 深度解析MLPerf竞赛Resnet50训练单机最佳性能
深度解析MLPerf竞赛Resnet50训练单机最佳性能
MLPerf是一套衡量机器学习系统性能的权威标准,于2018年由谷歌、哈佛、斯坦福、百度等机构联合发起成立,每年定期公布榜单成绩,它将在标准目标下训练或推理机器学习模型的时间,作为一套系统性能的测量标准。MLPerf训练任务包括图像分类(ResNet50)、目标物体检测(SSD)、目标物体检测(Mask R-CNN)、智能推荐(DLRM)、自然语言处理(BERT)以及强化机器学习(Minigo)等。最新的1.0版本增加了两项新的测试项目:语音识别(RNN-T)和医学影像分割(U-Net3D)。
本文将着重讨论其中的图像分类模型Resnet50。
ResNet是残差网络,该系列网络被广泛用于目标分类等领域,并作为计算机视觉任务主干经典神经网络的一部分,是一个典型的卷积网络。ResNet50网络结构如下图,首先对输入做卷积操作,之后经过4个残差模块,最后进行一个全连接操作用于分类任务,ResNet50包含50个卷积操作。
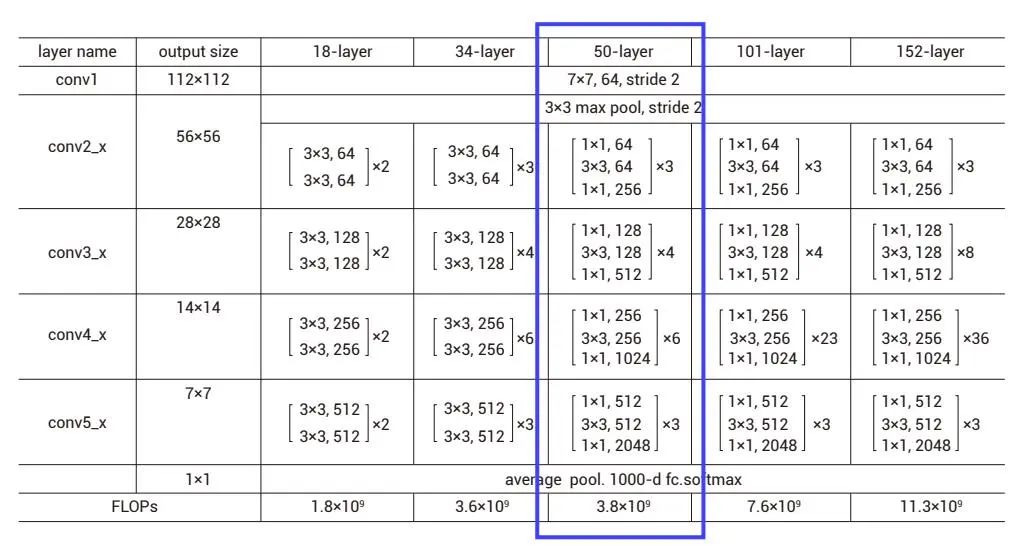
图1 ResNet网络结构▲

图2 ResNet34网络结构▲
来源:Deep Residual Learning for Image Recognition
作者:何恺明等
在MLPerf最早版本V0.5中,就包含Resnet50训练任务。下图是历次MLPerf 训练竞赛Resnet50的单机最优性能。在MLPerf V0.7训练基准测试中,浪潮AI服务器NF5488A5在33.37分钟内完成ResNet50训练,在所有提交的单服务器性能成绩中名列榜首,比同类配置服务器快16.1%。而在最新的MLPerf 训练V1.0榜单中,浪潮AI服务器NF5688M6进一步将Resnet50单机训练提速到27.38分钟,耗时较V0.7缩短了17.95%。
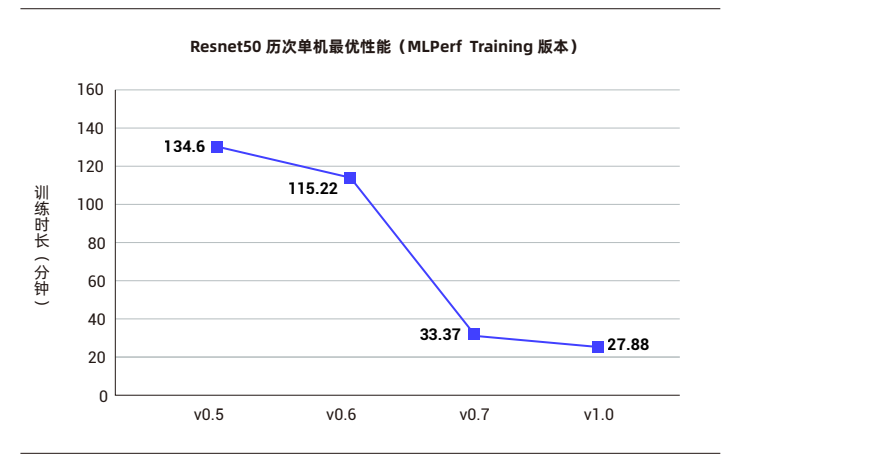
图3 历次MLPerf训练测试Resnet50单机最优性能▲
性能的一次次突破,得益于硬件的发展和软件的更新及优化。本文将深度解析取得这一成绩背后的原因,谈谈Resnet50对计算平台的需求以及如何提升训练速度。
ResNet50训练流程简介
在MLPerf训练V1.0测试中,Resnet50使用的数据集是包含128万图片的ImageNet2012(注:数据下载需要注册),训练的目标精度是75.9%,共需运行5次。厂商提交的成绩是训练模型达到目标精度所花费的时间(以分钟为单位),值越小则表示性能越好。去掉一个最差性能和一个最优性能,其余3次的平均值为最终成绩。
我们来看看Resnet50模型训练的流程。首先,需要从硬盘上读取训练集,进行解码,然后对图像进行预处理,处理后的数据送入训练框架进行训练,经过若干个epoch后得到满足精度要求的模型。
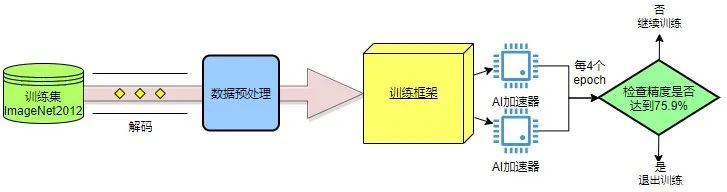
图4 Resnet50模型训练流程▲
硬件平台选取
在Resnet50训练中,硬件及设备平台的选取至关重要。其中磁盘读取性能、CPU运算性能、内存到显存的传输性能以及GPU运算性能对训练速度的影响都比较大:磁盘读取性能直接决定训练数据供给的速度;在引入DALI后,CPU的性能、CPU到GPU的传输带宽以及GPU的性能共同决定了数据前处理的速度;而训练中的前向推理和反向传播由GPU的性能及GPU之间的数据传输带宽决定。上述几个硬件就如同工厂流水线上的几名工人,任何一名工人的处理速度跟不上就会导致堆积,成为性能瓶颈,影响最终结果。因此这几个重要部分不能有明显的短板。
此次MLPerf评测浪潮选取了NF5688M6和NF5488A5服务器作为Resnet50的训练平台,不仅保证上述关键部件性能十分强劲,而且把它们很好地整合在一起,能更好地发挥它们的性能,满足了模型训练对硬件的性能要求,从而能快速地完成训练任务。
NF5688M6在6U空间内支持2颗Intel最新的Ice Lake CPU和8颗NVIDIA最新的NVSwitch全互联GPU。支持PCIe Gen4.0高速互联,实现CPU和GPU之间数据高速传输。同时采用完全风道独立,有效避免回流产生,实现风冷支持8颗 GPU高环温下稳定工作。在本次MLPerf V1.0训练测试中,NF5688M6获得了ResNet50、DLRM和SSD三项任务的单机训练性能第一。
NF5488A5在4U空间内实现8颗高性能NVIDIA GPU液冷散热,搭载2颗支持PCIe4.0的AMD EPYC 7742 处理器,能够为AI 用户提供超强单机训练性能和超高数据吞吐。NF5488A5在MLPerf V0.7基准测试中创下Resnet50训练任务最佳单服务器性能成绩,在MLPerf V1.0榜单中获得了BERT任务的单机训练性能第一。
训练调优方法
Resnet50模型的训练时长主要受两大因素的影响:一是训练模型到目标精度的步数,也就是需要多少轮可以达到目标精度,在其它性能相同的情况下步数越短则训练时间越短,这部分需要找出一组超参数让步数足够少;二是图4所示的数据读取、数据预处理、训练等各个步骤的处理速度。Resnet50的训练数据为128万张ImageNet2012图片数据集,训练过程对传输带宽和计算能力的要求都很高。正如木桶理论所说,模型训练速度是由流水线上最慢的部分决定,因此需要对流水线上的每一个步骤做分析,特别是着重分析整个流水线上的瓶颈,有针对性地去做优化。
从这两大因素入手,浪潮主要采用了以下调优方法:
对学习率、batch size、优化器等超参数进行调试,将ResNet50模型收敛的步数从41降为35,带来了15%左右的性能提升;
通过优化DALI,使用GPU资源加速解码和数据处理环节,实现了1%左右的性能提升;
使用NCCL提升多GPU卡之间通信效率,加速训练环节,性能提升0.1%左右。
下面分别按照训练流程进行详述。
| 训练集读取
训练集是官方指定的。需要注意是读取图像带来的开销,如前所述,这个取决于磁盘读取的速度和传输带宽。好的磁盘自然能带来更快的速度,另外通过组Raid 0 磁盘阵列也能带来读取速度的提升。我们曾在两种不同的磁盘上使用同样的Raid 0磁盘阵列,测试结果的训练时长差异达到5‰左右,所以磁盘的选择是很重要的。
| 解码和数据处理
读取数据后便是解码和数据处理,通常它们是一起进行的。图像解码会比较耗时,常常会成为性能瓶颈,一般的处理方式只能利用CPU资源来进行图像解码,性能会受到极大的制约,我们选择的是DALI(NVIDIA Data Loading Library)框架,这是一款高度优化用来加速计算机视觉深度学习应用的执行引擎,可以利用GPU的资源来做图像解码和预处理,号称可以比原框架带来4倍的性能提升。使用DALI来做预处理处理是个不错的选择,大家可以试试。
选定预处理的方法后,需要对其做优化,充分利用它的优势,使之适用于我们的系统和数据。首先,我们先找出预处理数据的极限,通过设置训练数据为模拟的拟合数据,这样可以抛开数据读取以及预处理的开销,评测只有训练开销时的吞吐率,后面要做的就是调整DALI参数,让真实数据的吞吐率接近拟合数据的吞吐率。
我们可以从以下几个方面入手:
1. DALI的计算分配:DALI可以把预处理的计算按指定的比例分配到CPU和GPU上,如果分配给GPU的比例小了则不能充分利用GPU的性能,如果大了则会挤占后面的训练资源;
2. DALI的处理线程:这个值大了,会占用资源,并让一些线程处于等待状态,这个值小了,不能充分利用资源;
3. ALI的数据预取量:值过小会让后面的处理等待,值过大会占用过多显存存储和计算资源,甚至会耗尽显存;
4. 使用融合函数:采用ImageDecoderRandomCrop函数,把解码和随机裁剪放在一起做,通常会比分开做性能提升不少。
前3个参数值的选取需要针对不同硬件设备和模型进行测试,找出一个最优组合,通过这个部分的优化,可以带来大概7‰左右的性能提升。而采用融合函数通常能带来1%左右的性能提升。
上述DALI代码关键就是实现一个自己的Pipeline类,ResNet50的数据前处理关键代码参考如下:
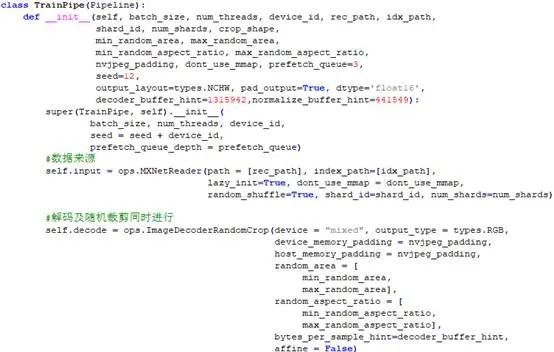
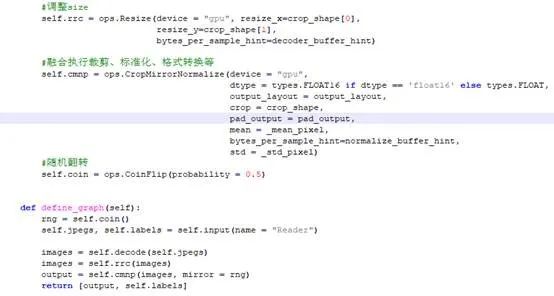
图6 ResNet50数据前处理关键代码▲
| 训练框架选取
目前训练框架有很多,如tensorflow、pytorch、mxnet等。不同的模型在不同的框架下有不一样的性能表现,通过比较,我们发现mxnet框架在处理resnet50模型的训练上有较大的优势。
另外,使用多块GPU进行训练时,各卡之间有大量的数据传输,各个框架会采用horovod或者直接采用NCCL来进行分布式的训练,而horovod本质上也是调用NCCL进行的数据传输。在MLPerf的示例代码中有的框架会提供默认的NCCL参数选择,这在不同的硬件设备中可能会有所不同,例如在最新的NVSWITCH架构中MAXCHANNEL数为32,而在之前的NVLINK架构中默认值为16最佳。在大部分的情况下,NCCL内部的默认值即可满足其要求, 但仍要注意其传入参数对传输速度的影响。另外经测试最新的NCCL版本,对于不同的硬件设备可能不是速度最快的版本,可通过NCCL_TEST进行测试选择,这里不再展开说明。
| 超参数调优
训练中的一个关键因素就是超参数的调试,一组好的超参数能让模型经过更少的epoch就收敛,自然会让性能提升。试想一下如果两个厂商的训练吞吐率一样,但其中一家的模型要10个epoch才能收敛到目标精度,而另一家的模型可以8个epoch就收敛,相当于2位选手以同样的速度下山,其中一位选手找到的路需要走10公里,另一位找到的路只需要走8公里,那毫无疑问走8公里路的占有明显优势,能更快到达终点。所以挑选一组合适的超参数能事半功倍。实际上,MLPerf Training为了避免走“错路”带来的不公平,特意制定了超参数借用规则,让大家借一条“路”再跑一次,在同一个赛道下的结果才公平。
当然,要找这样一条“路”是不容易的,下面给出一些超参数调试的小技巧:
学习率(learning rate):学习率对收敛速度和精度都有影响。而调整学习率也是让人抓狂的事情,经常出现梯度不收敛。一般对于学习率等超参数采用先粗调、再微调的策略。其中在粗调过程中学习率先以10的倍数进行调整,如选取0.01、0.1、1等值进行尝试,等学习率基本固定后,再进行精调,可以在基准值上每次以10%的变化量进行调整。
batch size:一般来讲增大batch size可以提高训练速度,同时也可以提高AI加速器的利用率,但稍有不慎来个out of memory就可以终止你增大该值的念想,另外过大的batch size也会带来精度的下降。那么选一个小batch size是否就可以了呢?经实验验证,过小的batch size也会导致精度下降,所以该值的选取,也需要调试。此外,batch size和learning rate也会相互影响,一般操作是,在增大batch size的同时,也应对应的增大learning rate。
优化器:一般在分类模型中,最常用的优化器为随机梯度下降SGD。虽然adam等优化器可以获取到更快的速度,但是经常会出现精度下降的问题。除此之外还有LARS(Layer-wise Adaptive Rate Scaling:https://arxiv.org/abs/1708.03888)优化器,这是MLPerf中各个参赛厂家普遍使用的优化器。LARS的优化器的公式如下:
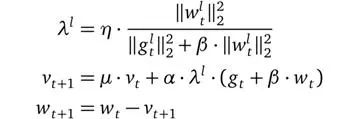
LARS是SGD 的有动量扩展,可以适应每层的学习率,核心是让网络的每个层根据自己的情况动态的调整学习率,作用是可以有效缓解在较大batch size训练的前期由于学习率太大导致的不稳定问题。
按照上述的方法调试超参数,最终我们将ResNet50模型收敛的epoch次数从41降为35,带来了15%左右的性能提升,看来正确的“路”效果很明显,超参数带来的性能提升不容小觑。
总之,影响训练性能的因素有很多。本文主要从硬件平台和软件优化的角度,以MLPerf训练V1.0榜单中的ResNet50模型为例,从数据处理、训练框架、超参数等方面来提升训练速度,取得了不错的效果。浪潮优化代码已共享至Github(附1)。如果各位有兴趣可以试一试,希望能帮助你提升模型训练速度。
展望
MLPerf竞赛经过3年多时间的发展,已经逐渐进入成熟期,其模型的选取也紧跟时代潮流,为评估各类AI计算平台在实际应用场景中的性能提供了权威有效的基准。MLPerf是一个开放社区,很多厂商将优化方法回馈至社区,推动AI技术的共同进步。如浪潮已将在MLPerf V0.7中用到的ResNet收敛性优化方案共享给社区成员,得到广泛采纳并应用到本次V1.0测试中。可以预见,随着谷歌、英伟达、英特尔、浪潮、戴尔等众多主流芯片及系统厂商持续参与MLPerf,并贡献软硬件系统优化方法,未来AI计算平台的性能将会得到进一步提升,为AI技术在更多应用场景的落地打下坚实的基础。
* 附:
1.浪潮代码:
https://github.com/mlcommons/training_results_v1.0/tree/master/Inspur/benchmarks/resnet/implementations/mxnet
按照下面的步骤来搭建环境:
a. 下载以上代码
b. 按照代码中README.MD中的描述下载所需数据,并参考附2里的方法对数据进行预处理,生成Mxnet格式的数据集
c. 进入mxnet目录,通过docker构建所需的image,可参考以下代码:
cd ./benchmarks/resnet/implementations/mxnet/docker build --pull -t image_name:image_version .
d. Image构建完成后,修改设置参数的配置文件config_NF5688M6.sh,修改参数为适合你的系统的值(填入按照后面的调优方法去找出优化后的值)
e. 至此软件环境构建完成,可以开始执行训练, 比如我们使用的系统是“NF5688M6”:
source config_5688M6.sh
DGXSYSTEM="NF5688M6"
CONT=image_name:image_version
DATADIR=/path/to/preprocessed/data
LOGDIR=/path/to/logfile ./run_with_docker.sh
接下来等着训练结束,通过查找日志里的“run_stop”和“run_start”记录的时间点就可以计算出整个训练时间(单位是秒)。
2.数据预处理:
https://github.com/NVIDIA/DeepLearningExamples/blob/master/MxNet/Classification/RN50v1.5/README.md#prepare-dataset
审核编辑:汤梓红
-
服务器
+关注
关注
12文章
9415浏览量
86464 -
浪潮
+关注
关注
1文章
471浏览量
24044 -
机器学习
+关注
关注
66文章
8460浏览量
133400 -
MLPerf
+关注
关注
0文章
35浏览量
671
原文标题:深度解析MLPerf竞赛Resnet50训练单机最佳性能
文章出处:【微信号:浪潮AIHPC,微信公众号:浪潮AIHPC】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习与图神经网络学习分享:CNN经典网络之-ResNet
YOLOv6中的用Channel-wise Distillation进行的量化感知训练
【KV260视觉入门套件试用体验】四、学习过程梳理&DPU镜像&Resnet50
【KV260视觉入门套件试用体验】KV260系列之Petalinux镜像+Resnet 50探索
索尼发布新的方法,在ImageNet数据集上224秒内成功训练了ResNet-50
百度大脑EdgeBoard计算卡基于Resnet50/Mobile-SSD模型的性能评测
浪潮发布AI服务器NF5488A5,计算性能提升234%
浪潮信息MLPerf单机系统测试:7项性能第一
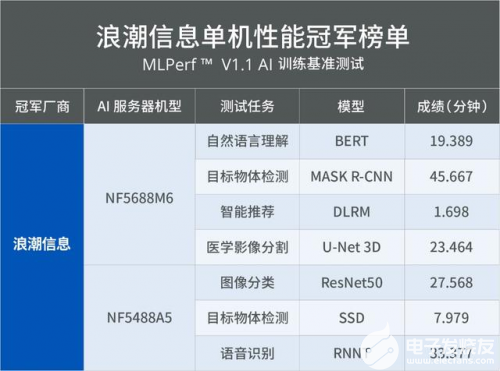
MLPerf训练性能测试榜单发布,浪潮信息刷新多项纪录
【R329开发板评测】实机测试Resnet50

如何使用框架训练网络加速深度学习推理

NVIDIA 与飞桨团队合作开发基于 ResNet50 的模型示例
MLPerf世界纪录技术分享:优化卷积合并算法提升Resnet50推理性能
基于改进ResNet50网络的自动驾驶场景天气识别算法






 工商网监
工商网监
评论