 空间稀疏推理(SSI)加速深度生成模型
空间稀疏推理(SSI)加速深度生成模型
1. 个人理解
生成模型近年来发展迅猛,已经表现出极强的真实感合成能力,在三维重建、AI绘画、音视频创作、可控图像生成、真实图像编辑等领域的应用广泛。例如,即便没有绘画基础,大家也可以很容易利用生成模型绘制大师级画作。但近年来SOTA生成模型的主要问题是需要大量的计算资源,这一方面是由于深度网络的框架较为复杂,另一方面是因为每次针对图像可能只是做了很小的改动,但生成模型仍然需要重新计算整张图像。
在2022 NeurIPS论文“Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models”中,CMU、MIT、斯坦福联合提出了空间稀疏推理(SSI),它可以利用编辑区域的空间稀疏性来加速深度生成模型,并且可以应用于各种生成模型!在Apple M1 Pro CPU上的推理速度加快了14倍!
2. 摘要
在图像编辑期间,现有的深度生成模型倾向于从头开始重新合成整个输出,包括未编辑的区域。这导致了计算的显著浪费,尤其是对于较小的编辑操作。在这项工作中,我们提出了空间稀疏推理(SSI),这是一种通用技术,它选择性地对编辑区域执行计算,并加速各种生成模型,包括条件GAN和扩散模型。
我们的主要观察是,用户倾向于对输入图像进行渐进的改变。这促使我们缓存和重用原始图像的特征图。给定一个编辑过的图像,我们稀疏地将卷积滤波器应用于编辑过的区域,同时为未编辑的区域重用缓存的特征。
基于我们的算法,我们进一步提出稀疏增量生成引擎(SIGE)来将计算减少转换为现成硬件上的延迟减少。通过1.2%的面积编辑区域,我们的方法减少了7.5倍的DDIM和18倍的GauGAN的计算,同时保持视觉保真度。通过SIGE,我们加速了3.0倍在RTX 3090上的DDIM和6.6倍在苹果M1 Pro CPU上的推理时间,以及4.2倍在RTX 3090上的GauGAN和14倍在Apple M1 Pro CPU上的推理时间。
3. 算法分析
3.1 效果对比
话不多说,先看效果! 如图1(a)所示,上一次编辑的生成结果已经被计算,用户进一步编辑其中9.4%的区域。然而,普通的DDIM需要生成整个图像来计算新编辑的区域,在未改变的区域上浪费了80%的计算资源。解决这个问题的一个简单方法是首先分割新编辑的片段,合成相应的输出片段,并将输出与先前结果进行叠加。
但这种方法很容易在新编辑和未编辑的区域之间产生明显接缝。 为解决此问题,作者提出了空间稀疏推理(Spatially Sparse Inference,SSI)和稀疏增量生成引擎(SIGE),如图2(b)所示。作者的关键思想是重用之前编辑的缓存特征图并稀疏更新新编辑的区域。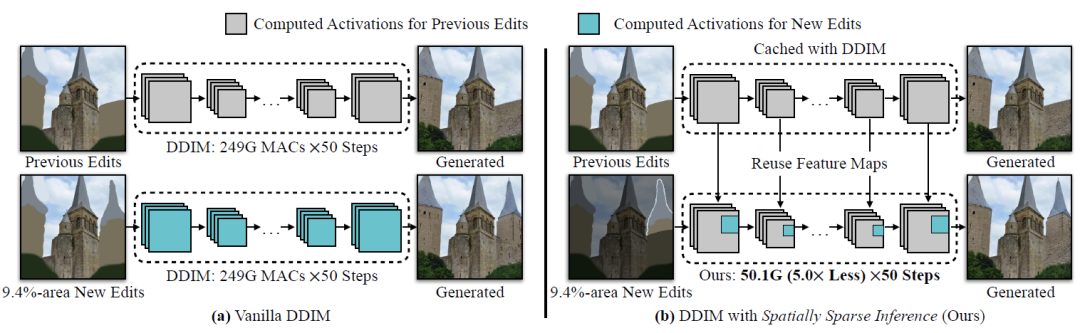
图1 在交互式编辑场景中,用户添加了一个新的建筑,它占据了9.4%的像素 如图2所示是作者与其他生成模型的对比结果。可以看出相较于DDIM和GauGAN,作者提出的方法计算量大幅降低。其中相较于DDIM,计算量降低了4~6倍,相较于GauGAN,计算量降低了15倍,当引入模型压缩方法以后,计算量进一步减少了47倍。注意一下这里的MACs指标,1 MAC等于2 FLOPs。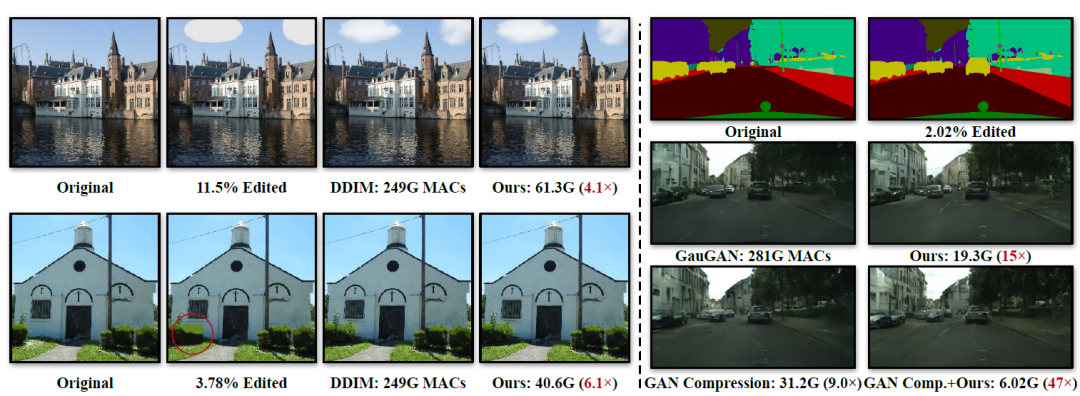
图2 作者提出方法的计算量对比 重要的是,这种方法可以很容易得推广到其他生成模型中!进一步降低计算量!
3.2 激活稀疏性
作者的启发灵感是,在交互式图像编辑期间,用户通常每次只编辑图像中的一部分。因此,可以为未编辑区域重用原始图像的激活。因此,可以利用编辑区域的空间稀疏性来加速深度生成模型。具体来说,给定用户输入,首先计算一个差异掩码来定位新编辑的区域。
对于每一个模型中的卷积层,仅稀疏地将滤波器应用于掩蔽的区域,而对未改变的区域重复使用先前的生成模型。稀疏更新可以在不损害图像质量的情况下显著减少计算量。 此外,由于稀疏更新涉及聚集-分散过程,现有的深度学习框架会导致显著的延迟开销。
为了解决这个问题,作者进一步提出了稀疏增量生成引擎(SIGE)来将算法的理论计算减少转化为在各种硬件上测量的延迟减少。 如图3所示是具体的算法原理,首先预计算原始输入图像的所有激活。在编辑过程中,通过计算原始图像和编辑图像之间的差异掩模来定位编辑区域。然后,对未编辑的区域重新使用预先计算的激活,并且通过对它们应用卷积滤波器来仅更新已编辑的区域。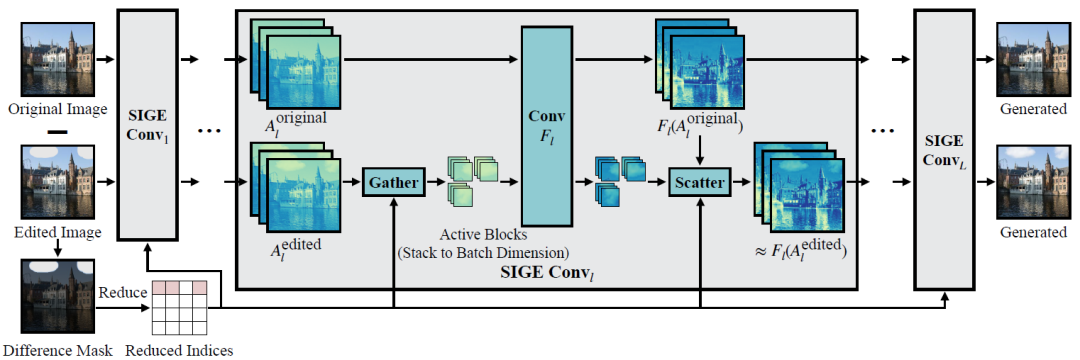
图3 稀疏卷积原理概述 具体的数学推导为:
其中Al表示第l层卷积层F的输入tensor,W和b分别是第l层的权重和偏置。 如图4所示,ΔAl共享了用户所做编辑中的结构化空间稀疏性,因此非零值主要聚集在编辑区域内。这样就可以直接使用原始图像和编辑后的图像来计算一个差异掩码,并用这个掩码对ΔAl进行稀疏化。
图4 左图:图像编辑示例。右图:在不同特征图分辨率下,DDIM第l层的∆Al通道平均值
3.3 稀疏增量生成引擎SIGE
但是如何利用结构化稀疏性来加速Wl*ΔAl呢? 一种简单的方法是为每个卷积从ΔAl中裁剪一个矩形编辑区域,并且只计算裁剪区域的特征。但作者发现这种裁剪方法对于不规则的编辑区域(图4所示的例子)效果很差。 因此,如图5所示,作者使用基于tiling的稀疏卷积算法。
首先将差异掩码向下采样到不同的比例,并扩展向下采样的掩码,将ΔAl在空间上划分为多个相同大小的小块。每个块索引指的是具有非零元素的单个块。然后将非零块沿批维度进行相应的聚集,并将其馈入卷积Fl。最后,根据索引将输出块分散成零张量,以恢复原始空间大小,并将预先计算的残差计算。
图5 基于titling的稀疏卷积
4. 实验
作者分别在三个模型上进行实验,包括扩散模型和GAN模型:DDIM、Progressive Distillation (PD)、GauGAN。使用LSUN Church数据集和Cityscapes数据集进行实验。在评价指标方面,使用PSNR、LPIPS、FID来评估图像质量。对于Cityscapes数据集还是用了语义分割中的mIoU这一指标。
4.1 主要结果
表1所示是作者方法应用于DDIM、Progressive Distillation (PD)和GauGAN的定量结果,并在图6中显示了定性结果。对于PSNR和LPIPS来说,对于DDIM和Progressive Distillation (PD)来说,作者方法始终优于所有基线,并获得与原始模型相当的结果。当由于全局上下文不足而编辑的区域很小时,补片推理失败。
尽管作者方法仅将卷积滤波器应用于局部编辑区域,但是可以重用存储在原始激活中的全局上下文。因此,作者的方法可以像原始模型一样执行。对于GauGAN,作者的方法也比GAN Compression执行得更好,MACs减少更多。当应用于GAN Compression时,进一步实现了大约40倍MACs的减少,性能略有下降,同时超过了0.19 GauGAN和GAN Comp。
表1 定量质量评估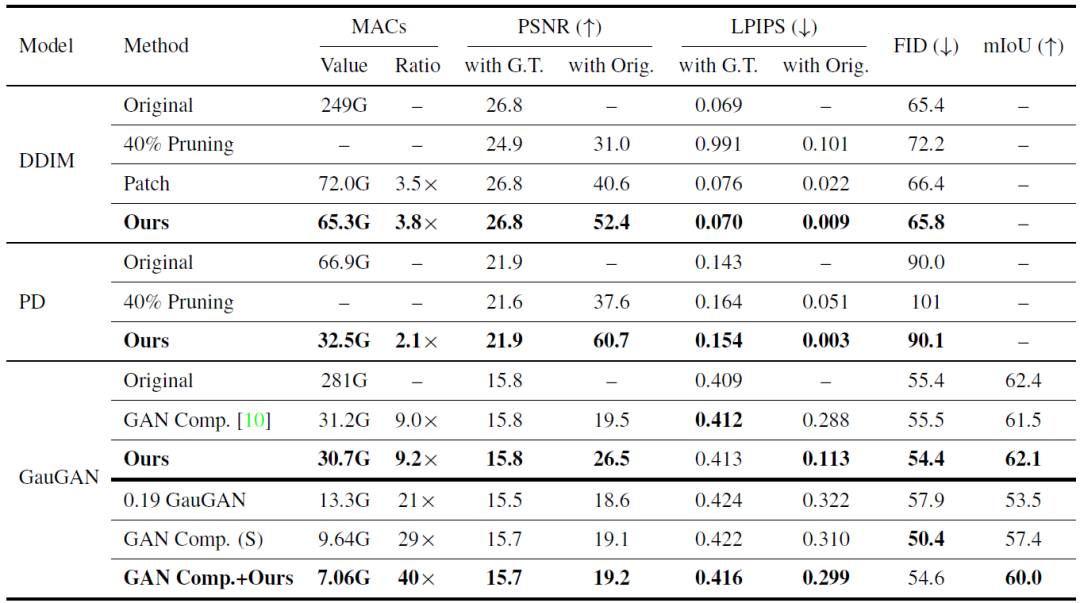

图6 所提出方法的定性对比
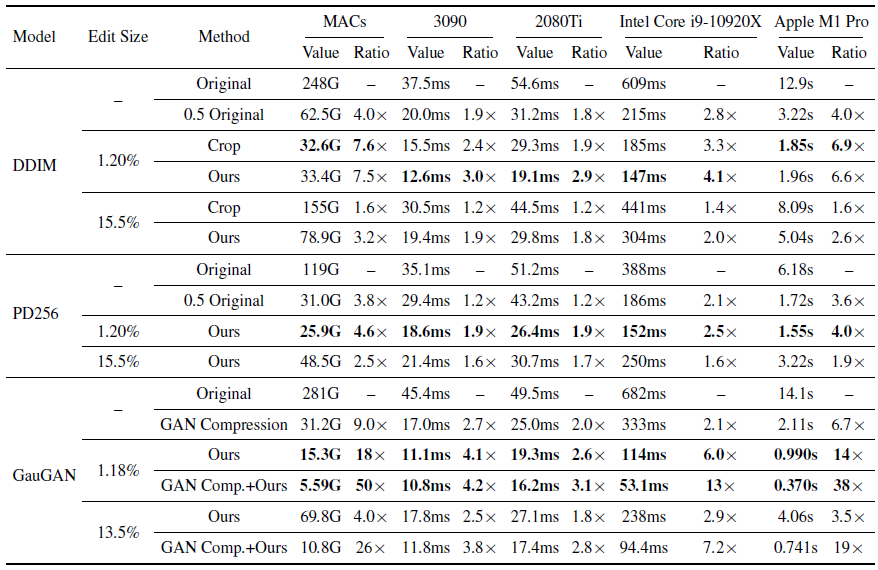
在模型模型效率方面,作者测试了了图6所示的编辑实例在4个设备上的加速比,包括RTX 3090、RTX 2080Ti、Intel Core i9-10920X CPU和Apple M1 Pro CPU,并且设置batch size为1来模式真实应用。对于GPU设备,首先执行200次预热运行,并测量接下来200次运行的平均耗时。对于CPU设备,首先执行10次预热运行和10次测试运行,重复此过程5次并报告平均耗时。结果如表2所示。
表2 模型效率对比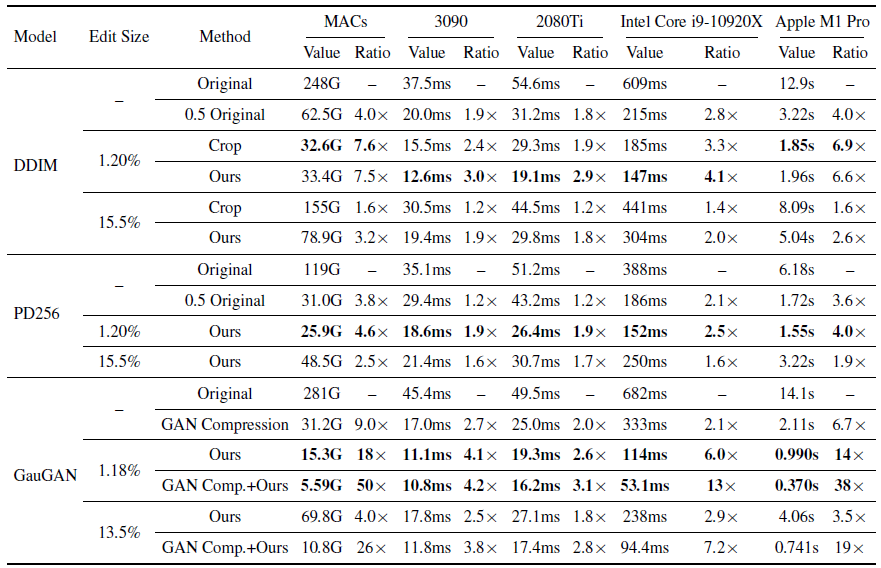
4.2 消融研究
表3显示了消融研究结果。 内存使用:原始图像预先计算的激活需要额外的存储量,但作者所提出的方法仅将DDIM、PD、GauGAN和GAN Compression的单次转发的峰值内存使用量分别增加了0.1G、0.1G、0.8G和0.3G。表3(a)所示是在RTX 2080Ti上为DDIM添加的每个内核优化的有效性。
简单地应用基于tiling的稀疏卷积可以将计算量减少7.6倍。表3(b)是在TensorRT上进行了模型部署,TensorRT进一步加快了模型的运行效率。
表3 模型消融实验结果
5. 结论
在2022 NeurIPS论文“Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models”中,CMU、MIT、斯坦福联合提出了空间稀疏推理(SSI)和稀疏增量生成引擎(SIGE)。这种算法减少了现有深度生成模型的计算资源浪费问题,对于生成模型的落地和应用具有重要意义。重要的是,算法已经开源,并且可以应用于各种生成模型,包括条件GAN和扩散模型!
审核编辑:刘清
-
cpu
+关注
关注
68文章
10816浏览量
210963 -
MIT
+关注
关注
3文章
253浏览量
23356 -
GaN
+关注
关注
19文章
1913浏览量
72865 -
SSI
+关注
关注
0文章
38浏览量
19204
原文标题:加速各种生成模型!NeurIPS开源!CMU、MIT、斯坦福提出高效空间稀疏推理!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

高效大模型的推理综述

FPGA和ASIC在大模型推理加速中的应用

AI大模型与深度学习的关系
使用OpenVINO C++在哪吒开发板上推理Transformer模型








 工商网监
工商网监
评论