 建立计算模型来预测一个给定博文的抱怨强度
建立计算模型来预测一个给定博文的抱怨强度
01
研究动机
抱怨是一种表达现实和人类期望之间不一致的言语行为[1]。人们会根据情况的严重性和紧迫性,用抱怨来表达他们的担忧或不满。轻微的抱怨可以达到发泄情绪以促进心理健康的目的,但严重的抱怨可能会导致仇恨甚至欺凌行为[2]。之前的研究主要集中在识别抱怨是否存在或其类型上,但是分析抱怨强度尤其重要,因为一定程度的抱怨可能会对公司或组织造成严重的负面后果。

图1 Jin数据集中同类别抱怨博文
在计算语言学中,先前的研究主要集中在建立自动分类模型来识别抱怨是否存在。Jin提供了一个数据集,基于语用学注释了不同严重程度的抱怨博文,分别为“没有明确的指责”、“反对”、“指责”、“指控”和“责备”[3]。在这些研究中,我们注意到一个缺失的部分是测量抱怨的强度。
为了说明这一点,我们展示了Jin最新数据集中的四个例子,如图1所示:“我能向你抱怨我刚刚收到的咖啡吗?”和“维珍媒体如往常一样充满谎言谎言谎言!!!”,这两句话被分为同一类型“指控”,但显然它们在抱怨的程度上是不同的。另一个例子是,“完全不酷”和“请尽快回复我的消息!!!”,这两句都被归类为“反对”,然而,后者明显提出了更强烈的抱怨。
分析不同的抱怨水平是有利的。公司需要定期监控来自用户的反馈,因为某些抱怨可能会严重影响其产品的声誉。组织或政府需要监控民众的抱怨,以了解他们的迫切需求。
02
贡献
1、我们提出一个新颖的工作:即自动捕捉文本中抱怨强度
2、我们展示了第一个中文抱怨强度数据集,包含来自微博平台的3103条数据。
3、通过一系列分析实验进一步证明研究抱怨强度的必要性和重要性,以及一些有趣的实证发现。
4、我们展示了我们的数据集如何帮助预测社交媒体上博文的流行度。
03
数据标注
在这项工作中,我们使用Louviere and Woodworth(1991)提出的最佳最差比例法(Best-Worst Scaling, BWS)[4]注释了抱怨强度。这种方法通过相互比较,可以比直接评分产生更稳定和细粒度的分数。类似的方法也被广泛应用于计算语言学的各种任务中,例如测量攻击性,亲密度等等。我们通过简单的计数百分比统计最终为每个博文分配抱怨强度评分,范围从-1(最不抱怨)到1(最抱怨)。部分标注结果如图2所示:

图2部分数据标注结果
04
主实验
我们建立计算模型来预测一个给定博文的抱怨强度,使用SVR,Bidirectional LSTM,和BERT, RoBERTa等预训练模型。我们在两种情况下评估模型的性能:(1)混合话题(Mix Hashtag),我们将来自不同话题的微博博文组合在一起;(2)交叉话题(Cross Hashtag),其中训练、开发和测试集的博文与不同的话题分开。我们使用皮尔逊相关性和MSE(均方误差)作为我们所有实验的度量标准。实验结果如图3所示:
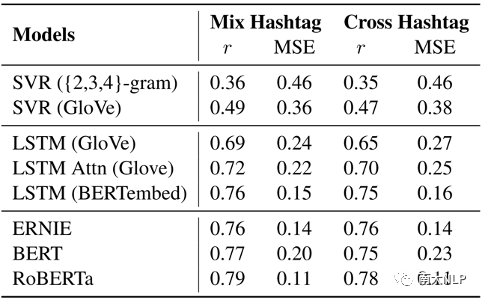
图3用于评估预测抱怨强度的Pearson系数的r和均方误差(MSE)
05
分析实验
抱怨和情绪之间的差异
我们注意到更强烈的抱怨似乎与消极词汇有关。先前的研究也指出,抱怨可以被视为一个有影响的情感维度[2].我们展示在标准情绪数据集上训练的模型在我们的抱怨强度预测任务中表现情况,如图4所示,使用来自情绪模型的概率分数在我们的抱怨强度预测任务中表现出不错的表现,这表明了抱怨和情绪之间的明确联系。同时在我们的标注语料库上训练的模型优于情绪模型,这证明了我们的工作的必要性。
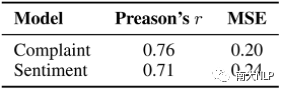
图4抱怨强度预测任务中情绪模型和抱怨模型的表现
抱怨可以加强情感分析任务
我们将抱怨分数作为一个附加的特性输入被添加到模型中。从图5中,我们观察到具有抱怨特征的模型比原始模型表现得更好。表明一个简单的附加组件可以提高非神经模型和传统神经模型的情绪分类预测精度,分析抱怨可以有助于二元情感分析任务。
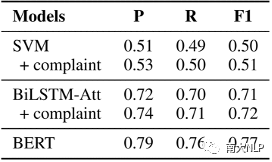
图5二元情绪预测的结果(显著性测试p-vlaue < 0.01, t-test)
06
跨语言分析
我们最新收集的抱怨强度数据集是中文的,而当前现有的数据集包含英文推文。这为我们提供了一个机会来了解在社交媒体上使用中文和英语的人在抱怨上的语言差异。
(1)直接和间接抱怨:中文博文中80%为间接抱怨;相反,英文推文91%的都是直接抱怨。
(2)策略:图6显示了不同语言的策略有所不同。我们发现,中文使用者更倾向于不补偿策略,而英文使用者最常用的策略是补偿策略。
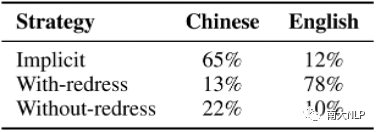
图6跨语言分析中不同策略所占百分比。
(3)讽刺:10%的中文数据包含讽刺,26%的英文数据包含讽刺。图7展示了词性分析,中文讽刺表达中名词比例最高,其次是动词;而在英文讽刺表达中,动词最多,其次是名词。此外,英语中的形容词和副词比中文的要多。
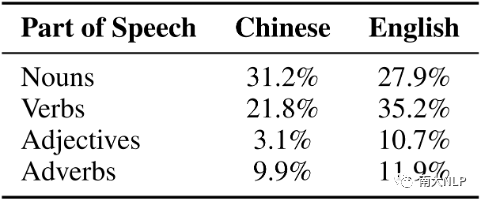
图7跨语言分析的POS标签的百分比
07
预测博文流行度
我们设想将抱怨强度分数纳入现有的社交媒体监控系统中,以提高它们的预测准确性,证明了来自我们的计算模型的抱怨强度得分可以帮助估计社交媒体上的帖子流行度。
我们遵循Szabo的流行度计算方法[5],使用早期流行度进行预测的基线,为了显示我们的抱怨分数的有效性,我们添加了抱怨强度作为一个新的术语来估计最终的对数流行度,公式如下所示:
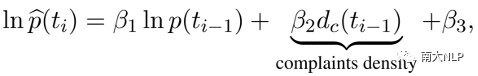
图8显示,我们结合了抱怨密度的方法优于基线方法。
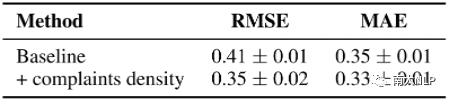
图8 RMSE和MAE的流行度预测
我们还展示了随时间变化的单一话题下的流行度预测,如图9所示。我们观察到,增加了抱怨分数有助于更好地估计发布后的流行度,特别是在早期阶段。这可能是因为抱怨可能会吸引用户的注意力,以便参与讨论,从而提高活动的流行度。
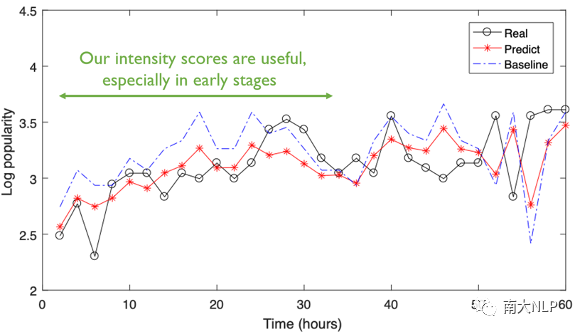
图9比较实际的博文流行度和对单一话题的流行度预测
08
总结
我们提出了第一个测量文本抱怨强度的研究。我们构建了一个包含3103篇关于抱怨的中国微博文章的语料库,并使用BWS方法标注了抱怨强度评分。然后,我们证明了我们的语料库支持自动计算模型的发展,以准确的抱怨强度预测。此外,我们还研究了抱怨与情绪之间的联系,并对中文和英文之间的抱怨表达进行了跨语言比较。我们最终证明,我们的抱怨强度得分有助于更好地估计社交媒体上的博文的流行度。
审核编辑:刘清
-
SVR
+关注
关注
0文章
7浏览量
10750
原文标题:NAACL'22 Findings | 社交媒体上的抱怨强度分析
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
介绍FIR滤波模型的建立,分4个步骤
BP神经网络预测模型的建模步骤
matlab预测模型怎么用
如何使用MATLAB创建预测模型
bp神经网络预测模型建模步骤
arimagarch模型怎么预测
如何使用PyTorch建立网络模型
这个CRC计算单元是如何基于固定的生成多项式(0x4C11DB7)来获取给定数据缓冲区的CRC码的?
异步电机的磁链给定值该怎样计算?
如何基于深度学习模型训练实现工件切割点位置预测

如何基于深度学习模型训练实现圆检测与圆心位置预测






 工商网监
工商网监
评论