 如何为ClickHouse增强高可用能力
如何为ClickHouse增强高可用能力
相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻。但在字节大量生产使用中,发现了ClickHouse依然存在了一定的限制。例如:
缺少完整的upsert和delete操作
多表关联查询能力弱
集群规模较大时可用性下降(对字节尤其如此)
没有资源隔离能力
因此,我们决定将ClickHouse能力进行全方位加强,打造一款更强大的数据分析平台。后面我们将从五个方面来和大家分享,本篇将详细介绍我们是如何为ClickHouse增强高可用能力的。
字节遇到的ClickHouse可用性问题
随着字节业务的快速发展,产品快速扩张,承载业务的ClickHouse集群节点数也快速增加。另一方面,按照天进行的数据分区也快速增加,一个集群管理的库表特别多,开始出现元数据不一致的情况。两方面结合,导致集群的可用性极速下降,以至于到了业务难以接受的程度。直观的问题有三类:
1、故障变多
典型的例子如硬件故障,几乎每天都会出现。另外,当集群达到一定的规模,Zookeeper会成为瓶颈,增加故障发生频率。
2、故障恢复时间长
因为数据分区变多,导致一旦发生故障,恢复时间经常会需要1个小时以上,这是业务方完全不能接受的。
3、运维复杂度提升
以往只需要一个人负责运维的集群,由于节点增加和分区变多,运维复杂度和难度成倍的增加,目前运维人数增加了几人也依然拙荆见肘,依然难保证集群的稳定运行。
可用性问题已经成为制约业务发展的重要问题,因此我们决定将影响高可用的问题一一拆解,并逐个解决。
提升高可用能力的方案
一、降低Zookeeper压力
问题所在:
原生ClickHouse 使用 ReplicatedMergeTree 引擎来实现数据同步。原理上,ReplicatedMergeTree 基于 ZooKeeper 完成多副本的选主、数据同步、故障恢复等功能。由于 ReplicatedMergeTree 对 ZooKeeper 的使用比较重,除了每组副本一些表级别的元信息,还存储了逻辑日志、part 信息等潜在数量级较大的信息。Zookeeper并不是一个能做到良好线性扩展的系统,当ZooKeeper 在相对较高的负载情况下运行时,往往性能表现并不佳,甚至会出现副本无法写入,数据也无法同步的情况。在字节内部实际使用和运维 ClickHouse 的过程中,ZooKeeper 也是非常容易成为一个瓶颈的组件。
改造思路:
ReplicatedMergeTree 支持 insert_quorum,insert_quorum 是指如果副本数为3,insert_quorum=2,要成功写入至少两个副本才会返回写入成功。
新分区在副本之间复制的流程如下:
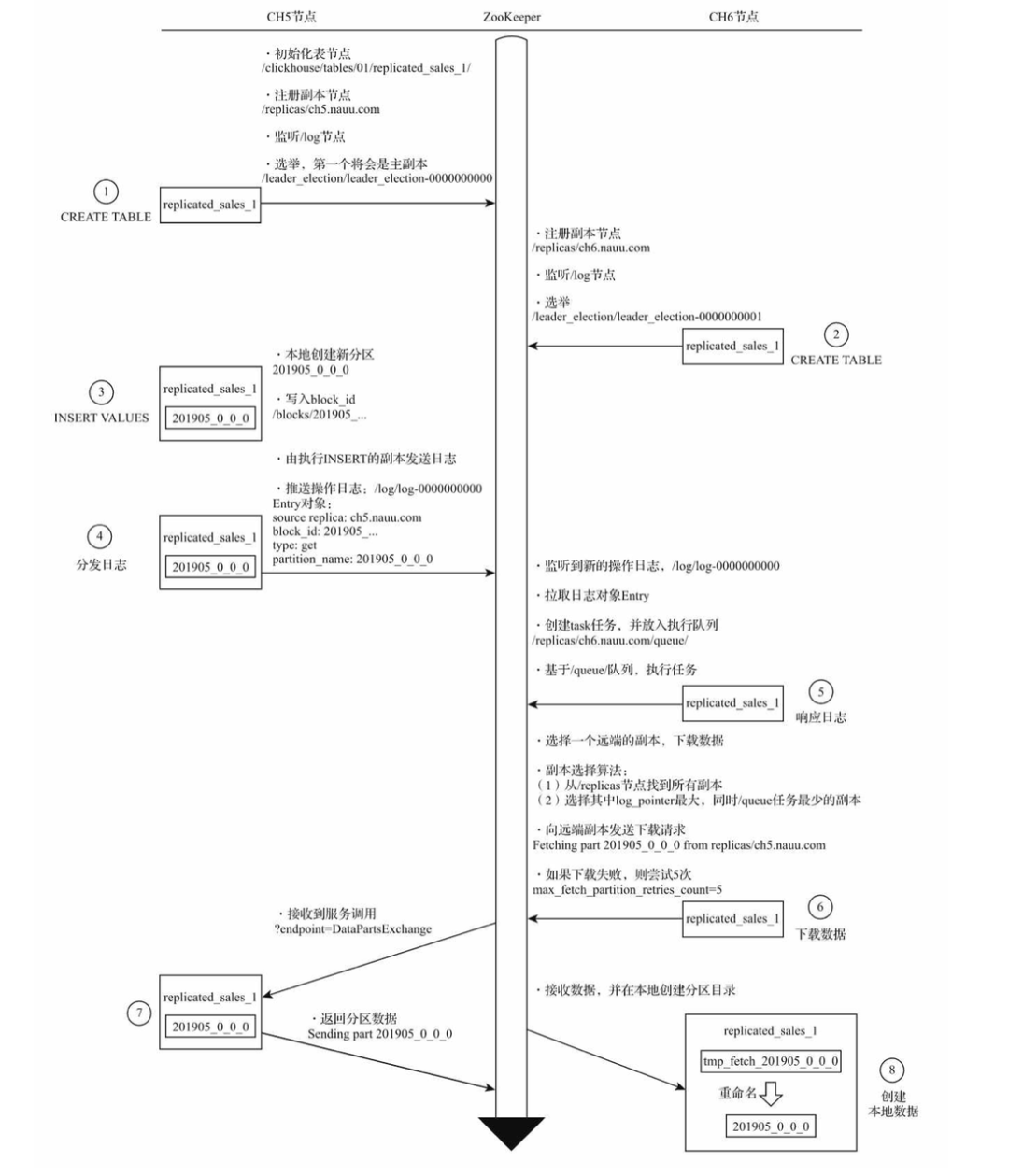
可以看到,反复在 zookeeper 中进行分发日志、数据交换等步骤,这正是引起瓶颈的原因之一。
为了降低对 ZooKeeper 的负载,在ByteHouse中重新实现了一套 HaMergeTree 引擎。通过HaMergeTree降低对 ZooKeeper 的请求次数,减少在 ZooKeeper 上存储的数据量,新的 HaMergeTree 同步引擎:
1)保留ZooKeeper上表级别的元信息;
2)简化逻辑日志的分配;
3)将 part 信息从 ZooKeeper 日志移除。
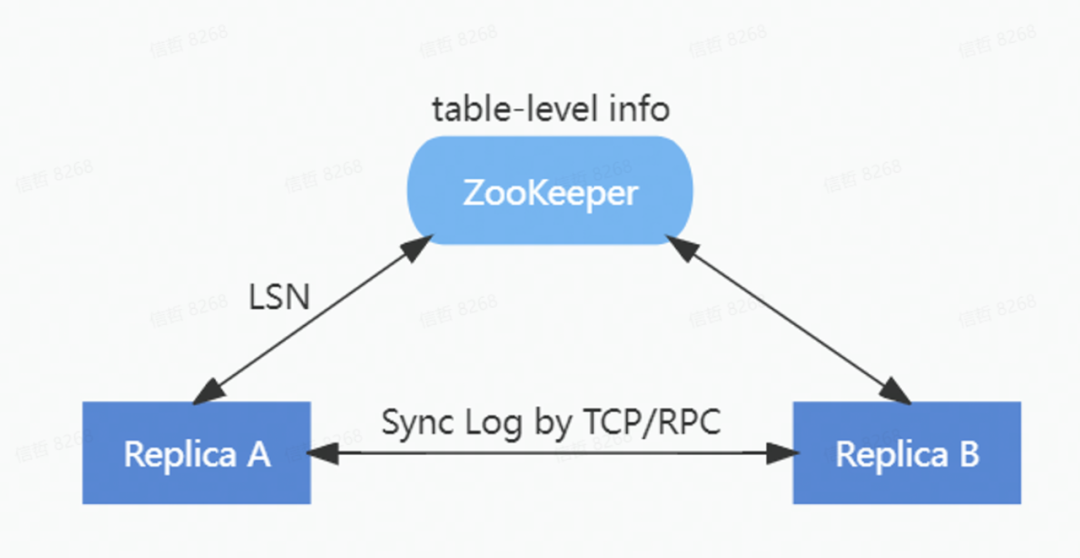
HaMergeTree 减少了操作日志等信息在zookeeper里面的存放,来减少zookeeper的负载,zookeeper里面只是存放log LSN, 具体日志在副本之间通过gossip协议同步回放。
在保持和ReplicatedMergeTree完全兼容的前提下,新的 HaMergeTree 极大减轻了对 ZooKeeper 的负载,实现了 ZooKeeper 集群的压力与数据量不相关。上线后,因Zookeeper导致的异常大量减少。无论是单集群几百甚至上千节点,还是单节点上万张表,都能保障良好的稳定性。
二、提升故障恢复能力
问题所在:
虽然所有数据从业者都在做各种努力,想要保证线上生产环境不出故障,但是现实中还是难以避免会遇到各式各样的问题。主要是由下面这几种因素引起的:
软件缺陷:软件设计本身的Bug引起的系统非正常终止,或依赖的组件兼容引发的问题。
硬件故障:常见的有磁盘损坏、内容故障、CPU故障等,当集群规模扩大后发生的频率也线性增加。
内存溢出导致进程被停止:在OLAP数据库中经常发生。
意外因素:如断电、误操作等引发的问题。
由于原生ClickHouse希望达到极致性能的初衷,所以在ClickHouse系统中元数据常驻于内存中,这导致了ClickHouse server重启时间非常长。因而当故障发生后,恢复的时间也很长,动辄一到两个小时,相当于业务也要中断一到两个小时。当故障频繁出现,造成的业务损失是无法估量的。
改造思路:
为了解决上述问题,在ByteHouse中采用了元数据持久化的方案,将元数据持久化到RocksDB, Server启动时直接从RocksDB加载元数据,内存中也仅仅存放必要的Part信息。因此可以减少元数据对内存的占用,以及加速集群的启动以及故障恢复时间。
如下图所示,元数据持久化整体上采用了RocksDB+Meta in Memory的方式,每个Table都会对应一个RocksDB数据库存放该表所有Part的元信息。Table首次启动时,从文件系统中加载的Part元数据将被持久化到RocksDB中;之后重启时就可以直接从RocksDB中加载Part。每个表从RocksDB或者文件系统加载的Part将只在内存中存放必要的Part信息。在实际使用Part时,将通过内存中存放的Part元信息去RocksDB中读取并加载对应Part。
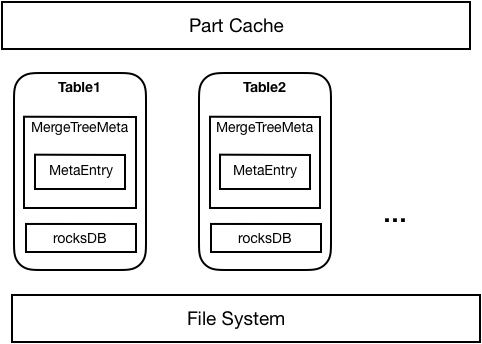
完成元数据持久化后,在性能基本无损失的情况下,单机支持的part不再受内存容量的限制,可以达到100万以上。最重要的是,故障恢复的时间显著缩短,只需要此前的几十分之一的时间就可以完成。例如在原生ClickHouse中需要一到两个小时的恢复时间,在ByteHouse中只需要3分钟,大大提高的系统的高可用能力,为业务提供了坚实保障。
三、其他方面
除了以上两点,在ByteHouse中在其他很多方面都为高可用能力做了增强,如通过HaKafka引擎提升了数据写入的高可用性,提升实时数据写入的容错率,可自动切换主备写入;增加了监控运维平台,实现对关键指标的监控、告警;增加多种问题诊断工具,能实现故障的快速定位。
对于数据分析平台来说,稳定性是重中之重。我们对ByteHouse的高可用能力的提升是不会停止的,在极致性能的背后,力图为用户提供最强有力的稳定性保障。
-
cpu
+关注
关注
68文章
10944浏览量
213822 -
存储
+关注
关注
13文章
4404浏览量
86416 -
数据分析
+关注
关注
2文章
1463浏览量
34328
原文标题:ByteHouse实践与思考:如何补全ClickHouse高可用短板?
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Centos7下如何搭建ClickHouse列式存储数据库
PB级分析型数据库ClickHouse的应用场景和特性等分享


ClickHouse和Elasticsearch压测对比
火山引擎:ClickHouse增强计划之“Upsert”
替代ELK:ClickHouse+Kafka+FlieBeat才是最绝的
火山引擎:ClickHouse增强计划之“多表关联查询”
ClickHouse增强计划之“资源隔离”
如何增强MOS管的带载能力呢?
供应链场景使用ClickHouse最佳实践





 工商网监
工商网监
评论