 基于Transformer与覆盖注意力机制建模的手写数学公式识别
基于Transformer与覆盖注意力机制建模的手写数学公式识别
一、研究背景
手写数学公式识别是将包含数学表达式的图像转换为结构表达式,例如LaTeX数学表达式或符号布局树的过程。手写数学表达式的识别已经带来了许多下游应用,如在线教育、自动评分和公式图像搜索。在在线教育场景下,手写数学表达式的识别率对提高学习效率和教学质量至关重要。 对比于传统的文本符号识别(Optical Character Recognition, OCR),公式识别具有更大的挑战性。公式识别不仅需要从图像中识别不同书写风格的符号,还需要建模符号和上下文之间的关系。例如,在LaTeX中,模型需要生成“^”、“_”、“{”和“}”来描述二维图像中符号之间的位置和层次关系。编码器-解码器架构由于可以编码器部分进行特征提取,在解码器部分进行语言建模,而在手写数学公式识别任务(Handwritten Mathematical Expression Recognition, HMER)中被广泛使用。 虽然Transformer在自然语言处理领域已经成为了基础模型,但其在HMER任务上的性能相较于循环神经网络(Recurrent Neural Network, RNN)还不能令人满意。作者观察到现有的Transformer与RNN一样会受到缺少覆盖注意力机制的影响,即“过解析”——图像的某些部分被不必要地多次解析,以及“欠解析”——有些区域未被解析。RNN解码器使用覆盖注意机制来缓解这一问题。然而,Transformer解码器所采用的点积注意力没有这样的覆盖机制,作者认为这是限制其性能的关键因素。 不同于RNN,Transformer中每一步的计算是相互独立的。虽然这种特性提高了Transformer中的并行性,但也使得在Transformer解码器中直接使用以前工作中的覆盖机制变得困难。为了解决上述问题,作者提出了一种利用Transformer解码器中覆盖信息的新模型,称为CoMER。受RNN中覆盖机制的启发,作者希望Transformer将更多的注意力分配到尚未解析的区域。具体地说,作者提出了一种新颖的注意精炼模块(Attention Refinement Module, ARM),它可以在不影响并行性的前提下,根据过去的对齐信息对注意权重进行精炼。同时为了充分利用来自不同层的过去对齐信息,作者提出了自覆盖和交叉覆盖,分别利用来自当前层和前一层的过去对齐信息。作者进一步证明,在HMER任务中,CoMER的性能优于标准Transformer解码器和RNN解码器。
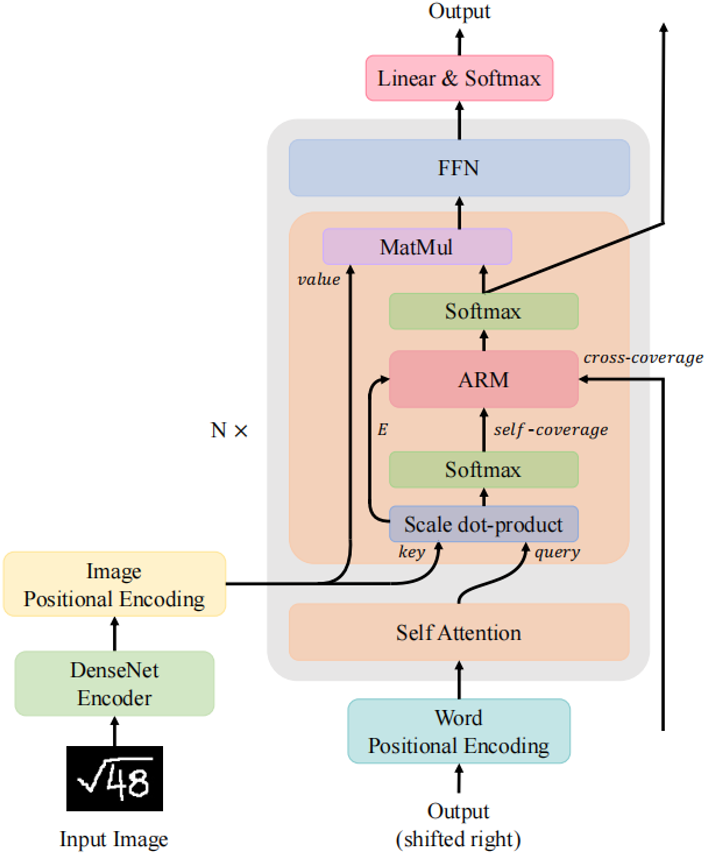
图1 本文提出的具有注意力精炼模块的Transformer模型
二、方法原理简述
CNN编码器在编码器部分,本文使用DenseNet作为编码器。相较于ResNet,DenseNet在不同尺度特征图上的密集连接能够更好地反映出不同大小字符的尺度特征,有利于后续解码不同位置大小字符的含义。为了使DenseNet输出特征与解码器模型尺寸对齐,作者在编码器的末端增加了1 × 1的卷积层,得到输出图像特征
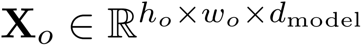 。
。
位置编码与RNN解码器不同,由于Transformer解码器的Token之间不具有空间位置关系,额外的位置信息是必要的。在论文中,作者与BTTR[1]一致,同时使用图像位置编码和字符位置编码。 对于字符位置编码,作者使用Transformer[2]中引入的1D位置编码。给定编码维数d,位置p,特征维索引i,则字符位置编码向量
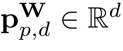
可表示为:
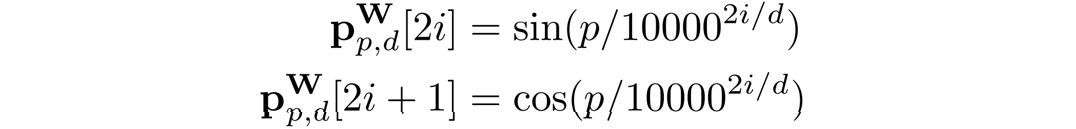
图像位置编码采用与[1,3]相同的二维归一化位置编码。由于模型需要关注的是相对位置,所以首先要将位置坐标归一化。给定二维坐标元组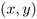 ,编码维数为d,通过一维位置的拼接计算二维图像位置编码
,编码维数为d,通过一维位置的拼接计算二维图像位置编码
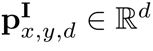 。
。
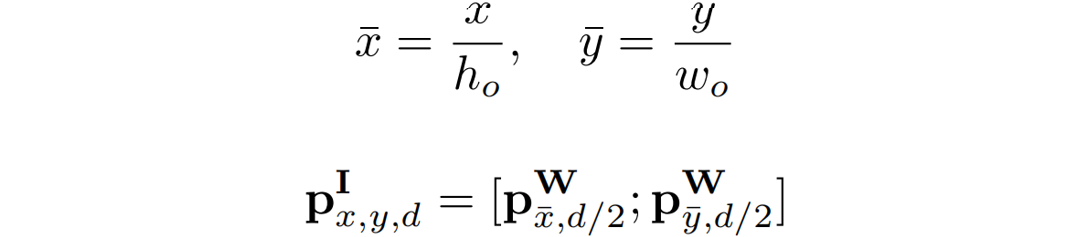
其中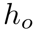 和
和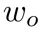 代表了输入图像特征的尺寸。注意力精炼模块(ARM)如果在Transformer中直接采用RNN式的覆盖注意力机制。那么将会产生一个具有
代表了输入图像特征的尺寸。注意力精炼模块(ARM)如果在Transformer中直接采用RNN式的覆盖注意力机制。那么将会产生一个具有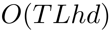 空间复杂度的覆盖矩阵
空间复杂度的覆盖矩阵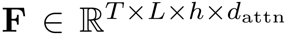 ,这样的大小是难以接受的。问题的瓶颈在于覆盖矩阵需要先与其他特征向量相加,再乘以向量
,这样的大小是难以接受的。问题的瓶颈在于覆盖矩阵需要先与其他特征向量相加,再乘以向量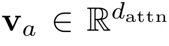 。如果我们可以先将覆盖矩阵与
。如果我们可以先将覆盖矩阵与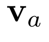 相乘,再加上LuongAttention[4]的结果,空间复杂度将大大降低到。因此作者将注意力机制修改为:
相乘,再加上LuongAttention[4]的结果,空间复杂度将大大降低到。因此作者将注意力机制修改为:
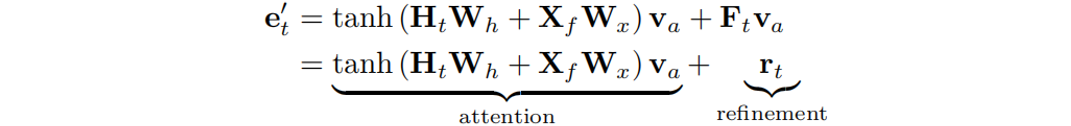
其中相似向量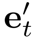 可分为注意项和精炼项
可分为注意项和精炼项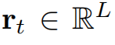 。需要注意的是,精炼项可以通过覆盖函数直接由累积
。需要注意的是,精炼项可以通过覆盖函数直接由累积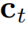 向量生成,从而避免了具有为维数为
向量生成,从而避免了具有为维数为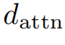 的中间项。作者将上式命名为注意力精炼框架。
的中间项。作者将上式命名为注意力精炼框架。
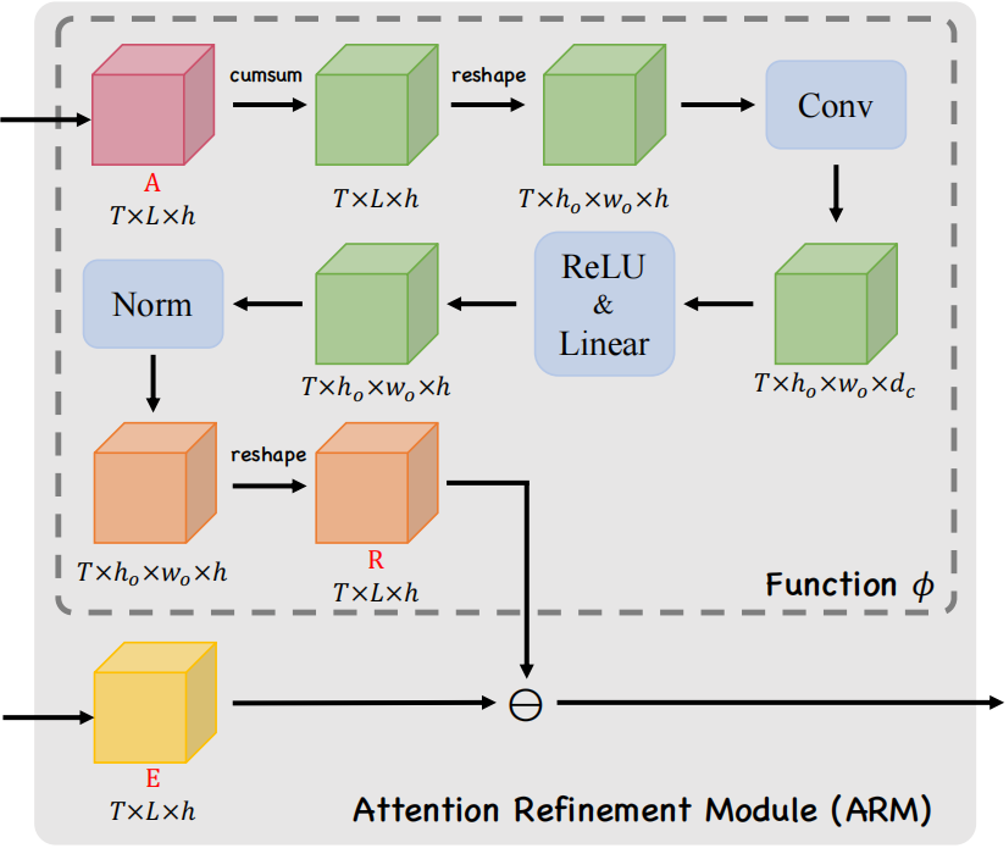
图2 注意精炼模块(ARM)的整体结构 为了在Transformer中使用这一框架,作者提出了如图2所示的注意精炼模块(ARM)。可以将Transformer中的点积矩阵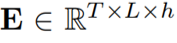 作为注意项,精炼项矩阵R需要从经过Softmax后的注意权值A中计算出来。作者使用了注意权值A来提供历史对齐信息,具体的选择会在下一小节介绍。 作者定义了一个将注意力权重
作为注意项,精炼项矩阵R需要从经过Softmax后的注意权值A中计算出来。作者使用了注意权值A来提供历史对齐信息,具体的选择会在下一小节介绍。 作者定义了一个将注意力权重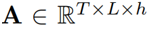 作为输入,输出为精炼矩阵
作为输入,输出为精炼矩阵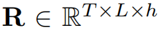 的函数
的函数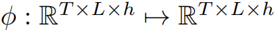 :
:
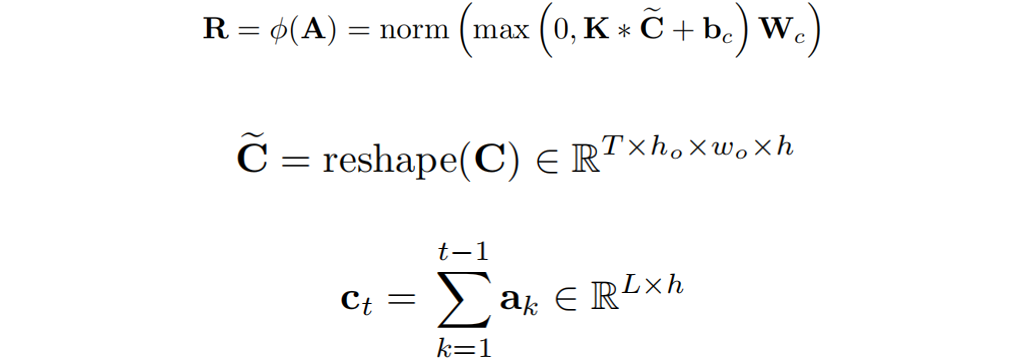
其中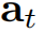 是在时间步
是在时间步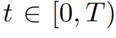 时的注意力权重。
时的注意力权重。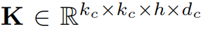 代表一个卷积核,*代表卷积操作。
代表一个卷积核,*代表卷积操作。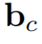 是一个偏置项,
是一个偏置项,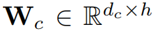 是一个线性投影矩阵。 作者认为函数
是一个线性投影矩阵。 作者认为函数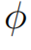 可以提取局部覆盖特征来检测已解析区域的边缘,并识别传入的未解析区域。最终,作者通过减去精炼项R来达到精炼注意力项E的目的。覆盖注意力本节将介绍注意权重A的具体选择。作者提出了自覆盖、交叉覆盖以及融合覆盖三种模式,以利用不同阶段的对齐信息。自覆盖: 自覆盖是指使用当前层生成的对齐信息作为注意精炼模块的输入。对于当前层j,首先计算注意权重
可以提取局部覆盖特征来检测已解析区域的边缘,并识别传入的未解析区域。最终,作者通过减去精炼项R来达到精炼注意力项E的目的。覆盖注意力本节将介绍注意权重A的具体选择。作者提出了自覆盖、交叉覆盖以及融合覆盖三种模式,以利用不同阶段的对齐信息。自覆盖: 自覆盖是指使用当前层生成的对齐信息作为注意精炼模块的输入。对于当前层j,首先计算注意权重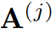 ,并对其进行精炼。
,并对其进行精炼。
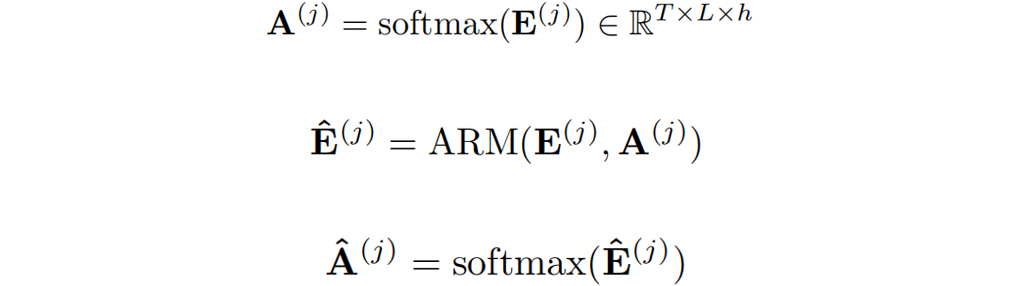
其中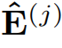 代表了精炼后的点积结果。
代表了精炼后的点积结果。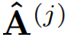 代表在j层精炼后的注意力权重。交叉覆盖:作者利用Transformer中解码层相互堆叠的特性,提出了一种新的交叉覆盖方法。交叉覆盖使用前一层的对齐信息作为当前层ARM的输入。j为当前层,我们使用精炼后的注意力权重
代表在j层精炼后的注意力权重。交叉覆盖:作者利用Transformer中解码层相互堆叠的特性,提出了一种新的交叉覆盖方法。交叉覆盖使用前一层的对齐信息作为当前层ARM的输入。j为当前层,我们使用精炼后的注意力权重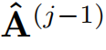 之前
之前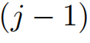 层来精炼当前层的注意力项。
层来精炼当前层的注意力项。
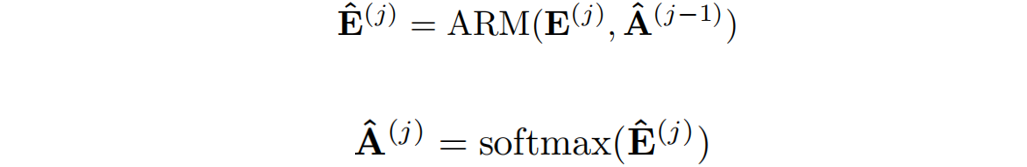
融合覆盖:将自覆盖和交叉覆盖相结合,作者提出了一种新的融合覆盖方法,充分利用从不同层生成的过去对齐信息。
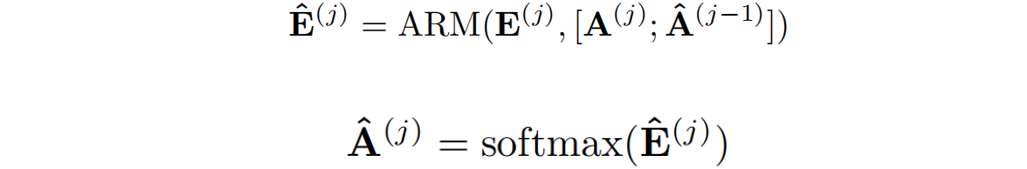
其中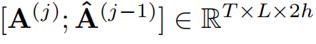 表示来自当前层的注意权重与来自前一层的精炼注意权重进行拼接。
表示来自当前层的注意权重与来自前一层的精炼注意权重进行拼接。
三、主要实验结果及可视化结果
表1 与先前工作在CROHME数据集上的效果的比较
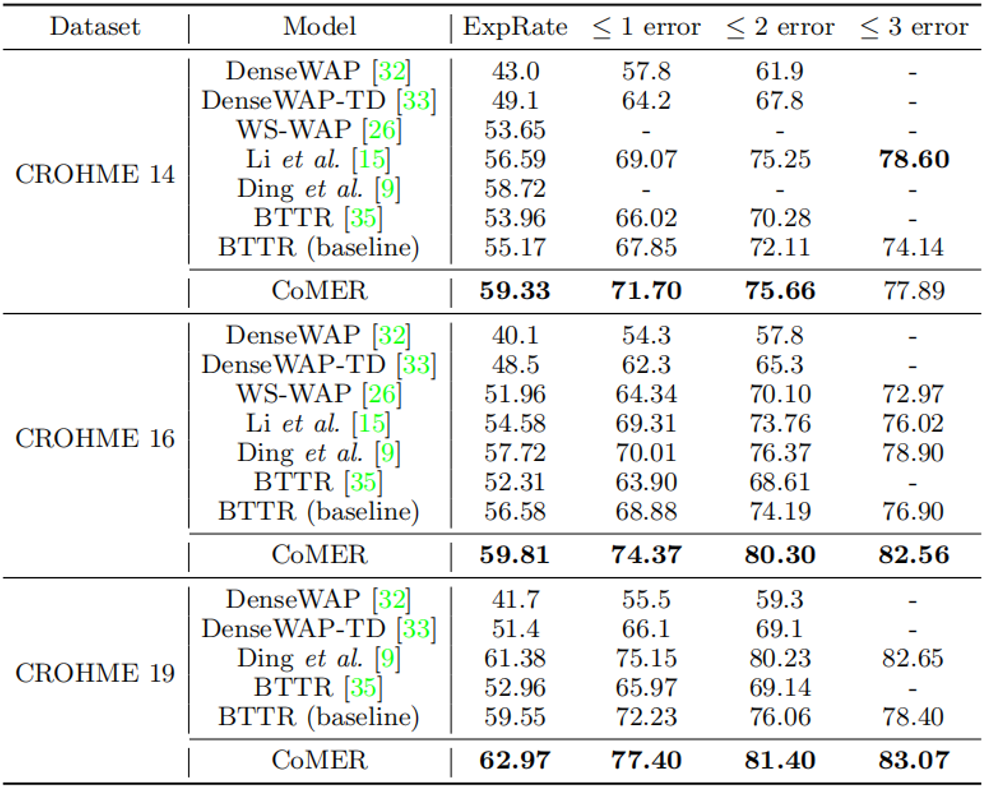
从表1中可以看出,与使用覆盖注意力机制的RNN的模型相比,CoMER在每个CROHME测试集上的性能优于Ding等人[5]提出的先前最先进的模型。在完全正确率ExpRate中,与之前性能最好的基于RNN的模型相比,CoMER平均提高了1.43%。与基于Transformer的模型相比,作者提出的带有ARM和融合覆盖的CoMER显著提高了性能。具体而言,CoMER在所有指标上都优于基准“BTTR”,在ExpRate中平均领先基准“BTTR”3.6%。
表2 各模块消融实验
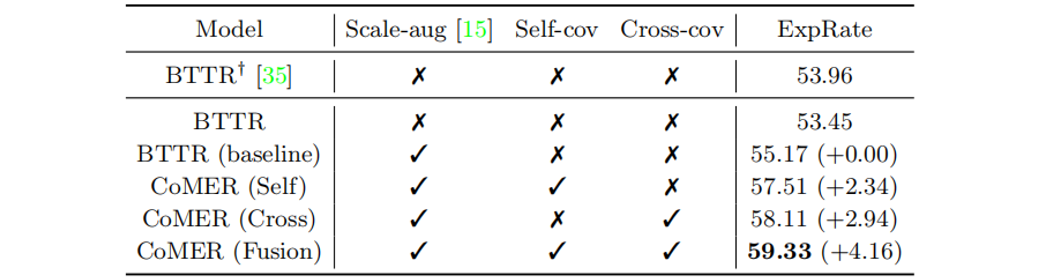
在表2中,“Scale -aug”表示是否采用尺度增广[6]。“Self-cov”和“Cross-cov”分别表示是否使用自覆盖和交叉覆盖。与BTTR相比,采用ARM和覆盖机制的CoMER的性能有了明显的提高。
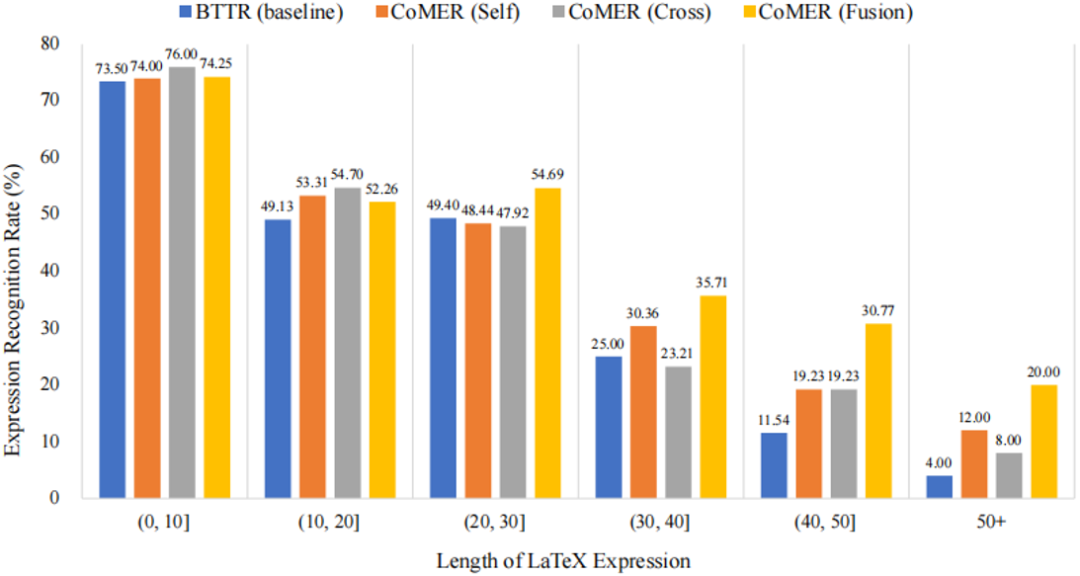
图3 不同算法在CROHME 2014数据集上不同长度正确率的对比 从图3中可以看到,相较于基准方法与本文提出的三种覆盖方法,融合覆盖可以大大增强模型对长公式的识别率。这也验证了覆盖机制能够更好地引导注意力对齐历史信息。
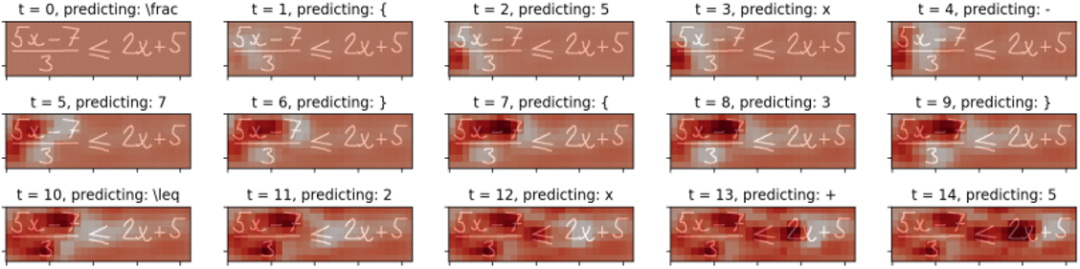
图4 公式图像识别中的精炼项R可视化。
如图4所示,作者将识别过程中的精炼项R可视化。可以看到,经过解析的区域颜色较深,这表明ARM将抑制这些解析区域的注意权重,鼓励模型关注未解析区域。可视化实验表明,作者提出的ARM可以有效地缓解覆盖不足的问题。
四、总结及讨论
作者受RNN中覆盖注意力的启发,提出将覆盖机制引入到Transformer解码器中。提出了一种新的注意精炼模块(ARM),使得在Transformer中进行注意力精炼的同时不损害其并行计算特性成为可能。同时还提出了自覆盖、交叉覆盖和融合覆盖的方法,利用来自当前层和前一层的过去对齐信息来优化注意权重。实验证明了作者提出的CoMER缓解了覆盖不足的问题,显著提高了长表达式的识别精度。作者认为其提出的注意精炼框架不仅适用于手写数学表达式识别。ARM可以帮助精炼注意权重,提高所有需要动态对齐的任务的对齐质量。为此,作者打算将解码器中的ARM扩展为一个通用框架,用于解决未来工作中的各种视觉和语言任务(例如,机器翻译、文本摘要、图像字幕)。
原文作者: Wenqi Zhao, Liangcai Gao
审核编辑:郭婷
-
解码器
+关注
关注
9文章
1143浏览量
40737 -
ARM
+关注
关注
134文章
9091浏览量
367492 -
编码器
+关注
关注
45文章
3641浏览量
134490
发布评论请先 登录
相关推荐
一种基于因果路径的层次图卷积注意力网络

Llama 3 模型与其他AI工具对比
【《大语言模型应用指南》阅读体验】+ 基础知识学习
llm模型有哪些格式
Transformer模型在语音识别和语音生成中的应用优势
神经网络在数学建模中的应用
Transformer 能代替图神经网络吗?

【大规模语言模型:从理论到实践】- 阅读体验
采用单片超构表面与元注意力网络实现快照式近红外光谱成像

视觉Transformer基本原理及目标检测应用
基于Transformer的多模态BEV融合方案
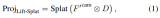
labview公式波形里的公式
语言模型的弱监督视频异常检测方法





 工商网监
工商网监
评论