 介绍大模型高效训练所需要的主要技术
介绍大模型高效训练所需要的主要技术
本文分为三部分介绍了大模型高效训练所需要的主要技术,并展示当前较为流行的训练加速库的统计。
引言:随着BERT、GPT等预训练模型取得成功,预训-微调范式已经被运用在自然语言处理、计算机视觉、多模态语言模型等多种场景,越来越多的预训练模型取得了优异的效果。为了提高预训练模型的泛化能力,近年来预训练模型的一个趋势是参数量在快速增大,目前已经到达万亿规模。
但如此大的参数量会使得模型训练变得十分困难,于是不少的相关研究者和机构对此提出了许多大模型高效训练的技术。本文将分为三部分来介绍大模型高效训练所需要的主要技术:并行训练技术、显存优化技术和其他技术。文章最后会展示当前较为流行的训练加速库的统计。欢迎大家批评指正,相互交流。
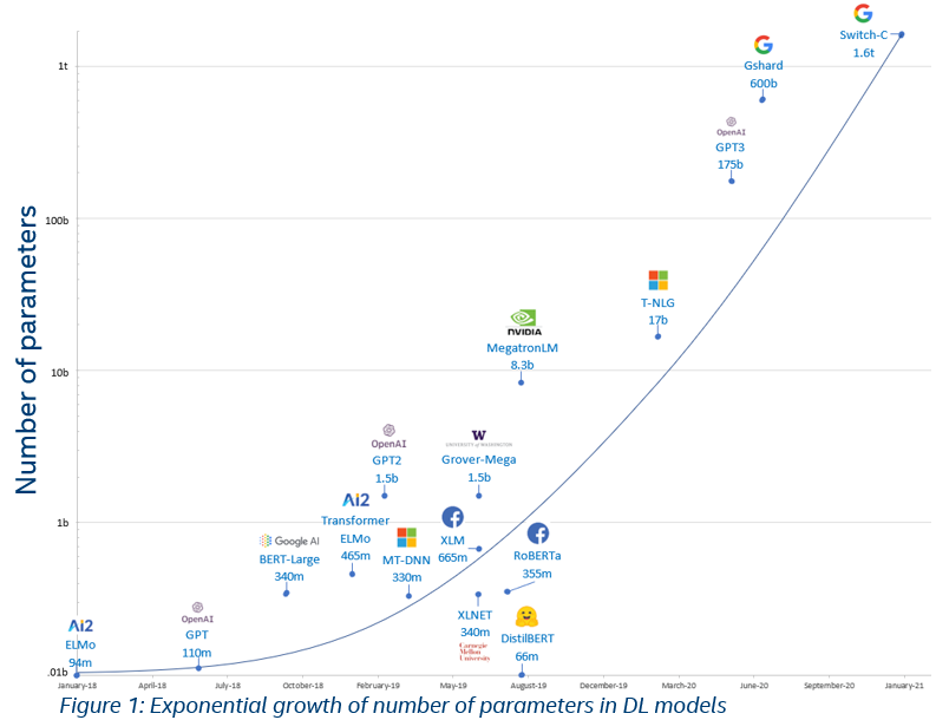
预训练模型参数量增长趋势
一、并行训练技术:
并行训练技术主要是如何使用多块显卡并行训练模型,主要可以分为三种并行方式:数据并行(Data Parallel)、张量并行(Tensor Parallel)和流水线并行(Pipeline Parallel)。
数据并行(Data Parallel)
数据并行是目前最为常见和基础的并行方式。这种并行方式的核心思想是对输入数据按 batch 维度进行划分,将数据分配给不同GPU进行计算。
在数据并行里,每个GPU上存储的模型、优化器状态是完全相同的。当每块GPU上的前后向传播完成后,需要将每块GPU上计算出的模型梯度汇总求平均,以得到整个batch的模型梯度。
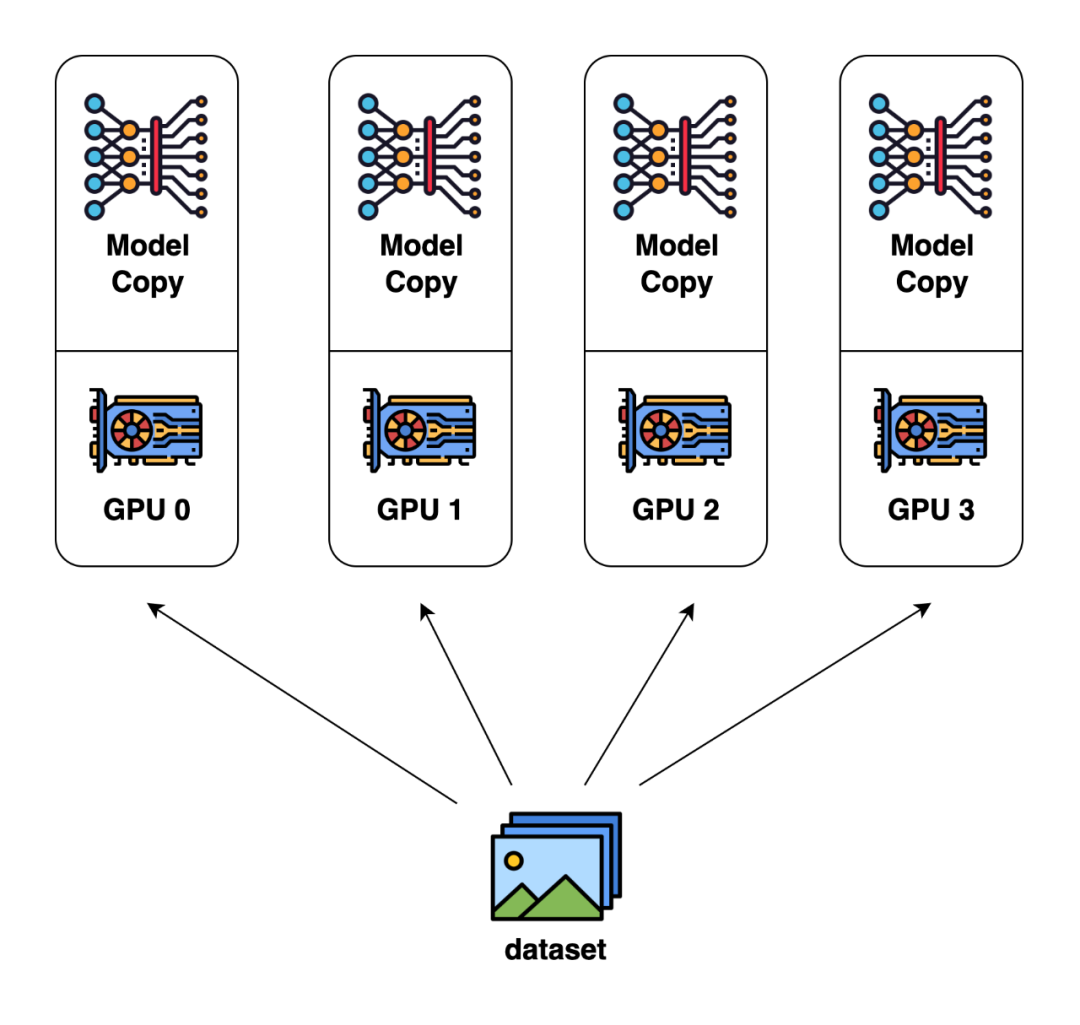
数据并行(图片来自 Colossal-AI 的文档)
目前 PyTorch 已经支持了数据并行 [1]:
https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html
张量并行(Tensor Parallel)
在训练大模型的时候,通常一块GPU无法储存一个完整的模型。张量并行便是一种使用多块GPU存储模型的方法。
与数据并行不同的是,张量并行是针对模型中的张量进行拆分,将其放置到不同的GPU上。比如说对于模型中某一个线性变换Y=AX,对于矩阵A有按列拆解和按行拆解两种方式:
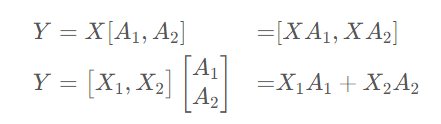
我们可以将矩阵A1和A2分别放置到两块不同的GPU上,让两块GPU分别计算两部分矩阵乘法,最后再在两张卡之间进行通信便能得到最终的结果。
同理也可以将这种方法推广到更多的GPU上,以及其他能够拆分的算子上。
下图是Megatron-LM[2] 在计算 MLP 的并行过程,它同时采用了这两种并行方式:
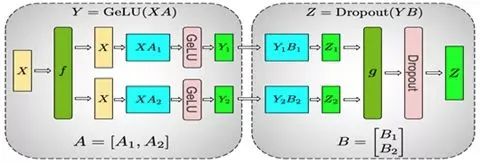
整个MLP的输入X先会复制到两块GPU上,然后对于矩阵A采取上面提到的按列划分的方式,在两块GPU上分别计算出第一部分的输出Y1和Y2。
接下来的 Dropout 部分的输入由于已经按列划分了,所以对于矩阵B则采取按行划分的方式,在两块GPU上分别计算出Z1和Z2。最后在两块GPU上的Z1和Z2做All-Reduce来得到最终的Z。
以上方法是对矩阵的一维进行拆分,事实上这种拆分方法还可以扩展到二维甚至更高的维度上。在Colossal-AI中,他们实现了更高维度的张量并行:
https://arxiv.org/abs/2104.05343 https://arxiv.org/abs/2105.14500 https://arxiv.org/abs/2105.14450
对于序列数据,尤洋团队还提出了Sequence Parallel来实现并行:
https://arxiv.org/abs/2105.13120
流水线并行(Pipeline Parallel)
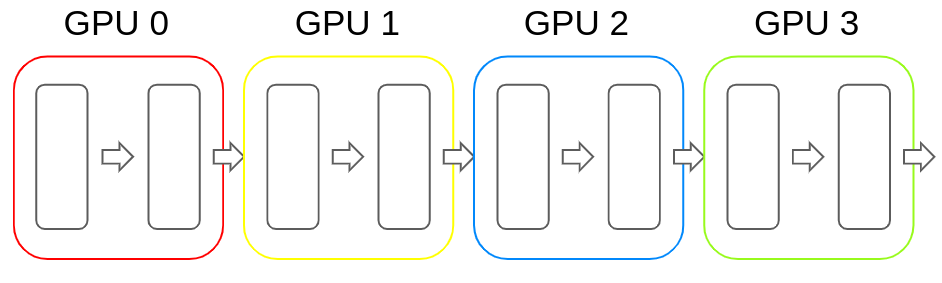
和张量并行类似,流水线并行也是将模型分解放置到不同的GPU上,以解决单块GPU无法储存模型的问题。和张量并行不同的地方在于,流水线并行是按层将模型存储的不同的GPU上。
比如以Transformer为例,流水线并行是将连续的若干层放置进一块GPU内,然后在前向传播的过程中便按照顺序依次计算hidden state。反向传播也类似。下图便是流水线并行的示例:
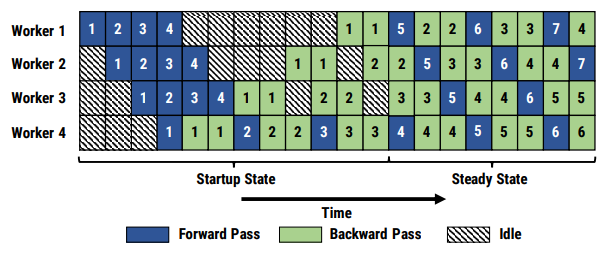
但朴素的流水线并行实现会导致GPU使用率过低(因为每块GPU都要等待之前的GPU计算完毕才能开始计算),使流水线中充满气泡,如下图所示:
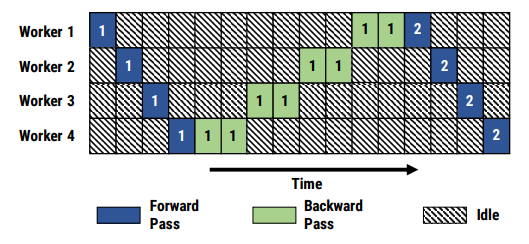
有两种比较经典的减少气泡的流水线并行算法:GPipe[7] 和PipeDream[8]
GPipe 方法的核心思想便是输入的minibatch划分成更小的 micro-batch,让流水线依次处理多个 micro batch,达到填充流水线的目的,进而减少气泡。GPipe 方法的流水线如下所示:
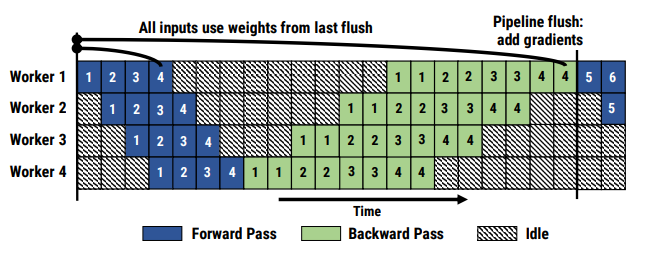
PipeDream 解决流水线气泡问题的方法则不一样,它采取了类似异步梯度更新的策略,即计算出当前 GPU 上模型权重的梯度后就立刻更新,无需等待整个梯度回传完毕。相较于传统的梯度更新公式:
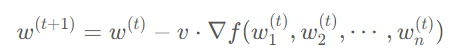
PipeDream 的更新公式为:
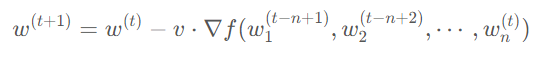
由于这种更新方式会导致模型每一层使用的参数更新步数不一样多,PipeDream 对上述方法也做出了一些改进,即模型每次前向传播时,按照更新次数最少的权重的更新次数来算,即公式变为:
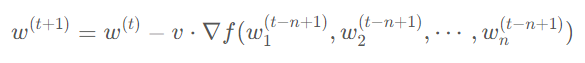
PipeDream 方法的流水线如下所示:
对比总结
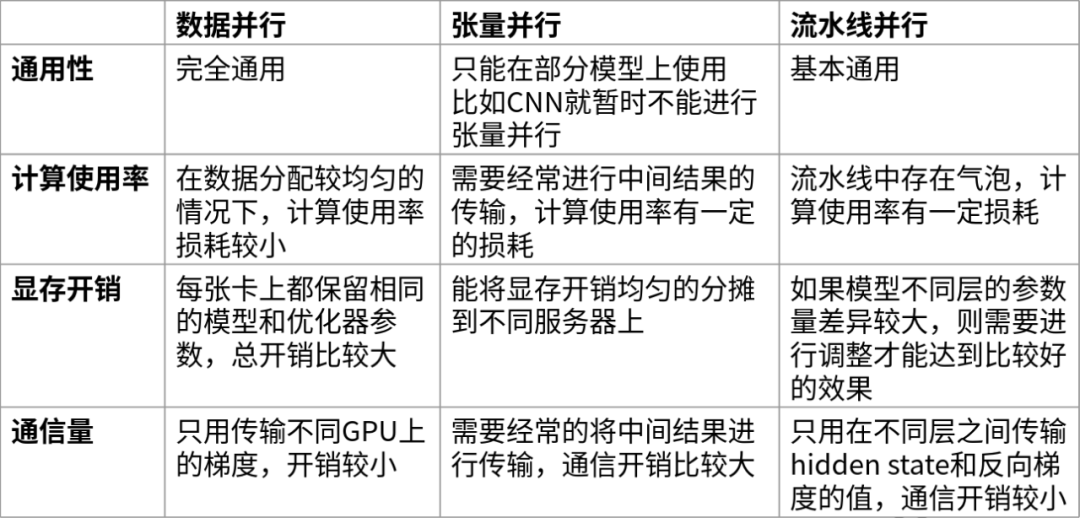
下面是对这三种并行技术从通用性、计算效率、显存开销和通信量这几个方面进行对比。
可以看出数据并行的优势在于通用性强且计算效率、通信效率较高,缺点在于显存总开销比较大;而张量并行的优点是显存效率较高,缺点主要是需要引入额外的通信开销以及通用性不是特别好;流水线并行的优点除了显存效率较高以外,且相比于张量并行的通信开销要小一些,但主要缺点是流水线中存在气泡。
二、显存优化技术:
在模型训练的过程中,显存主要可以分为两大部分:常驻的模型及其优化器参数,和模型前向传播过程中的激活值。显存优化技术主要是通过减少数据冗余、以算代存和压缩数据表示等方法来降低上述两部分变量的显存使用量,大致可分为四大类:ZeRO技术、Offload技术、checkpoint技术以及一些节约显存的优化器。
ZeRO 技术
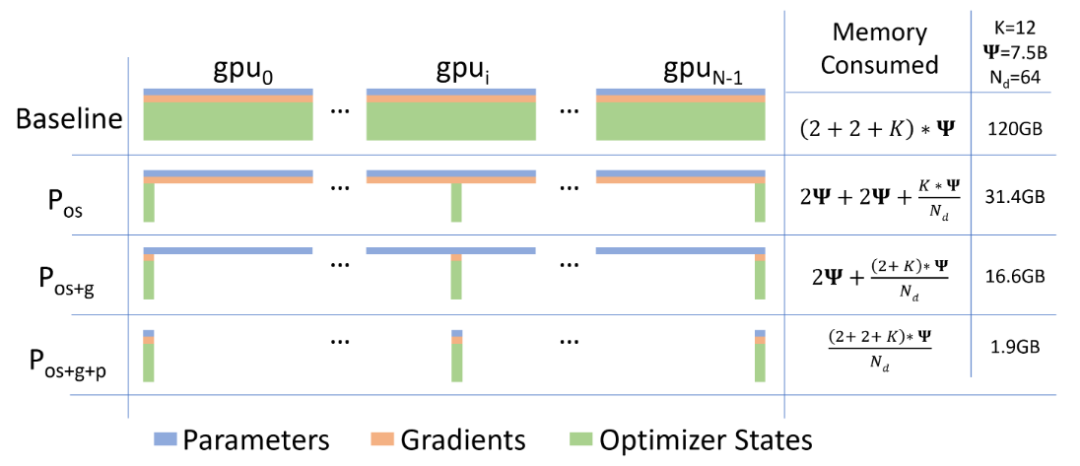
ZeRO[9] 技术是微软的 DeepSpeed 团队解决数据并行的中存在的内存冗余问题所提出的解决方法。常驻在每块GPU上的数据可以分为三部分:模型参数,模型梯度和优化器参数。注意到由于每张 GPU 上都存储着完全相同的上述三部分参数,我们可以考虑每张卡上仅保留部分数据,其余的可以从其他 GPU 上获取。
即假如有N张卡,我们可以让每张卡上只保存其中1/N的参数,需要的时候再从其他 GPU 上获取。ZeRO 技术便是分别考虑了上述三部分参数分开存储的情况,下图中的Pos、Pos+g和Pos+g+p就分别对应着将优化器参数分开存储、将优化器参数和模型梯度分开存储以及三部分参数都分开存储三种情况。
论文里不仅分析了三种情况可以节省的内存情况,还分析出了前两种优化方法不会增加通信开销,第三种情况的通信开销只会增加50%。
目前Pytorch也已经支持了类似的技术:
https://engineering.fb.com/2021/07/15/open-source/fsdp/ https://pytorch.org/docs/stable/fsdp.html
Offload 技术
ZeRO-Offload[10] 技术主要思想是将部分训练阶段的模型状态 offload 到内存,让 CPU 参与部分计算任务。
为了避免 GPU 和 CPU 之间的通信开销,以及 CPU 本身计算效率低于 GPU 这两个问题的影响。Offload 的作者在分析了 adam 优化器在 fp16 模式下的运算流程后,考虑只将模型更新的部分下放至 CPU 计算,即让 CPU 充当 Parameter Server 的角色。如下图所示:
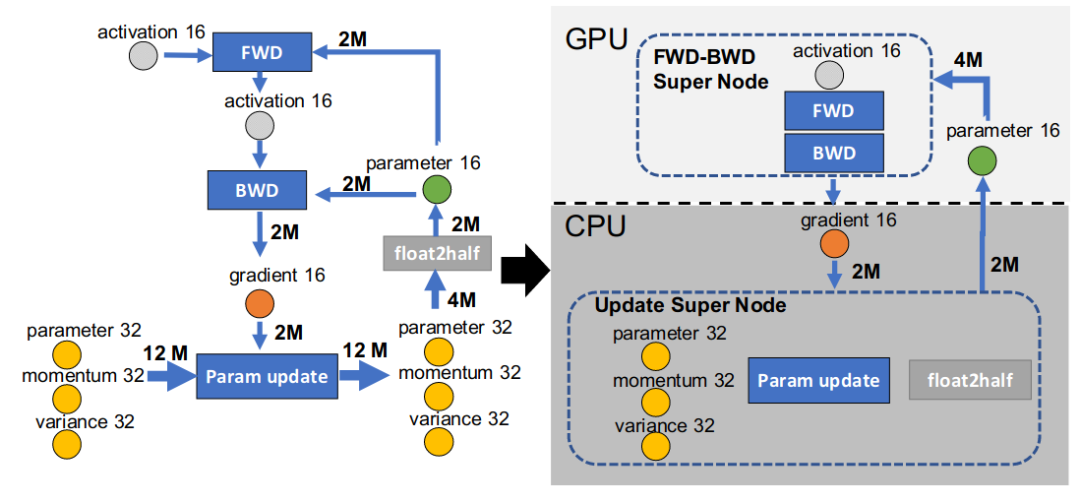
同时为了提高效率,Offload 的作者提出可以将通信和计算的过程并行起来,以降低通信对整个计算流程的影响。
具体来说,GPU 在反向传播阶段,可以待梯度值填满bucket后,一边计算新的梯度一边将bucket传输给CPU;当反向传播结束,CPU基本上获取了最新的梯度值。同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示:
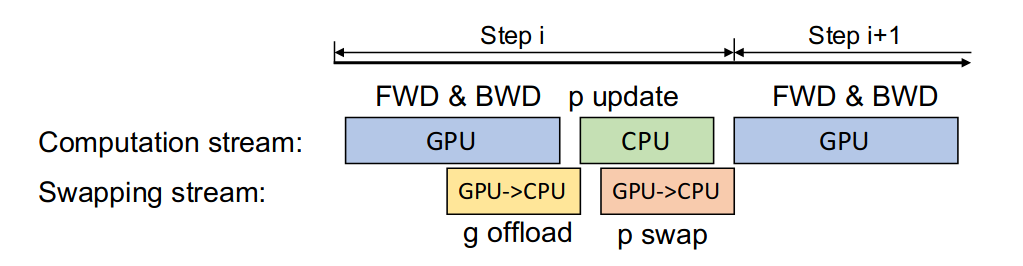
最后作者也分析了多卡的情况,证明了他提出的方案具有可扩展性。
Checkpoint 技术
在模型前向传播的过程中,为了反向传播计算梯度的需要,通常需要保留一些中间变量。例如对于矩阵乘法
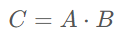
A和B的梯度计算公式如下所示
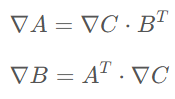
可以看出要想计算A和B的梯度就必须在计算过程中保留A和B本身。这部分为了反向传播所保留的变量会占用不小的空间。Checkpoint技术的核心是只保留checkpoint点的激活值,checkpoint点之间的激活值则在反向传播的时候重新通过前向进行计算。可以看出,这是一个以算代存的折中方法。最早是陈天奇将这个技术引入机器学习中 [11]:
https://arxiv.org/abs/1604.06174
目前该方法也以及被 PyTorch 所支持。
https://pytorch.org/docs/stable/checkpoint.html
节约显存的优化器
比较早期的工作是如Adafactor[12] 主要是针对 Adam 进行优化的,它取消了 Adam 中的动量项,并使用矩阵分解方法将动量方差项分解成两个低阶矩阵相乘来近似实现 Adam 的自适应学习率功能。
后来也有使用低精度量化方式存储优化器状态的优化器,如8 bit Optimizer[13],核心思想是将优化器状态量化至 8 bit 的空间,并通过动态的浮点数表示来降低量化的误差。还有更加激进的使用 1 bit 量化优化器的方法,如1-bit Adam[14] 和1-bit LAMB[15]。他们主要是使用压缩补偿方法的来减少低精度量化对模型训练的影响。
三、其他优化技术:
大批量优化器
在目前模型训练的过程中,直接使用大批量的训练方式可能导致模型训练不稳定。最早有 Facebook 的研究[16] 表明,通过线性调整学习率,并配合 warmup 等辅助手段,让学习率随 batch 的增大而线性增大,即可在ResNet-50上将 batch size 增大至 8K 时仍不影响模型性能。
但该方法在 AlexNet 等网络失效,在LARS[17] 优化器这篇论文中,作者尤洋在实验中发现不同层的权值和其梯度的 2 范数的比值差异很大,据此基于带动量的SGD优化器提出LARS优化器。核心算法如下图所示:

基于以上的思路,尤洋将上述方法扩展到Adam优化器,提出了LAMB[18] 优化器:

FP16
FP16[19] 基本原理是将原本的32位浮点数运算转为16位浮点数运算。一方面可以降低显存使用,另一方面在 NVIDIA 的显卡上 fp16 的计算单元比 fp32 的计算单元多,可以提升计算效率。在实际的训练过程中,为了保证实际运算过程中的精度,一般还会配合动态放缩技术。目前的主流框架都已实现该功能。
算子融合
算子融合实际上是将若干个 CUDA 上的运算合成一个运算,本质上是减少了 CUDA 上的显存读写次数。举个例子,对于一个线性层 + batch norm + activation 这个组合操作来说:
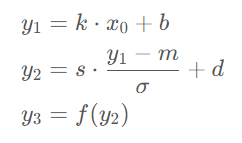
直接使用 PyTorch 实现的会在计算y1,y2,y3的过程中分别产生一次显存的读和写操作,即3次读和写。如果将其按下面的公式合并成一个算子进行计算,那么中间的结果可以保留在 GPU 上的寄存器或缓存中,从而将显存读写次数降低至1次。
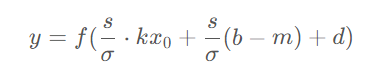
目前 PyTorch 可以使用 torch.jit.script 来将函数或 nn.Module 转化成 TorchScript 代码,从而实现算子融合。
https://pytorch.org/docs/stable/generated/torch.jit.script.html
设备通信算法
在之前介绍的模型分布式训练中,通常需要在不同 GPU 之间传输变量。在 PyTorch 的 DataParallel 中,使用的是Parameter Server架构,即存在一个中心来汇总和分发数据:
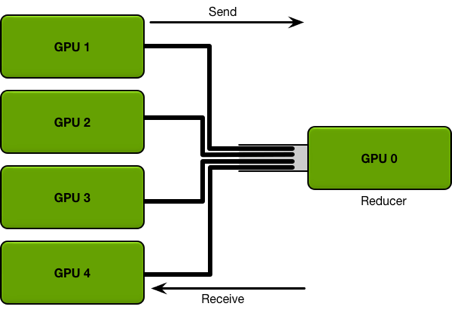
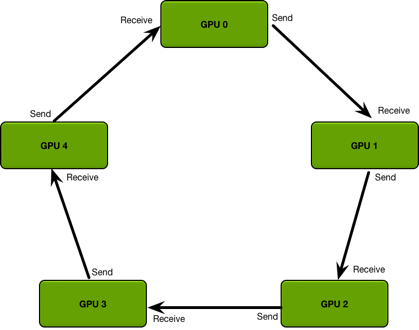
但上述方式的缺点是会导致 Parameter Server 成为通信瓶颈。之后PyTorch的Distributed DataParallel则使用了Ring All-Reduce[20] 方法,将不同的GPU构成环形结构,每个GPU只用与环上的邻居进行通信:
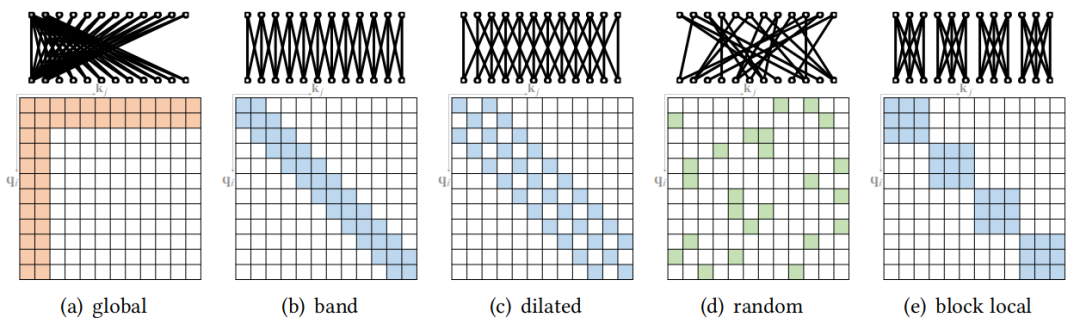
稀疏attention
稀疏Attention技术最开始是运用在长序列的Transformer建模上的,但同时也能有效的降低模型计算的强度。稀疏Attention主要方法可以分为以下五类 [21]:
目前DeepSpeed已经集成了这个功能:
https://www.deepspeed.ai/tutorials/sparse-attention/
自动并行
目前并行训练技术在大模型训练中已被广泛使用,通常是会将前面介绍的三种并行方法结合起来一起使用,被称之为 3D 并行。
但这些并行方式都有不少的训练超参数,之前的一些研究者是使用手动的方式来设置这些超参数。目前也出现了不少自适应的方法来设置超参数,被称为自动并行技术。
这些方法包括动态规划、蒙特卡洛方法、强化学习等。下面的 GitHub 仓库整理了一些自动并行的代码和论文:
https://github.com/ConnollyLeon/awesome-Auto-Parallelism
四、训练加速库概览
下面是本人对当下比较流行的训练加速库的统计,可供大家进行参考。
审核编辑:刘清
-
gpu
+关注
关注
28文章
4791浏览量
129471 -
GPT
+关注
关注
0文章
363浏览量
15542 -
MLP
+关注
关注
0文章
57浏览量
4305 -
大模型
+关注
关注
2文章
2628浏览量
3239
原文标题:Huge and Efficient! 一文了解大规模预训练模型高效训练技术
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何在SAM时代下打造高效的高性能计算大模型训练平台
芯耀辉DDR PHY训练技术简介
【大语言模型:原理与工程实践】核心技术综述
【大语言模型:原理与工程实践】大语言模型的基础技术
【大语言模型:原理与工程实践】大语言模型的预训练
Pytorch模型训练实用PDF教程【中文】
医疗模型人训练系统是什么?
如何进行高效的时序图神经网络的训练
基于速度追踪原理实现目标模拟训练系统的设计
DGX SuperPOD助力助力织女模型的高效训练
深度学习如何训练出好的模型






 工商网监
工商网监
评论