 一种快速的激光视觉惯导融合的slam系统
一种快速的激光视觉惯导融合的slam系统
本文提出了一种快速的激光视觉惯导融合的slam系统,可以分为LIO和VIO两个紧耦合的子系统。LIO直接把当前的扫描点和增量构建的地图对齐,地图点也会辅助基于直接法的VIO系统进行图像对齐。为了进一步提高vio系统的鲁棒性和准确性,作者提出了一种新的方法来剔除边缘或者在视觉中遮挡的地图点。
本文方法可以适用于机械雷达和固态雷达,并能实时的ARM和Intel的处理器上运行,作者已经开源了代码。
代码地址:https://github.com/hku- mars/FAST- LIVO
本文的主要贡献有:
一个建立在两个基于直接法的紧耦合的完整的激光视觉惯导融合的slam框架;
一个直接高效的最大程度重用LIO构建的地图的VIO框架,具体来说利用地图点和观测到的图像像素块结合后投影到一个新的图像上通过最小化光度误差来得到全部状态的位姿估计结果。
通过在视觉中使用雷达点云可以避免特征的提取和三角化,同时可以在测量层对视觉和激光雷达进行融合。
开源了这项伟大的工作。
这项工作的系统框架如下所示: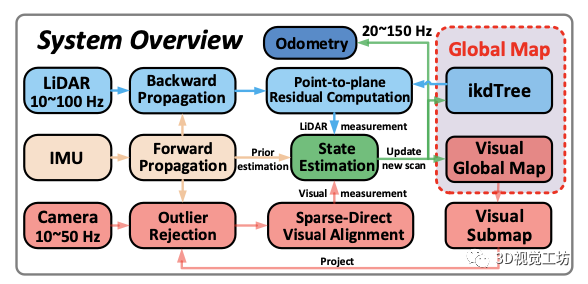
LIO:利用后向递推的方法剔除点云的运动畸变,利用去畸变的点云基于点到平面的距离进行帧到地图的匹配。
VIO:视觉基于当前的FOV从全局的视觉地图中选取当前能观测到的子地图并剔除被遮挡和深度不连续的点,然后基于稀疏光流进行帧到地图点匹配。
最后激光点到平面的残差和视觉的光度误差及IMU前向传播的值放到基于误差状态的迭代卡尔曼滤波器中得到准确的位姿,并利用该位姿把新的观测加到地图中。
状态估计: 系统利用紧耦合的ESIKF来进行状态估计,首选需要知道两个运算的定义: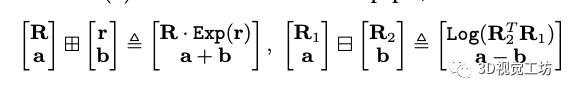
其中Exp和Log表示旋转矩阵和旋转向量之间的基于罗德里格斯公式的映射关系。
状态转移模型: 在本文的系统中假设激光雷达,相机和imu之间的时间offset是已知的,定义imu的第一帧为全局坐标系,三个传感器之间固联且外参已知。第i帧imu在离散模型下的状态转移方程为: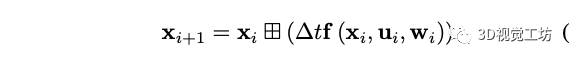
T表示imu采样的时间间隔,x是状态,u是输入,w是噪声,f的具体形式为: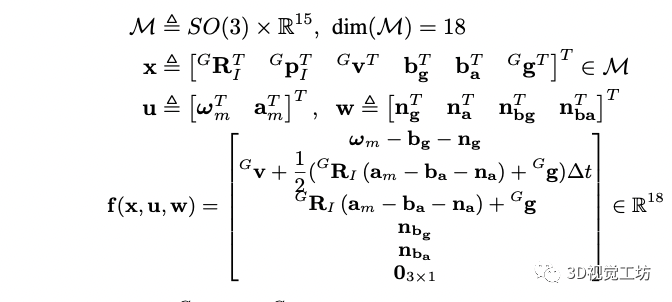
前两个状态分别表示imu在全局坐标系下的姿态和平移,最后一个表示重力在全局坐标系下的方向。 前向传播: 利用前向传播来得到i+1时刻的状态和协方差矩阵,具体形式为: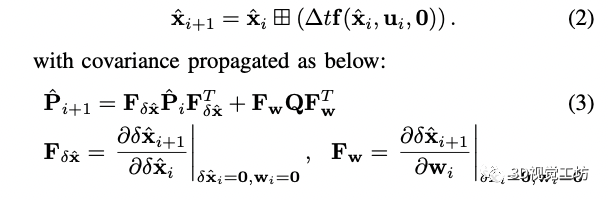
在前向传播中把噪声项设置为0,其中Q是噪声的协方差矩阵。大家应该知道下尖是后验,就是已经融合了视觉和激光雷达观测的结果,通过运动方程我们可以得到新的视觉或者激光雷达来的时候的先验的状态,然后等激光或者视觉帧来的时候进行对应的量测更新。
(这里多说一点,在做自动驾驶的时候,由于观测后的补偿量可能较大导致位姿产生小范围的跳变,所以我们一般都会把大的补偿量分成小的补偿量进行补偿,虽然这种做法不严密但是能保证位姿的平滑性,大家也可以想想有什么更好的办法)。
帧到地图的量测更新:
激光雷达的测量模型:
新的激光帧来之后首先进行点云运动畸变矫正,当进行帧到地图匹配到时候我们假设新观测的点在和他近邻的地图中的平面上(用方向向量和中心点表示),如果先验的位姿是准的可以得到如下约束: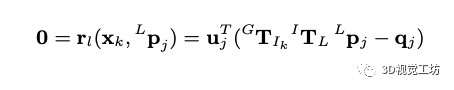
这个约束是把当前的点利用先验的位姿投影到地图上,找到最近的平面后投影点应该在平面上,所以两个点相减得到的向量为平面上的向量,和平面的法向量垂直,点乘为0。
实际上,为了找到距离该点最近的平面,利用先验的位姿把点投影到地图中找到距离该投影点最近的五个点(地图点是用ikd_tree维护的)来拟合平面,为了考虑雷达点的测量噪声,会加上一个矩阵表示每个点的权重。
2.视觉的测量模型:
当接收到一帧新的图像,我们从全局的视觉地图中提取落在当前视野内的地图点。对于地图中的点,已经被先前的帧观测过很多次,我们找到和当前观测角度相近的一帧作为参考帧,然后把地图点投影到当前帧获取地图点的光度值,应该和参考帧中的patch获取的光度值一样,以此构建残差: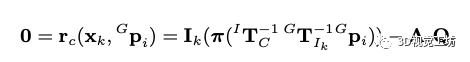
预印版没有解释A,我猜测因为是像素块进行光度匹配,所以A矩阵是权重矩阵,patch中心点权重高,周围点权重低,大家可以看代码验证一下。 基于迭代的卡尔曼滤波器更新:
通过公式3我们可以得到先验的状态和协方差的值,先验的分布可以表示为: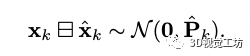
当视觉和激光的观测来的时候我们可以进行量测更新以得到状态量后验的结果: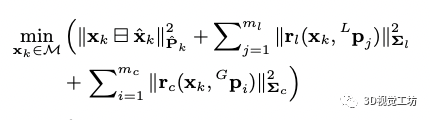
上式为非凸的函数,可以基于高斯牛顿的方法优化求解最小值,但是高斯牛顿和基于迭代的卡尔曼滤波器是等价的,参考文献的21有证明。为了保证流型的约束,在每次迭代的时候,都把误差状态参数化到切空间中(通过第一个公式定义的方法),得到的误差状态更新到状态量然后进行下次迭代直到收敛,收敛的状态和协方差用于imu的前向递推,也用于视觉地图和激光雷达地图点增量更新。
地图管理: 地图主要有LIO构建的雷达点云图和VIO构建的用patchs表示的视觉全局地图。
1.雷达地图管理: 激光雷达点云图的管理和FAST-LIO2一致,利用ikd_tree进行管理,ikd_tree提供了一些查询、插入和删除的接口,还可以根据配置参数下采样地图,同时新帧来的时候基于kd_tree的数据结构可以大大缩短最近点查找的时间(基于并行化加速后,2000个点大概0.6ms)。
2.视觉全局地图管理: 视觉的全局地图是原来观测过的雷达点云的集合,每个雷达点都对应着多个观测到这个激光点点视觉帧到多个像素块。
视觉全局地图的数据结构和更新的方法如下: 数据结构:为了快速找到落在当前视野内的地图点,我们利用体素保存视觉全局地图。
体素通过哈希表来管理,每个体素中保存点的位置,多个观测到该点的像素的patch的金字塔和每个patch金字塔的相机位姿。
视觉的子地图和外点剔除:即使体素的数量比视觉地图定的数量少的多,但是确定他们中的哪些在当前的视野中仍然非常耗时,尤其是体素数量很大时。为了解决这个问题,作者针对最近的雷达扫描的每个点基于哈希表查找这些体素。如果相机FoV和雷达大致对齐,则落在相机FoV中的地图点很可能包含在这些体素中。
因此,视觉子图可以通过这些体素包含的点进行FoV检查获得。 视觉子图可能包含在当前的图像帧中被遮挡或具有不连续深度的地图点,这会降低VIO的精度。为了解决这个问题,作者基于当前的状态量将视觉子图中的所有点投影到当前帧并在每个40x40的像素网格中保留深度最小的点。
此外,作者将当前帧雷达扫描点投影到当前帧,并检查他们的深度来检查他们是否遮挡了投影到9x9领域内的其他地图点。被遮挡的点也会被剔除。 视觉子地图更新:在对齐新的图像帧后,我们将当前图像中的patch附加到FoV内的地图点中,这样地图点就可能具有均匀分布视角的有效patch。
具体而言,作者在帧对齐后选择具有高光度误差的patch,如果距离上次添加patch超过20帧,或者当前帧中patch距离上次添加了patch的参考帧中的像素位置超过40像素,则将向地图点中添加新的patch。从当前图像中提取新的大小为8×8像素。并构建金字塔,并保存相机的位姿。
除了向地图点添加patch之外,还需要向视觉全局地图添加新的地图点。为此作者将当前图像分成40×40像素的网格,并在其上投影最近一次激光雷达扫描中的点。每个网格中具有最高梯度的投影激光雷达点将添加到视觉全局地图中,以及在其中提取的patch和相机位姿。为了避免将边缘上的激光雷达点添加到视觉地图中,跳过了具有高局部曲率的边缘点。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19583浏览量
232119 -
SLAM
+关注
关注
23文章
430浏览量
32089 -
激光视觉
+关注
关注
0文章
8浏览量
6062
原文标题:激光视觉惯导融合的slam系统
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种基于点、线和消失点特征的单目SLAM系统设计

图林科技完成B轮融资,加速激光陀螺仪与惯导系统研发
一种基于MASt3R的实时稠密SLAM系统
一种降低VIO/VSLAM系统漂移的新方法

利用VLM和MLLMs实现SLAM语义增强

激光雷达在SLAM算法中的应用综述
MG-SLAM:融合结构化线特征优化高斯SLAM算法

现代海上的电子指南针——舰艇惯导系统
一种新型光电吊舱用航姿测量系统
导远科技首次公开展示其自主研发的新一代MEMS惯导芯片







 工商网监
工商网监
评论