 为什么基于学习的VO很难超过传统VSLAM?
为什么基于学习的VO很难超过传统VSLAM?
0. 笔者个人体会
深度学习在其他CV领域可以说已经完全碾压了传统图像算法,例如语义分割、目标检测、实例分割、全景分割。但是在VSLAM领域,似乎还是ORB-SLAM3、VINS-Fusion、DSO、SVO这些传统SLAM算法占据领导地位。那么这背后的原因是什么?基于深度学习的VO目前已经发展到了什么程度?
本文将带领读者探讨基于学习的VO难以训练的真正原因,并分析几个目前SOTA的学习VO,深入浅出理解基于学习的VO和传统VSLAM算法之间的区别是什么。当然笔者水平有限,如果有不同见解欢迎大家一起讨论,共同学习!
1. 为什么基于学习的VO很难超过传统VSLAM?
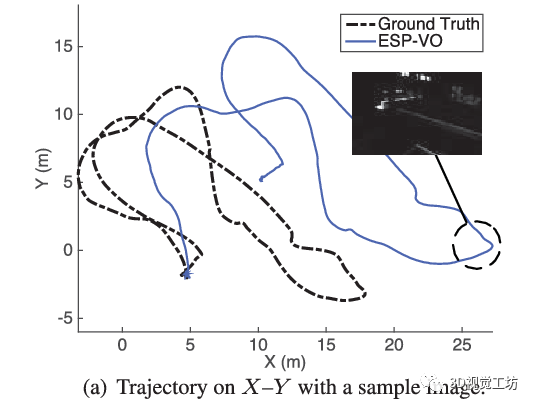
最早的基于学习的VO应该是2017年ICRA论文“DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks”,这个架构也非常直观,就是将图片序列利用CNN提取特征,然后借助RNN输出位姿。之后它们团队也在2018年ICRA发表了“End-to-end, sequence-to-sequence probabilistic visual odometry through deep neural networks”,提出了DeepVO的改进版本ESP-VO,但可以看出它们在一些场景的效果还是不太好的。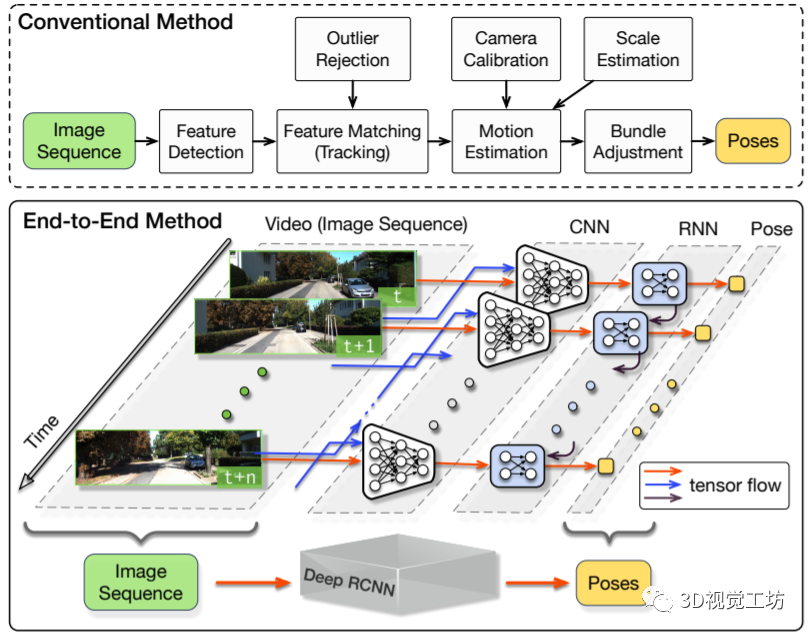
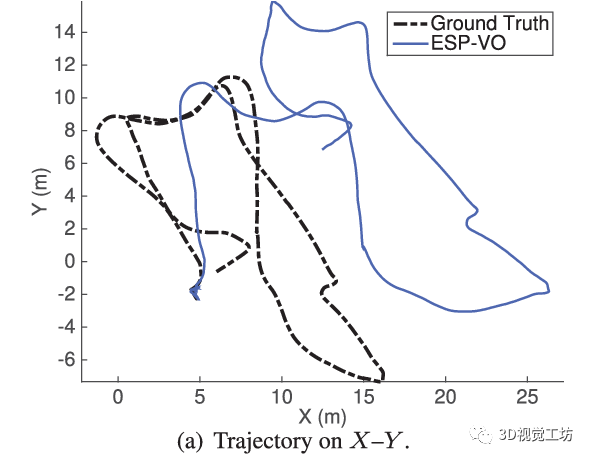
我认为基于学习的VO之所以失败,主要有六点原因。
首先就是数据量的问题,深度学习是非常吃数据的。
模型越大,想让网络权重收敛所需的数据规模也就越大。近些年随着Transformer的横空出世,深度网络的参数量几乎是呈几何倍数增长,动不动就出现上亿参数的大模型。
但目前VSLAM的评估场景主要是KITTI (22个序列)、EuRoC (11个序列)和TUM (24个序列)这三个数据集。
即使是三个数据集加起来,也没有ImageNet这一个数据集大。因此想使用深度学习直接定位建图的话,模型根本喂不饱,训练就显得非常困难。
但仅仅如此吗?
如果只是数据集规模的问题,那直接在车上放一个摄像头,开车出去采个十几万张图片不就可以轻松解决问题了吗?或者说根本不需要自己采集数据集,直接使用其他CV领域的数据集,比如伯克利自动驾驶BDD数据集里面有10万个视频序列,不一样可以用吗? 这里就需要说到另一个很少有人关注的点,就是空间位姿中的主成分问题。
KITTI数据集是用无人车采集的,EuRoC是用无人机采集的,TUM是用手持相机采集的。这里不可避免得就涉及到六个自由度的分布问题,显然KITTI数据集中的位姿基本都是绕Z轴的旋转和水平方向的平移(显然车不可能无缘无故翻滚和上升),EuRoC和TUM数据集中的位姿也是绕Z轴的旋转和水平方向的平移占主导(这个也很容易理解,录制视频的时候也很难有特别复杂的杂技运动)。
这是什么意思呢?
就是说,目前SLAM算法中常用的数据集,基本上只有两个方向的运动,其他4个自由度的运动很少或基本为0。这就导致基于学习的方法在训练过程中,只能学习到绕Z轴的旋转和水平方向的平移这两个方向的运动,其他4个方向很难得到充分学习。不仅如此,其他4个方向还会带来大量噪声,导致本来学好的位姿也不准了!
第三点原因也相当重要,就是图像分辨率和内参的问题!深度模型在训练之前,输入数据会统一Resize为固定的大小,也就是说基于学习的VO在训练过程中学到的是这一固定分辨率下的位姿估计结果。
当网络换一个数据集进行测试的时候,由于图片分辨率变了,网络没学习过这种设置下的位姿,所以输出结果非常受影响。但是传统SLAM算法不会有这种问题,因为它是完全基于对极几何和PNP进行求解的,即使换一个数据集,结果也不会受到太大影响。
第四点原因,就是所有单目算法都会面临的尺度模糊问题。单目算法的尺度不确定性在此不做过多赘述。需要注意的是,基于学习的VO在一个数据集上会学习到这个数据集所对应的尺度,这个尺度还是一个相对尺度。当我们希望将网络迁移到另一个数据集时,由于这个尺度变化,会导致网络估计出的位姿非常不准。
第五,基于学习的VO很难实现回环检测。
熟悉ORB-SLAM3的同学知道,ORB-SLAM3中是存在短期、中期、长期、多地图这四种数据关联的。短期数据关联对应跟踪线程,也是大多数VO使用的唯一数据关联类型,一旦地图元素从视野中消失,就会被丢弃,即使回到原来的地方,也会造成持续的位姿漂移。中期数据关联对应局部建图,通过BA优化可以约束具有共视关系的关键帧。长期数据关联指回环和重定位,可以拉回大幅度的累计漂移。
多地图数据关联可以使用之前已经建立的多块地图来实现地图中的匹配和BA优化。通过这四种数据关联模型,ORB-SLAM3实现了非常强的全局一致性约束,使得整体的位姿估计非常准。但是对于基于学习的VO来说,仅有帧间匹配,很难去实现回环这种长期数据关联,位姿漂移的问题非常严重。
最后一个问题就是,现有的深度学习方法非常吃计算资源。2022年了,基本上3090显卡只能勉强达到深度学习的入门门槛,没有几块A100的话,大模型想都不要想。目前效果最好DROID-SLAM甚至需要4块3090才能达到实时运行。但SLAM算法的最终目标还是落地,要求的是能在低功耗的嵌入式设备上实时运行。
目前大公司的SLAM算法都在做减法来尽可能缩减算力要求,这时候突然要求GPU加速就有点令人难以接受,毕竟谁也不可能真的给自动驾驶汽车或者配送无人机装4块A100吧?
2. 传统VSLAM就一定稳定吗?
我们所熟知的ORB-SLAM、VINS等算法在KITTI、EuRoC、TUM这些静态场景中都已经实现了非常好的效果。但问题是这些场景的规模还是太小了,很少有什么运动模糊的情况,并且也没有什么动态物体。即使它们之中有一些动态序列,动态物体所占的图像范围也没有多大。
当涉及到一些高动态、无纹理、大范围遮挡等挑战性的场景时,传统的VSLAM算法很容易崩溃。如下图所示,测试ORB-SLAM在挑战性数据集Tartan Air中的运行结果时发现,ORB-SLAM平均只能跑完一半的序列,平均绝对轨迹误差ATE甚至达到了27.67m,双目比单目的效果好一些,但也没有好太多。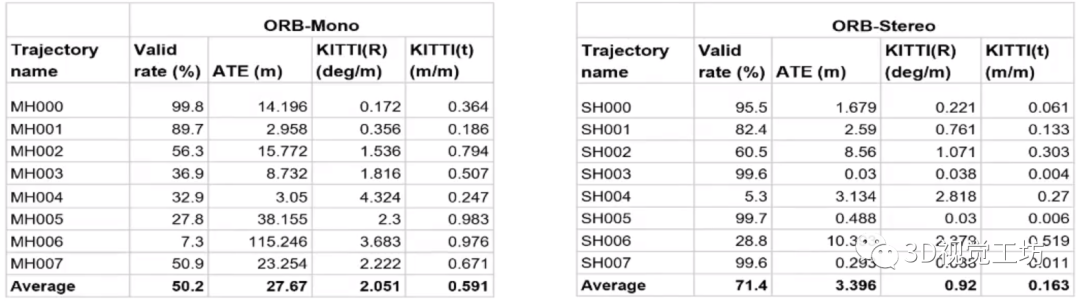

现有的传统方法也基本都是加入点线面特征,或者引入IMU/激光雷达/轮速计/GNSS等多传感器来辅助定位和建图。
但现有算法也基本都是针对特定场景才能运行的,针对这些挑战性场景,始终都没有一个统一且完善的解决方案。 但在深度学习领域,这些都不是问题!目前YOLO已经出到了v7版本,可以轻轻松松检测上千种不同目标,基于Transformer语义分割/实例分割的IoU也已经不停涨点。
不用说检测出一个动态物体,就是多目标跟踪的算法现在也已经非常成熟。 所以说,深度学习结合SLAM是一个非常有价值的大方向!虽然现有的深度学习方法也都有不同的问题,但相信随着时间变化,这些问题都可以被解决。
3. TartanVO
TartanVO来源于2020年CoRL论文“TartanVO: A Generalizable Learning-based VO”,作者是卡内基梅隆大学的王雯珊。
前面说到,ORB-SLAM在挑战性数据集Tartan Air上运行很容易崩溃,Tartan Air数据集也是王雯珊团队的工作。
Tartan Air是一个大规模、多场景、高动态的仿真数据集,里面包含20种不同的环境、500+个轨迹以及40万+帧图像。虽然Tartan Air并不来源于真实传感器,只是一个仿真场景,但其实内部的图像已经足够真实。
我们沿着TartanVO作者的设计思路来进行分析,首先TartanVO设计了一个简单并传统的网络架构,思路也非常简单,输入是连续的两帧图像。网络首先会提取特征并估计光流,之后利用Pose网络估计出位姿。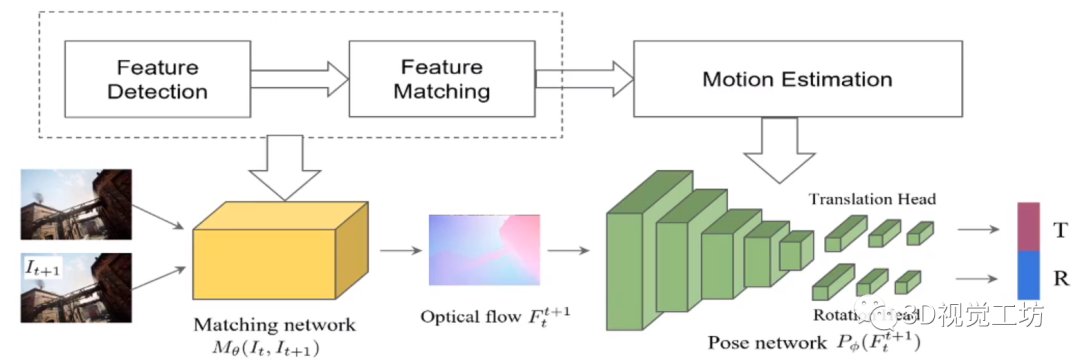
但TartanVO的作者发现,训练过程中的损失一直降不下来!通过分析发现这是由于平移位姿估计差引起的,那原因就显而易见了,还是单目尺度不确定问题!为了解决这个问题,作者设计了对应的尺度一致性损失,只估计相对尺度: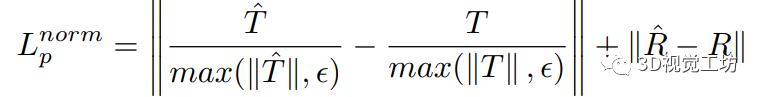
同时TartanVO的另一个重要创新点在于,通用性非常强!前面说到,不同数据集的图像分辨率和内参不一致,这影响了网络的泛化性能。
因此TartanVO又加入了内参层,在训练过程中同时估计相机内参矩阵。同时在训练过程中对Tartan Air数据集的图像进行随机裁剪和缩放,以此来模拟不同的内参。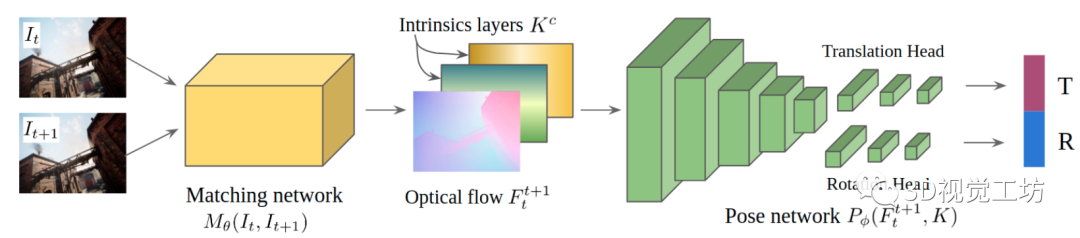
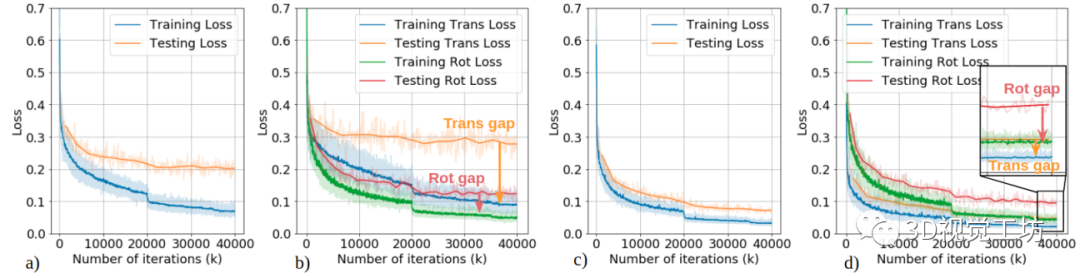
定量结果也证明了网络的有效性,虽然训练损失提高了(模型任务复杂了),但测试损失还是得到了明显降低。
下表是在KITTI数据集上的测试结果,注意TartanVO并没有进行Finetune,但是效果比其他基于学习的VO方法好。值得一提的是,TartanVO的平移精度很高,但是相较于ORB-SLAM的旋转精度较低,这是因为ORB-SLAM具有回环检测模块。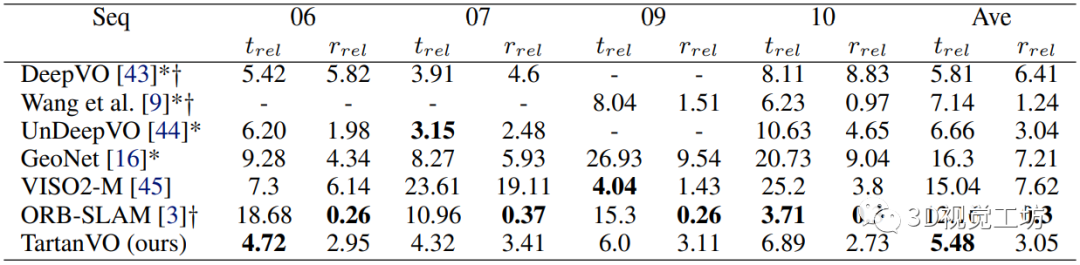
4. 基于TartanVO的动态稠密RGB-D SLAM
这篇论文是今年5月上传到arXiv的,论文名为“Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry”,同样是卡内基梅隆大学的研究成果。
这个网络是基于TartanVO进行的,相当于TartanVO在动态环境中的改进,输出是没有动态对象的稠密全局地图。
算法的主要思想是从两个连续的RGB图像中估计光流,并将其传递到视觉里程计中,以通过匹配点作为直接法来预测相机运动。然后通过利用光流来执行动态分割,经过多次迭代后,移除动态像素,这样仅具有静态像素的RGB-D图像就被融合到全局地图中。
不过不知为何,这篇论文没有进行定量评估,没有和其他SLAM算法的一些ATE、RTE等参数的对比,只有一些定量对比,可能是工作还在进一步优化。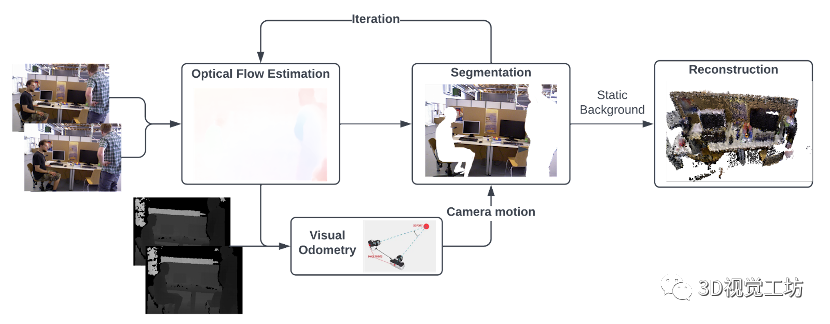
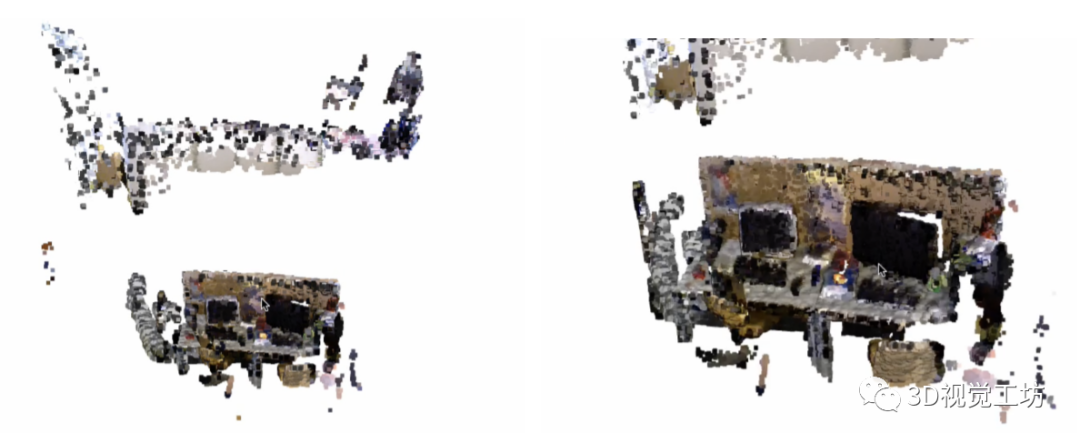
5. DytanVO
DytanVO算是目前最前沿的成果了,论文名“DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments”,同样是卡内基梅隆大学王雯珊团队的工作,该论文已经提交到2023 ICRA。 DytanVO的整个网络架构还是基于TartanVO进行优化的。
DytanVO由从两幅连续图像中估计光流的匹配网络、基于无动态运动的光流估计位姿的位姿网络和输出动态概率掩码的运动分割网络组成。
匹配网络仅向前传播一次,而位姿网络和分割网络被迭代以联合优化位姿估计和运动分割。停止迭代的标准很简单,即两个迭代之间旋转和平移差异小于阈值,并且阈值不固定,而是预先确定一个衰减参数,随着时间的推移,经验地降低输入阈值,以防止在早期迭代中出现不准确的掩码,而在后期迭代中使用改进的掩码。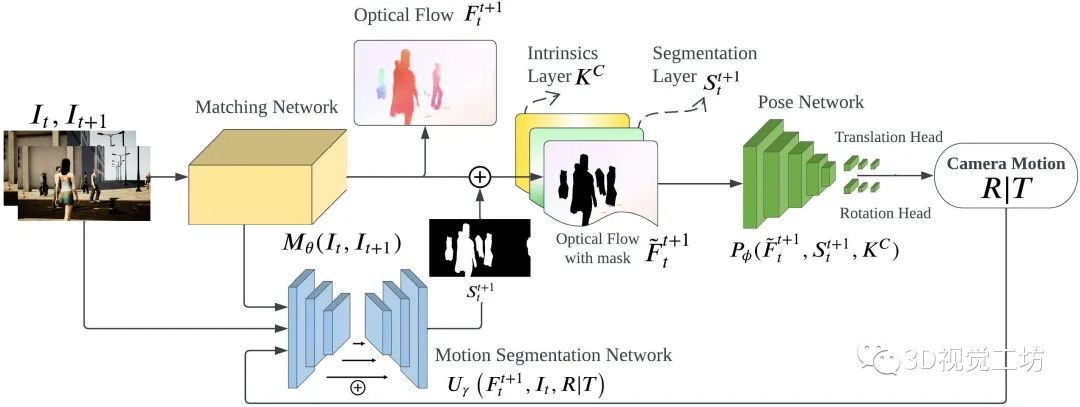
下图所示是DytanVO的运行示例,包含两个输入的图像帧、估计的光流、运动分割以及在高动态AirDOS-Shibuya数据集上的轨迹评估结果。结果显示DytanVO精度超越TartanVO达到了最高,并且漂移量很小。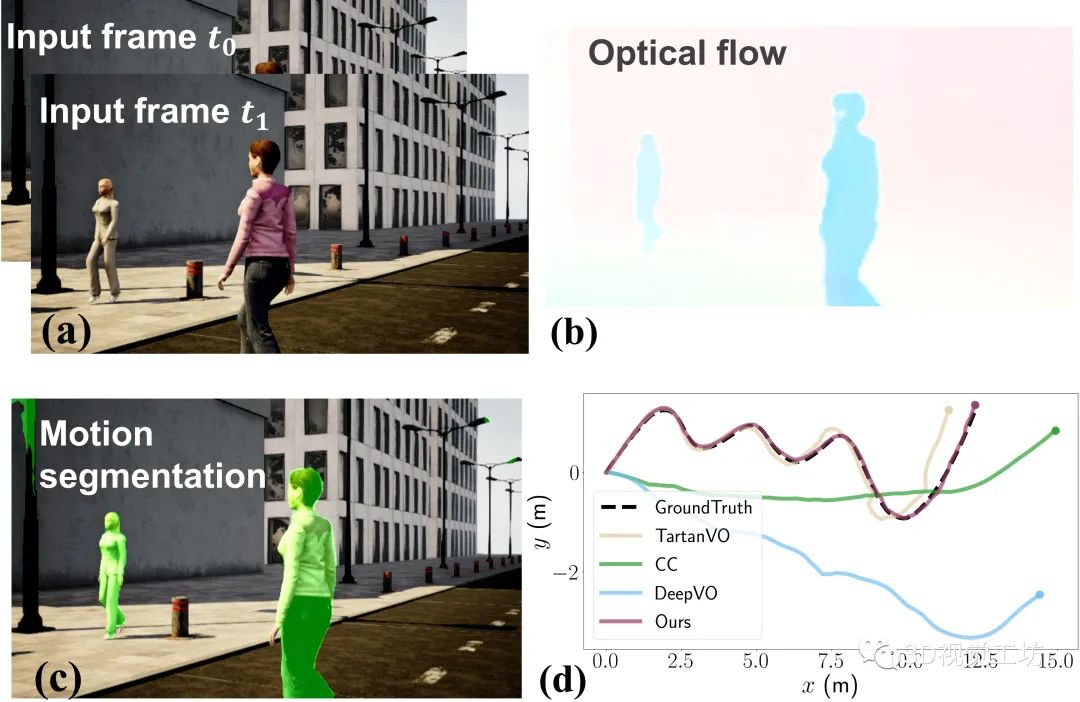
下表是在AirDOS-Shibuya的七个序列上,DytanVO与现有最先进的VO算法进行的定量对比结果。
七个序列分为三个难度等级:大多数人站着不动,很少人在路上走来走去,穿越(容易)包含多个人类进出相机的视野,而在穿越道路(困难)中,人类突然进入相机的视野。
除了VO方法之外,作者还将DytanVO与能够处理动态场景的SLAM方法进行了比较,包括DROID-SLAM、AirDOS、VDO-SLAM以及DynaSLAM。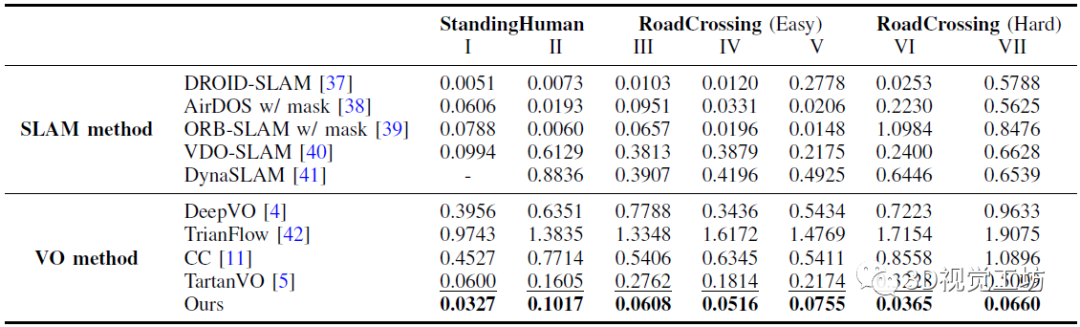
6. 总结
深度学习已经广泛应用到了各个领域,但在SLAM领域却没有取得很好的效果。本文深入探讨了为什么基于学习的VO效果不如传统的SLAM算法,并介绍了三种基于学习的VO的算法原理。
总之,深度学习与SLAM结合是一个大趋势,现阶段无论是基于学习的VO还是传统SLAM算法都有各自的问题,但两者结合就可以解决很多困难。
审核编辑:刘清
-
ESP
+关注
关注
0文章
186浏览量
34145 -
VSLAM算法
+关注
关注
0文章
5浏览量
2257
原文标题:基于学习的VO距离传统VSLAM还有多远?
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大联大世平集团推出基于Intel技术的双目VSLAM空间定位解决方案
诠视科技的VSLAM技术突破 看看CEO林琼如何诠释
通过持续元学习解决传统机器学习方式的致命不足
VSLAM系统方法的各种特点
研讨会预告 | 在 Jetson 上使用 vSLAM 进行 ROS 2 精准定位
VC-VO异质颗粒的相演化促进锂硫电池中硫转化反应
一文梳理缺陷检测的深度学习和传统方法
基于事件相机的vSLAM研究进展

基于事件相机的vSLAM研究进展

深度学习与传统机器学习的对比
传统机器学习方法和应用指导






 工商网监
工商网监
评论