 避免在军事/航空航天嵌入式代码中使用无恶意API
避免在军事/航空航天嵌入式代码中使用无恶意API
动态分配在 C/C++ 中普及,通过在运行时根据需要将系统内存分配给应用程序进程,并在不再需要内存时检索内存,从而简化开发。
但动态分配被广泛认为是安全关键型嵌入式软件的禁忌。使用 C 运行时库的 malloc() 和 free() API 来完成动态分配的繁重工作,可能会引入灾难性的副作用,例如内存泄漏或碎片。此外,malloc() 可能会表现出非常不可预测的性能,并成为多核系统上多线程程序的瓶颈。由于其风险,根据DO-178B标准,在安全关键型嵌入式航空电子代码中禁止动态内存分配。
整个嵌入式行业的开发人员似乎对这个话题做出了发自内心的反应。在最近的一次互联网技术小组讨论中,“你在嵌入式设计中使用动态内存分配吗?”这个问题获得了惊人的77个回答,典型的是“一般来说,它被认为违反了容错系统的最佳实践”,以及“如果要求包括‘五个九’(99.999%的正常运行时间)可靠性,硬实时或小内存占用,答案是‘从不’。求职者请注意:一位咨询工程师的面试策略“是温和地探查潜在员工在实时应用程序中的动态内存分配使用情况。如果他们对此没有问题,他们就不会被雇用。
更好的策略 - 无论是代码安全和工作面试成功 - 是将安全关键代码中的标准(默认)分配器替换为更匹配特定分配方案的自定义内存分配函数。以下讨论描述了两个这样的自定义内存管理器:基于堆栈的分配器和线程本地分配器。摆脱 malloc() 和 free() 应用程序的另一种方法——从而获得更好的性能、稳定性和可预测性——是用包含自定义分配器的现成软件替换基于标准分配函数的代码。内存数据库系统(IMDS)的使用被讨论为这种“购买而不是构建”方法的一个例子。
这是标准的,但它是最好的吗?
为什么标准(动态)内存管理器不适合任务关键型代码?通常,它们基于列表分配器算法,该算法将内存池组织到单向链表中的连续位置(空闲孔)。然后,分配器“行走”这条链条,寻找合适的孔来满足请求。列表分配器是典型的通用功能:它们在各种情况下分配和解分配内存方面做得很好 - 但在任务或安全关键系统中“相当好”还不够好。
基于堆栈的算法:分配和倒带内存
某些应用程序方案需要分配许多生存期较短的对象,然后一次释放所有对象。基于堆栈的分配器(不要与应用程序调用堆栈混淆)是一种类型的自定义分配器,在这里运行良好。使用此算法,每次分配返回堆栈指针当前位置的地址,并按请求量推进指针(图 1)。当不再需要内存时,堆栈指针将倒带。处理开销减少了,因为没有要管理的指针链,也没有任何要跟踪的分配大小或可用孔。这种方法也更安全:不会因不当的解除分配而意外引入内存泄漏,因为应用程序不必跟踪特定的分配。
图1:基于堆栈的自定义分配器
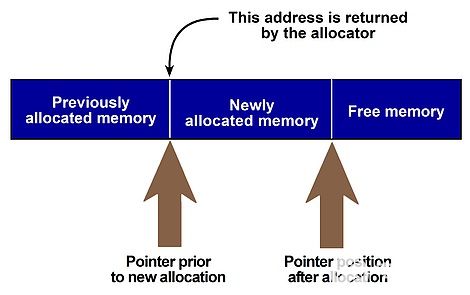
与标准列表分配器相比,使用基于堆栈的分配器所消除的开销随着应用程序的继续运行而增加。当内存以随机顺序释放时,列表分配器通常需要将指针和大小值添加到其链中(这称为碎片),以便指针和大小值表示占总堆大小的更大百分比。因此,列表分配器的开销(必须管理的元数据量以及必须走得更远才能找到合适的可用漏洞的可能性)随着应用程序的继续运行而增长。(使用基于堆栈的分配器,从某个时间点分配的所有块都会在一个操作中返回到堆中,从而避免碎片。
多线程、多核分配挑战
当多线程应用程序陷入多处理器硬件时,由互斥锁控制的默认 malloc() 和 free() 函数通常是罪魁祸首。使用这些分配器的线程可能会导致锁定冲突,操作系统通过消耗性能的上下文切换部分解决这些问题。自定义线程本地分配器通过为每个线程分配特定的内存池来避免冲突。线程的分配是从这个块执行的,而不会干扰其他线程的请求,从而提高性能和可预测性。当线程分配器内存不足时,如果系统允许,其他分配器可以为其分配另一个块。线程本地分配器对每个线程使用挂起请求列表或 PRL 来协调由执行原始分配的线程以外的线程释放的内存块的释放。由同一线程分配和取消分配的内存不需要协调,因此不会发生锁冲突。
简而言之,通过从 malloc() 和 free() 中删除内存管理责任并将其分配给应用程序,可以避免安全关键代码中的问题,应用程序使用与特定应用程序任务相吻合的自定义分配器。自定义分配器为该任务的独占使用留出缓冲区(通常在启动期间),并满足来自它的内存分配请求。如果缓冲区内存不足,应用程序将收到通知,并可以释放缓冲区内的内存。或者它可以在其他地方找到更多的内存来投入到任务中。耗尽此专用池中的内存不会影响系统的其他部分。可以选择的自定义分配器包括所讨论的分配器,以及位图分配器、块分配器等。
通过第三方应用程序分配
自定义内存分配器的优势也可以通过集成使用它们的第三方软件来利用。IMDS是受益于自定义分配器的良好候选者,因为它们专门设计用于管理RAM中的应用程序对象。图 2 说明了使用 malloc() 和 free() 进行分配/解除分配。图3显示了使用McObject的eXtremeDB的相同过程,这是一个IMDS,它结合了自定义分配器,包括基于堆栈和线程本地。在图 2 的开头,C 程序定义了一个结构,声明了一个指向该结构实例的指针,并通过 malloc() 为其分配内存。
图2:使用 malloc() 和 free() 进行内存分配

图3:使用内存数据库系统的内存分配

使用IMDS的程序员在数据库模式文件中定义类,该文件被处理(通过特殊的编译器)以产生.C 文件,以及 。包含类型定义和函数原型的 H 文件。
如果使用 malloc/free 的程序是多线程的,并且线程将共享 Sensor 对象,则开发人员必须实现并发控制。使用IMDS,并发性通过事务自动管理。图 3 显示了事务如何开始 (mco_trans_start) 并获取事务句柄。
调用 Sensor_new() 会声明一些专用于新传感器对象的 IMDS 内存池。(在军事/航空航天应用中,传感器对象可以代表任何东西,从用于跟踪导弹目标的光学传感器到用于化学战防御的生物传感器或帮助导航飞机的运动传感器。Sensor_new() 返回数据库对象的句柄,通过该句柄可以写入和/或读取对象的值。相比之下,C 程序直接处理结构的字段,从而在多线程应用程序中创建并发访问控制的需求。
当 C 程序完成使用 Sensor 结构时,free() 将内存返回到堆中。当带有IMDS的代码完成时,数据库中的空间被放弃,事务结束,用于传感器对象的内存返回到专用内存池。
eXtremeDB IMDS可能会内存不足,但这会产生“数据库已满”错误消息,应用程序可以处理该错误消息。相反,由 malloc() 和 free() 引起的内存碎片和泄漏可能会破坏整个系统的稳定性。IMDS提供了一种“幕后”工作的机制,通过使用多种底层分配器类型,以更高的效率和灵活性分配和释放内存,避免malloc()和free()固有的风险。
但是,自定义内存管理器并不是IMDS所特有的。例如,用于管理传感器网络的现成代码非常适合一种称为块分配器的自定义内存管理器。虽然离散传感器值事先不知道,但这些值的大小是固定的(如 4 字节时间戳和 8 字节值),并且块分配器擅长分配预定义大小的内存块。基于堆栈的分配器对于任何计算需求都很有用,可以分为需要所有内存的第一阶段和不再需要所有内存的第二阶段。任何必须解析某些输入流的程序都符合此描述。例如,通信监视程序可能会解析文本流(口语),构建令牌树(单词或短语),然后对其执行一些后处理。这种后处理可能是决定给定的单词或短语是否与其上下文相关。
事实上,很难想象一种应用程序类型不会从面向其特定分配模式和挑战的内存管理中受益。当然,自定义内存管理为已经复杂的软件开发任务增加了另一个考虑因素。但是,进入安全关键领域的软件工程师知道,与消费者或业务应用程序开发相比,需求和风险更高。编写避免动态内存分配而是使用一个或多个自定义内存管理器的代码不太方便。但它增加了安全性和稳定性,这是安全关键系统的工程师应该接受的权衡。
审核编辑:郭婷
-
嵌入式
+关注
关注
5082文章
19126浏览量
305262 -
API
+关注
关注
2文章
1501浏览量
62027 -
C++
+关注
关注
22文章
2108浏览量
73655
发布评论请先 登录
相关推荐
泰克信号发生器在航空航天测试中的关键作用


亿纬锂能通过AS9100D航空航天体系认证
格瑞普电池诚邀您共同参与2024年土耳其国际防务与航空航天展览会

光学变焦机芯:航空航天领域的“千里眼”

在航空航天应用中使用AFE11612-SEP偏置GaN和LDMOS射频功率放大器

3D打印航空航天零部件模型3D打印定制设计服务CASAIM

高精度滚珠丝杆在航空航天技术中实现精准对接!


刚性or柔性?航空航天PCB线路板类型全揭秘

图扑数字孪生技术在航空航天方面的应用

航空航天5G智能工厂数字孪生可视化平台,推进航空航天数字化转型

激光打标机助力航空航天业实现高效、精准标识

优可测助力航空航天材料科研,推动航天事业向前发展






 工商网监
工商网监
评论