 探究字符串模式匹配的高级数据结构和算法
探究字符串模式匹配的高级数据结构和算法
导读
本文介绍了几个常见的匹配算法,通过算法过程和算法分析介绍了各个算法的优缺点和使用场景,并为后续的搜索文章做个铺垫;读者可以通过比较几种算法的差异,进一步了解匹配算法演进过程以及解决问题的场景;KMP算法和Double-Array TireTree是其中算法思想的集大成者,希望读者重点关注。
01
前言
上文探究了数据结构和算法的一些基础和部分线性数据结构和部分简单非线性数据结构,本文我们来一起探究图论,以及一些字符串模式匹配的高级数据结构和算法。《搜索中常见数据结构与算法探究(一)》
搜索作为企业级系统的重要组成部分,越来越发挥着重要的作用,ES已经成为每个互联网企业必备的工具集。而作为搜索的基础部分,文本匹配的重要性不言而喻。文本匹配不仅为精确搜索提供了方法,而且为模糊匹配提供了算法依据。比如相似度算法,最大搜索长度算法都是在匹配算法的基础上进行了变种和改良。
02 图论基础
2.1 图的基本概念
一个图G(V,E)由顶点的集V和边的集E组成。每一条边就是一副点对(v,w),其中v,w∈V。如果点对是有序的,那么图就是有向图。有时候还有第三种成分,称作权。
以物流的抽象模型为例:每个配送中心是一个顶点,由两个顶点表示的配送中心间如果存在一条干线运输线,那么这两个顶点就用一条边连接。边可以由一个权,表示时间、距离和运输的成本。可以迅速确定任何两个配送中心的最佳线路。这里的“最佳”可以是指最少边数的路径,也即经过的配送中心最少;也可以是对一种或所有权总量度所算出的最佳者。
2.2 图的表示方法
考虑实用情况,以有向图为例:
假设可以以省会城市开始对顶点编号。如下图
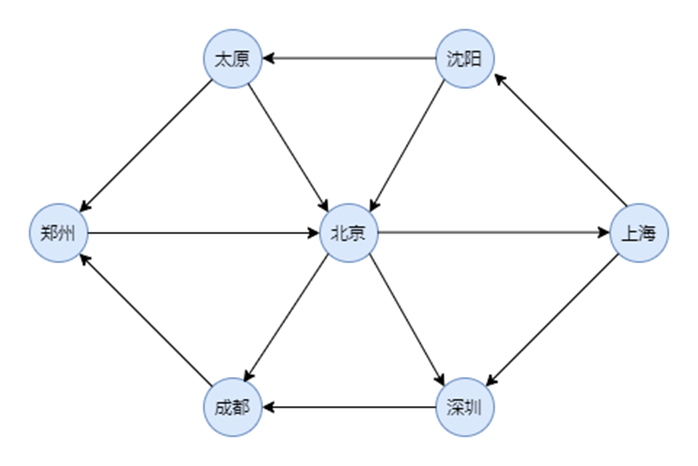
图1有向图图示
1.邻接矩阵
表示图的一种简单的方法是使用一个二维数据,称为邻接矩阵表示法。有一个二维数组A,对于每条边(u,v),置A[u][v]等于true;否则数组元素就是false。
如果边有一个权,那么可以置A[u][v]等于该权,而使用很大或者很小的权作为标记表示不存在的边。虽然这种表示方法的优点是简单,但是,它的空间复杂度为θ(|V|^2),如果图的边不是很多(稀疏的),那么这种表示的代价就太大了。代码如下:
/** ** Description: 使用邻接矩阵的图表示法 *
* Company: 京东 * * @author pankun8 * @date 2021/11/11 15:41 */ @Data @NoArgsConstructor public class Graph
{ /** * 图的节点数 */ privateintn; /** * 图 */ privateT[]data; /** * 是否是有向图 */ privateBooleandirected; /** * 邻接矩阵 */ private int[][] matrix; public Graph(T[] data , Boolean directed){ this.n = data.length; this.data = data; this.directed = directed; matrix = new int[n][n]; } public void init(T[] data , Boolean directed){ this.n = data.length; this.data = data; this.directed = directed; matrix = new int[n][n]; } /** * * @param v 起点 * @param w 终点 * @param value 权重 */ public void addEdge(int v , int w , int value){ if((v >=0 && v < n) && (w >= 0 && w < n)){ if(hasEdge(v,w) == value){ return; } matrix[v][w] = value; if(!this.directed){ matrix[w][v] = value; } n ++; } } //判断两个节点中是否以及存在边 public int hasEdge(int v, int w){ if((v >=0 && v < n) && (w >= 0 && w < n)){ return matrix[v][w]; } return 0; } /** * 状态转移函数 * @param index * @param value * @return */ public int stateTransfer(int index , int value){ int[] matrix = this.matrix[index]; for (int i = 0; i < matrix.length; i++) { if(matrix[i] == value){ return i; } } return Integer.MAX_VALUE;
2.邻接表
如果图是稀疏的,那么更好的解决办法是使用邻接表。
2.3图的搜索算法
从图的某个订单出发,访问途中的所有顶点,并且一个顶点只能被访问一次。图的搜索(遍历)算法常见的有两种,如下:
深度优先搜索算法(DFS)
广度优先搜索算法(BFS)
03
数据结构与算法
3.1 BF(Brute Force)算法
3.1.1 算法介绍
BF(Brute Force)算法也可以叫暴力匹配算法或者朴素匹配算法。
3.1.2 算法过程
在讲解算法之前,先定义两个概念,方便后面讲解。他们分别是主串(S)和模式串(P)。比如说要在字符串A中查找字符串B,那么A就是主串,B就是模式串。把主串的长度记作n,模式串的长度记作m,并且n>m。算法过程如下图:
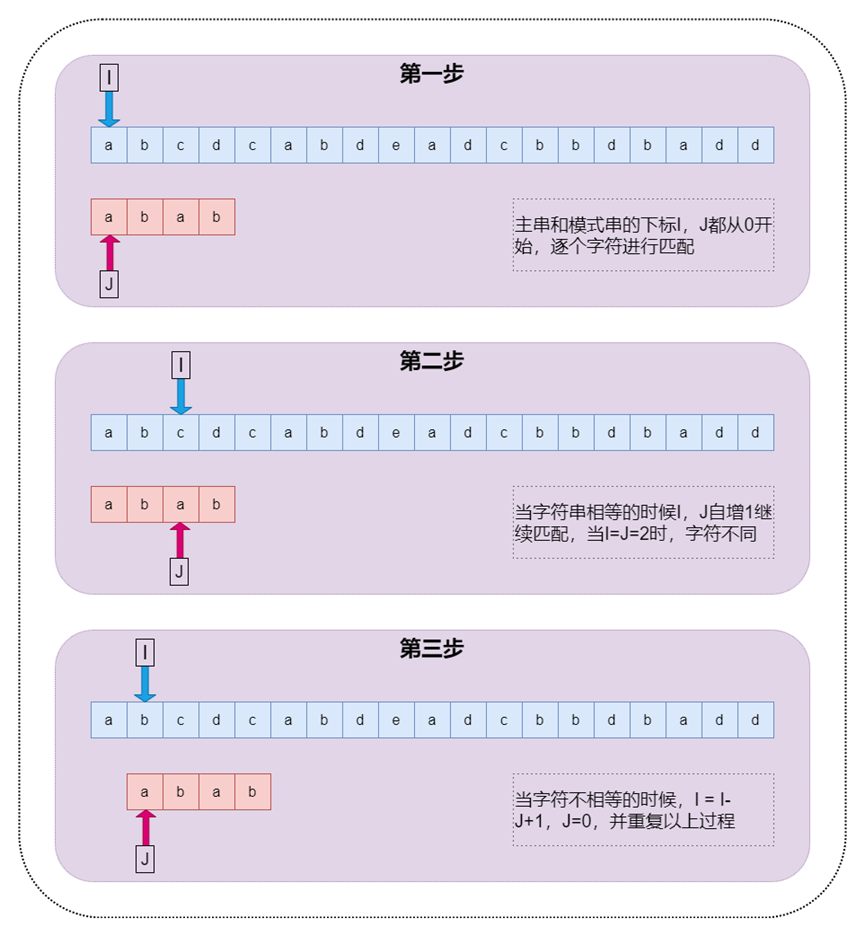
图2 BF算法过程图示
3.1.3 算法分析
BF算法过程很“暴力”,当然也就比较简单,好懂,但是响应的性能也不高极端情况下时间复杂度函数为O(m*n)。
尽管理论上BF算法的时间复杂度很高,但在实际的开发中,它却是一个比较常用的字符串匹配算法,主要原因有以下两点:
朴素字符串匹配算法思想简单,代码实现也非常简单,不容易出错,容易调试和修改。
在实际的软件开发中,模式串和主串的长度都不会太长,大部分情况下,算法执行的效率都不会太低。
3.2 RK(Rabin-Karp)算法
3.2.1算法介绍
RK算法全程叫Rabin-Karp算法,是有它的两位发明者Rabin和Karp的名字来命名,这个算法理解并不难,它其实是BF算法的升级版。
3.2.2 算法过程
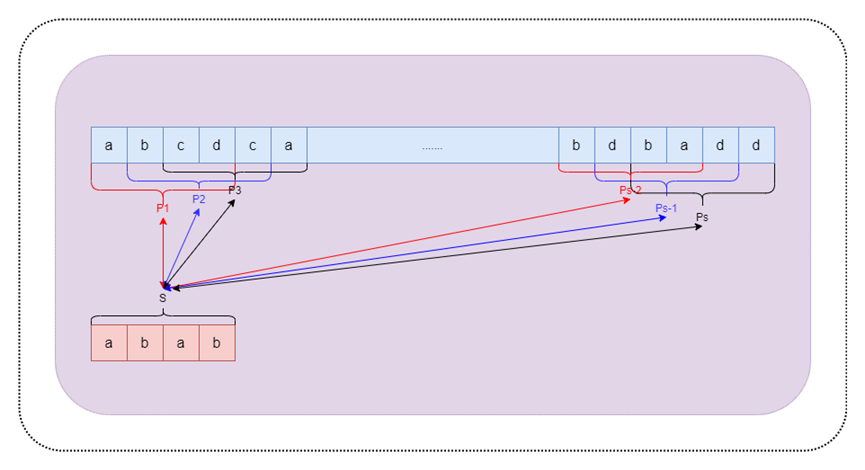
图3 RK算法过程图示
3.2.3算法分析
在BF算法中当字符串不匹配时,需要比对每一个字符,如果不能匹配则重新调整I,J的值重新比对每一个字符,RK的思路是将模式串进行哈希算法得到s=hash(P),然后将主串分割成n-m+1个子串,分别对其进行hash算法,然后逐个和s进行比对,减少逐个字符串比对的次数。其中hash函数的具体实现可自行选择。
整个RK算法包含两部分:
计算模式串哈希和子串的哈希;
模式串哈希和子串哈希的比较;
第一部分的只需要扫描一遍主串就能计算出所有子串的哈希值,这部分的时间复杂度是O(n)。模式串哈希值与每个子串哈希之间的比较的时间复杂度是O(1),总共需要比对n-m+1次,所以这部分的时间复杂度为O(n)。所以RK算法的整体时间复杂度为O(n)。
3.3KMP算法
3.3.1算法介绍
KMP算法是一种线性时间复杂度的字符串匹配算法,它是对BF(Brute-Force)算法的改进。KMP算法是由D.E.Knuth与V.R.Partt和J.H.Morris一起发现的,因此人们称它为Knuth-Morris-Pratt算法,简称KMP算法。
前面介绍了BF算法,缺点就是时间消耗很大,KMP算法的主要思想就是:在匹配过程中发生匹配失败时,并不是简单的将模式串P的下标J重新置为0,而是根据一些匹配过程中得到的信息跳过不必要的匹配,从而达到一个较高的匹配效率。
3.3.2算法过程
在介绍KMP算法之前,首先介绍几个字符串的概念:
前缀:不包含最后一个字符的所有以第一个字符开头的连续子串;
后缀:不包含第一个字符的所有以最后一个字符结尾的连续子串;
最大公共前后缀:前缀集合与后缀集合中长度最大的子串;
例如字符串abcabc
前缀集合是a,ab,abc,abca,abcab
后缀集合为bcabc,cabc,abc,bc,c
最大公共前后缀为abc
KMP算法的过程如下图:
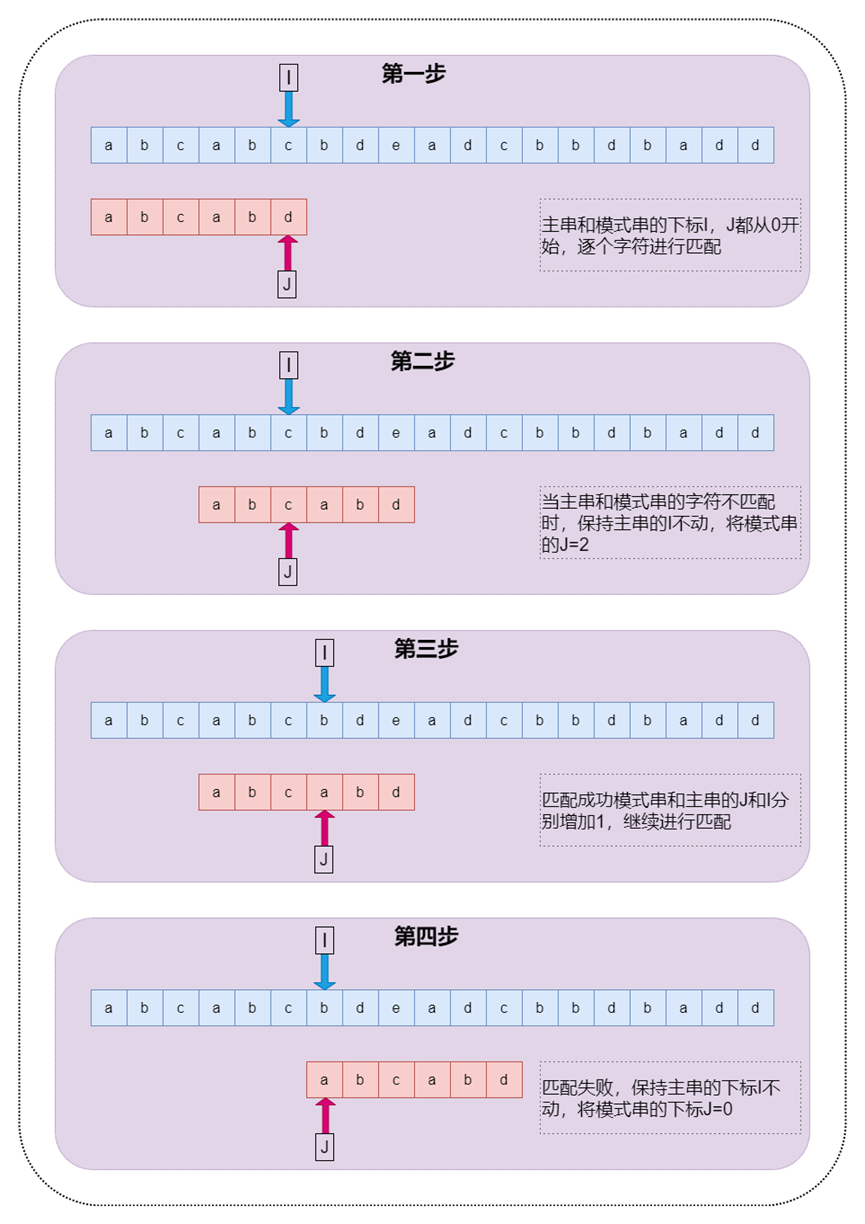
图4 KMP算法过程图示
那么为什么KMP算法会知道在匹配失败时下标J回溯到那个位置呢?其实KMP算法在匹配的过程中将维护一些信息来帮助跳过不必要的匹配,这个信息就是KMP算法的重点,next数组也叫做fail数据或者前缀数据。下面来分析next数组的由来:
对于模式串P的每个元素P[j],都存在一个实数k,使得模式串P开头的k个字符(P[0]P[1]...P[k-1])依次于P[j]前面的k(P[j-k]P[j-k+1]...P[j-1])个字符相同。如果这样的k有多个,则取最大的一个。模式串P中的每个位置j的字符都存在这样的信息,采用next数组表示,即next[j]=MAX{k}。
从上述定义中可看到next(j)的逻辑意义就是求P[0]P[1]...P[j-1]的最大公共前后缀长度。代码如下:
public static void genNext(Integer[] next , String p){
int j = 0 , k = -1;
char[] chars = p.toCharArray();
next[0] = -1;
while(j < p.length() - 1){
if(k == -1 || chars[j] == chars[k]){
j++;k++;
next[j] = k;
}else{
k = next[k];//此处为理解难点
}
}
}
下面分析next的求解过程:
1. 特殊情况
当j的值为0或者1的时候,它们的k值都为0,即next(0) = 0 、next(1)= 0。为了后面k值计算的方便,我们将next(0)的值设置为-1。
2. 当P[j]==P[k]的情况
当P[j]==P[k]时,必然有P[0]...P[k-1]==P[j-k]...P[j-1],因此有P[0]...P[k]==P[j-k]...P[j],这样就有next(j+1)=k+1。
3. 当P[j]!=P[k]的情况
当P[j]!=P[k]时,必然会有next(j)=k,并且next(j+1)
4. 算法优化
上述算法有一个小问题就是当P[k]匹配失败后会跳转到next(k)继续进行匹配,但是此时有可能P[k]=P[next(k)],此时匹配肯定是失败的所以对上述代码进行改进如下:
public void genNext(Integer[] next , String p){
int j = 0 , k = -1;
char[] chars = p.toCharArray();
next[0] = -1;
while(j < p.length() - 1){
if(k == -1 || chars[j] == chars[k]){
j++;k++;
if(chars[j] == chars[k]){
next[j] = next[k];//如果两个相等
}else{
next[j] = k;
}
}else{
k = next[k];
}
}
}
3.3.3算法分析
KMP算法通过消除主串指针的回溯提高匹配的效率,整个算法分为两部分,next数据的求解,以及字符串匹配,从上一节的分析可知求解next数组的时间复杂度为O(m),匹配算法的时间复杂度为O(n),整体的时间复杂度为O(m+n)。KMP算法不是最快匹配算法,却是名气最大的,使用的范围也非常广。
3.4BM算法
3.4.1算法介绍
Boyer-Moore字符串搜索算法是一种非常高效的字符串搜索算法。它由BobBoyer和J Strother Moore发明,有实验统计它的性能是KMP算法的3-4倍。
3.4.2算法过程
前面介绍的BF,KMP的算法的匹配过程虽然模式串的回溯过程不同,但是相同点都是从左往右逐个字符进行匹配,而BM算法则是采用的从右向左进行匹配,借助坏字符规则(SKip(j))和好后缀规则(Shift(j)),能够进行快速匹配。其中坏字符和好后缀示意如下图
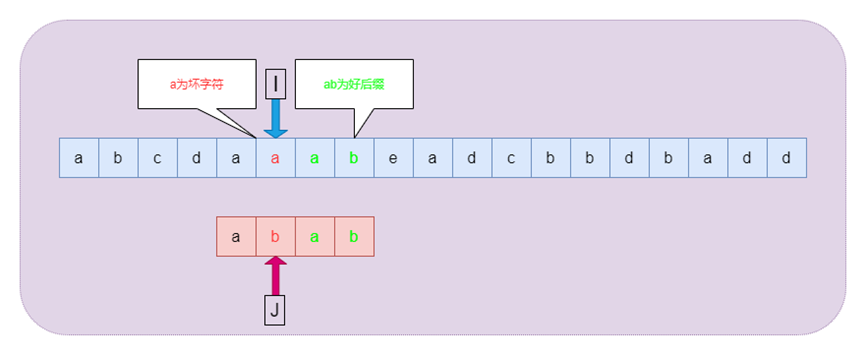
图5坏字符和好后缀图示
1. 坏字符规则:在BM算法从右向左扫描的过程中,若发现某个字符S[i]不匹配时,则按照如下两种情况进行处理:
如果字符S[i]在模式串P中没有出现,那么从字符S[i]开始的m个文本显然是不可能和P匹配成功,直接全部跳过该区域。
如果字符S[i]在模式串P中出现,则以该字符进行对齐。
2. 好后缀规则:在BM算法中,若发现某个字符不匹配的同时,已有部分字符匹配成功,则按照如下两种情况进行处理:
如果已经匹配的子串在模式串P中出现过,且子串的前一个字符和P[j]不相同,则将模式串移动到首次出现子串的前一个位置。
如果已经匹配的子串在模式串P中没有出现过,则找到已经匹配的子串最大前缀,并移动模式串P到最大前缀的前一个字符。
BM算法过程如下:
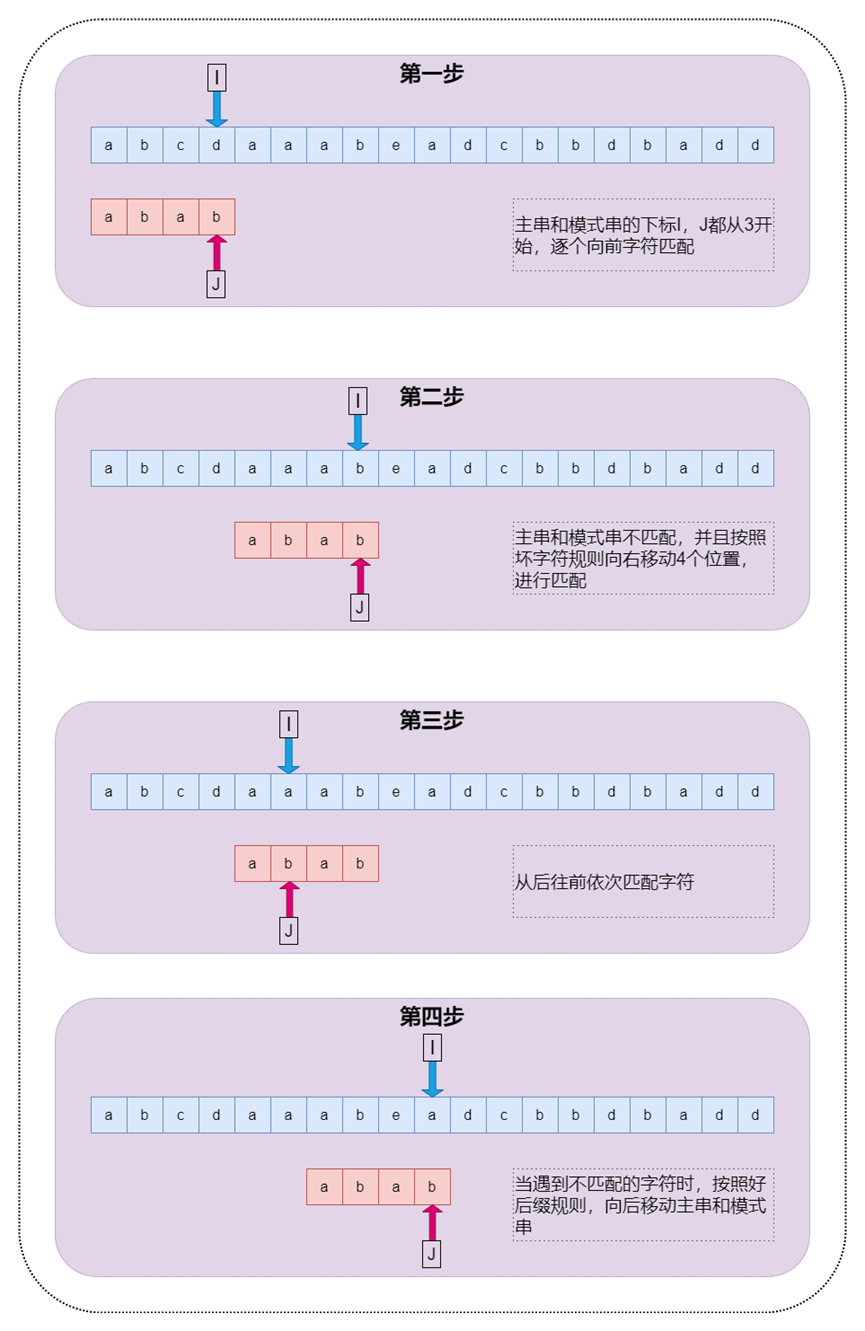
图6BM算法过程图示
3.4.3算法分析
在BM算法中,如果匹配失败则取SKip(j)与Shift(j)中的较大者作为跳跃的距离。BM算法预处理阶段的复杂度为O(m+n),搜索阶段的最好的时间复杂度为O(n/m),最坏的时间复杂度为O(n*m)。由于BM算法采用的是后缀匹配算法,并且通过坏字符和好后缀共同作用下,可以跳过不必要的一些字符,具体Shift(j)的求解过程可参看KMP算法的next()函数过程。
3.5TireTree
3.5.1算法介绍
在搜索中常见数据结构与算法探究(一)中,介绍过一种树状的数据结构叫做HashTree,本章介绍的TireTree就是HashTree的一个变种。TireTree又叫做字典树或者前缀树,典型的应用是用于统计和排序大量的字符串,所以经常被搜索系统用于文本的统计或搜索。
TireTree的核心思想是空间换时间。TrieTree是一种高效的索引方法,它实际上是一种确定有限自动机(DFA),利用字符串的公共前缀来降低查询时间的开销以达到提高查询效率的目的,非常适合多模式匹配。TireTree有以下基本性质:
根节点不包含字符,除根节点外每个节点都包含一个字符。
从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点对应的所有子节点包含的字符都不相同。
3.5.2算法过程
TireTree构建与查询
我们以《搜索中常见的数据结构与算法探究(一)》案例二中提到的字谜单词为例,共包含this、two、fat和that四个单词,我们来探究一下TireTree的构建过程如下图:
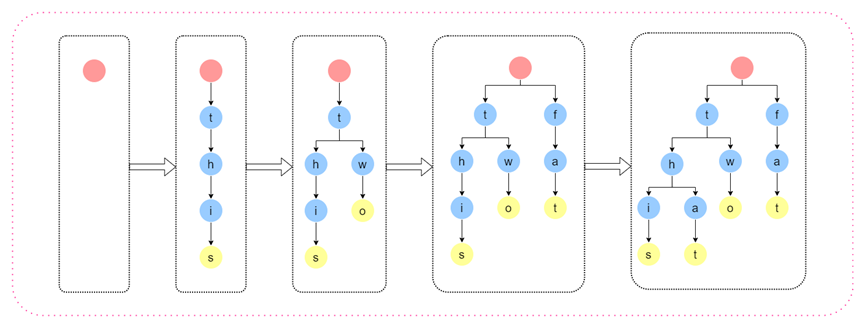
图7 TireTree算法过程图示
上述过程描述了that,two,fat,that四个单词的插入TireTree的过程,其中黄色的节点代表有单词存在。由于TireTree的构建的过程是树的遍历,所以查询过程和创建过程可以视为一个过程。
3.5.3算法分析
TireTree由于本身的特性非常适合前缀查找和普通查找,并且查询的时间复杂度为O(log(n)),和hash比较在一些场景下性能要优于甚至取代hash,例如说前缀查询(hash不支持前缀查询)。
虽然TireTree的查询速度会有一定的提升但是却不支持后缀查询,并且TireTree对空间利用率不高,且对中文的支持有限。
3.6 AC自动机
3.6.1算法介绍
AC自动机(Aho-Corasick automation)该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。要搞懂AC自动机,先得有TireTree和KMP模式匹配算法的基础知识,上述章节有TireTree和KMP算法的详细介绍。
3.6.2算法过程
AC自动机的构建过程需要如下步骤:
1. TireTree的构建,请参看TireTree章节
2. fail指针的构建
使当前字符失配时跳转到具有最长公共前后缀的字符继续匹配。如同 KMP算法一样, AC自动机在匹配时如果当前字符匹配失败,那么利用fail指针进行跳转。由此可知如果跳转,跳转后的串的前缀,必为跳转前的模式串的后缀并且跳转的新位置的深度一定小于跳之前的节点。fail指针的求解过程可是完全参照KMP算法的next指针求解过程,此处不再赘述。
3. AC自动机查找
查找过程和TireTree相同,只是在查找失败的时候感觉fail指针跳转到指定的位置继续进行匹配。
3.6.3算法分析
AC自动机利用fail指针阻止了模式串匹配阶段的回溯,将时间复杂度优化到了O(n)。
3.7Double-Array-TireTree
3.7.1算法介绍
前面提到过TireTree虽然很完美,但是空间利用率很低,虽然可以通过动态分配数组来解决这个问题。为了解决这个问题引入Double-Array-TireTree,顾名思义Double-Array-TireTree就是TireTree压缩到两个一维数组BASE和CHECK来表示整个树。Double-Array-TireTree拥有TireTree的所有优点,而且克服了TireTree浪费空间的不足,使其应用范围更加广泛,例如词法分析器,图书搜索,拼写检查,常用单词过滤器,自然语言处理中的字典构建等等。
3.7.2算法过程
在介绍算法之前,提前简单介绍一个概念DFA(下一篇详细介绍)。DFA(DeterministicFinite State)有限自动机,通俗来讲DFA是指给定一个状态和一个输入变量,它能转到的下一个状态也就确定下来,同时状态是有限的。
Double-Array-TireTree构建
Double-Array-TireTree终究是一个树结构,树结构的两个重要的要素便是前驱和后继,把树压缩在双数组中,只需要保持能查到每个节点的前驱和后继。首先要介绍几个重要的概念:
STATE:状态,实际是在数组中的下标
CODE:状态转移值,实际为转移字符的值
BASE:标识后继节点的基地址数组
CHECK:标识前驱节点的地址
从上面的概念的可以理解如下规则,假设一个输入的字符为c,状态从s转移到t
state[t] = base[state[s]] + code[c]
check[state[t]] = state[s]
构建的过程大概也分为两种:
动态输入词语,动态构建双数组
已知所有词语,静态构建双数组
以静态构建过为核心,以《搜索中常见的数据结构与算法探究(一)》案例二中提到的字谜单词为例,共包含this、two、fat和that四个单词为例,其中涉及到的字符集{a,f,h,i,o,s,t,w}共8个字符,为了后续描述方便,对这个八个字符进行编码,分别是a-1,f-2,h-3,i-4,o-5,s-6,t-7,w-8
构建this,如下图

图8 构建This图示
构建two,如下图
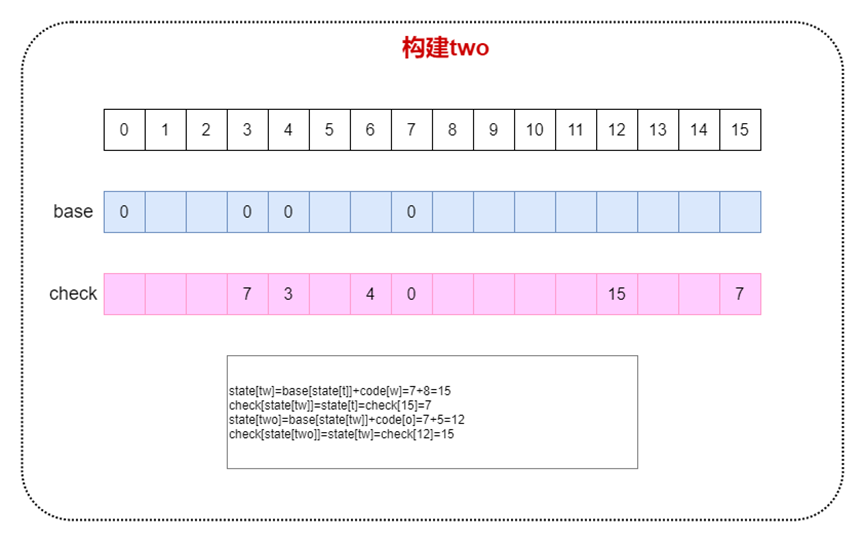
图9构建two图示
构建fat,如下图

图10构建fat图示
构建that,如下图

图11 构建that图示
Double-Array-TireTree查询
验证this是否在范围内如下过程
1. state[t]= base[state[null]]+code[t]= 0 + 7=7
check[7]=state[null]=0 通过
2. state[th]= base[state[t]]+code[h]=base[7]+3 =2+3=5
check[5]= state[t] = 7 通过
3. state[tha]= base[state[th]]+ code[a]=base[5]+1=5+1=6
check[6]=state[th]=5 通过
4. state[that]= base[state[tha]]+t = base[6]+7=11
check[11]=state[tha]=6 通过
3.7.3算法分析
通过两个数据base和check将TireTree的数据压缩到两个数组中,既保留了TireTree的搜索的高效,又充分利用了存储空间。
3.8其他数据结构
鉴于篇幅有限,DFA,FSA以及FST将在下一篇文章中再来一起讨论,敬请期待!
04
总结
本篇文章对本系列的上一篇文章的常见数据结构做了补充,介绍了非线性数据结构的最后一种,图数据结构作为基本数据结构最复杂的一种,在多种企业级应用中都有使用,如网络拓扑,流程引擎,流程编排;另外本文重点介绍了几种常见的匹配算法,以及算法的演进过程和使用场景,为下一篇的主题,也是本系列的重点探究的目标,“搜索”做一个铺垫,敬请期待!
审核编辑:刘清
-
字符串
+关注
关注
1文章
586浏览量
20664 -
DFS
+关注
关注
0文章
26浏览量
9218 -
BFS
+关注
关注
0文章
9浏览量
2197
原文标题:搜索中常见数据结构与算法探究(二)
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
改进的AC-BM字符串匹配算法
基于字符串匹配算法的蒙古文搜索
学习Tcl来这里:字符串匹配
什么是复制字符串?Python如何复制字符串
数据结构字典树的实现
strtok拆分字符串






 工商网监
工商网监
评论