 模型压缩算法的设计思路、实现方式及效果
模型压缩算法的设计思路、实现方式及效果
MLPerf竞赛由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、斯坦福、哈佛大学等单位共同成立,是国际上最有影响力的人工智能基准测试之一。
在MLPerf V0.7推理竞赛开放赛道中,浪潮信息通过模型压缩优化算法取得性能大幅提升,将ResNet50的计算量压缩至原模型的37.5%,压缩优化后的ResNet50推理速度相比优化前单GPU提升83%,8GPU提升81%,基于浪潮NF5488A5服务器,每秒最多可以处理549782张图片,排名世界第一。
本文将重点介绍浪潮在比赛中使用的模型压缩算法的设计思路、实现方式及效果。
什么是模型压缩
为了提高识别准确率,当前深度学习模型的规模越来越大。ResNet50参数量超过2500万,计算量超40亿,而Bert参数量达到了3亿。不管是训练还是推理部署,这对平台的计算能力和存储能力都提出了非常高的要求。当前深度学习已经发展到部署应用普及阶段,在移动端/嵌入式端设备,计算/存储资源是有限的,大模型难以适用。
很多深度神经网络中存在显著的冗余,仅仅训练一小部分原来的权值参数就有可能达到和原网络相近的性能,甚至超过原网络的性能[1]。这给模型压缩带来了启发。
模型压缩是通过特定策略降低模型参数量/计算量,使其运行时占用更少的计算资源/内存资源,同时保证模型精度,满足用户对模型计算空间、存储空间的需求,从而能够将模型更好地部署在移动端、嵌入式端设备,让模型跑得更快、识别得更准。
常用模型压缩方法
模型压缩有多种实现方法,目前可分为5大类:
▣模型裁剪
实现方式:对网络中不重要的权重进行修剪,降低参数量/计算量。
使用方式:分为非结构化裁剪与结构化裁剪,非结构化裁剪需结合定制化软硬件库,结构化裁剪无软硬件限制。
▣模型量化
实现方式:以低比特位数表示网络权重,(如fp16/8bit/4bit/2bit),降低模型的占用空间,进行推理加速。
使用方式:需要定制化软硬件支持,如TensorRT、TVM。
▣知识蒸馏
实现方式:迁移学习的一种,用训练好的“教师”网络去指导另一个“学生”网络训练。
使用方式:大模型辅助小模型训练来帮助小模型提升。
▣精度紧凑网络
实现方式:设计新的小模型结构,如MobileNet、ShuffleNet。
▣低秩分解
实现方式:将原来大的权重矩阵分解成多个小的矩阵。
使用方式:现在模型多以1x1为主,低秩分解难以压缩,目前已不太适用。
上述几种模型压缩技术中,模型量化对推理部署软硬件的要求较高,知识蒸馏一般用来辅助提高精度,紧凑网络模型结构相对固定,低秩分解不适用目前主流模型结构。而模型裁剪可以对模型结构灵活压缩,满足用户对计算量/参数量的需求,且压缩后的模型仍可保持较高精度,本文将重点介绍模型裁剪方法。
模型裁剪相关技术
如前所述,模型裁剪分为非结构化裁剪与结构化裁剪。非结构化裁剪是一种细粒度裁剪,通过裁剪掉某些不重要的神经元实现,优点是裁剪力度较大,可将模型压缩几十倍,缺点是裁剪后的模型部署需要定制化的软硬件支持,部署成本较高。而结构化裁剪是一种粗粒度裁剪,一般有channel、filter和shape级别的裁剪,这种方法裁剪力度虽然不像非结构化裁剪力度那么大,但好处是裁剪后的模型不受软硬件的限制,可以灵活部署,是近几年模型压缩领域研究者/公司的研究热点。本文我们重点研究结构化裁剪。
结构化模型裁剪近几年涌现很多优秀论文,压缩成绩不断被刷新,压缩技术从手动化结构裁剪进化到基于AutoML的自动化结构化裁剪。以下是几种代表性的方法:
将训练好的模型进行通道剪枝(channel pruning)[2]。通过迭代两步操作进行:第一步是channel selection,采用LASSO regression来做;第二步是reconstruction,基于linear least squares来约束剪枝后输出的feature map尽可能和减枝前的输出feature map相等。
麻省理工学院韩松团队提出了一种模型压缩方法[3],其核心思想是使用强化学习技术来实现自动化压缩模型。它不是对网络结构的路径搜索,而是采用强化学习中的DDPG(深度确定性策略梯度法)来产生连续空间上的具体压缩比率。
基于元学习的自动化裁剪方法[4],分三步实现:首先生成元网络进行权重预测;然后基于元网络利用遗传进化算法进行裁剪模型结构搜索;最后筛选出符合要求的裁剪模型结构,对候选模型进行训练。
对ResNet50模型的压缩优化
我们选择Resnet50进行模型压缩。从MLPerf竞赛开始至2022年,而Resnet50始终是图像分类任务的基准模型,是计算机视觉领域模型的典型代表。
在裁剪方法的选择上,我们采用基于AutoML的自动化裁剪方法。该方法的优势是可以灵活定义搜索空间,从而灵活裁剪出所需要的任何模型结构。
Resnet50的裁剪要求可概括为“快且准”,实现方法分以下三步:
▣ 第一,与MetaPruning类似,首先生成一个“超网络”,为后续搜索出的裁剪模型生成权重及预测精度。
▣第二,优化搜索空间。自动化模型裁剪方法会基于特定方法对裁剪模型进行搜索,搜索方法与搜索效率直接影响到目标模型的质量,我们对模型裁剪的搜索空间与搜索方法进行了深度优化。这一步是搜索出符合预期的最优裁剪模型结构的关键,也是对Resnet50模型裁剪优化的关键技术点。
传统方法在裁剪时一般以模型的计算量/参数量为裁剪指标,比如需要将参数量/计算量裁剪掉多少,但是我们对裁剪的终极目标之一是在推理部署时降低延迟,也就是快且准中的“快”。而单纯降低模型参数量/计算量并不代表一定能带来模型性能提升,需要考虑裁剪后模型计算强度与平台计算强度的关系,参考roofline model理论。
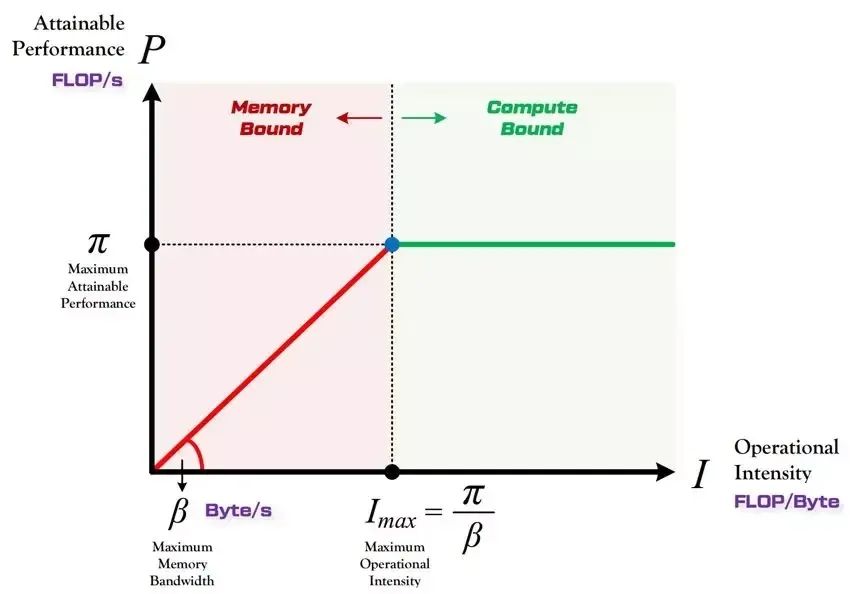
图1 Roofline model示意图▲
图1为roofline model示意图,roofline model展示了模型在计算平台的限制下能达到多快的计算速度,使用计算强度进行定量分析。当模型计算强度小于平台计算强度(红色区域),模型处于内存受限状态,模型性能<计算平台理论性能,性能提升<计算量减少;当模型计算强度大于平台计算强度(绿色区域),模型处于计算受限状态,模型性能约等于计算平台理论性能,性能提升接近计算量减少。
同时我们研究发现,某些情况下,单纯减少channel不一定会带来模型性能提升甚至可能会降低模型性能,另外,裁剪后模型的推理性能因目标运行设备不同存在差异。也就是说单纯裁剪channel不一定会带来性能提升,甚至有可能会适得其反,裁剪后模型的实际性能与部署的目标设备相关,平台计算特性和模型结构特点紧密相关。
基于以上研究,我们对裁剪模型的搜索空间做了重点优化,提出了基于性能感知的模型裁剪优化方法。在对裁剪模型结构进行搜索时,除了考虑裁剪后模型的规模如计算量/参数量(FLOPS/Params),同时考虑不同模型结构(channel/shape/layers)基于设备平台的真实性能表现,也就是裁剪模型在推理部署平台上的的推理延迟时间(latency)。具体做法如下:
由于单纯的计算量/参数量并不能反映模型在计算平台上的真实性能,我们首先将不同的模型结构在计算平台进行性能测试,决定模型的哪些层的channel需要多裁,哪些层的channel需要少裁,裁掉哪些层对实际性能提升效果最好。我们对resnet50的模型结构特点进行了研究。图2为resnet50模型[5]结构图,该模型结构分为5个conv模块,conv1是一个7x7卷积,conv2-conv5都是由bottleneck组成,分别包含3/4/6/3个bottleneck。
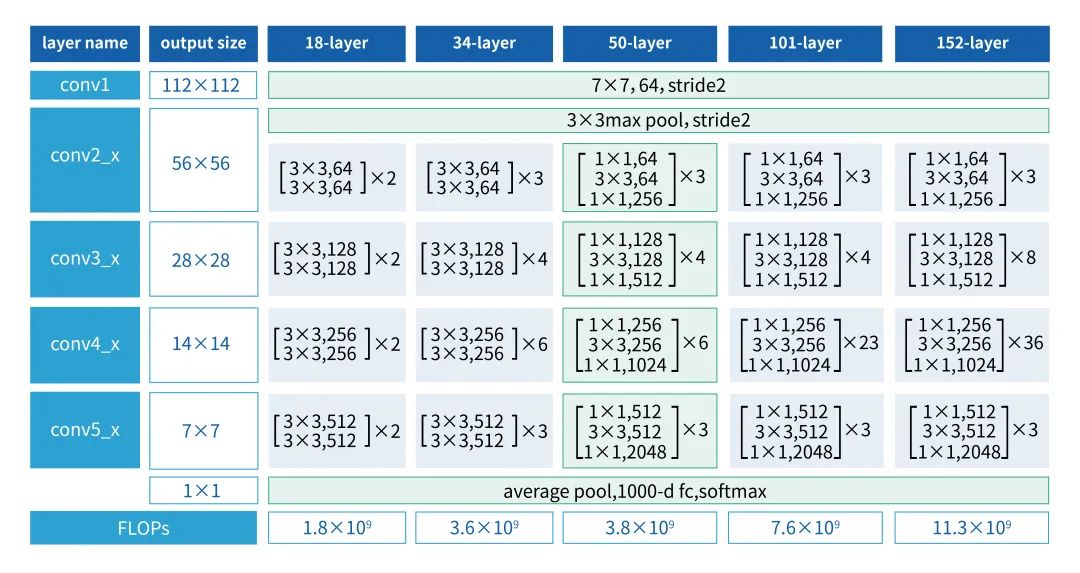
图2 resnet50模型结构▲
以bottleneck为基本测试单位,模型推理测试平台选择tensorrt,对于每一个bottleneck,改变他们的输入输出channel个数,测试其在tensorrt上的推理性能表现,得到了每一个bottleneck在不同的输入输出channel下的实际性能表现。图3展示了实验中resnet50第三个stage的第6个bottleneck在不同的输出channel个数下,在tensorrt上测试的推理性能。
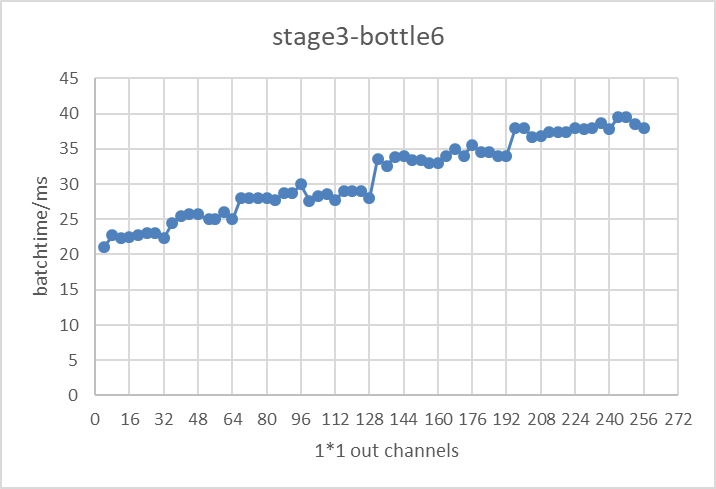
图3 resnet50conv3_bottleneck6基于tensorrt的推理延迟▲
由图3结果可以看出,该模型结构下测得的推理延迟时间并不会随着channel个数的增加而线性增长,推理时间与channel个数呈现出阶梯状关系(如当32<channel个数≤64时,推理性能持平)。该实验结果带来的启发是,在对模型进行裁剪时,我们选择保留阶梯线右侧边缘的channel个数,这样既能保证推理性能又能尽可能保证模型本身的channel个数;
在对裁剪模型进行自动化搜索时,除了基于计算量/参数量参考指标,提出了以延迟为优化目标的自动化模型裁剪方法。将基于性能感知的约束条件添加到裁剪模型搜索空间,在对裁剪模型进行搜索时,可同时满足对计算量/参数量/延迟的多重要求,尽可能保证裁剪后的模型在推理部署阶段最大限度地降低延迟。在裁剪模型搜索阶段,我们的优化代码第一阶段首先会指定裁剪模型的计算量/参数量,通过计算量/参数量的设定去搜索符合条件的裁剪模型。在裁剪模型的搜索空间中,每一层channel个数的设定会参考(1)中的测试结果。第二阶段在搜索出的候选裁剪模型中,计算每个候选裁剪模型在目标推理平台上的推理耗时,筛选出推理耗时最小的模型为我们的目标裁剪模型,从而保证裁剪模型是在计算量/参数量/延迟三个层面搜索出的最优结果。
第三步,裁剪后模型精度恢复。对于模型裁剪,大家最关注的问题是裁剪后的模型是否能恢复到与裁剪前相近的精度,也就是快且准中的“准”。一般的模型裁剪方法是将模型裁剪之后进行finetune或者一边裁剪一边训练,而通过我们的实验发现通过裁剪算法得到的压缩模型,直接随机初始化训练(Training from scratch)得到的模型精度,反而比基于原模型权重finetune效果更好,Training from scratch可以更多去探索稀疏化模型的表达空间,所以我们对于裁剪后的模型采用Training from scratch的训练方式。同时,为了尽可能恢复裁剪后模型的精度,我们结合蒸馏训练,用大模型去指导裁剪后的小模型训练,在精度保持上取得了非常好的效果。
表1是我们裁剪并训练出的一些模型,将Resnet50计算量裁剪到原来的50%、37.5%时,仍然可以保持76%以上的TOP1精度:
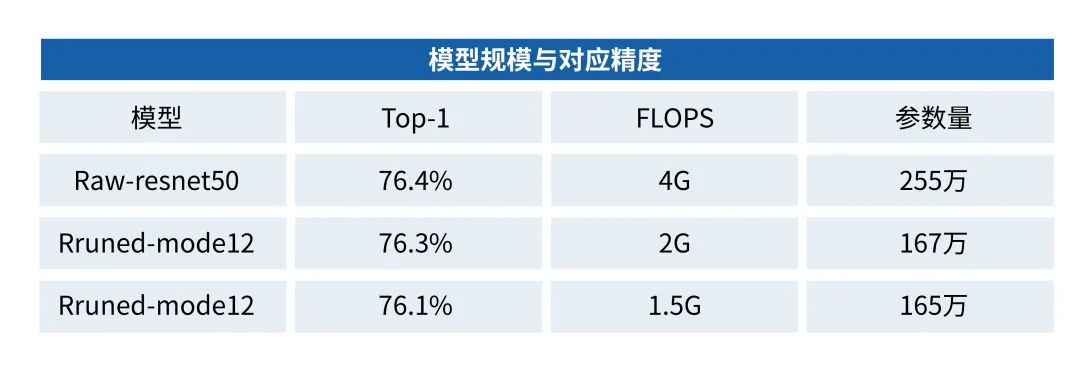
表1模型规模与对应精度▲
基于浪潮NF5488A5平台,未经过压缩优化的Resnet50推理性能如表2:

表2 压缩前的Resnet50基于NF5488A5的性能▲
而经过压缩优化后,Resnet50在开放赛道的性能如表3:

表3 压缩后的Resnet50基于NF5488A5的性能▲
综上,在MLPerf推理V0.7竞赛开放赛道中,基于压缩优化算法,我们将ResNet50计算量压缩到原来的37.5%,压缩优化后的ResNet50模型单GPU推理速度相比压缩优化前提升83%,8GPU推理速度相比压缩优化前提升81%。基于浪潮NF5488A5服务器,单卡每秒可处理68994张图片,8卡每秒可以处理549782张图片,这个成绩在当时参赛结果中排名第一。
-
嵌入式
+关注
关注
5068文章
19013浏览量
303074 -
服务器
+关注
关注
12文章
9015浏览量
85169
原文标题:MLPerf世界纪录技术分享:通过模型压缩优化取得最佳性能
文章出处:【微信号:浪潮AIHPC,微信公众号:浪潮AIHPC】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
常见人体姿态评估显示方式的两种方式
【BearPi-Pico H3863星闪开发板体验连载】LZO压缩算法移植
PolarDB-MySQL引擎层的索引前缀压缩能力的技术实现和效果
如何评估AI大模型的效果
Huffman压缩算法概述和详细流程
FP8模型训练中Debug优化思路
ai大模型和算法有什么区别
【RTC程序设计:实时音视频权威指南】音视频的编解码压缩技术

基于门控线性网络(GLN)的高压缩比无损医学图像压缩算法
详解从均值滤波到非局部均值滤波算法的原理及实现方式
AI模型常见压缩及减量方式





 工商网监
工商网监
评论