 使用无监督学习和合成数据作为数据增强方法来分类异常
使用无监督学习和合成数据作为数据增强方法来分类异常
导读
创建异常检测模型,实现生产线上异常检测过程的自动化。在选择数据集来训练和测试模型之后,我们能够成功地检测出86%到90%的异常。
介绍
异常是指偏离预期的事件或项目。与标准事件的频率相比,异常事件的频率较低。产品中可能出现的异常通常是随机的,例如颜色或纹理的变化、划痕、错位、缺件或比例错误。
异常检测使我们能够从生产流程中修复或消除那些处于不良状态的部件。因此,由于避免生产和销售有缺陷的产品,制造成本降低了。在工厂中,异常检测由于其特点而成为质量控制系统的一个有用工具,对机器学习工程师来说是一个巨大的挑战。
不推荐使用监督学习,因为:在异常检测中需要内在特征,并且需要在完整数据集(训练/验证)中使用少量的异常。
另一方面,图像比较可能是一个可行的解决方案,但标准图像处理多个变量,如光线、物体位置、到物体的距离等,它不允许与标准图像进行像素对像素的比较。在异常检测中,像素到像素的比较是不可或缺的。
除了最后的条件外,我们的建议包括使用合成数据作为增加训练数据集的方法,我们选择了两种不同的合成数据,随机合成数据和相似异常合成数据。(详见数据部分)
这个项目的目标是使用无监督学习和合成数据作为数据增强方法来分类异常 — 非异常。
背景研究
异常检测与金融和检测“银行欺诈、医疗问题、结构缺陷、设备故障”有关(Flovik等,2018年)。该项目的重点是利用图像数据集进行异常检测。它的应用是在生产线上。在项目开始时,我们熟悉了自动编码器在异常检测中的功能和架构。作为数据计划的一部分,我们研究了包括合成噪声图像和真实噪声图像的重要性(Dwibedi et al, 2017)。
数据计划是这个项目的重要组成部分。选择一个数据集,有足够的原始图像和足够的真实噪声的图像。同时使用合成图像和真实图像。在处理真实图像时,这些数据需要对目标有全覆盖,但是在尺度和视角方面无法完全获得。“……要区分这些实例需要数据集对对象的视角和尺度有很好的覆盖”(Dwibedi et al, 2017)。
合成数据的使用允许“实例和视角的良好覆盖”(Dwibedi et al, 2017)。合成图像数据集的创建,包括合成渲染的场景和对象,是通过使用Flip Library完成的,这是一个由LinkedAI创建的开源python库。“剪切,粘贴和学习:非常简单的合成实例检测”,通过这些数据的训练和评估表明,使用合成数据集的训练在结果上与在真实图像数据集上的训练具有可比性。
自动编码器体系结构“通常”学习数据集的表示,以便对原始数据进行维数缩减(编码),从而产生bottleneck。从原始的简化编码,产生一个表示。生成的表示(重构)尽可能接近原始。
自动编码器的输入层和输出层节点数相同。“bottleneck值是通过从随机正态分布中挑选出来的”(Patuzzo, 2020)。在重构后的输出图像中存在一些重构损失(Flovik, 2018),可以通过分布来定义原始图像输入的阈值。阈值是可以确定异常的值。
去噪自动编码器允许隐藏层学习“更鲁棒的滤波器”并减少过拟合。一个自动编码器被“从它的一个损坏版本”来训练来重建输入(去噪自动编码器(dA))。训练包括原始图像以及噪声或“损坏的图像”。随着随机破坏过程的引入,去噪自编码器被期望对输入进行编码,然后通过去除图像中的噪声(破坏)来重建原始输入。
用去噪自编码器提取和组合鲁棒特征,去噪自编码器应该能够找到结构和规律作为输入的特征。关于图像,结构和规律必须是“从多个输入维度的组合”捕获。Vincent等(2020)的假设引用“对输入的部分破坏的鲁棒性”应该是“良好的中间表示”的标准。
在这种情况下,重点将放在获取和创建大量原始和有噪声图像的能力上。我们使用真实数据和合成数据创建了大量的图像来训练我们的模型。
根据Huszar(2016)的说法,扩张卷积自动编码器“支持感受野的指数扩展,而不丢失分辨率或覆盖范围。“保持图像的分辨率和覆盖范围,对于通过扩大卷积自动编码器重建图像和使用图像进行异常检测是不可或缺的。这使得自动编码器在解码器阶段,从创建原始图像的重建到更接近“典型”自动编码器结构可能产生的结果。
Dilated Convolutional Autoencoders Yu et al.(2017),“Network Intrusion Detection through Stacking Dilated Convolutional Autoencoders”,该模型的目标是将无监督学习特征和CNN结合起来,从大量未标记的原始流量数据中学习特征。他们的兴趣在于识别和检测复杂的攻击。通过允许“非常大的感受野,而只以对数的方式增加参数的数量”,Huszar (2016),结合无监督CNN的特征学习,将这些层堆叠起来(Yu et al., 2017),能够从他们的模型中获得“卓越的性能”。
技术
Flip Library (LinkedAI):https://github.com/LinkedAi/flip
Flip是一个python库,允许你从由背景和对象组成的一小组图像(可能位于背景中的图像)中在几步之内生成合成图像。它还允许你将结果保存为jpg、json、csv和pascal voc文件。
Python Libraries
在这个项目中有几个Python库被用于不同的目的:
可视化(图像、指标):
OpenCV
Seaborn
Matplotlib
处理数组:
Numpy
模型:
Keras
Random
图像相似度比较:
Imagehash
PIL
Seaborn (Histogram)
Weights and Biases
Weights and bias是一个开发者工具,它可以跟踪机器学习模型,并创建模型和训练的可视化。它是一个Python库,可以作为import wandb导入。
它工作在Tensorflow, Keras, Pytorch, Scikit,Hugging Face,和XGBoost上。使用wandb.config配置输入和超参数,跟踪指标并为输入、超参数、模型和训练创建可视化,使它更容易看到可以和需要更改的地方来改进模型。
模型&结构
我们基于当前的自动编码器架构开始了我们的项目,该架构专注于使用带有卷积网络的图像(见下图)。经过一些初步的测试,基于研究(参见参考资料)和导师的建议,我们更改为最终的架构。
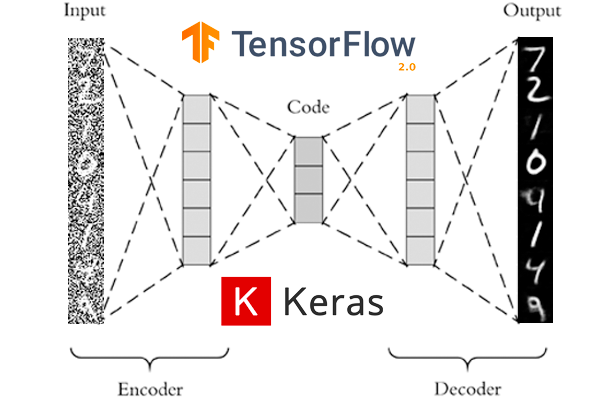
自编码器的典型结构
使用扩张特征
扩张特征是一种特殊的卷积网络,在传统的卷积核中插入孔洞。在我们的项目中,我们特别的对通道维度应用了膨,不影响图像分辨率。
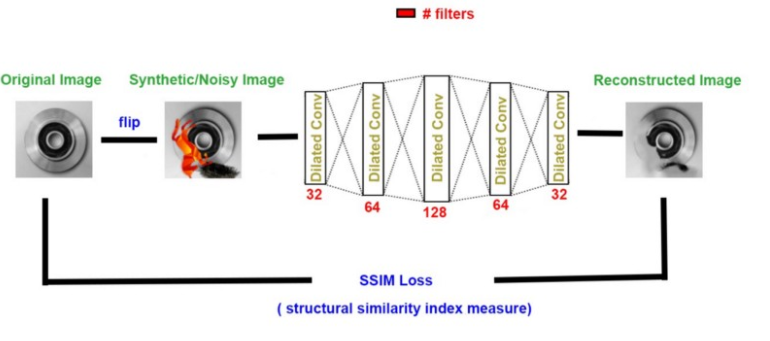
最终的结构
图像相似度
这个项目的关键点之一是找到一个图像比较的指标。利用图像比较度量对模型进行训练,建立直方图,并计算阈值,根据该阈值对图像进行异常和非异常的分类。
我们从逐个像素的L2欧氏距离开始。结果并不能确定其中的一些差异。我们使用了带有不同散列值(感知、平均和差异)的Python Imagehash库,对于相似的图像,我们得到了不同的结果。
我们发现SSIM(结构相似度指数度量)度量为我们提供了一对图像之间相似度的度量,此外,它是Keras库的一个内置损失。
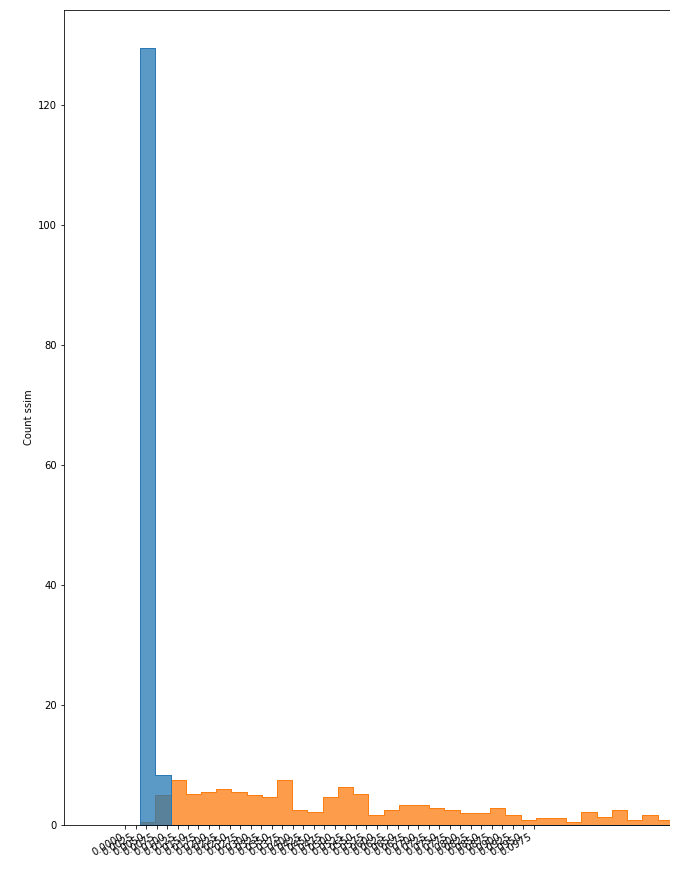
直方图
在对模型进行训练和评估后,利用其各自的数据集,对重建后的图像和原始图像之间的相似度进行识别。当然,由于原始图像的多样性(如,大小,位置,颜色,亮度和其他变量),这种相似性有一个范围。
我们使用直方图作为图的表示,以可视化这个范围,并观察在哪个点会有不同的图像。
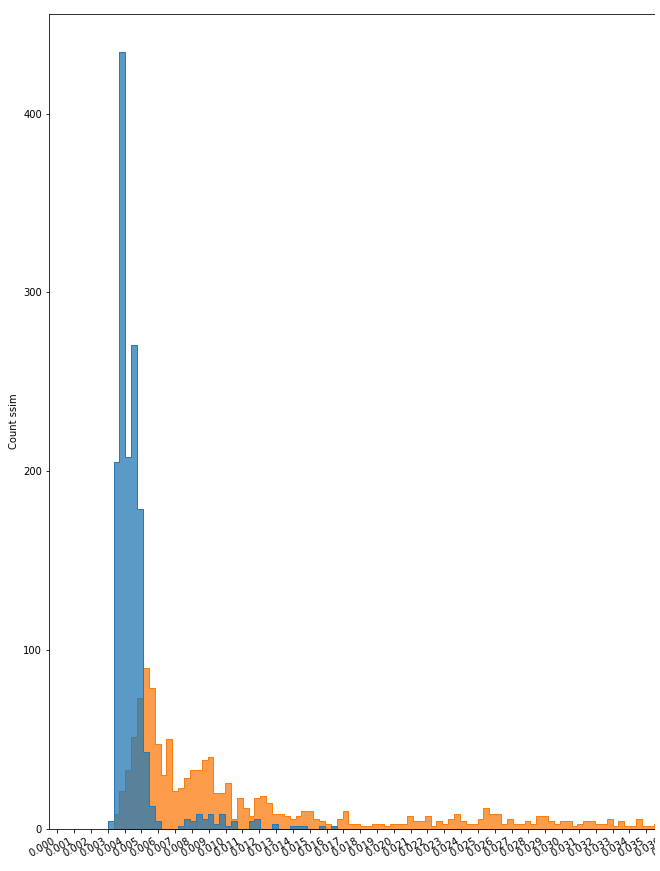
直方图的例子
数据
使用的数据从Kaggle下载:表面裂纹检测数据集:https://www.kaggle.com/arunrk7/surface-crack-detection和铸造产品质量检查图像数据:https://www.kaggle.com/ravirajsinh45/real-life-industrial-dataset-of-casting-product?select=casting_data。
第一个是裂缝数据集,包含20,000张负样本墙图像(无裂缝)和20,000张正样本墙图像(有裂缝)。在这种情况下,裂缝被认为是异常的。所有数据都是227x227像素的RGB通道。下面显示了每个组的示例。

我们从没有异常的组中选取了10,000张图像来生成不同的合成数据集。然后合成的数据集被分为两种类型:一种是带有类似异常的噪声(51张图像是用Photoshop创建的),另一种是使用水果、植物和动物等随机物体。所有用作噪声的图像都是png格式的,背景是透明的。下面是用于模型训练的两种类型的数据集的一些例子。

第二个数据集,cast数据集分为两组,一组为512x512像素的图像(有异常的781张,无异常的519张),另一组为300x300像素的图像(有异常的3137张,有异常的4211张)。
所有图像都有RGB通道。使用的是300 x 300像素的图像。后者,来自Kaggle,91.65%的数据被分为训练,其余的测试。对于该数据集,异常包括:边缘碎片、划痕、表面翘曲和孔洞。下面是一些有和没有异常的图像示例。

我们使用1,000张属于训练组的无缺陷图像来生成合成数据数据集。
在前面的例子中,我们创建了两种类型的数据集:一种带有类似于异常的噪声(51张图像是用Photoshop创建的),另一种带有随机对象的噪声,如动物、花朵和植物(裂缝数据集中使用的相同的80张图像)。
下面是一些在模型训练中使用的图像示例。

所有合成数据都是使用Flip库创建的。在每个生成的图像中,选择两个对象并随机放置。
对象应用了三种类型的转换:翻转、旋转和调整大小。生成的图像保存为jpg格式。项目使用的数据集如下表所示:
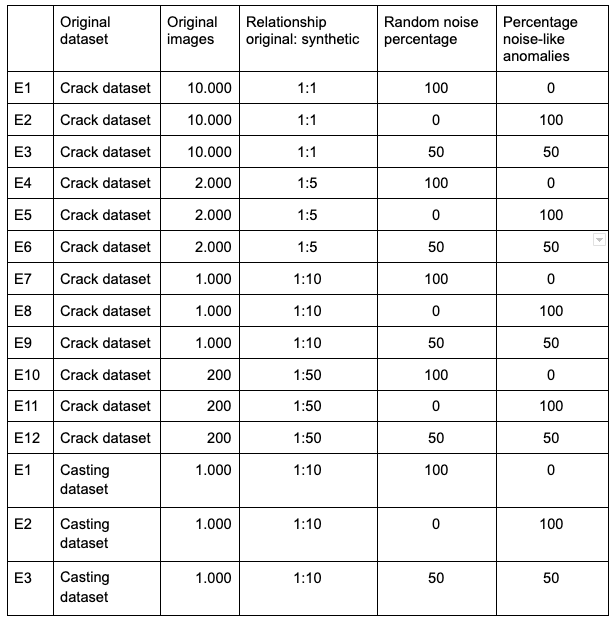
实验
根据上述表格说明,我们的主要目的是研究数据集的哪些变化可能呈现最好的结果,我们用这些数据和获得的结果训练了模型(见下面的图表)。
对于每个数据集,我们评估了几个指标,如(SSIM)损失、召回、精度、F1和精度。在每一次实验中,我们将评估代表这组噪声图像和重建图像之间图像相似性的直方图。
为了跟踪和比较我们的结果,我们使用了library Weight & bias,它允许一种简单的方式来存储和比较每个实验的结果。

训练
为了在我们的环境中保持少量的变量,我们决定总是使用一个有1000个样本的数据集,而不管真实数据和合成数据之间的关系。
在算法中,我们将各自的数据集分割为95%进行训练,5%进行测试结果。除此之外,我们的评估只使用了真实的数据。

评估和结果
下面是一些实验的主要结果。你可在以下连结找到所有的结果:
裂缝数据集:https://wandb.ai/heimer-rojas/anomaly-detector-cracks?workspace=user-
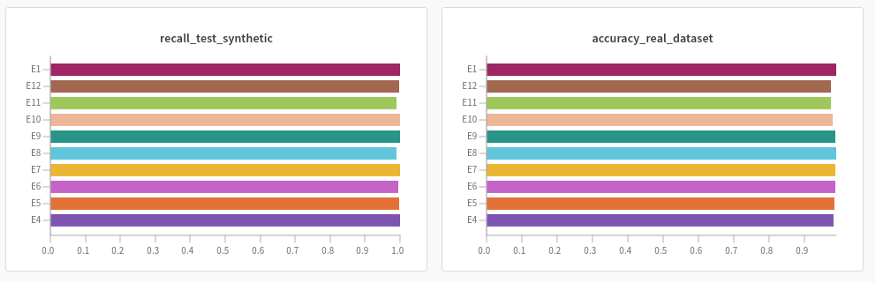
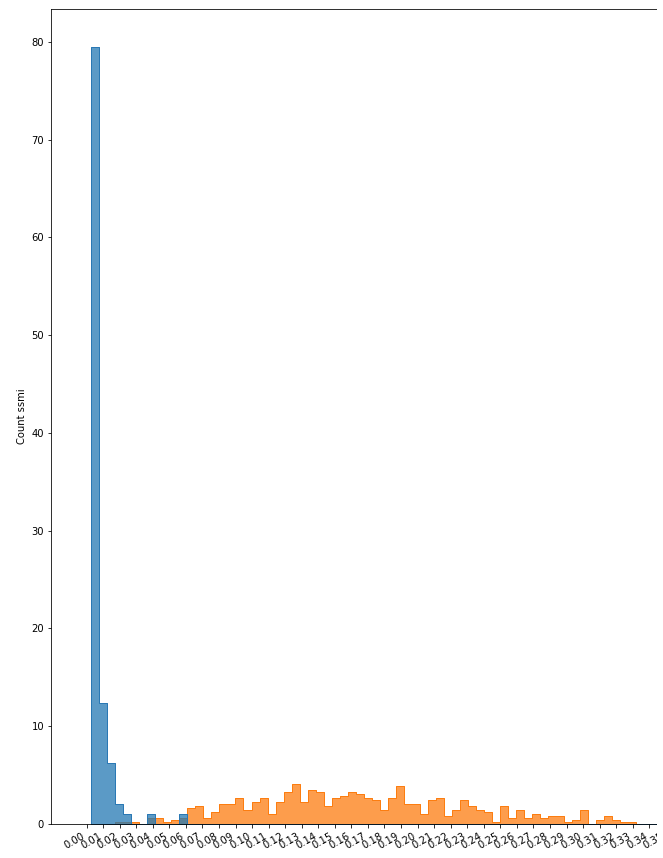
裂缝直方图

裂缝数据集的异常检测
对于裂纹数据集,实验结果也很好(91% ~ 98%),实验之间没有显著差异。与无异常的图像相比,其行为主要取决于裂纹大小和颜色等变量。
铸造工件数据集:https://wandb.ai/heimer-rojas/anomaly-detector-cast?workspace=user-heimer-rojas
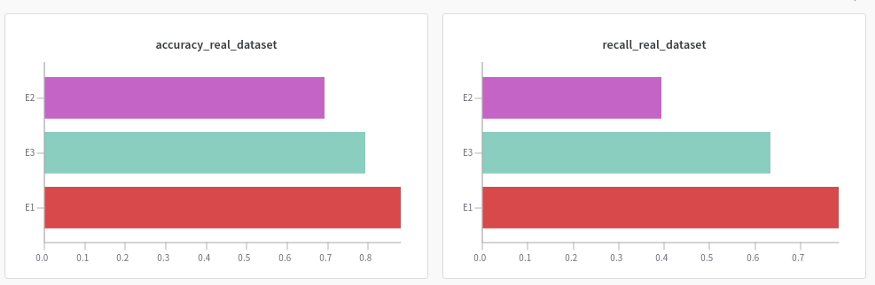
铸造工件数据集的准确率和召回率
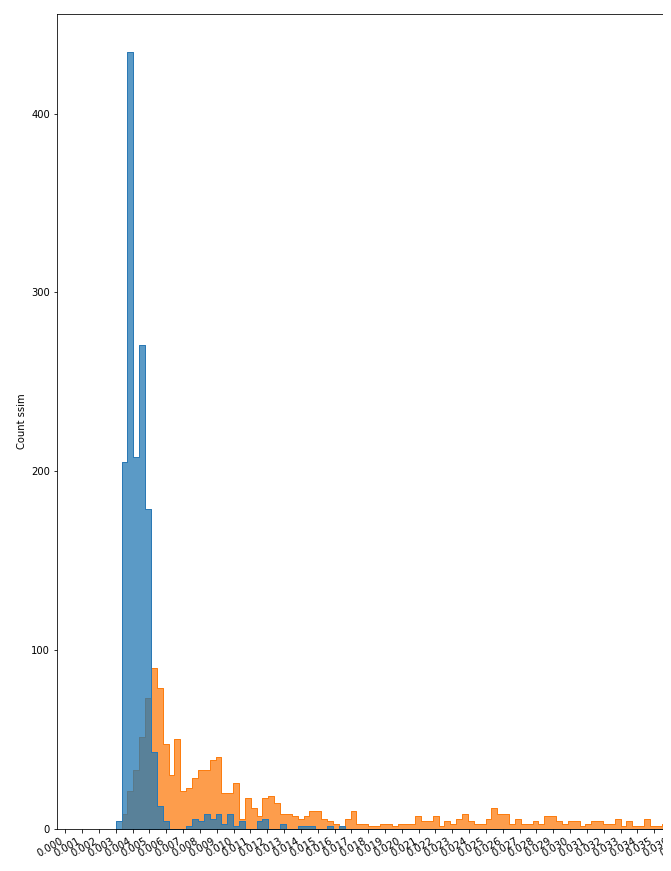
铸造件E1&E3

铸造件数据集的异常检测
挑战
训练时间长,在谷歌Colab和专业版中使用GPU训练。
通过上传压缩后的zip格式的数据来解决长时间的数据加载问题,这样每个数据集上传一个文件,大大减少了时间。
最初的提议是使用哥伦比亚汽车生产线的数据集,不幸的是,正样本和负样本图像的质量和数量都不足以创建一个合适的机器学习模型。这种情况促使我们决定使用Kaggle的数据集,与生产线生产的条件类似。
每个数据集在异常情况下的可视化差异是不同的,需要考虑正常的图像结构,如图像的颜色、亮度等内在特征
需要人类的专业知识来根据真实数据或合成数据的阈值选择适当的阈值。这可能要视情况而定。
讨论
实现一个真正的机器学习项目需要几个步骤,从想法到模型的实现。这包括数据集的选择、收集和处理。
在使用图像的项目中有“调试脚本”是很重要的。在我们的例子中,我们使用了一个允许我们可视化的脚本:原始数据集、新的合成图像和自编码器去噪之后的图像,使我们能够评估模型的性能。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3638浏览量
134426 -
OpenCV
+关注
关注
31文章
634浏览量
41337 -
python
+关注
关注
56文章
4792浏览量
84628
原文标题:详解如何用深度学习实现异常检测/缺陷检测
文章出处:【微信号:机器视觉沙龙,微信公众号:机器视觉沙龙】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
适用于任意数据模态的自监督学习数据增强技术

基于transformer和自监督学习的路面异常检测方法分享

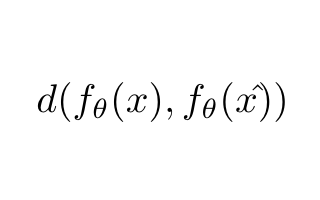






 工商网监
工商网监
评论