 遇到无法识别(分类)的物体怎么办?
遇到无法识别(分类)的物体怎么办?
单目或三目构成的视觉系统是目前智能驾驶的主流,其致命缺陷就是识别与检测是一体的,也就是说要检测目标必须先识别目标,无法识别就等于看不到,车辆不会有任何减速而直接撞上去,此类事故,特斯拉、小鹏和蔚来都发生过。普通人说识别,在计算机视觉里实际是分类,为了对应传统习惯,本文依然把分类叫识别。
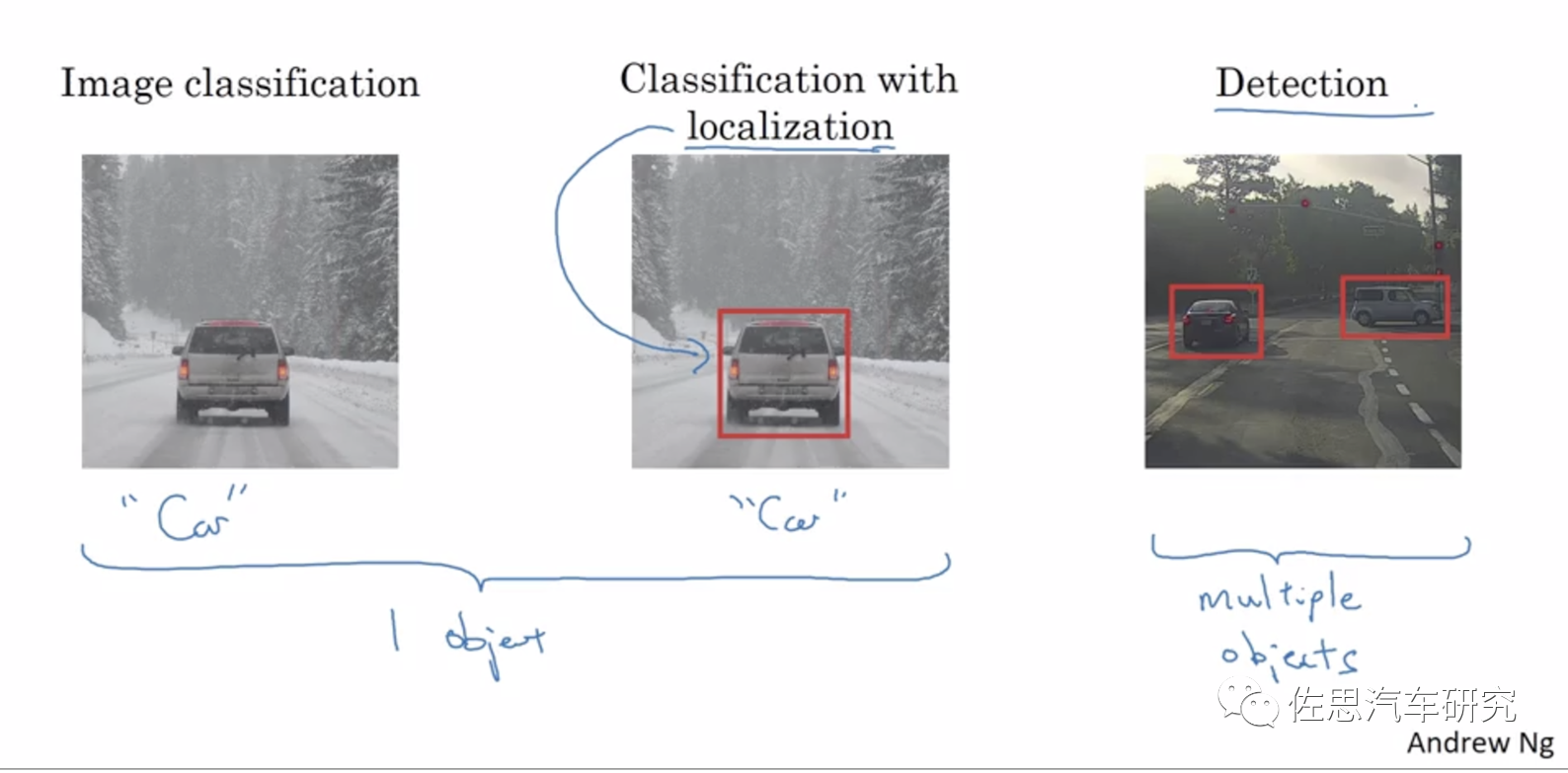
图片来源:Andrew Ng公开课
要解决这个问题最好的办法是立体双目,其次是没有分类任务的激光雷达,典型代表就是奥迪A8上那种四线激光雷达,目前多线的激光雷达通常都是用与单目摄像头一样的应用算法,同样会遇到识别与检测一体的问题。这也正是特斯拉不用激光雷达的原因之一,单目摄像头遇到的困难,多线激光雷达一样会遇到,而奥迪A8上那种四线激光雷达只能检测到前方有没有物体,是什么物体就不知道,算是加强版的毫米波雷达。对于复杂驾驶环境如城区则不太适合,只能用于塞车时的自动跟车。最后是4D毫米波雷达,近似于4线激光雷达,缺点与4线激光雷达一样。
立体双目能完美解决问题,缺点是其标定太麻烦,传感器的尺寸一致性要求很高。还有就是立体匹配算法难度不低,最好使用FPGA,AI加速器完全无用,GPU的话消耗算力太多。熟悉FPGA的厂家很少,需要摸索很长时间,因此立体双目只有老牌的博世、斯巴鲁、奔驰和丰田坚持使用。
大部分厂家没有时间去摸索,看看Mobileye便知研发人员人工成本太高了,即便已经占有超过75%的智能驾驶市场,利润依然无法填平研发成本的坑。
为什么会出现无法识别的目标,这就是深度学习的天生缺陷,无法改变。学术的说法叫Outof Distribution(OOD),OOD detection 指的是模型能够检测出OOD样本,而OOD样本是相对于InDistribution(ID)样本来说的。传统的机器学习方法通常的假设是模型训练和测试的数据是独立同分布的(IID,Independent Identical Distribution),这里训练和测试的数据都可以说是InDistribution(ID)。在实际应用当中,模型部署上线后得到的数据往往不能被完全控制的,也就是说模型接收的数据有可能是OOD样本,也可以叫异常样本(outlier, abnormal)。
简单地说,深度学习数据集就像穷举法,但穷举所有类型是不可能的,那样数据集会异常庞大且成本高昂,并且现实世界每分每秒都在产生新的异常样本,永远都无法穷尽。对于牵涉到安全的应用,如无人驾驶和医学识别,OOD是噩梦般的存在。虽然说异常样本出现的几率很低,但一旦出现就可能损失一条生命。有人会说,人开车会出事故,因此不能苛求机器开车不出事故,这显然是错误的,人是有纠错机制的,而机器不会,它犯错一次要一条人命,下次遇到异常样本还是如此。
除了OOD外,还有一类物体是单目三目视觉系统永远都无法识别的,那就是侧翻车辆。
画面中这辆侧翻的集装箱车对单目三目来说也是噩梦,是一大片红色,无纹理特征的图像,任何计算机视觉技术皆无能为力,当然,最困难的是白色,就等同于天空,特斯拉中国台湾高速事故就是如此,无论何种单目计算机视觉都无从下手,立体双目可以完美解决这个问题。
还有这种侧翻,大面积反光,且有图像显示在车上,训练数据集都是基于正常车辆拍摄的图像数据,这种侧翻的非常罕见,数据集里肯定没有,再加上它还能反光,还能显示其他图像,单目计算机视觉完全无能为力。
想完美解决问题是不可能的,目前学术界在尝试用差异性网络来解决这个问题。众所周知,深度神经网络不具备可解释性,永远存在概率,没有确定性,而汽车领域一定要有确定性,但除了深度神经网络,人类开发智能驾驶没有其他低成本方式,只能用它。当然对于那种大面积空洞类似天空的目标,任何基于单目三目的计算机视觉技术都无能为力。
目前对于无法识别物体的检测,学术界研究主要方向是差异性网络DiscrepancyNetworks。本文主要基于四篇论文:
第一篇是瑞士洛桑联邦理工学院EPFL的计算机视觉实验室的《Detecting the Unexpected via Image Resynthesis》,
第二篇是丰田的《Road Obstacle Detection Method Based on an Autoencoder with SemanticSegmentation》,
还有一篇《Efficient Unknown Object Detectionwith Discrepancy Networks for Semantic Segmentation》。
最后一篇是微软研究院和Wisconsin-Madison大学的《Unknown-Aware ObjectDetection Learning What You Don’t Know from Videos in the Wild》。
目前都局限于学术研究,离上车最快也要等10年。
思路都大同小异,即用GAN再合成图像,制造差异性网络。
EPFL的思路
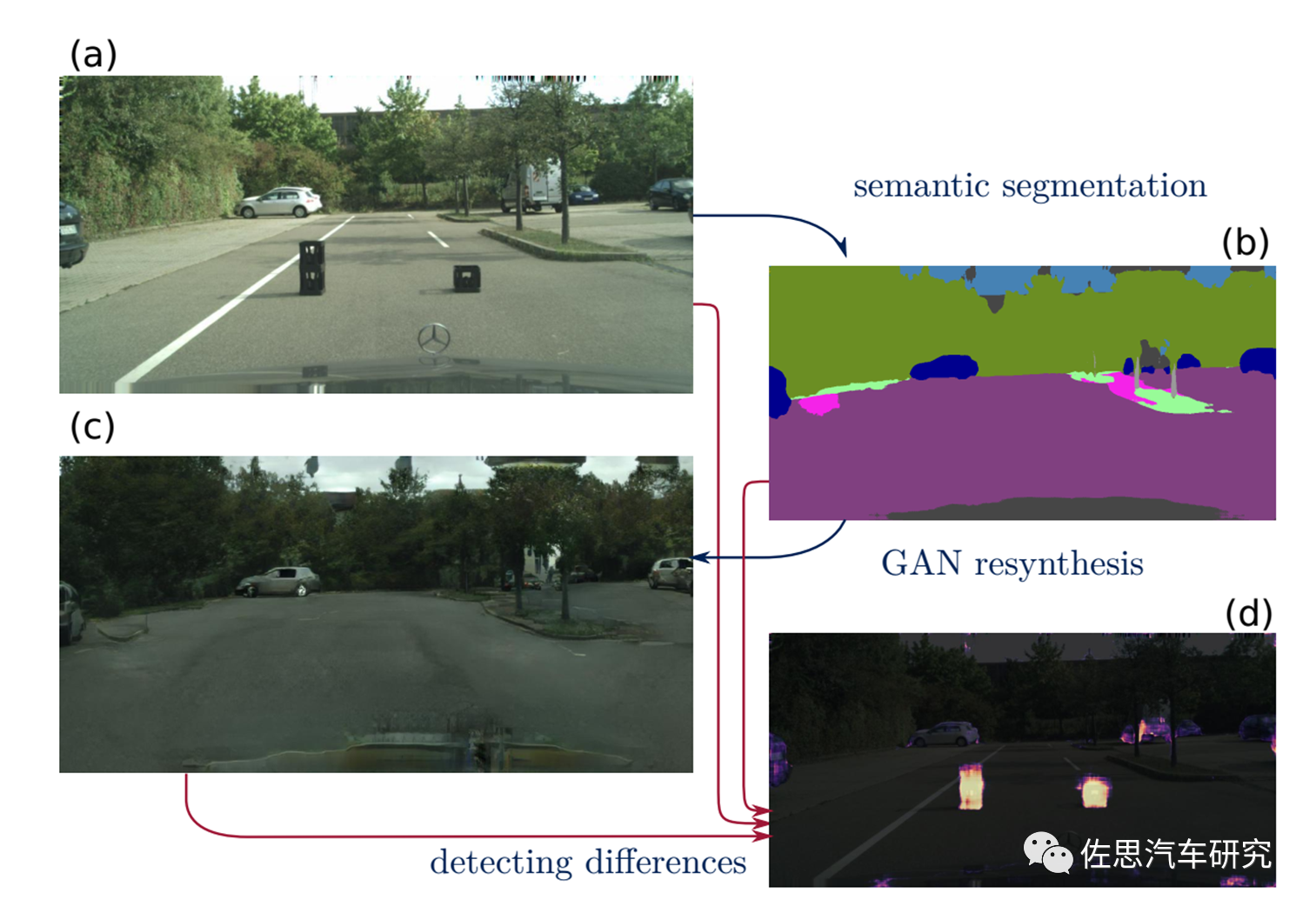
图片来源:EPFL
EPFL的思路,图a是路上的两个异常样本物体,深度学习完全无法识别,也就检测不到;图b是图像语义分割,这两个物体消失了,用GAN再合成图像,这两个物体还是消失不见,但最后加上差异性网络,这两个物体找到了,就是图d的高光显示部分。
EPFL的做法
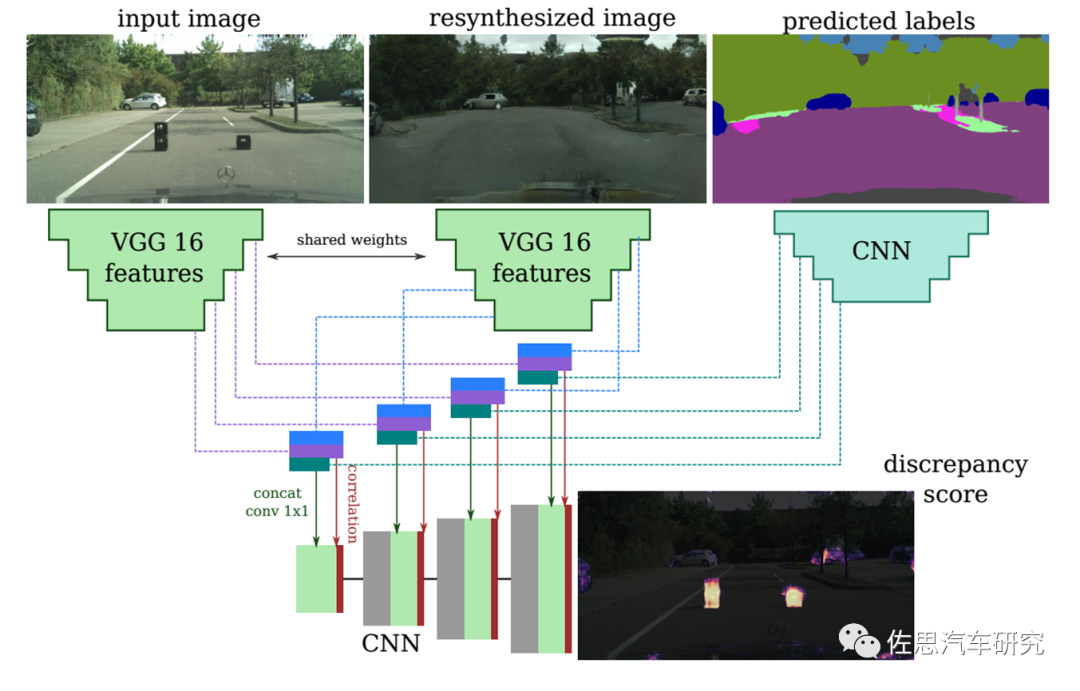
图片来源:EPFL
EPFL的做法,用两个VGG16网络从原始图像和再合成图像中抽出特征并做金字塔矫正,特征和关联送入一个跳过连接的解码器,最终得到差异性图像。
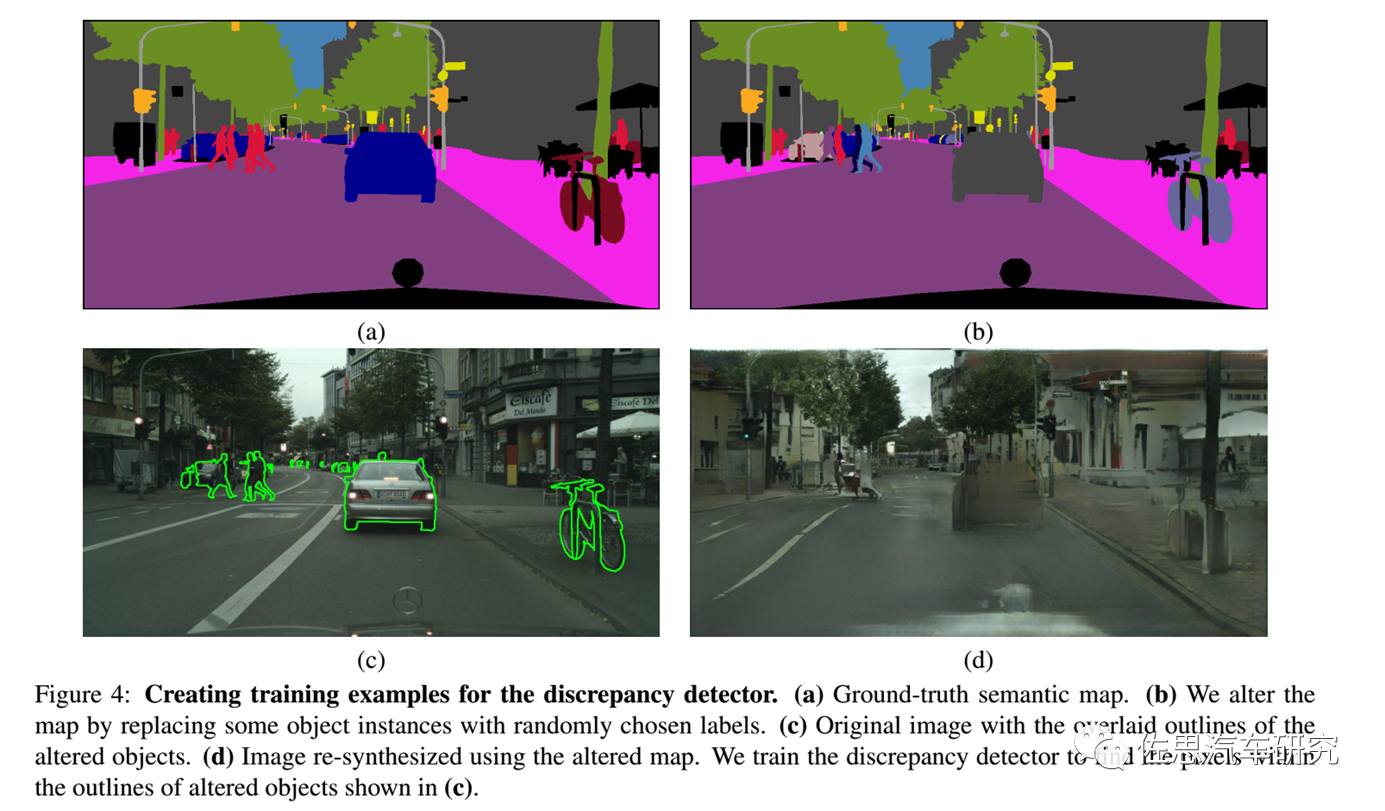
图片来源:EPFL
基于CNN的图像识别通常无法识别右边这辆自行车,因为它靠在柱子上。
丰田的思路
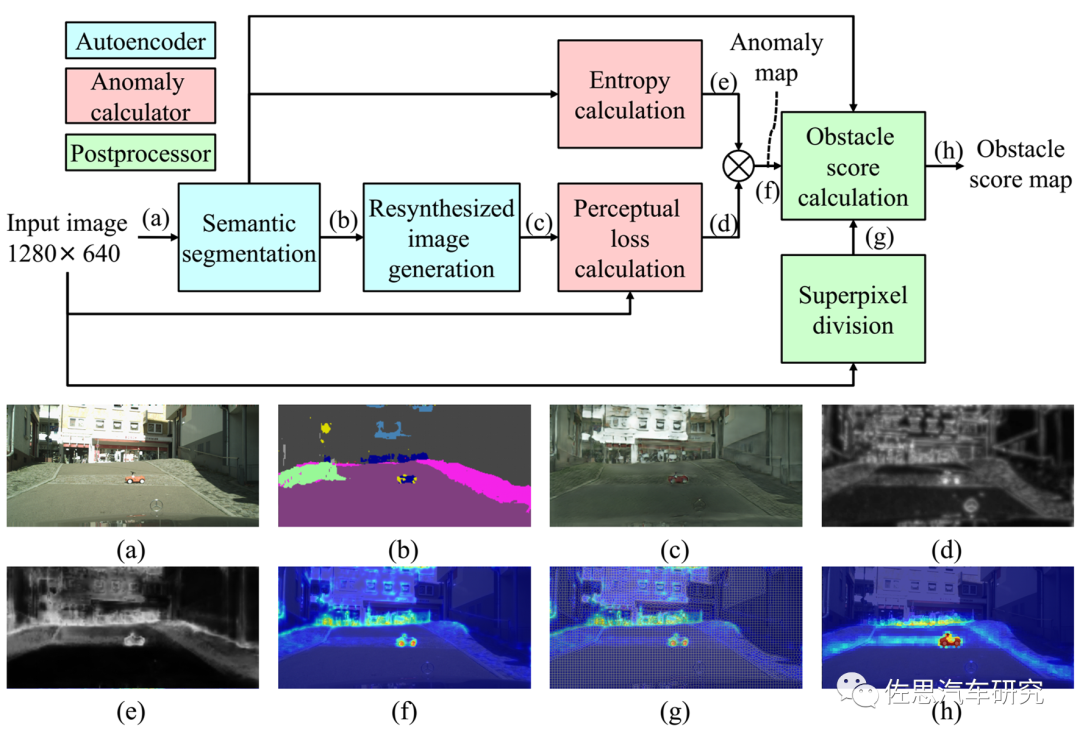
图片来源:丰田
微软的思路
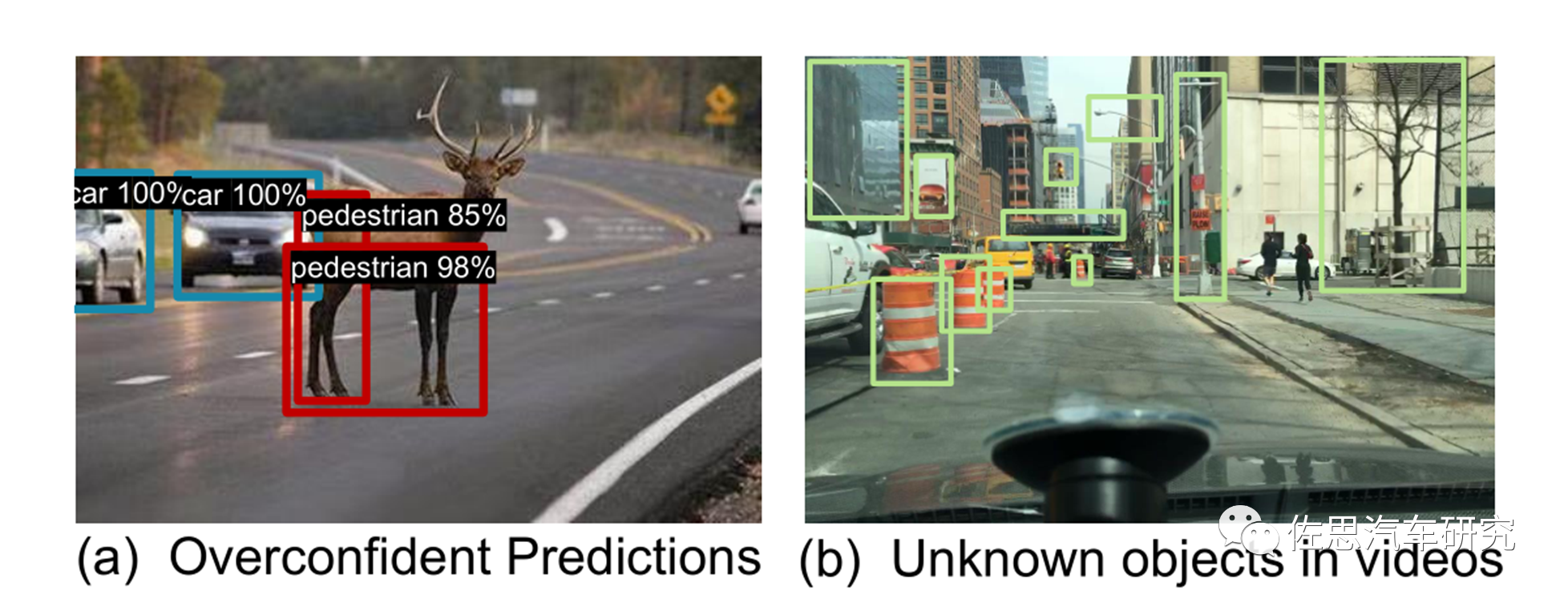
图片来源:微软
微软提出了一种新的未知感知目标检测框架,该框架通过时空未知提取(STUD)从野外视频中提取未知对象,并有意义地正则化模型的决策边界。视频数据自然地捕获了模型运行的开放世界环境,并封装了已知和未知对象的混合物;见图1(b)。例如,建筑物和树木(OOD)可能会出现在驾驶视频中,尽管它们没有明确标注用于培训车辆和行人的物体检测器(ID)。类似于化学中的蒸馏概念,即“从混合物中分离物质的过程”。虽然经典的目标检测模型主要使用标记的已知对象进行训练,微软试图通过联合优化目标检测和OOD检测性能,利用未知对象进行模型正则化。
微软的STUD框架
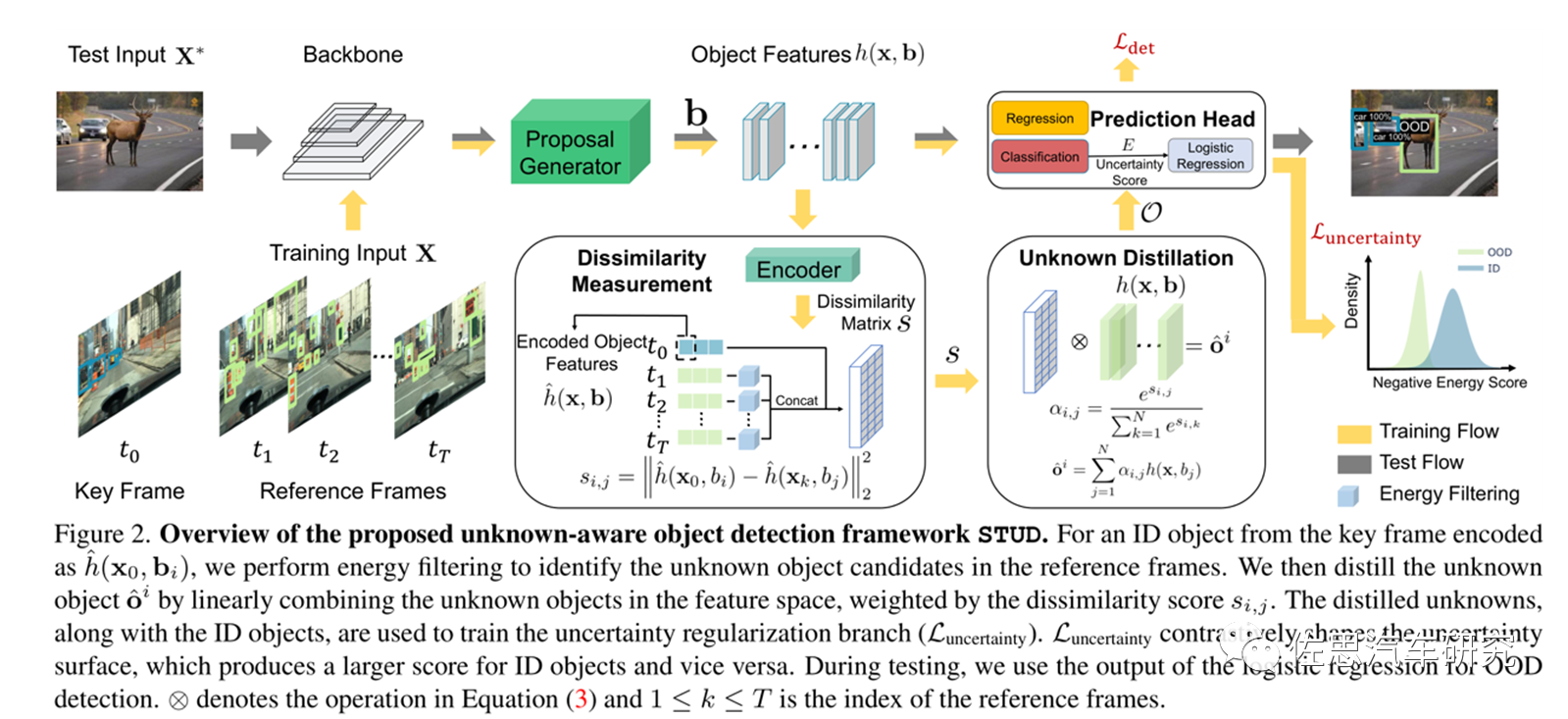
图片来源:微软
《Efficient Unknown Object Detectionwith Discrepancy Networks for Semantic Segmentation》这篇论文比较新,是2022年8月发表的,作者单位名气不大,有日本SenseTime和德州奥斯汀大学。
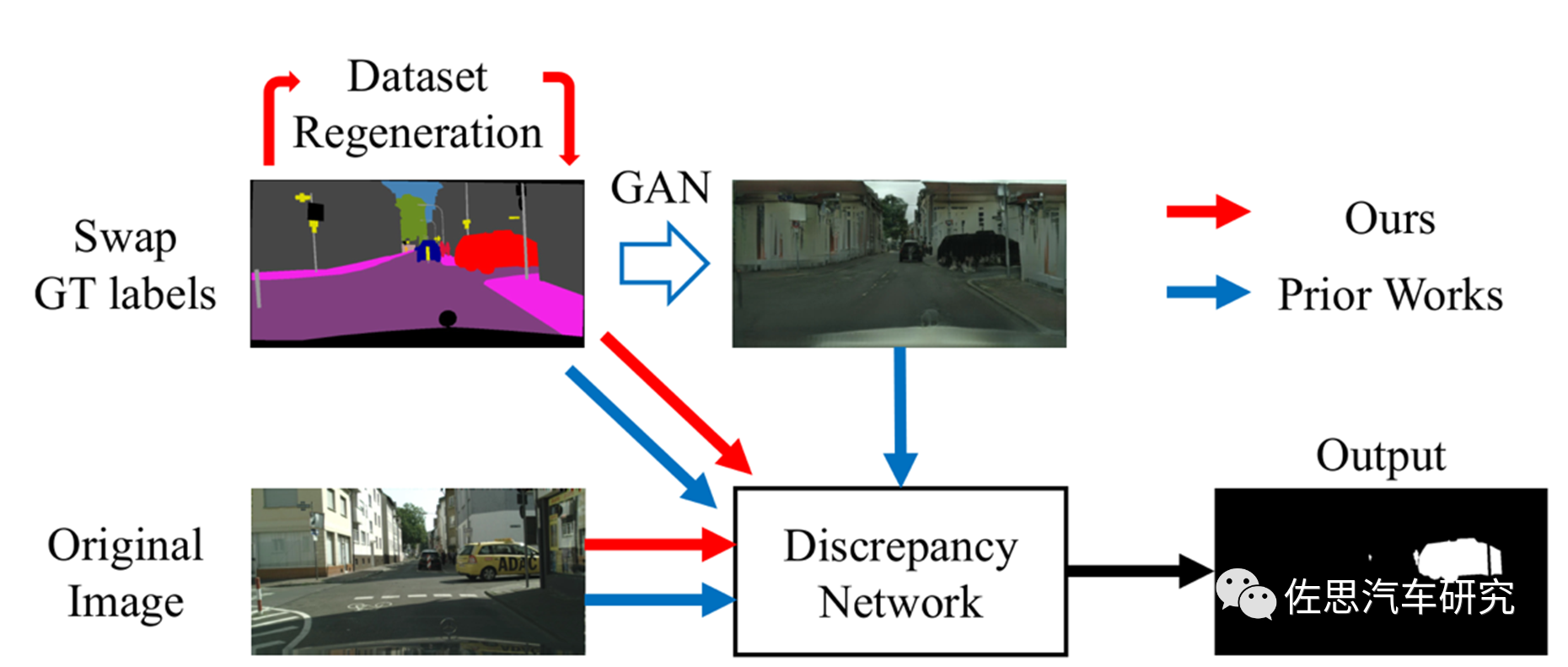
图片来源:SenseTime
典型示例如上,图中车辆车身上有大字,很容易被误认为标志牌,或者无法识别。
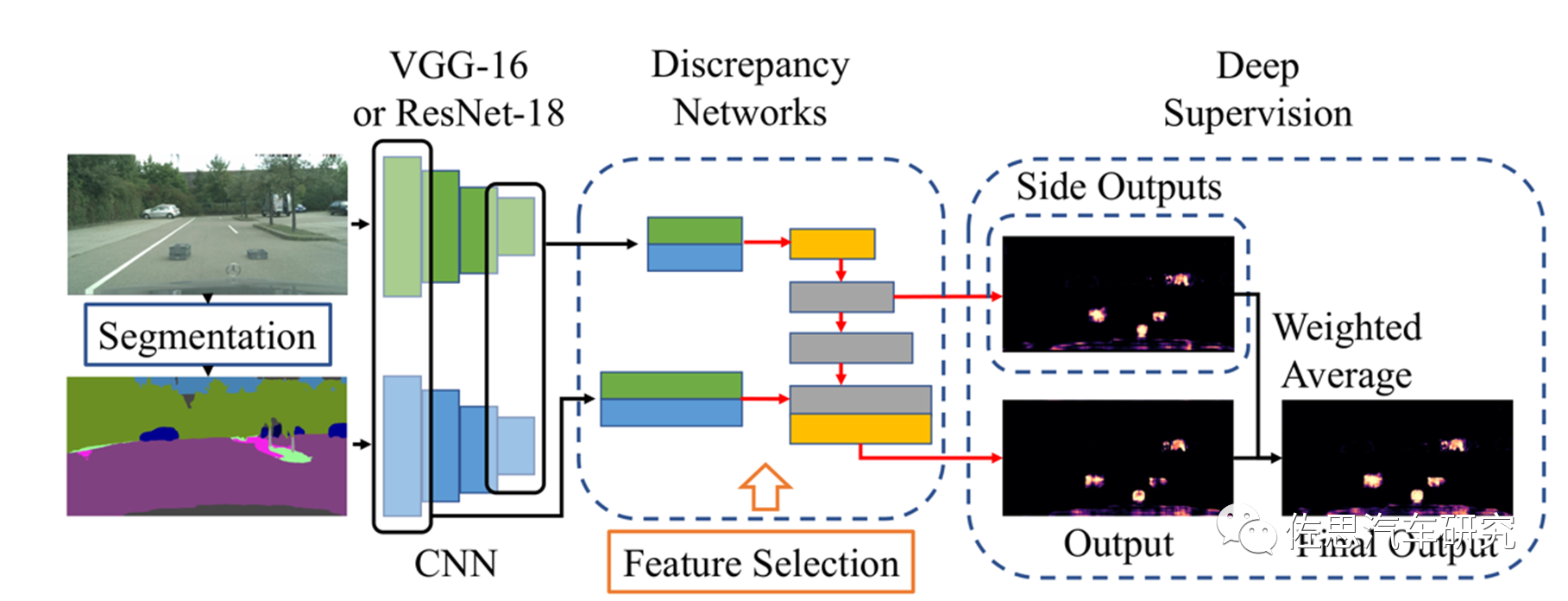
图片来源:SenseTime
作者的思路主要是加入了所谓深监督(Deep Supervision),就是在深度神经网络的某些中间隐藏层加了一个辅助的分类器作为一种网络分支来对主干网络进行监督的技巧,用来解决深度神经网络训练梯度消失和收敛速度过慢等问题。
虽然立体双目可以完美解决所有难题,但立体双目研发周期长,短期很难出成果,大部分企业都不会选择立体双目,深度学习太容易了,炼丹不需要知道因果关系,只需塞数据即可,立体双目阵营目前也开始出现松动,丰田还专门出了个深度学习加单目推测立体视觉再获得深度数据的数据集,宝马也在2021年放弃了立体双目。年轻人几乎没有从事立体双目研究的。
Argo关闭,Aurora和图森市值暴跌95%,Cruise和Waymo沉寂多日,过度依赖深度学习的无人驾驶该何去何从?
审核编辑 :李倩
-
分类器
+关注
关注
0文章
152浏览量
13261 -
视觉系统
+关注
关注
3文章
337浏览量
30880 -
深度学习
+关注
关注
73文章
5523浏览量
121732
原文标题:遇到无法识别(分类)的物体怎么办?
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
盛显科技:投影融合处理器连接出现超时,该怎么办?

物体识别桌 AR物体识互动桌 电容屏实物识别漫游桌
物体识别交互软件 AR实物识别桌软件 电容物体识别桌
TLV320AIC3254EVM-K连接电脑无法识别USB是怎么回事?
usb主机控制器设备破坏怎么办
ddos造成服务器瘫痪后怎么办
盛显科技:投影融合处理器画面出现闪烁或抖动,该怎么办?

盛显科技:投影融合处理器出现颜色失真或偏色,该怎么办?
KT142C-sop16语音芯片,插上usb,出不来虚拟U盘怎么办
工控主板发生故障该怎么办?
电容负极熔断怎么办






 工商网监
工商网监
评论