 TC3xx内部模块框图和各种内部总线及存储器访问方式
TC3xx内部模块框图和各种内部总线及存储器访问方式
前言
TriCore是英飞凌自主开发的私有内核。早在2000年,英飞凌发布了第一代TriCore单片机产品。英飞凌为TriCore申请了注册商标,在一个内核架构里集成了RISC精简指令集单片机,MCU微控制器,DSP数字信号处理的功能,是一款计算能力强大的32位实时单片机内核架构。TC3xx系列MCU是基于TC1.6P作为其内核的。本系列文章将记录Infineon芯片的学习笔记。本文首先介绍TC3xx的内部模块框图和各种内部总线以及存储器访问方式,接着介绍TC1.6.2的内核架构,这其中主要介绍了寻址方式,通用寄存器,上下文管理,中断机制,Trap机制,MPU机制等内容。
1.Architectural Overview
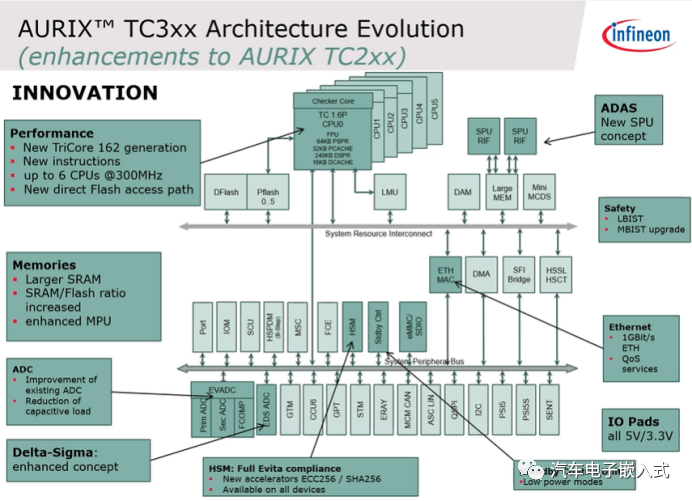
图1:TC3xx相比于TC2xx改进部分
如图一所示,TC3xx内部最多支持6个核,这些核间使用SRI总线进行通信,每个核都有自己的Memory。TC3xx在核架构上相比于TC2xx做了如下改进:
1.1 Performanc
1)支持Tricore 1.6.2的内核
2)增加了新的指令
3)最多支持6个核,最大主频达到300MHz
4)每个CPU有自Local的Flash bank,也就是说有自己的Local的总线可以访问自己Local的Flash bank,速度更快
5)
1.2 Memories
1)更大的SRAM
2)更强大的内存保护单元MPU。数据和代码保护的Register的设置更多。
1.3 ADC
1)TC2xx有队列模式,自动扫描模式,背景扫描模式,TC3xx只有队列扫描模式,更加的灵活。
1.4 Delta-Sigma
1.5 HSM
1)支持非对称加密算法
1.6 Standby control unit
专门的低功耗管理单元
1.7 IO Pads
支持5/3.3v两种硬件系统
1.8 Ethernet
1)支持千M以太网,支持一部分TSN/AVB的功能
1.9 Safety
1.10 ADAS
增强的SPU
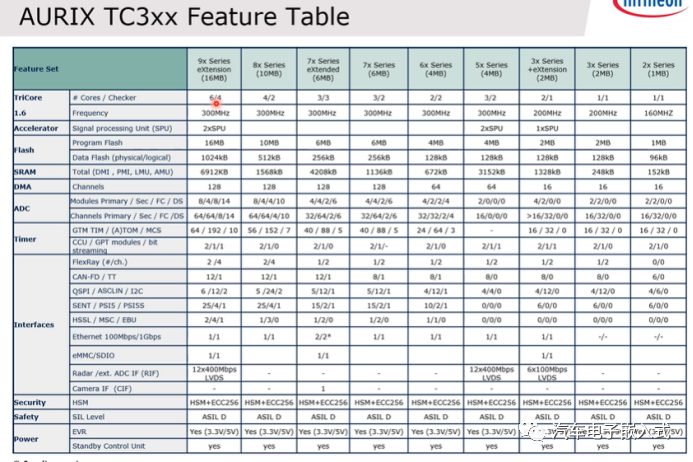
图2:TC3xx系列资源概况
2.Memory Concept
2.1 Memory architecture
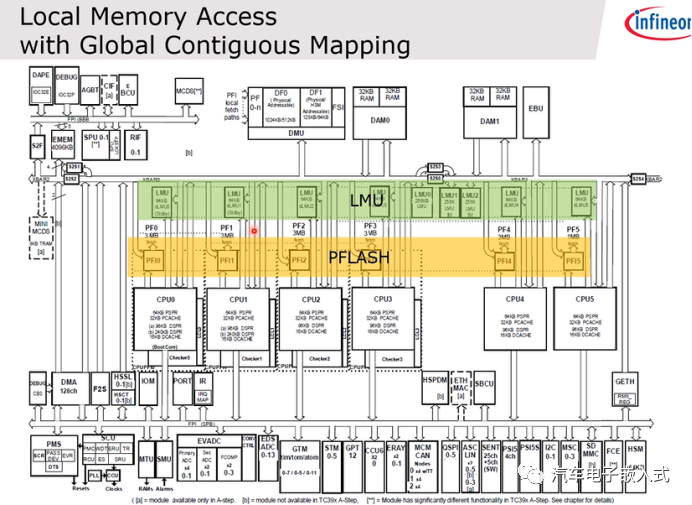
图3:TC3xx内存架构
主要关注PFlash和LMU部分。
每个CPU都可以通过一个私有的LPB总线访问各自3M的PFlash的bank,访问速度比较快。外部有个LMU的Ram,分为两种,一种叫dLMU,另一种叫LMU。每个cpu可以通过私有的总线访问dLMU,对于LMU,CPU只能通过SRI总线来访问,速度相对dLMU的访问较慢。
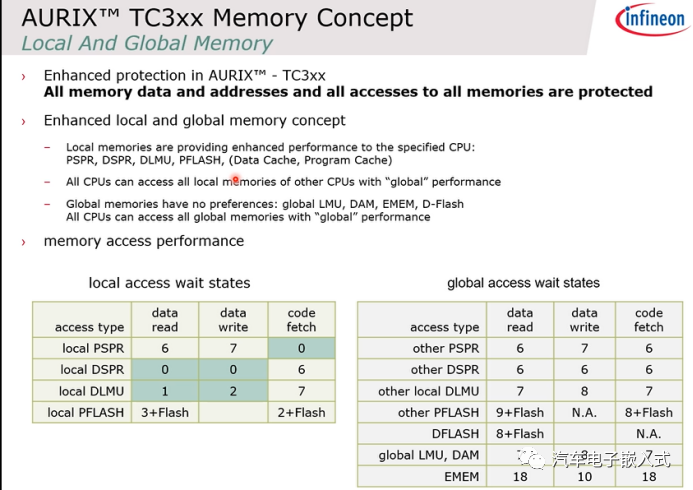
图4:TC3xx内存访问速度
PSPR,DSPR,DLMU都是Local的SRAM,CPU访问自己的Local Ram的熟读非常的快,例如CPU读写local DSPR都是0等待时间的。CPU也能范围其他核的Local Ram,但是读/写/取指的速度就会变慢。
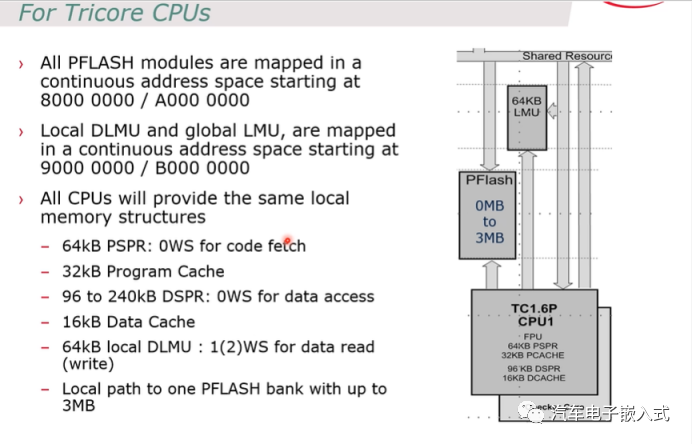
图5:内存范围起始地址
对于同一款内存可以使用cache的访问方式或者非cache的访问方式。例如对于PFLASH的访问如果使用cache则起始地址是0x80000000,非cache的访问方式的起始地址是0xA0000000。同样,LMU也存在0x90000000/0xB00000000两个起始地址。
对于每个CPU内部的PSPR和DSPR都不需要使用cache,CPU等待时间是0ws。
每个CPU都有3M的local PFLASH的bank,CPU通过LPB总线访问PFLASH。这个LPB总线在使能了AB SWAP之后就会被disable掉,这么做的原因是为了让code运行在A Bank还是B Bank的performence都是一样的(是能ab swap和disable lpb总线的操作在UCB的一块区域操作)。
2.2 Memory and connectivity
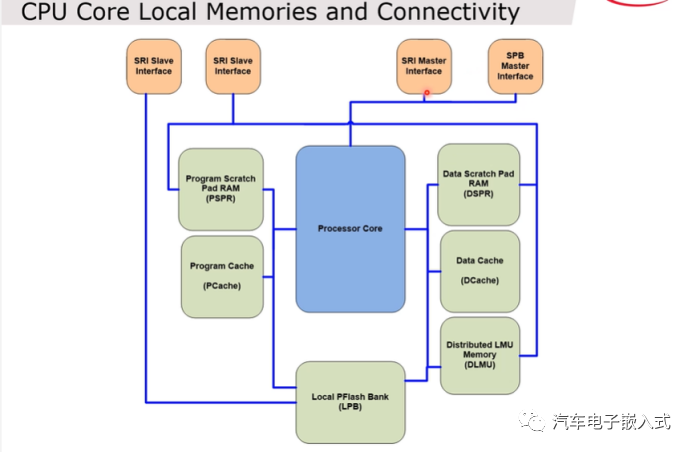
图6:CPU内部总线连接图
CPU通过SRI Master Interface连接到其他core的SRI Slave Interface来范围其他核的memory。
2.3 Memory map
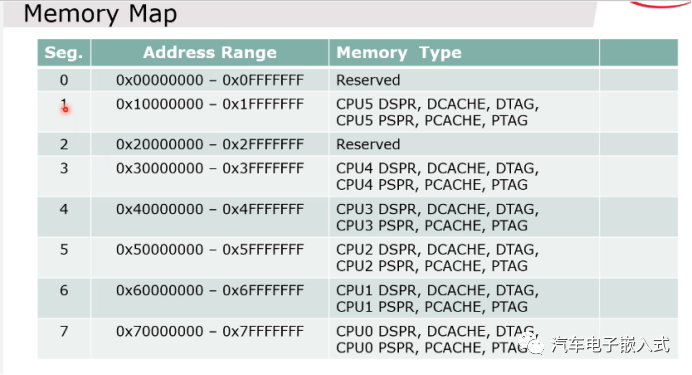
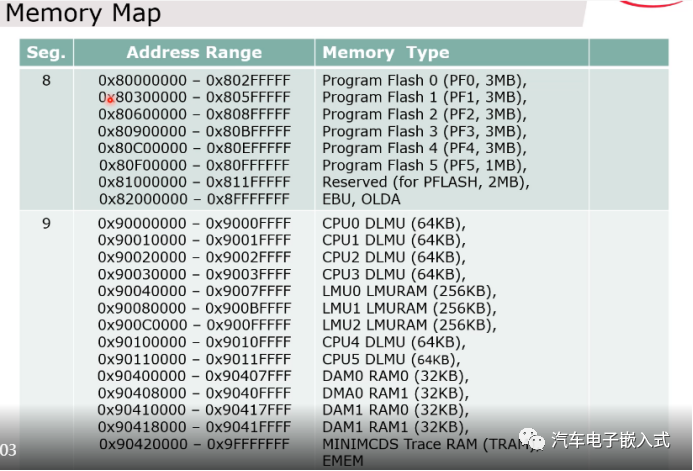
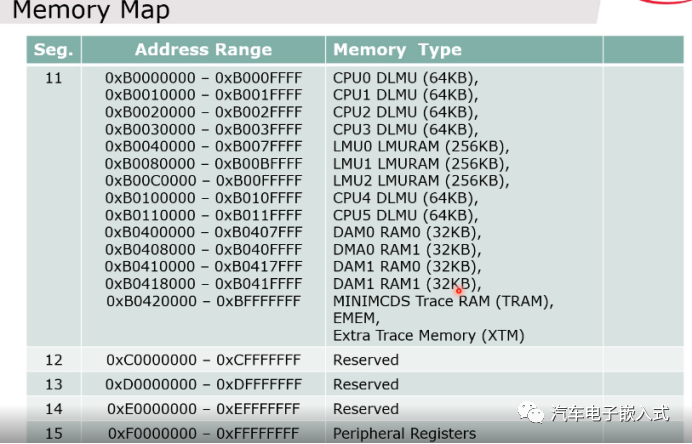
图7:内存映射图
3.On-chip Bus Connectivity
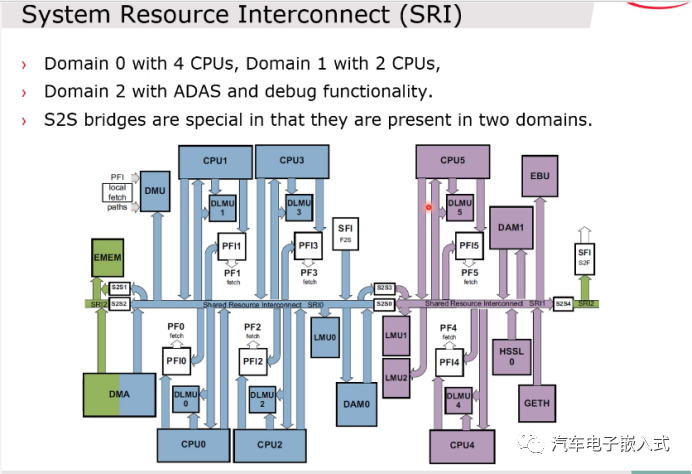
图8:SRI总线
Tricore里面,内核之间的相互访问和通信都是通过SRI总线进行的。Tricore 1.6.2里面SRI总线有3个Domain,Domain 1包括CPU0-3,通过SRI0进行相互访问。其他类似。SRI直接通过S2S Bridge连接。
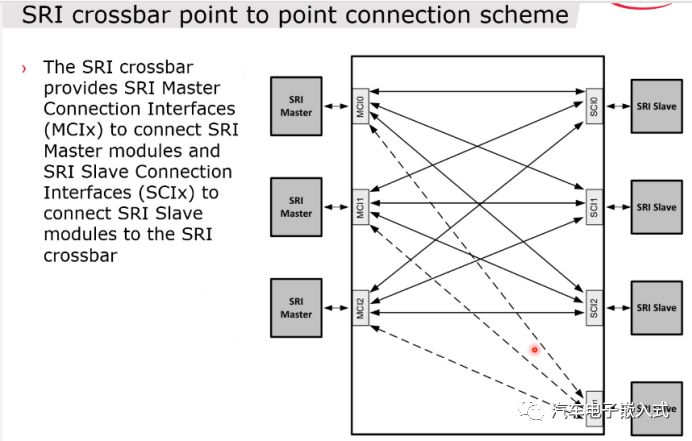
图9:SRI总线连接图
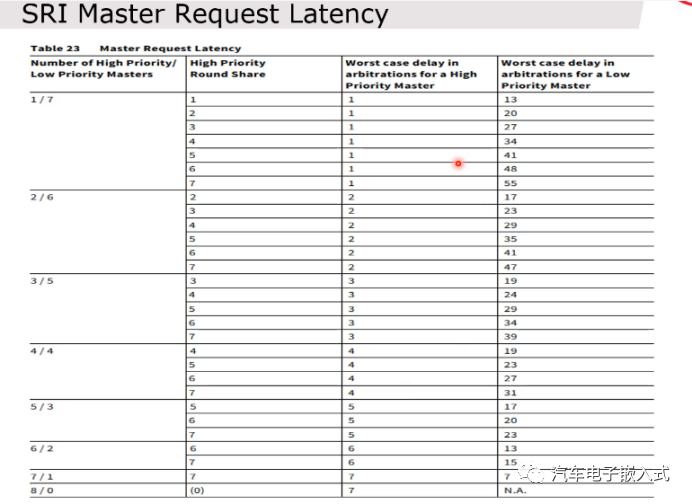
图10:SRI总线间最差延迟时间
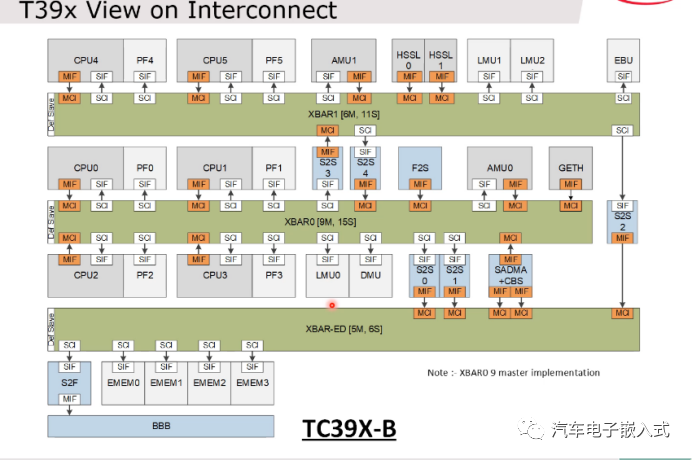
图11:TC39x内部SRI总线连接图
每个SRI总线都有一个SRI Master Interface和一个SRI Slave Interface,对于一个SRI总线的SRI Slave Interface就存在同一时间多个SRI Master Interface访问的问题,那么就需要SRI具有仲裁的功能。
4.TC1.6.2 Architecture
4.1 TriCore concept
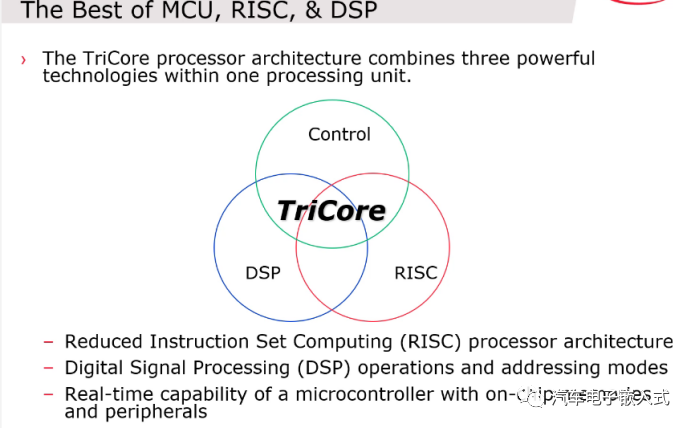
图12:TriCore定义
TriCore的含义:既有RISC精简指令集的特性,也集成了DSP数字信号处理器的性能,同时也可以实现实时控制。
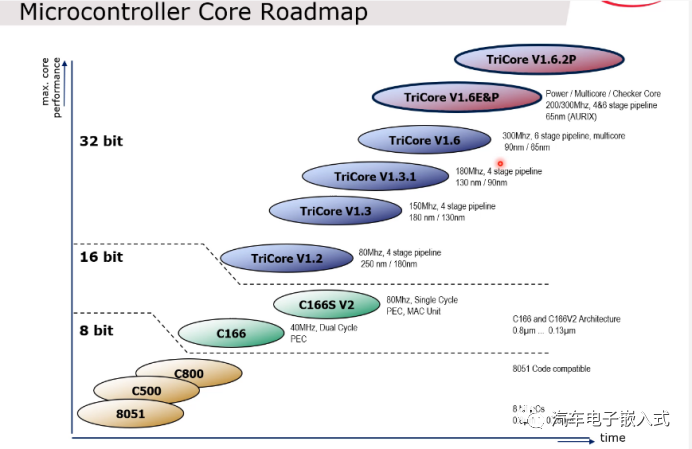
图13:英飞凌TriCore的发展图
4.2 Address range

图14:TriCore的寻址空间
4G的寻址空间,16个Segment,小端系统。
4.3 Pipeline
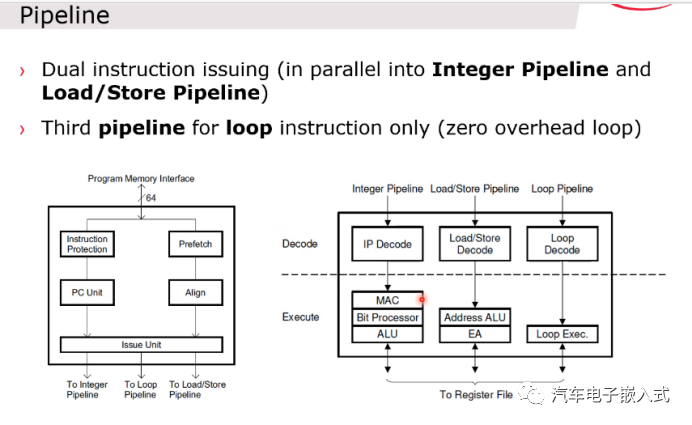
图15:Pipline
整型的Pipline主要组数据的运算,类似数据的加减乘除。Load/Store Pipline主要用来做数据的读取和存储,Loop Pipline主要做数据的循环处理。三个Pipline可以并行处理。
4.4 Instructions

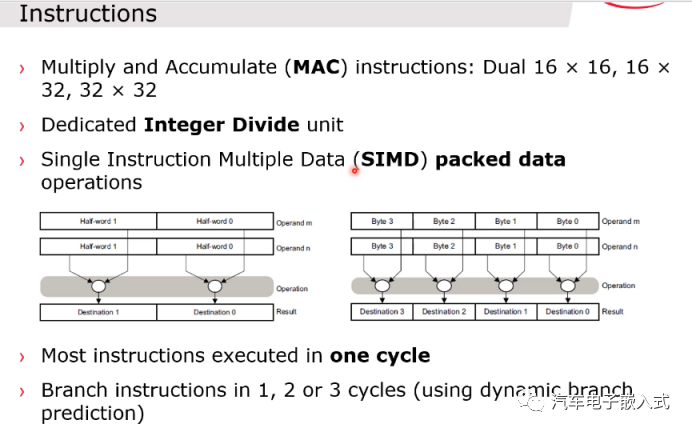
图16:指令
支持16位和32位指令格式,op1的bit 0为1则是32位指令,op1的bit 0为0则是16位指令。
支持位操作
支持MAC乘加指令,除法指令,单周期多数据处理指令SIMD。
4.5 Data Types

图17:支持的数据类型
支持大部分数据类型。
4.6 Addressing Modes
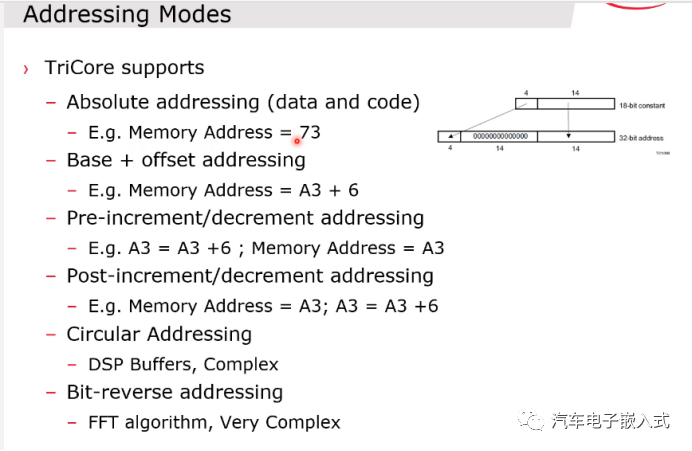
图18:寻址方式
支持绝对地址寻址,相对地址寻址,先加减后运算寻址,先运算后加减寻址。
4.7 Core Registers
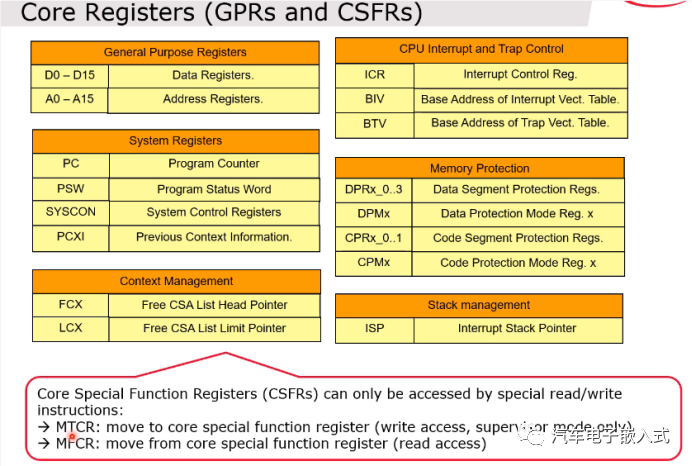
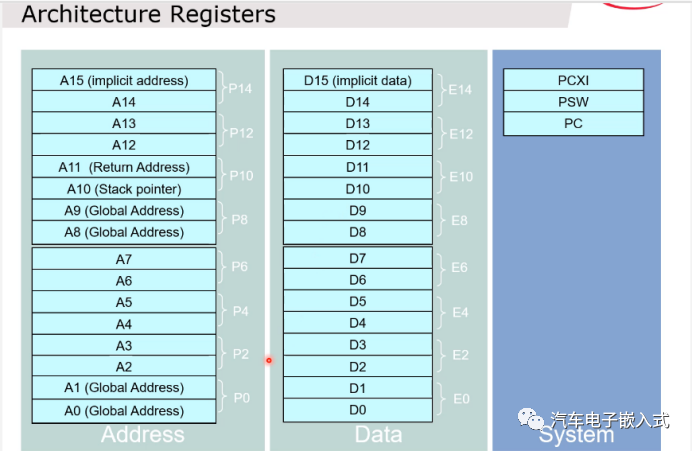
图19:核寄存器
通用寄存器:和ARM核(r0 - r15)不一样,数据寄存器和地址寄存器分开。数据运算和地址运算不冲突,这样可以提高寻址和数据处理的效率。
系统寄存器:PC指针,程序状态字寄存器,系统控制寄存器(比如设置系统在Run/Halt/Sleep状态)
上下文寄存器:
中断和陷阱控制寄存器:ICR寄存器可以控制全局中断的开关。BIV是中断向量表的起始地址,BTV是陷阱向量表的起始地址。
内存保护寄存器:
栈中断寄存器:通用寄存器里面的A10是user stack pointer,而ISP是interrupt stack pointer,通过PSW寄存器可以设置是否使用ISP,如果使用了ISP的话,通常情况下系统使用A10作为栈指针,一旦产生中断后系统把ISP指向的地址赋值给A10,也就是中断使用另一块内存作为栈空间。
访问核寄存器只能只用专用的MTCR,MFCR指令。
A11类似ARM核里面的LR寄存器。
所谓Global Address也就是进入中断或者进行函数调用的时候是不存这些内容的。
数据和地址寄存器可以两个合起来作为一个64位的寄存器(P0/D0)。
4.8 Context Management

图20:上下文管理
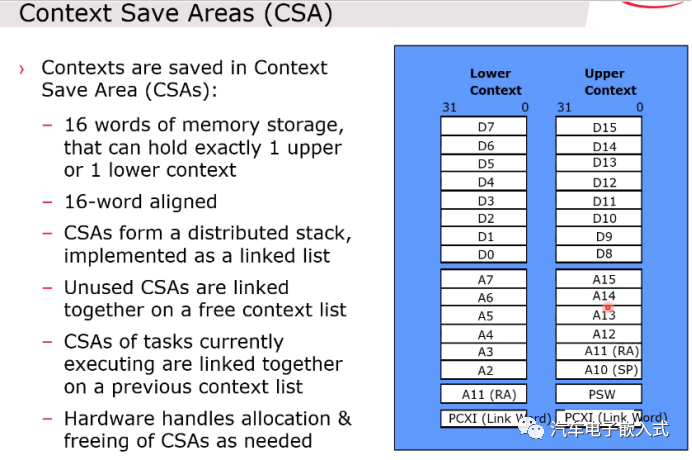
图21:上下文存储区域
TriCore的上下文处理比较特殊。对于通用MCU(ARM 核)在进入中断或者函数调用时候的上下文内容一般存放在栈里面的,但是TriCore的上下文存放在一个叫CSA的区域的。Upper Context 的内容由硬件自动处理,而Lower Context的内容需要一些特殊的指令操作。
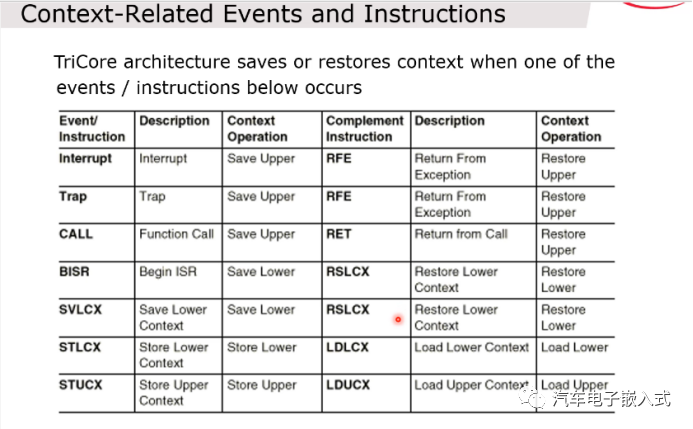
图21:上下文事件和指令
对于绝大部分简单的ISR, Trap, 函数调用都比较简单的话只要保存Upper context就足够了,也就不会产生后面的BISR,SVLCX,STLCX,STUCX指令。

图22:CSA存放地址
CSA可以存放在DSPR(一般存放在这里),DLMU,External Memory里面,通过修改连接ld文件来配置。
FCX: 指向空闲的CSA的起始地址。
PCX: 指向已经使用的CSA的地址。
LCX: 指向空闲CSA的结束地址。
4.8 Interrupt System
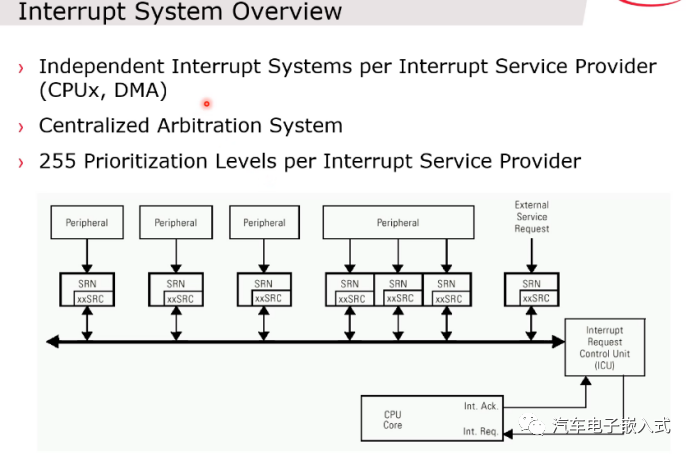

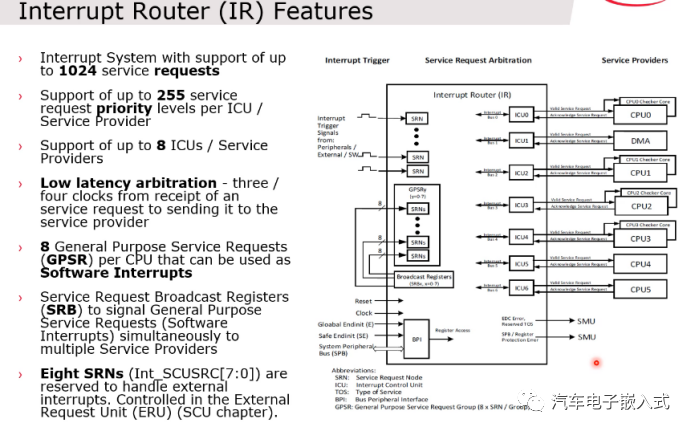
图23:中断系统
TriCore 1.6.2中最多有7个中断服务提供对象,分别是CPU0-5以及DMA。每一个Service Provider对应一个中断控制单元ICU,中断服务请求节点SRN最多有1024个,8个GPSR可以用作软中断做来核间通信。
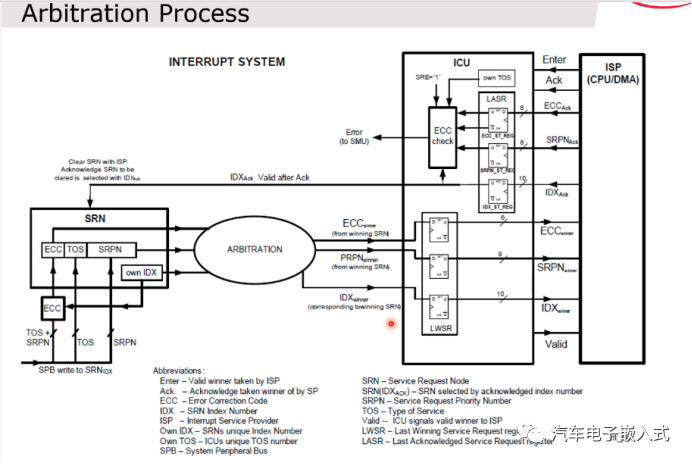
图24:中断仲裁
ICU能够仲裁处理多个SRN同时的请求。

图25:中断保护
中断寄存器也有保护机制,SRC有ECC的保护措施,在写完SRC寄存器后会自动生产一个ECC的Code,然后这个SRC的内容在被读取的时候就会做ECC的check。
SRC寄存器的权限也可以设置。比如,每个Bus Master总线都会有一个TAG-ID,我们可以设置SRC寄存器可以被哪些TAG-ID表示的总线访问。
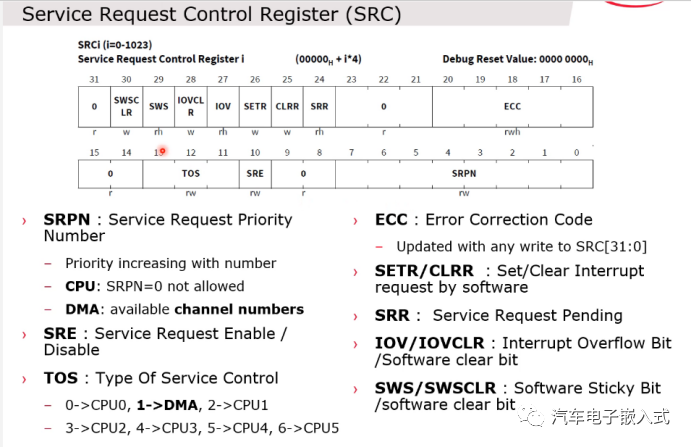
图26:服务请求控制寄存器SRC

图27:中断控制寄存器ICR和中断向量表地址寄存器BIV
VSS寄存器设置中断向量表是8字节对齐还是32字节对齐。
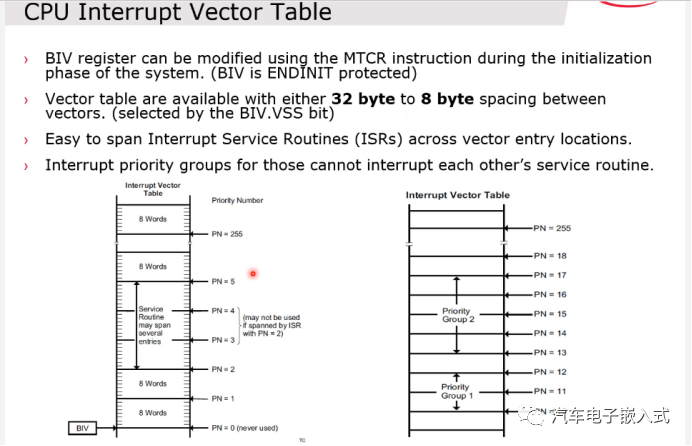
图28:中断向量表
在TricCore里面,中断向量表不是固定的,是跟着中断优先级走的,也就是整个中断向量表内中断服务的排序是会跟着中断优先级的变化而变化的(和其他内核不一样)。

图29:中断处理过程
4.9 DMA service requests
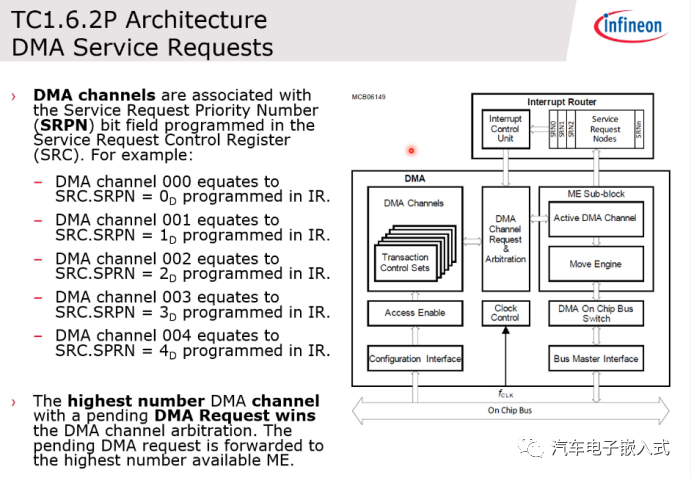
图30:DMA服务请求
SRN目标也可以选择DMA的,选择DMA的时候,TOS要设置成1。中断优先级要设置成和DMA的通道号一样,也就是中断优先级在选择DMA的时候就是DMA的通道号,这个很关键。
4.10 Traps

图31:Trap
Trap的概念就类似ARM里面的Exception vector异常向量。Trap也有自己的Trap向量表,Trap是为了检查一些非法的访问,例如NMI中断,内存保护。Trap有自己的类型TCN和ID TIN。

图32:Trap类型
Trap类型一般有两种划分方式,同步或者异步,硬件或者软件。
同步Trap:CPU在执行的过程中发生的Trap,比如说中断溢出,取值错误,内存非法访问等。Trap发生的时候,CPU会把Trap发生的指令的下一条指令作为返回地址保存到A11寄存器当中,所以在Trap的handler里面可以读取A11来定位Trap发生的位置。
异步Trap:和中断类似,一般由外设或一些协处理器的错误造成的。比如说FPU上发生的一些Trap。异步Trap发生的时候,A11中的内容不具备参考意义的。
硬件Trap:比如说CPU执行的指令是非法的,内存保护错误等。
软件Trap:软件调用了一些系统调用指令,比如assert。
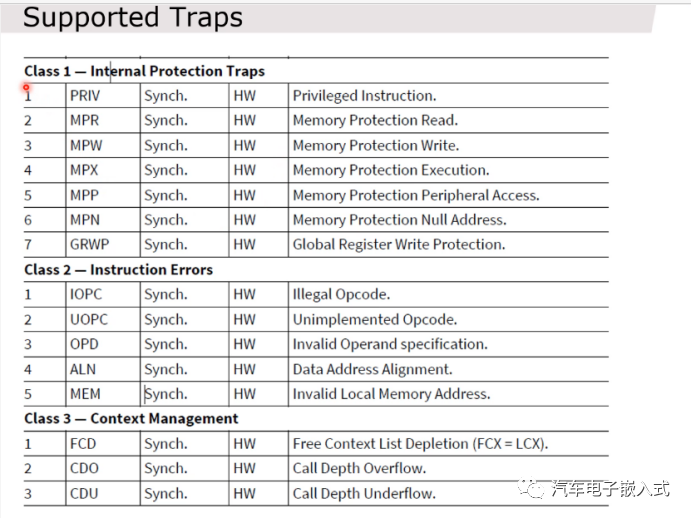
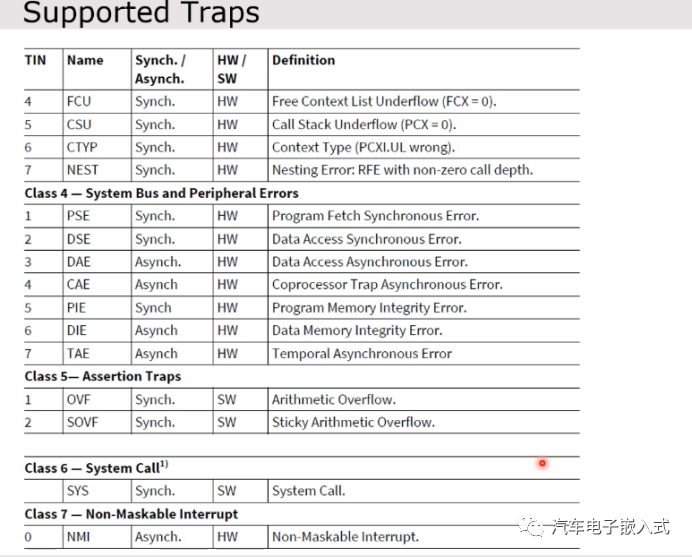
图33:具体的Trap
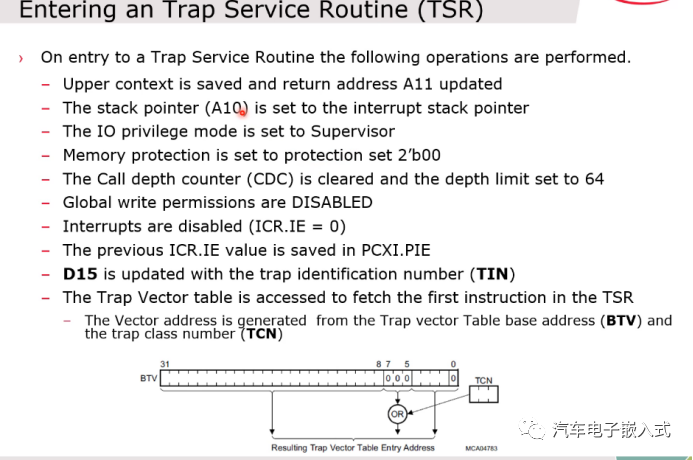
图34:Trap处理过程
关键点,D15保存了Trap的ID号,可以在handler中读取D15获取Trap ID。

图35:Trap保护机制
4.11 Permission Privilege Levels
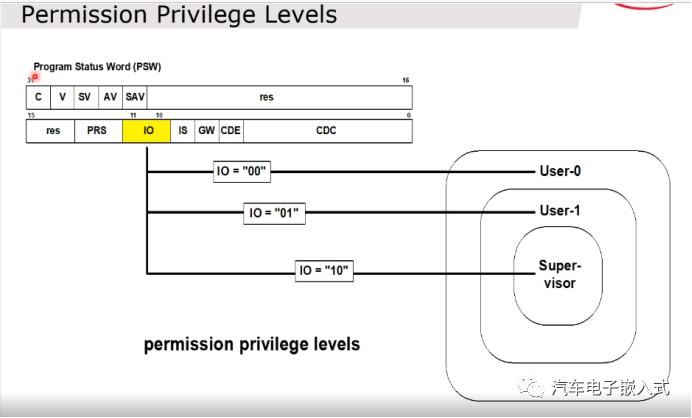
图36:权限设置
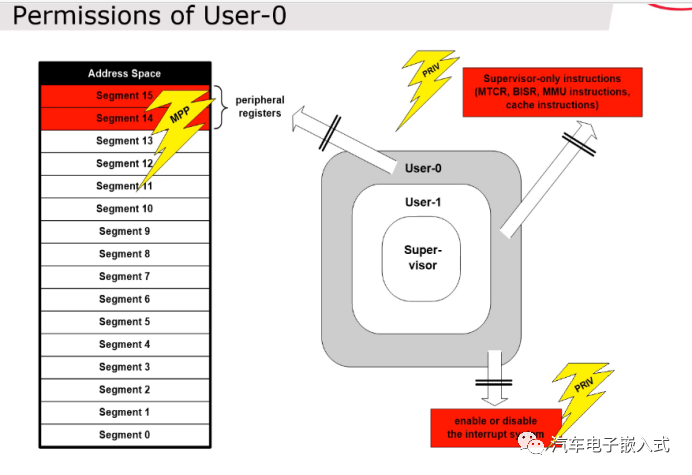
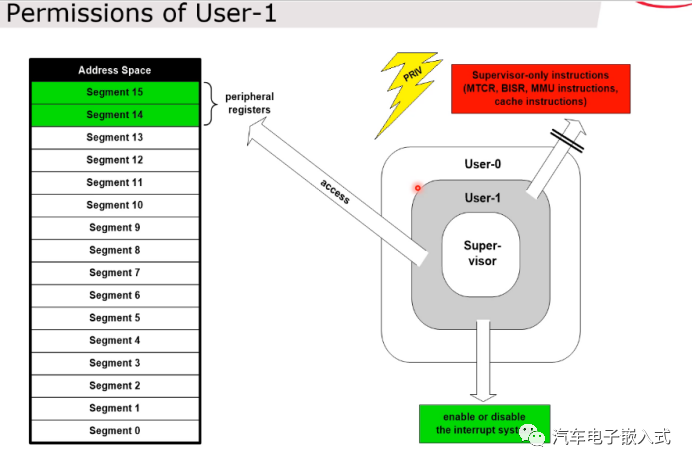
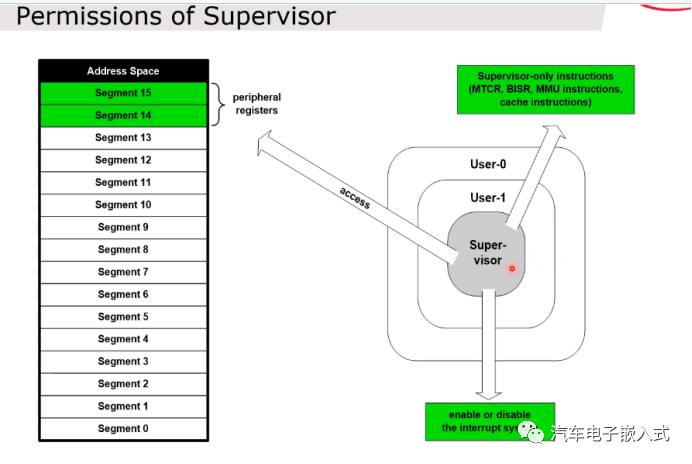
图37:不同模式下的访问权限
User0模式允许访问外设寄存器,不允许访问内核寄存器,也不允许访问中断系统寄存器。
User1模式可以访问中断系统寄存器。
Supervisor模式可以访问核寄存器。
4.12 Memory protection

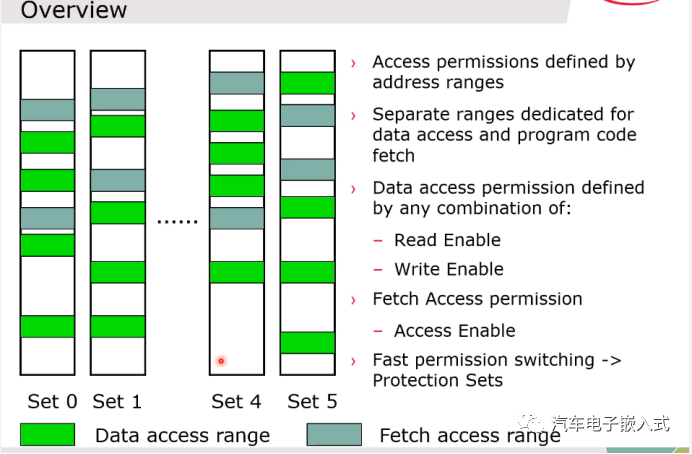
图38:内存保护
实际上就是6组MPU保护,6*18的数据保护,6*10的代码保护。
Bus MPU: 可以设置哪些Master Interface可以访问Local SRAM
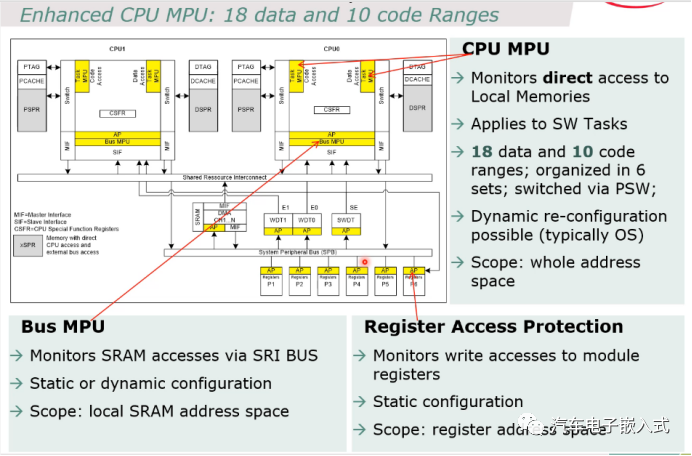
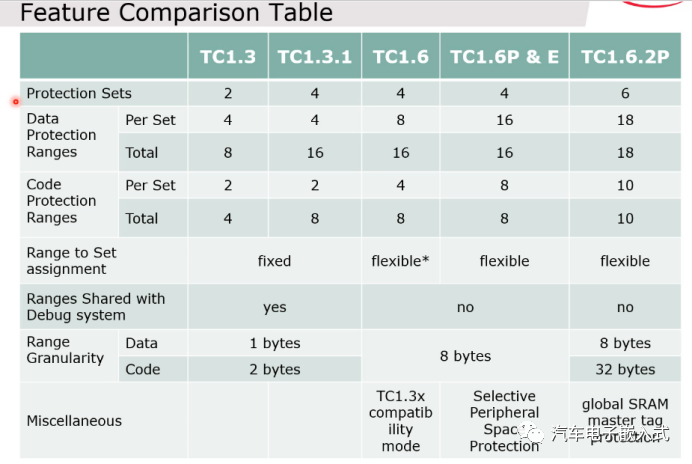
图38:增强的内存保护
4.13 Temporal Task Protection
实时操作系统对于内存访问错误可以通过MPU内存保护来识别和定位问题,但是对于任务超时该怎么来监控了?-- TriCore提供了时间任务保护机制来实现任务超时监控。



图39:时间任务保护
5.Summary


审核编辑:郭婷
-
英飞凌
+关注
关注
66文章
2188浏览量
138738 -
存储器
+关注
关注
38文章
7492浏览量
163845 -
总线
+关注
关注
10文章
2881浏览量
88094
原文标题:学习笔记 | Aurix TC3xx Architecture
文章出处:【微信号:汽车电子嵌入式,微信公众号:汽车电子嵌入式】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论