 RDMA RoCEv2、AWS SRD/EFA和阿里云HPCC
RDMA RoCEv2、AWS SRD/EFA和阿里云HPCC
编者按:
本文是《软硬件融合——超大规模云计算架构创新之路》图书内容的节选。云计算系统持续解构,东西向网络流量激增,服务器堆栈延迟问题凸显。要想提升数据中心网络性能,大体上通过如下措施:
(1)网络容量升级,例如整个网络从25Gbps升级到100Gbps;
(2)轻量协议栈,数据中心网络是局域网络,距离短/延迟敏感,不需要复杂的用于全球互联的TCP/IP协议栈;
(3)网络协议处理硬件加速;
(4)高性能软硬件交互:高效交互协议 + PMD + PF/VF/MQ;
(5)拥塞控制:低延迟、高可靠性(低性能抖动)、高网络利用率。
案例:RDMA RoCEv2、AWS SRD/EFA和阿里云HPCC。
1 高速网络接口RDMA/RoCEv2
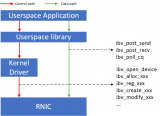
RDMA是一整套高性能网络传输技术的集合,不仅仅是软件和硬件的接口。RDMA的软件和硬件接口,并没有形成如同存储NVMe那样非常严格的标准。本节通过RDMA以及RoCEv2的相关介绍,使大家对高性能网络传输接口以及协议栈有个整体的认识。
1.1 基本概念
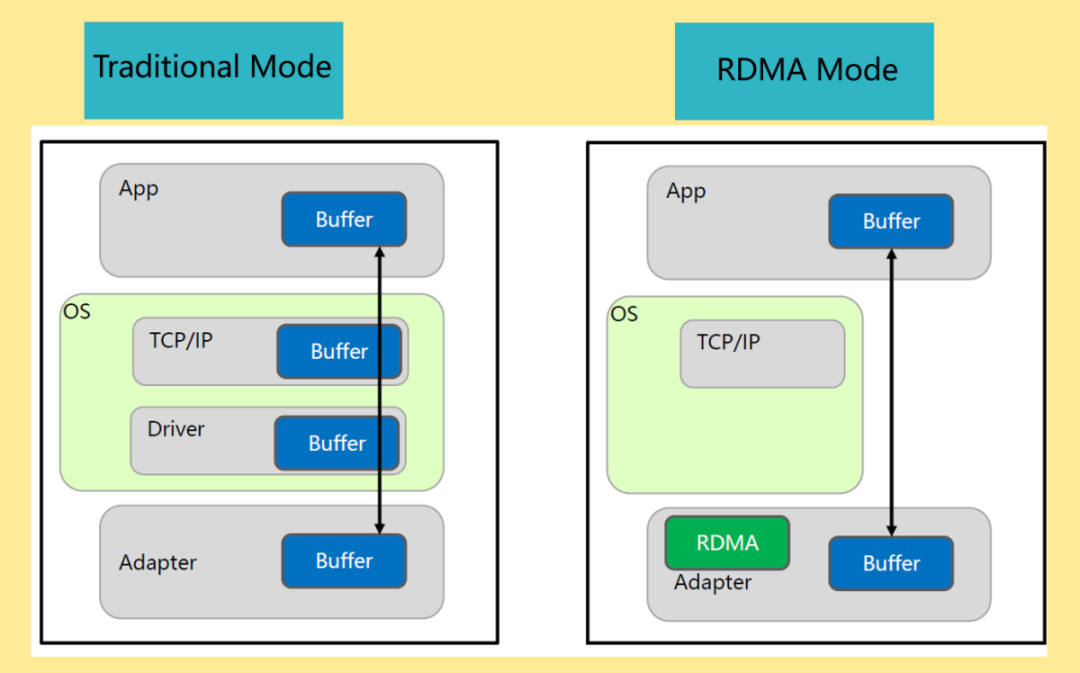
RDMA(Remote Direct Memory Access,远程直接内存访问)是一种高带宽、低延迟、低CPU消耗的网络互联技术,克服了传统TCP/IP网络的许多困难。RDMA技术体现在:
Remote(远程):数据在网络中的两个节点之间传输。
Direct(直接):不需要内核参与,传输的所有处理都卸载到NIC硬件中完成。
Memory(内存):数据直接在两个节点的应用程序的虚拟内存间传输;不需要额外的复制和缓存。
Access(访问):访问操作有send/receive、read/write等。
如图1,RoCE(RDMA over Converaged Ethernet)v1是基于现有Ethernet网络实现RDMA的一项技术。RoCEv1允许在现有以太网基础上实现RDMA技术,实现接近InfiniBand的性能和延迟指标,但不需要将现有网络基础设施升级成昂贵的InfiniBand,节约了大量的支出。RoCEv2基于标准网络的以太网(Ethernet PHY/MAC)、网络层(IP)和传输层(UDP)协议,这可以使得RoCEv2的网络流量可以经过传统的网络路由器路由。
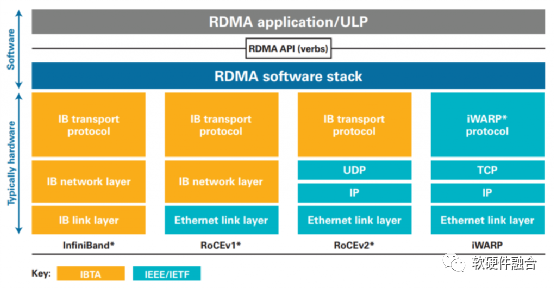
图1 RDMA所使用的InfiniBand、RoCEv1/v2、iWARP技术对比
1.2 RoCE分层
RoCEv2是当前数据中心比较流行的RDMA技术,我们以RoCEv2为例,介绍RoCE的系统分层。
如图2所示,RoCEv2自下而上分为:
以太网层:标准的Ethernet协议,即网络五层协议物理层和数据链路层。
网络层(IP):即网络五层协议中的网络层。
传输层(UDP):即网络五层协议中的传输层(选用UDP协议而不是TCP协议)。
IB传输层(Transport Layer):IB传输层负责数据包的分发、分割、通道复用和传输服务。接收方会确认数据包,然后把确认信息发动到发送方,发送方会根据这些确认信息更新完成队列。
RDMA硬件数据引擎层(Data Engine Layer):负责内存队列和RDMA硬件之间工作/完成请求的数据传输等。
RDMA接口驱动层:负责RDMA硬件的配置管理,负责队列和内存的管理,负责工作请求添加到工作队列中,负责完成请求的处理等。
Verbs API层:接口驱动的封装。管理连接状态、管理内存和队列访问、提交工作给RDMA硬件、从RDMA硬件获取工作和事件。
ULP层:OFED ULP(Upper Layer Protocol,上层协议)软件库,提供了各种软件协议的RDMA verbs支持,让上层应用可以无缝移植到RDMA平台。
应用层:分为两类,RDMA原生的应用,基于RDMA verbs API开发;另外,OFA提供了可以无缝兼容已有应用的OFED协议栈,让已有的应用可以无缝的使用RDMA功能。
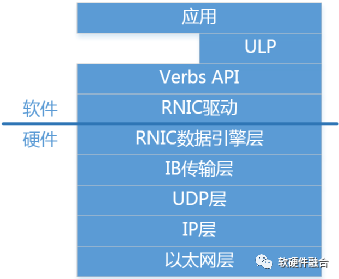
图2 RoCEv2分层
1.3 RDMA接口
RDMA并没有约束严格的软硬件接口,各家的实现各有不同,只需要支持RDMA的队列机制即可。Verbs API则是开源的标准的接口,具体的软硬件接口实现需要通过驱动对接到Verbs API。
a.RDMA工作队列
软件驱动和硬件设备的交互通常基于生产者消费者模型,这样能够实现异步的交互,实现软件和硬件的解耦。RDMA接口中驱动和设备的交互也是如此,RDMA软硬件共享的队列数据结构称为工作队列(Work Queue)。
如图3所示,工作队列是软件驱动和硬件RDMA交互的共享Queue。驱动负责把工作请求(Work Request)添加到工作队列,成为工作队列中的一项,称为工作队列项(Work Queue Element)。RDMA硬件设备会负责WQE在内存和硬件之间的传输,并且通过RDMA网络最终把WQE送到接收方的工作队列中去。最后,接收方RDMA硬件会反馈确认信息给到发送方RDMA硬件,发送方RDMA硬件会根据确认信息生成完成队列项(Completion Queue Element)发送到内存的完成队列(Completion Queue)。
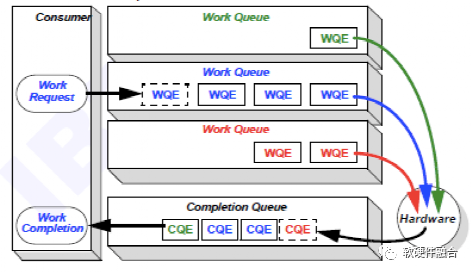
图3 RDMA数据传输模型——工作队列
RDMA Queue类型有:
发送队列(Send Queue):用于发送数据消息。
接收队列(Receive Queue):用于接收输入的数据消息。
完成队列(Completion Queue):完成队列主要是用于实现RDMA操作异步的实现。
队列对(Queue Pair):发送队列和接收队列组成一组队列对。
b.Verbs API操作
RDMA Verbs是提供给应用程序使用的最底层的RDMA功能抽象,RoCEv2中的Verbs操作主要有两类:
Send/Recv。类似于Client/Server结构,发送操作和接收操作协作完成,在发送方连接之前,接收方必须处于侦听状态;发送方不知道接收方的虚拟内存位置,接收方也不知道发送方的虚拟内存地址。不同的是RDMA Send/Recv因为是直接对内存操作,因此需要提前注册用于传输的内存区域。
Write/Read。与Client/Server架构不同,Write/Read是请求方处于主动,响应方处于被动。请求方执行Write/Read操作,响应方不需要做任何操作。为了能够操作响应方的内存,请求方需要提前获得响应方的地址和键值。
1.4 RDMA总结
计算机网络中的通信延迟主要是指:处理延迟和网络传输延迟。处理延迟开销指的就是消息在发送和接收阶段的处理时间。网络传输延迟指的就是消息在发送和接收之间的网络中传输的时间。在通常的南北向网络流量场景,基本都是远距离传输,网络传输延迟占了绝大部分,因此处理延迟问题并没有凸显。
随着云计算技术的发展,需要频繁的在集群服务器之间传递数据流量,数据中心中的东西向网络流量激增。在数据中心的短距离传输下,网络传输延迟大幅度缩小,处理延迟问题开始凸显。另外,东西向流量本身就是流量大、延迟敏感的应用场景,这要求进一步的优化处理延迟。如图4,RDMA不仅仅是一种高效的用于数据传输的软硬件接口,更是一种通过硬件实现网络数据传输加速的软硬件整体解决方案。
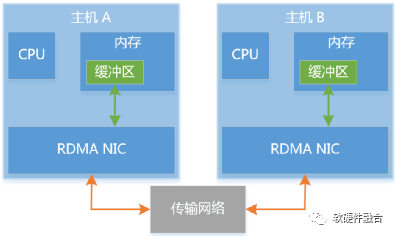
图4 RDMA传输模型
跟传统的TCP/IP网络技术相比,RDMA技术的优势体现在:
更高效的协议栈:InfiniBand相比传统的TCP/IP网络协议栈更加高效,RoCEv2使用了UDP,相比TCP更高效一些。因为是用于局域网的数据传输,数据的丢包率会低很多,UDP有更优的性能。
协议栈硬件卸载:整个RDMA协议栈处理完全由硬件完成,进一步提升性能,并且降低CPU资源消耗。
直接内存操作:内存一旦注册,数据就可以直接在内存和内存之间拷贝,不需要经过内核协议栈层的发送接收方各一次的拷贝;
操作系统 Bypass:没有了内核协议栈,用户空间驱动直接绕过内核,减少了操作系统模式切换的开销;
异步操作:一次事务操作分为发送Request(请求)和接收Completion(完成),这样就不会阻塞传输。
2 高性能网络优化
在基础网络、硬件加速以及网络接口都确定的情况下,为了更充分的利用网络容量,达到网络的高性能的同时防止性能抖动,就需要进行网络拥塞控制。
a.网络拥塞控制简介
网络中如果存在太多的数据包,会导致数据包的延迟,并且会因为超时而丢失,从而降低了传输性能,这种情况称为拥塞(Congestion) 。高性能网络非常重要的一个方面,就是在充分利用网络容量,提供低延迟网络传输的同时,尽可能的避免网络拥塞。
如图5(a)所示,当主机发送到网络的数据包数量在其承载能力范围之内时,送达的数据包数与发送的数据包数成正比例增长。随着负载接近网络承载能力,偶尔突发的网络流量会导致拥塞崩溃。如图 8.16(b)所示,为加载的数据包和延迟的函数关系,可以看到,当加载的数据包增加到接近承载上限的时候,其延迟时间是急剧上升的。
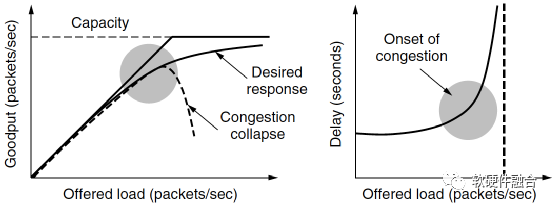
(a) 实际吞吐率的拥塞崩溃 (b) 延迟成指数上升
图5 网络拥塞导致的吞吐率和延迟问题
说明:拥塞控制和流量控制不是一回事:拥塞控制的目标是确保网络能够承载所有到达的流量,这是一个全局性的问题;相对的,流量控制只与特定的发送方和特定的接收方之间的点到点流量有关,流量控制的目标是确保一个快速的发送方不会持续地以超过接收方接收能力的速率传输数据。
针对拥塞所采取的办法有很多种,根据解决方案效果的从慢到快,介绍如下:
避免拥塞的最基本方法是建立一个与流量匹配的网络,需要根据流量的利用率增长趋势提前升级网络;
充分利用现有网络容量,根据不同时刻的流量模式度身定制路由,这称为流量感知的路由;
增加网络容量需要时间,因此解决拥塞的最直接的办法就是降低负载。比如拒绝新连接的建立,这称为准入控制;
当拥塞即将到来前,网络可以给造成拥塞问题的源端传递反馈信息,要求源端抑制它们的流量;
当一切努力均失败,网络不得不丢弃它无法传递的数据包,这称为负载脱落。
拥塞控制算法的目标是:
更加易于避免拥塞,即找到一种优化的带宽分配方法。一个优化的带宽分配方法能带来更好的性能,因为它能充分利用所有的可用带宽却能避免拥塞;
并且,此带宽分配算法对于所有传输是公平的,既能保证大流量数据流的快速传输,又能保证小流量数据流的及时传输;
最后,拥塞控制算法能够快速收敛到公平高效的带宽分配。
b.阿里云HPCC,RDMA拥塞控制优化
在过去的十年中,数据中心网络的端口带宽已从1 Gbps增长到100 Gbps,并且这种增长还在持续。越来越多的应用程序要求更低的延迟和更高的带宽,在数据中心,有两个重要的趋势驱动着对高性能网络的需求:
第一个趋势是新的数据中心架构。例如资源解构和异构计算:在资源解构中,CPU需要与GPU、内存和磁盘等远程资源进行高速网络互联;在CPU和加速器解构的异构计算环境中,不同的计算芯片也需要(通过网络)高速互连,并且延迟越小越好。
第二个趋势是新的应用程序。例如运行于高速IO介质(如NVMe)上的存储,以及在GPU和ASIC之类的加速计算设备上进行大规模机器学习训练。这些应用程序会定期的传输大量数据,其存储和计算速度非常快,性能的瓶颈通常是网络传输。
传统的基于软件的网络堆栈不再能够满足关键的延迟和带宽要求,将网络堆栈卸载到硬件中是高速网络中的必然方向。在数据中心中的部署RoCEv2,通过RDMA进行网络传输,是当前主要的硬件卸载解决方案。不幸的是,大规模的RDMA网络在平衡低延迟、高带宽利用率和高稳定性方面面临根本的挑战。经典的RDMA拥塞机制,例如DCQCN和TIMELY算法,具有一些局限性:
收敛缓慢。对于粗粒度的反馈,例如ECN(Explicit Congestion Notification,显式拥塞通知)或RTT(Round-Trip Time,传输往返时间),拥塞方案无法确切知道增加或降低发送速率的程度,使用启发式方法推测速率更新,迭代收敛到稳定的速率。
不可避免的数据包排队。DCQCN利用ECN标记来判断拥塞风险,TIMELY使用RTT增加来检测拥塞。两个算法都是在队列建立后,发送方才开始降低流量,这些堆积的队列会大大增加网络延迟。
复杂的参数调整。例如,DCQCN有15个参数可以调整,操作员在日常RDMA网络维护中要面对复杂且耗时的参数调整,这会大大增加配置错误的风险,这些错误配置会导致不稳定或性能下降。
HPCC(High Precision Congestion Control,高精度拥塞控制)背后的关键思想是利用INT(In-Network Telemetry,网络内遥测)提供的精确的链路负载信息来计算准确的流量更新,HPCC在大多数情况下仅需要一个速率更新步骤。HPCC发送方可以快速提高流量以实现高利用率,或者降低流量以避免拥塞;HPCC发送者可以快速调整流量,以使每个链接的输入速率略低于链接的容量,保持高链接利用率;由于发送速率是根据交换机直接测量的结果精确计算得出的,HPCC仅需要3个独立参数即可调整公平性和效率。
如图6,HPCC实现为由发送者驱动的拥塞控制框架。接收方确认发送方发送的每个数据包。数据包从发送方传输到接收方的过程中,路径上的每个交换机都利用INT功能插入一些元数据,这些数据报告了数据包出口的当前负载。当接收方收到数据包后,它将所有的元数据复制到ACK消息中。发送方根据ACK信息决定如何调整流量。
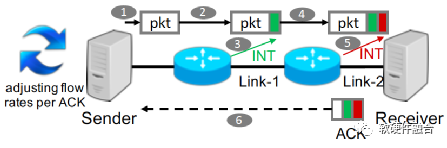
图6 HPCC框架示意图
图7为基于FPGA可编程NIC上的HPCC实现,NIC提供了一个FPGA芯片,并且用了基础的PCIe以及MAC模块,PCIe连接到主机内存,MAC模块连接到以太网。HPCC模块位于PCIe和MAC之间,实现发送方和接收方的角色。拥塞控制(CC)模块实现了发送方拥塞控制算法,它接收RX方向返回的ACK信息,根据这些信息调整发送窗口和速率,并且更新新的发送窗口和速率到流量调度器。
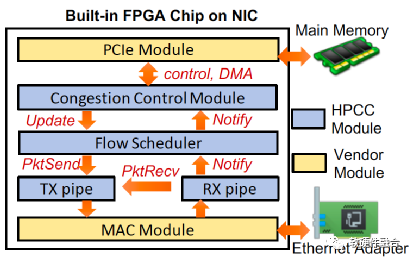
图7 支持HPCC的FPGA NIC实现
通过测试平台实验和大规模仿真,与DCQCN、TIMELY等方案相比,HPCC对可用带宽和拥塞的反应更快,并保持接近零的队列。在32台服务器测试平台中,在50%的流量负载下HPCC在中位数保持队列大小为零,当负载达到99%的情况下,队列大小为22.9KB(仅需要7.3µs的排队延迟)。与DCQCN相比,它使99%负载情况下的延迟减少了95%,而不会牺牲吞吐量。在320台服务器的测试中,即使DCQCN和TIMELY方案频繁发生PFC(Priority Flow Control,基于优先级的流量控制)风暴的情况下,HPCC也不会触发PFC暂停。
c.AWS的SRD和EFA
EFA(Elastic Fabric Adapter,弹性互联适配器)是AWS EC2实例的一种网络接口,EFA性能改进主要通过三项关键技术:
应用程序绕过操作系统内核直接与硬件对话,这提高了应用程序性能的稳定性;
持续开发和调整ENA和设备驱动程序以适应新的高带宽实例类型;
新的以云为中心的可靠性协议层,称为SRD(Scalable Reliable Datagram,可扩展可靠数据报)。
如图8,EFA定制的操作系统旁路硬件接口增强了实例间通信的性能。借助EFA,使用消息传递接口(MPI)的高性能计算(HPC)应用程序和使用NVIDIA集体通信库(NCCL)的机器学习(ML)应用程序可以扩展到数千个CPU或GPU,并且,将获得本地HPC集群的应用程序性能以及AWS云的按需弹性和灵活性。
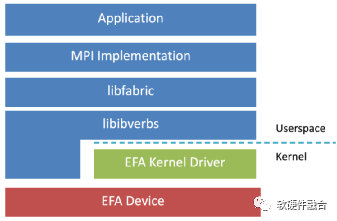
图8 基于EFA的HPC网络协议栈
SRD是专为AWS设计的可靠的、高性能的、低延迟的网络传输。这是数据中心网络数据传输的一次重大改进,已实现为AWS第三代NITRO芯片的一个重要功能。SRD受InfiniBand可靠数据报的启发,与此同时,考虑到大规模的云计算场景下的工作负载,SRD也经过了很多的修改和改进。SRD利用了云计算的资源和特点(例如AWS的复杂多路径主干网络)来支持新的传输策略,为其在紧耦合的工作负载中发挥价值。SRD的主要功能包括:
乱序交付:取消按顺序传递消息的约束,消除了行首阻塞,AWS在EFA用户空间软件堆栈中实现了数据包重排序处理引擎。
等价多路径路由(ECMP):两个EFA实例之间可能有数百条路径,使用大型多路径网络的一致性流哈希的属性,以及SRD对网络状况的快速反应能力,找到消息的最有效路径。数据包喷涂(Packet Spraying)可防止拥塞热点,并可以从网络故障中快速而无感地恢复。
快速的丢包响应:SRD对丢包的响应比任何高层级的协议都快得多。偶尔的数据包丢失是正常网络操作的一部分,这不是异常情况。
可扩展的传输卸载:使用SRD,与其他可靠协议(如InfiniBand可靠连接IBRC)不同,一个进程可以创建并使用一个队列对与任何数量的对等方进行通信。
表1为SRD和TCP、InfiniBand网络的功能特征对比:
表1 TCP、InfiniBand以及SRD的特征比较
| TCP | Infiniband | SRD |
| 基于流 | 基于消息 | 基于消息 |
| 顺序 | 顺序 | 乱序 |
| 单路径 | 单(ish)路径 | 负载均衡的ECMP喷涂 |
| 很长的重传超时(>50ms) |
静态的用户配置超时 (对数规模) |
动态估算的超时 (µs的精度) |
| 基于丢包率的拥塞控制 |
半静态的速率限制 (支持的速率有约束的设置) |
动态速率限制 |
| 低效的软件栈 | 受规模约束的传输卸载 |
可扩展的传输卸载 (相同数量的队列对,与集群大小无关) |
如图9所示,EFA非常明显的提高了带宽利用率(接近于线速100 Gbps),同时还明显的减少单数据包延迟,并且基于SRD的链接失效的处理,其性能抖动也变得非常的小。
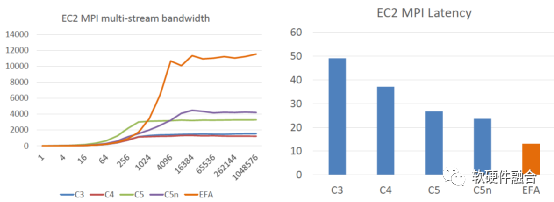
(a) EFA的带宽性能对比 (b) EFA的延迟性能对比
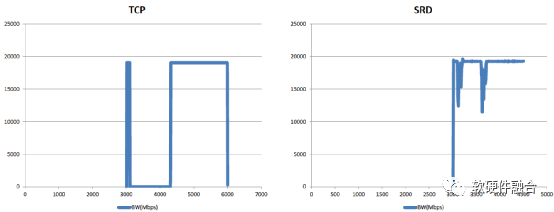
(c) SRD与TCP的性能抖动对比
图9 EFA/SRD的HPC性能
审核编辑 :李倩
-
服务器
+关注
关注
12文章
9191浏览量
85504 -
协议栈
+关注
关注
2文章
142浏览量
33642 -
AWS
+关注
关注
0文章
432浏览量
24387
原文标题:高性能网络及优化:RDMA/RoCEv2、AWS SRD & Aliyun HPCC
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Arm与AWS合作深化,AWS Graviton4展现显著进展
阿里云代理有哪些?
Forrester公有云评估:阿里云全球排名第二
以太网RDMA RoCE的技术局限
串口服务器NE2-T1M接入阿里云教程

IEC104转MQTT网关支持Zabbix、阿里云、华为云、亚马逊AWS、ThingsBoard、Ignition
阿里云设备的物模型数据里面始终没有值是为什么?
ESP32S3连接阿里云物联网平台LinkSDK报错怎么解决?
AWS豪掷78亿欧元,强化欧洲云计算布局

阿里云为什么能降价?释放了什么信号?
马云大幅增持阿里股票 马云取代软银成为阿里巴巴最大股东
RDMA RNIC虚拟化方案
阿里云是如何使用RDMA技术





 工商网监
工商网监
评论