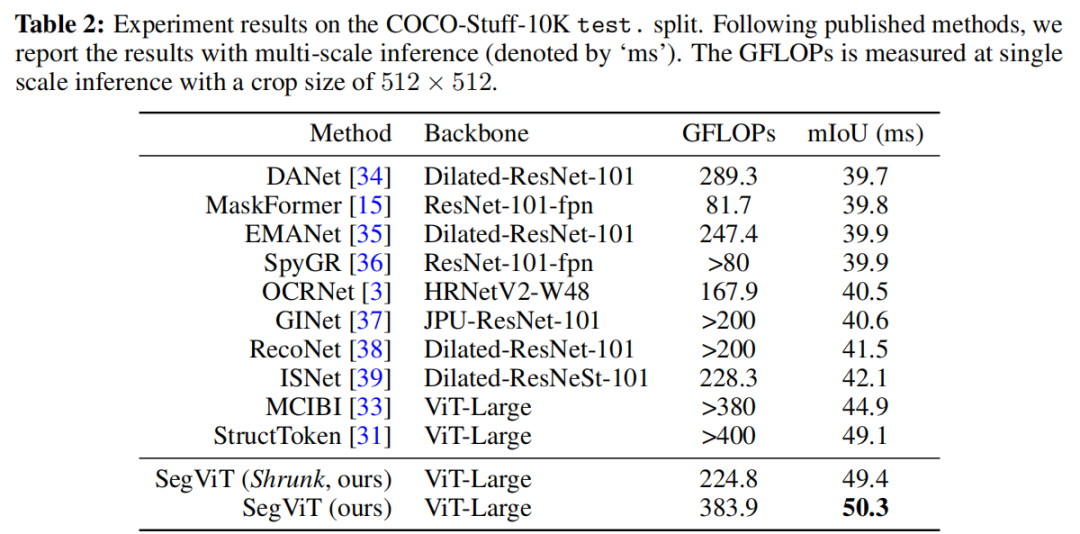
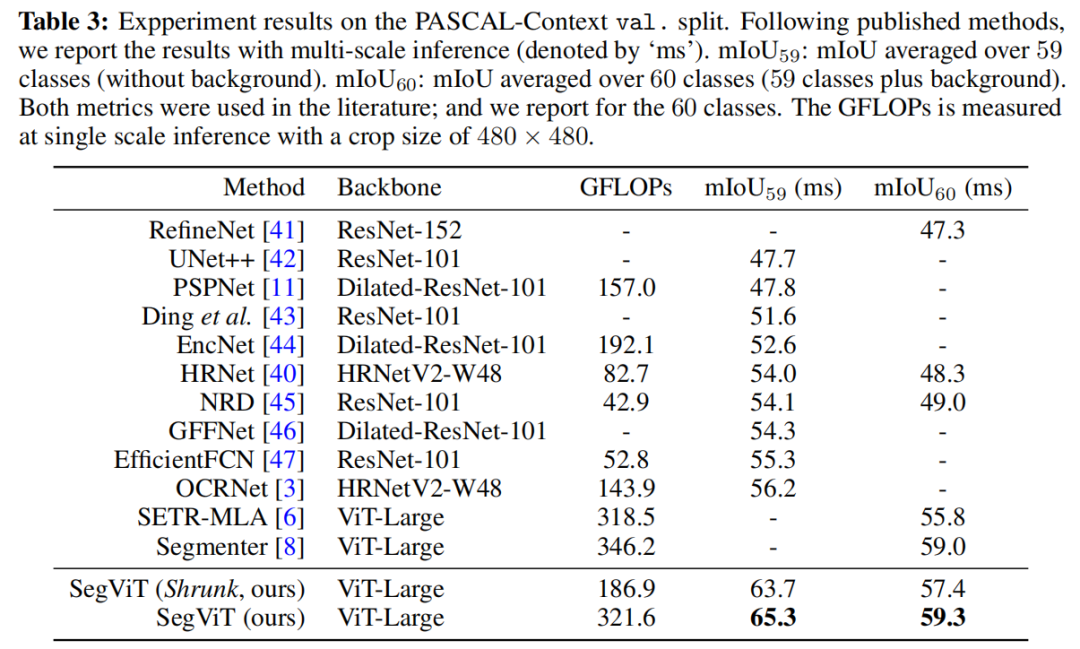
设法以级联方式将ATM解码器模块应用于普通、非分层的ViT主干,并设计了一种结构,即SegViT,它在竞争对手ADE20K数据集上实现了55.2%的mIoU,这是使用ViT主干的方法中最好、最轻的。作者还在PASCAL Context数据集(65.3%mIoU)和COCO-Stuff-10K数据集(50.3%mIoO)上对本文的方法进行了基准测试,并实现了新的SOTA。
进一步探索了ViT主干的架构,并制定了适用于主干的收缩结构,以降低总体计算成本,同时仍保持竞争力。这减轻了ViT主干的缺点,与层次结构的对等物相比,这些主干通常计算量更大。在ADE20K数据集上的收缩版SegViT达到了mIoU 55.1%,计算成本为373.5 GFLOP,与原始SegViT(637.9 GFLOP)相比降低了约40%。
2、本文方法
2.1、编码器
给定输入图像,一个普通视觉Transformer主干将其reshape为一系列tokens ,其中,P是patch size,C是通道数。添加与大小相同的可学习位置嵌入以获取位置信息。然后,将 token sequence 应用于m个transformer layers以获得输出。将每个层的输出token 定义为。通常,一个transformer layer由一个multi-head self-attention block和一个point-wise multilayer perceptron block组成,layer norm介于其间,然后再添加一个residual connection。transformer layers重复堆叠若干次。对于像ViT这样的普通视觉transformer ,没有涉及其他模块,并且对于每个层,token 的数量不会改变。
2.2、解码器
(1)Mask-to-Attention (ATM)
Cross Attention可以描述为两个 token sequence之间的映射。将2个 token sequence定义为,长度N等于类别数和。首先,对它们中的每一个应用线性变换以形成query(Q)、key(K)和value(V),如等式(1)所示。
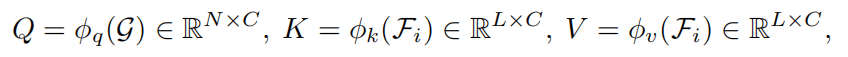
在query和key之间计算相似度图。根据scaled dot-product attention机制,相似度图和注意力图通过以下公式计算:
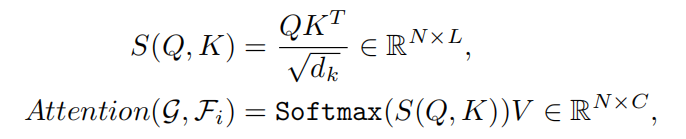
其中是缩放因子,等于key的尺寸。相似度图S(Q,K)的形状由两个token sequence N和L的长度确定。然后,注意力机制通过加权和V更新G,其中分配给总和的权重是沿维度L应用Softmax的相似度图。
Dot-product attention使用Softmax函数专门将注意力集中在最相似的token 上。然而,作者认为,除了产生最大相似性的token 之外,其他token 也有意义。基于这种直觉,作者设计了一个轻量级模块,可以更直接地生成语义预测。更具体地说,将G指定为 segmentation 任务的class embeddings,将指定为ViT主干的第层的输出。将semantic mask与G中的每个token 配对,以表示每个类的语义预测。Mask的计算为:

Mask的形状为N×L,可进一步reshape为N×H/P×W/P。ATM机制的结构如图2右侧所示。Mask是Cross Attention的中间输出。ATM模块的最终输出token 用于分类。对输出类token 应用线性变换,然后进行Softmax激活,以获得类概率预测。
请注意这里添加了一个“无对象”类别,以防图像不包含某些类。在推理过程中,输出由类概率和Mask组之间的点积产生。
像ViT这样的普通骨干没有具有不同规模特征的多个阶段。因此,用于合并具有多个比例的特征的结构(如FPN)不适用。然而,除最后一层之外的特征包含丰富的底层语义信息,并有利于性能。
作者设计了一种结构,它可以利用来自ViT不同层的特征映射,与ATM解码器SegViT进行压缩。在这项研究中,还找到了一种在不牺牲性能的情况下压缩ViT主干网计算成本的方法。这个建议的Shrunk版本的SegViT使用基于查询的下采样(QD)模块和基于查询的上采样(QU)模块来压缩ViT主干,并整体降低计算成本。
(2)The SegViT structure
如图2所示,ATM解码器将N个token作为类嵌入,并将另一个token序列作为基础来计算key和value,以便ATM模块生成mask。ATM的输出是N个更新token和对应于每个类token的N个mask。首先使用随机初始化的可学习token作为类嵌入,并将ViT主干最后一层的输出作为基础。为了利用多层信息,第一个ATM解码器的输出被用作下一个ATM解码的类嵌入,ViT主干网的另一层的输出作为基础。这个过程再重复一次,这样可以得到3组token和mask。每层的损失函数形式上可以表示为,
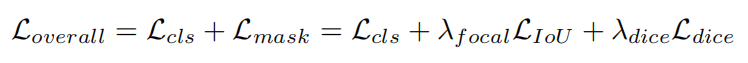
在每组中,输出令牌由上述分类损失(Lcls)监督,mask按顺序求和,并由mask损失()监督,该mask损失是focal loss和 dice loss的线性组合,分别乘以超参数和,如DETR中所示。然后将所有三组的损失加在一起。还有进一步的实验表明,这种设计是有益和有效的。
(3)The Shrunk structure
众所周知,像ViT这样的普通transformer主干比具有类似性能的同类transformer具有更大的计算成本。本文作者提出了一种使用基于查询的下采样(QD)和上采样(QU)的收缩结构。由于注意力模块输出的形状由query的形状决定,可以在query转换之前应用下采样来实现QD,或者在交叉注意力期间插入新的query tokens来实现QU,提供更大的灵活性来保存(恢复)重要区域。
更具体地说,在QD层中,使用最近的采样来减少query tokens的数量,同时保持key和value token的大小。当通过transformer层时,这些值通过query tokens和key tokens之间的注意力度映射进行加权和求和。这是非线性下采样,将更加关注重要区域。在QU层中,使用了一个transformer decoder结构,并根据期望的输出分辨率将新的可学习token初始化为query。
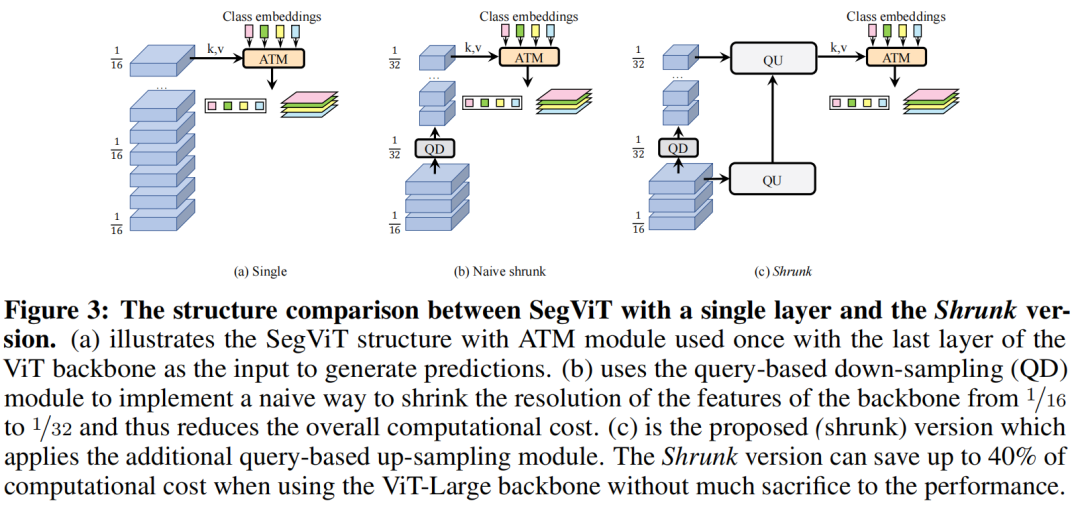
如图3所示,设计了一个单层作为基线的SegViT结构(a)。首先尝试一种简单的方法(b),即在主干的1/3深度(例如,具有24层的主干的第8层)应用一次QD,以将层输出的分辨率从1/16降到1/32,从而降低总体计算成本。由于QD过程涉及信息丢失,性能如预期般下降。
为了补偿原始“收缩”版本中的信息损失,进一步应用两个与主干并行的QU层。这是建议的Shrunk版本(c)。第一个QU层从主干的低层接收1/16分辨率的特征。然后将其输出用作query ,以与主干最后一层分辨率为1/32的下采样特征进行交叉注意力。该QU结构的输出形状为1/16分辨率。
直接减少query tokens的数量必然会损害最终性能。然而,使用设计的QU层和ATM模块,Shrunk结构能够减少40%的总计算成本,同时在性能上仍然具有竞争力。
3、实验
3.1、消融实验
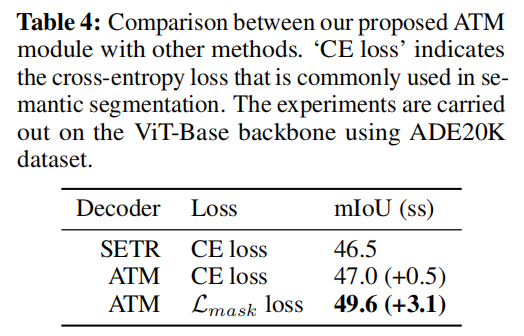
(1)ATM module的影响
(2)使用不同的层作为SegViT的输入

(3)ATM Decoder
(4)SegViT on hierarchical backbones

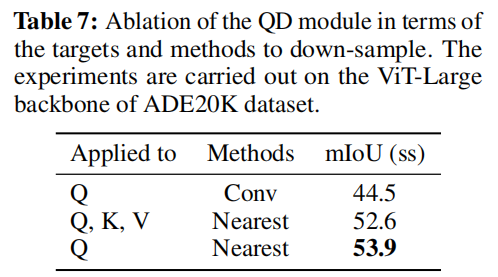
(5)QD module
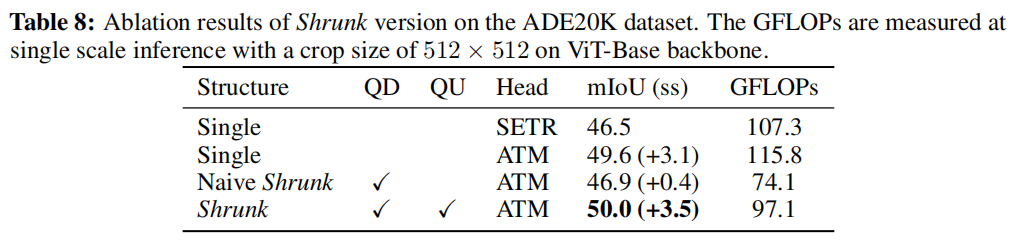
(6)Ablation of the components in Shrunk structure
3.2、SOTA对比
(1)ADE20K
(2)COCO-Stuff-10K
(3)PASCAL-Context
-
计算机视觉
+关注
关注
9文章
1716浏览量
47756 -
数据集
+关注
关注
4文章
1242浏览量
26291 -
Transformer
+关注
关注
0文章
156浏览量
6973
原文标题:全新语义分割方法SegViT | 沈春华老师团队提出全新语义分割方法
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
聚焦语义分割任务,如何用卷积神经网络处理语义图像分割?
语义分割算法系统介绍
视觉新范式Transformer之ViT的成功
基于深度神经网络的图像语义分割方法

关于Next-ViT 的建模能力
深度模型Adan优化器如何完成ViT的训练
语义分割数据集:从理论到实践
语义分割标注:从认知到实践
PyTorch教程-14.9. 语义分割和数据集


基于 Transformer 的分割与检测方法

使用 Vision Transformer 和 NVIDIA TAO,提高视觉 AI 应用的准确性和鲁棒性



评论