 训练数据的质量决定了机器学习算法的上限
训练数据的质量决定了机器学习算法的上限

如今,越来越多的企业正利用图分析来增强机器学习,今天的随身听我们就一起来聊聊图和机器学习。如果您正从事机器学习相关的工作,但对图分析却不太了解,那么您可以点击文末的“阅读原文”,下载完整的《原生并行图》白皮书,来增强您对图的了解,从而更好地利用图来增强机器学习。下面就一起来收听今天的TigerGraph 随身听吧。
我们就以欺诈侦查为例,从许多方面来说,欺诈侦查如同大海捞针。您必须整理并理解海量的数据,才能找到那根“针”,在本例中是指欺诈者。事实上,越来越多的组织利用机器学习及图技术来防止各种类型的欺诈,包括电话诈骗、信用卡退单、广告、洗钱等。
训练数据的质量决定了机器学习算法的上限
在进一步探讨机器学习与图技术这一强大组合的价值之前,我们先看一下当前基于机器学习的欺诈者识别是如何错失目标的。
为了侦查某一具体的情况,如从事诈骗的电话或涉嫌洗钱的付款交易,机器学习系统需要足够数量的欺诈电话或可能与洗钱相关的支付交易。下面我们以电话欺诈为例深入分析。
除可能属于欺诈的电话数量外,机器学习算法还需要与电话欺诈行为高度相关的特征或属性。
由于欺诈(与洗钱非常相似)在交易总量中所占的比重不到 0.01% 或万分之一,因此,存在确认欺诈活动的训练数据体量非常小。相应地,数量如此之少的训练数据将导致机器学习算法的准确度不佳。
选择与欺诈相关的一些特征或属性十分简单。就电话欺诈来说,这些特征或属性包括某些电话呼叫其他网内网外电话的历史记录、预付费 SIM 卡的卡龄、单向呼叫(即被呼叫方未回电)所占的百分比,以及被拒呼叫所占的百分比。同样,为了查找涉嫌洗钱的付款交易,需要为机器学习系统提供诸如付款交易的规模和频率等特征。
但是,由于依赖仅侧重于各个点的特征,导致误报率居高不下。例如,频繁进行单向呼叫的电话可能属于销售代表所有,他们需要致电潜在客户寻找销售线索或销售商品和服务。这种呼叫也可能涉嫌骚扰,是一方对另一方的恶作剧。大量的误报会造成浪费精力去调查非欺诈电话,最终降低对欺诈侦查机器学习解决方案的信心。
算法好不如数据多
在机器学习领域有一个很流行的说法:“算法好不如数据多”。很多机器学习就是因为缺乏充足的训练数据而失败的。简单来说,样本大小直接影响着预测的质量。与海量的交易相比(订单、付款、电话呼叫和计算机访问日志),诸如欺诈、洗钱或网络安全违规等异常检测事件的确认量很低。
很多大型客户使用 TigerGraph 来计算机器学习领域所谓的基于图的属性或特征。就中国移动来说,TigerGraph 为其 6 亿个号码分别生成 118 项新特征。这将创造超过 700 亿项新特征,用于将存在疑似欺诈活动的“坏号码”与其余属于普通用户的“好号码”区分开来。这将会有更多训练数据,供机器学习解决方案提高欺诈侦查的准确性。
为电话欺诈打造更好的“磁石”
很多现实生活中的示例不断证明着图技术和机器学习在打击欺诈方面的价值。目前,知名大型移动运营商正使用具备实时深度关联分析的新一代图数据库,解决现有机器学习算法训练方法的缺陷。该解决方案分析了 6 亿部手机的超过 150 亿通呼叫,最终为每个手机生成了 118 项特征。这些特征基于对通话记录的深度分析,范围不限于直接被呼叫方。
那么图数据库是如何识别“好”号码或“坏”号码呢?图数据库解决方案又是如何识别疑似欺诈的类型(例如,垃圾邮件广告、诈骗销售等),并且在被呼叫人的手机上显示警告消息?而且这一切全部都在手机接通之前完成。
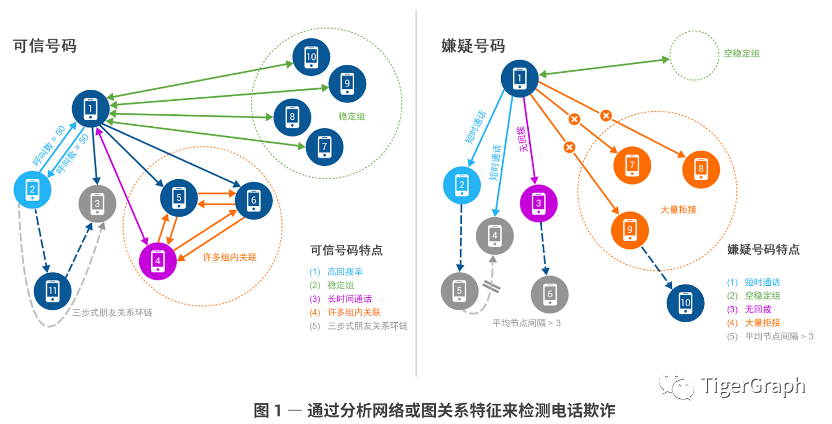
其实,简单来说,文中图1所示,拥有好号码的用户致电其他用户,大多数人都会回复他们的电话。这有助于指示用户之间的熟悉度或信任关系。好号码还会定期(比如,每天或每月)拨打一组其他号码,这一号码组在一段时间内非常稳定(“稳定组”)。
表示好号码行为的另一个特征是,当呼叫已经入网数月或数年的号码时得到回电。我们还看到,在好号码、长期联系号码及网内与二者频繁联系的其他号码之间有着大量呼叫。这表明我们的好号码具有很多组内关联。
最后,“好号码”通常会参与三步式朋友关联,意思是我们的好号码会呼叫另一号码,即号码 2,后者将呼叫号码 3。好号码还会通过直接呼叫与号码 3 联系。这表示一种三步式朋友关联,形成信任和相互关联性圆环。
通过分析号码之间的这类呼叫模式,我们的图解决方案可以轻松识别坏号码,即可能涉嫌诈骗的号码。这些号码会短暂呼叫多个好号码,但不会收到回电。此外,它们也没有定期呼叫的稳定号码组(即“空稳定组”)。当坏号码呼叫长期网内用户时,对方不会回电。坏号码的很多呼叫还会被拒绝,而且缺乏三步式朋友关系。
图数据库平台利用超过 100 项图特征(如稳定组),它们与我们使用案例中的 6 亿移动号码各自的好坏号码行为高度相关。相应地,它可以生成 700 亿项新的训练数据特征,供机器学习算法使用。最终提高了欺诈侦查机器学习的准确率,同时减少误报(即非欺诈号码被标记为潜在欺诈者号码)和漏报(即未标记出参与欺诈的号码)。
为了了解基于图的特征如何提高机器学习的准确率,我们来看一个示例(下图2),其中使用了以下四位移动用户的侧写:Tim、Sarah、Fred 和 John。
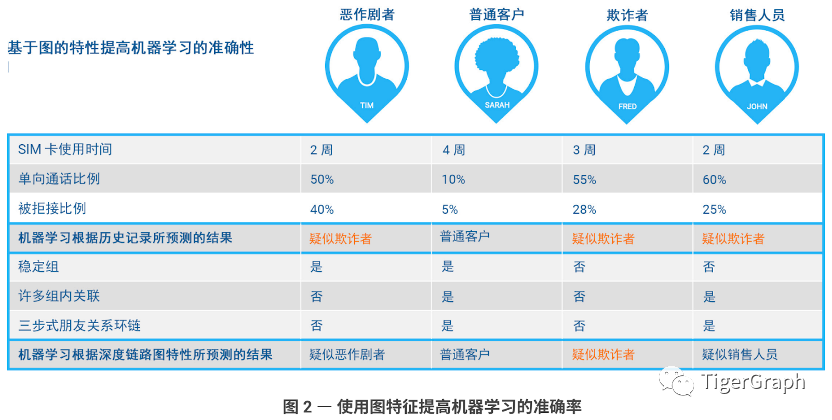
按照传统的通话记录特征,如 SIM 卡龄、单向呼叫的百分比以及被拒绝的呼叫总量百分比),四人中的三人(Tim、Fred 和 John)将被标记为疑似或潜在欺诈者,因为从这些特征来看,他们非常相似。经过分析基于图的特征,以及号码和用户之间的深度关联或多步关系,最终帮助机器学习将 Tim 归类为爱恶作剧者、John 为销售人员,而 Fred 则被标记为疑似欺诈者。我们来思考一下这个过程。
就 Tim 来说,他有一个“稳定组”,这意味着他不太可能是销售人员,因为销售人员每周都会拨打不同的电话号码。Tim 没有很多组内关联,这意味着他可能经常给陌生人打电话。他也没有任何三步式朋友关联,用于确认他所呼叫的陌生人不存在关联。根据这些特征判断,Tim 很可能是爱恶作剧者。
我们来看一下 John 的情况,他没有稳定组,这意味着他每天都通过电话寻找新的潜在销售线索。他会给具有很多组内关联的人打电话。当 John 介绍产品或服务时,如果接听方对它们感兴趣或认为与自己相关,则其中一些人很可能会将 John 介绍给其他联系人。John 还通过三步式朋友关系与他人产生关联,这表明他作为优秀的销售人员将整个环链闭合,通过在同一组内第一次联系的人的朋友或同事当中遴选,找到最终的买家来购买他的产品或服务。依据这些特征的组合,最终将 John 归类为销售人员。
就 Fred 来说,他既没有稳定组,也不与具有很多组内关联的群体交流。此外,他与所呼叫的人之间也没有三步式朋友关系。这使得他非常容易成为电话诈骗或欺诈的调查对象。
回到我们最初海底捞针的比喻,在本例中,我们可以利用图分析改善机器学习,进而提高准确率,最终找到那根“针”,即潜在的欺诈者 Fred。为此,需要使用图数据库框架对数据进行建模,以便能够识别和考虑更多特征,用于进一步分析我们的海量数据。相应地,计算机将利用越来越准确的数据进行训练,使自己不断变得聪明,更加成功地识别潜在的诈骗分子和欺诈者。
如果您正从事机器学习相关的工作,希望利用图分析来增强机器学习,别忘了点击文末的“阅读原文”,下载完整的《原生并行图》白皮书,来增强您对图的了解,从而更好地将图应用到您的工作中。
另外,您也可以下载使用TigerGraph 机器学习工作台(ML Workbench),这是一个基于Jupyter的Python开发框架,可以使数据科学家,人工智能和机器学习的从业者更容易、也更熟悉地使用图分析,而无需学习很多新的数据处理方式。比如数据科学家可以使用TigerGraph 机器学习工作台(ML Workbench),更快速地构建图神经网络 (GNN) 模型,轻松探索图神经网络(GNN)。它提供了 Python 级别强大而高效的数据管道,将数据从 TigerGraph 流式传输到用户的机器学习系统,执行常见的数据处理任务,例如对图数据集的训练、验证和测试,以及各种子图采样方法。详细信息,可以点击文中链接查看往期的TigerGraph 随身听(Vol.23 TigerGraph机器学习工作台)。
以上就是我们今天的随身听内容,如果您对于我们讨论的应用场景,有任何问题,或者希望和我们进行更有针对性的深度探讨,欢迎通过文中的联系方式和我们联系。
审核编辑 :李倩
-
算法
+关注
关注
23文章
4810浏览量
98597 -
机器学习
+关注
关注
67文章
8567浏览量
137234
原文标题:Vol.33 图和机器学习,为电话欺诈检测打造更好的“磁石”
文章出处:【微信号:TigerGraph,微信公众号:TigerGraph】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
机器学习中的数据质量双保障:从“验证”到“标记”

算法工程师需要具备哪些技能?
机器学习和深度学习中需避免的 7 个常见错误与局限性
穿孔机顶头检测仪 机器视觉深度学习

半导体缺陷检测升级:机器学习(ML)攻克类别不平衡难题,小数据也能精准判,降本又提效!

如何在NVIDIA Isaac Lab中使用Newton训练四足机器人
量子机器学习入门:三种数据编码方法对比与应用

模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题

AI 驱动三维逆向:点云降噪算法工具与机器学习建模能力的前沿应用




评论