 摩尔线程多功能GPU产品迭代创新实现的又一次跨越
摩尔线程多功能GPU产品迭代创新实现的又一次跨越
摩尔线程 2022 秋季发布会于 2022 年 11 月 3 日在北京中关村国家自主创新示范区成功举办。发布会上,摩尔线程推出全新多功能 GPU 芯片“春晓”、基于 MUSA 架构打造的业内首款国潮显卡 MTT S80 和面向服务器应用的 MTT S3000,以及元计算一体机 MCCX。这是时隔 7 个月后,摩尔线程多功能 GPU 产品迭代创新实现的又一次跨越。
发布多功能 GPU 芯片“春晓”, AI 计算加速度比“苏堤”芯片提升 4 倍
此次发布会上,摩尔线程正式发布第二颗多功能 GPU 芯片“春晓”,集成 220 亿个晶体管,内置 MUSA 架构通用计算核心以及张量计算核心,可以支持 FP32、FP16 和 INT8 等计算精度。相较于之前发布的“苏堤”芯片,“春晓”内置的四大计算引擎全面升级,带来了显著的性能提升:图形渲染能力方面平均提升 3 倍;编码能力提升 4 倍,解码能力提升 2 倍;;AI 计算加速平均提升 4 倍,物理仿真计算性能提升 2.5 倍。同时,引入了新技术支持窄带高清,节约带宽 30% 以上。

全新发布的摩尔线程 MTT S80 基于“春晓”GPU 芯片打造,也是首款面向游戏玩家打造的国潮显卡。其拥有的 4096 个可编程 MUSA 核心,在 1.8GHz 的主频下,能够提供 14.4TFLOPS 的单精度浮点算力。同时 MTT S80 还是业内首款配备 PCIe Gen5 接口的显卡产品,配合 16GB GDDR6 大容量高速显存,再辅以 8K 超高清与 1080P 360Hz 高刷新率显示输出能力,能为游戏玩家带来极致游戏视觉和操作体验。
不只是硬件,摩尔线程还围绕 MUSA 发布了系列 GPU 软件栈与应用工具,包括 MUSA 开发者套件、云原生 sGPU 技术及元宇宙平台 MTVERSE 等,旨在构建从底层芯片到上层开发和应用的整体解决方案,实现摩尔线程多功能 GPU 软硬件一体化创新模式的全面升维。
其中,面向服务器的多功能 GPU 产品 MTT S3000 基于 MUSA 架构打造,能够支持 DirectX、OpenGL、OpenGL ES、Vulkan、OpenCL 等主流图形和计算接口,兼容 CUDA,可为 AI 推理和训练、云游戏、云渲染、视频云、数字孪生、数字内容创作等场景提供通用智能算力支持,旨在为数据中心、智算中心和元计算中心的建设构建坚实算力基础,助力元宇宙多元应用创新和落地。
算力升级,助力元计算加速
MTT S3000 搭载了摩尔线程全新的第二颗多功能 GPU 芯片“春晓”,包含了 4096 个 MUSA 流处理核心及 128 个专用张量计算核心,晶体管规模达到 220 亿,运行频率为 1.9GHz,显存位宽 256bit;搭配 32GB GDDR6 显存;支持 FP32、FP16、INT8 等多种计算精度,其中 FP32 算力可达 15.2TFLOPS。
MTT S3000 率先采用了 PCIe 5.0 接口,是目前 GPU 行业中首款支持 PCIe 5.0 标准的产品。PCIe 5.0 所提供的高带宽不仅能提升 GPU 与 CPU 的通讯效率,更能在“多卡”部署时提供更大的核间通讯带宽,提升 GPU 集群的整体运算效率和性能。
MTT S3000 内置 MUSA 智能多媒体引擎 2.0 和硬件虚拟化功能,能够从多个维度增强显卡的应用范围和用户的应用体验。同时,MTT S3000 还提供了两组 DP 1.4a 显示输出接口,由此增加的显示输出能力将进一步拓展 MTT S3000 的业务适应性。

训推一体,为 AI 计算铺平道路
从数据中心向智算中心和元计算中心演进是行业算力需求发展的主流趋势,人工智能和元宇宙应用负载对 GPU 算力的强烈需求是推动这一演进趋势的关键力量。专为提升智能算力而设计的摩尔线程 MTT S3000,在与之配套的 MUSA 软硬件计算平台的加持下,AI 应用性能相比 “苏堤”可实现平均 4 倍提升。
MTT S3000 及其配套软硬件产品,实现从算法模型到应用部署的全流程覆盖,能够为 AI 用户提供友好丰富的一揽子解决方案。在算法层面,摩尔线程不仅可以支持用户的自定义算法模型,同时也提供丰富的预训练模型库,赋能广大 AI 开发者,提升开发效率;在应用解决方案层面,摩尔线程可提供数字人、数字客服、内容生成等行业解决方案,服务金融保险、教育、医疗等相关的行业用户。
在深度学习训练方面,MTT S3000 兼具易用性、扩展性和兼容性等多维优势。基于 MUSA 软件栈,MTT S3000 可实现现有算法的全面支持;能够支持包含单机单卡、单机多卡、多机多卡在内的多种训练模式。不仅如此,MTT S3000 还兼容 PyTorch、TensorFlow、百度飞桨(PaddlePaddle)、计图(Jittor)等多种主流深度学习框架,并实现了对 Transformer、CNN、RNN 等数十类 AI 模型的优化。
在深度学习推理方面,MTT S3000 支持视觉、语音、自然语音理解及多模态等多个领域主流 AI 模型。摩尔线程还对 MUSA 软件栈持续进行深度性能优化,并推出自研 AI 推理引擎 TensorX,利用任务并发、自适应算法寻优、访存优化、算子优化等技术,大幅提升推理性能。MTT S3000 可满足生物医疗、金融保险等特别强调高精度推理的行业需求,并提供极致性能。
同时,借助摩尔线程开发的 CUDA ON MUSA 兼容方案,用户可以将 CUDA 上开发的代码无缝迁移到 MTT S3000。 MUSA 不只是架构,而是一个生态
GPU 是一项系统性工程,涉及硬件架构、驱动开发、软件生态、销售应用等,研发壁垒高,产业链长。当前的 GPU 生态,历经几十年的更迭,变得庞大且复杂。一颗 GPU 要完成从研发到市场的商业化应用,既离不开软硬件方面的持续投入,也离不开生态的有力支持。
今年 3 月,摩尔线程正式发布第一颗多功能 GPU 芯片“苏堤”,目前已获得众多市场和生态的认可。基于“苏堤”芯片,摩尔线程联合 OEM 合作伙伴成功推出了多款个人电脑、工作站和数据中心服务器产品,应用在日常办公、数字孪生、人工智能训练和推理等业务场景;同时,携手云服务厂商为不同行业用户提供 GPU 云计算能力,为摩尔线程 GPU 在众多行业的应用落地铺平了道路。
摩尔线程创始人兼 CEO 张建中在现场表达了对所有合作伙伴和用户的感谢,并进一步表示:“GPU 创业是一个长期事业,充满了挑战,我们深知生态的重要性。摩尔线程多功能 GPU 基于先进 MUSA 架构,持续构建完备的软件栈及应用生态,旨在为开放生态系统创造友好的支持和体验。我们只有与生态伙伴、行业用户凝聚在一起,才能将摩尔线程的算力真正发挥出来,为元宇宙和数字经济提供核心动力。”
审核编辑 :李倩
-
gpu
+关注
关注
28文章
4753浏览量
129067 -
架构
+关注
关注
1文章
516浏览量
25497
原文标题:国产GPU再进一步!
文章出处:【微信号:技术大院,微信公众号:技术大院】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
国产GPU独角兽摩尔线程启动上市辅导
摩尔线程GPU与超图软件大模型适配:共筑国产地理空间AI新生态
摩尔线程与超图软件完成产品兼容认证
摩尔线程夸娥智算中心解决方案重磅升级
摩尔线程正式开源音频理解大模型MooER
摩尔线程和乐创能源签署战略合作协议
摩尔线程全功能GPU加速三维GIS全国产解决方案
摩尔线程与智谱AI完成大模型性能测试与适配
国产GPU可替代!摩尔线程千卡集群点亮新成就
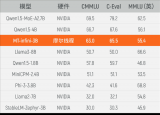
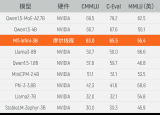
摩尔线程与无问芯穹在国产GPU上首次实现大模型实训
摩尔线程与无问芯穹宣布完成基于GPU千卡集群的3B规模大模型实训





 工商网监
工商网监
评论