 【AI简报20221021期】英特尔i9-13900K重夺PC性能桂冠、RISC-V可靠矢量处理弯道超车
【AI简报20221021期】英特尔i9-13900K重夺PC性能桂冠、RISC-V可靠矢量处理弯道超车
嵌入式 AI
AI 简报 20221021 期
1. 英特尔i9-13900K重夺PC性能桂冠:与AMD 7950X拉开8%差距
原文:
https://app.myzaker.com/news/article.php?pk=63476be18e9f0903ac797c80
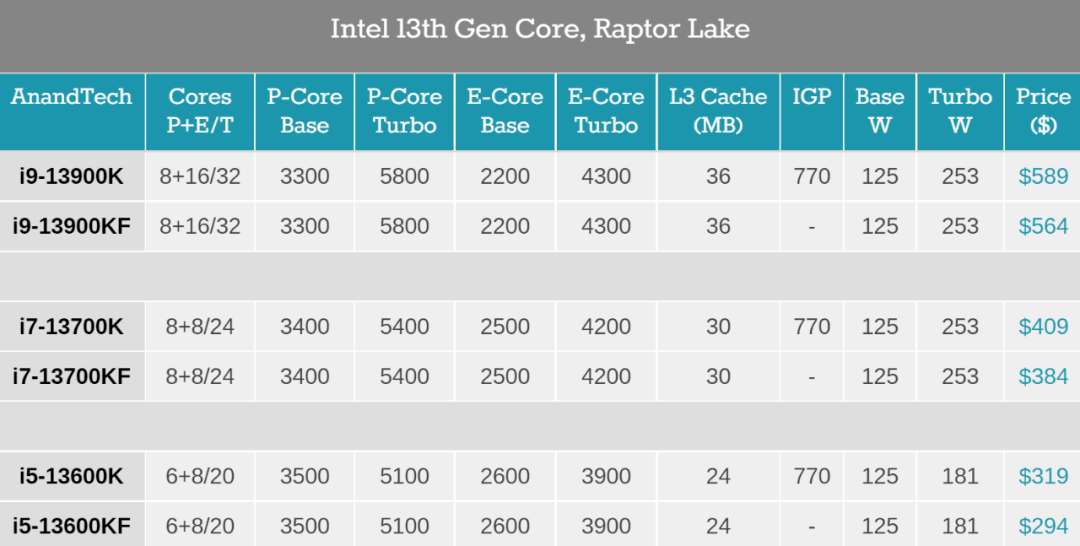
10 月 20 日晚上,英特尔正式解禁了 13 代酷睿台式机处理器的性能表现,包括 Intel Core i9-13900K 和 i5-13600K。美国科技媒体 The Verge 对 i9-13900K 与 AMD Ryzen 9 7950X 进行了比较 ,发现虽然 AMD 的 Zen 4 架构 CPU 相较于英特尔 12 代酷睿的性能有所提升,但这次英特尔 13 代酷睿重新夺回了整体性能的桂冠。
先来看下英特尔酷睿 i9-13900K 的相关参数,作为高端版本,它包括 24 个核心(8 个性能核和 16 个效能核)、32 个线程和高达 5.8GHz 的时钟速度。
英特尔承诺,酷睿 i9-13900K 的单线程性能较 i9-12900K 提升了 15%,多线程性能提升了 41%。与此同时,它的售价也来到了 589 美元。
过去一周,The Verge 一直在测试酷睿 i9-13900K,它在很大程度上兑现了英特尔声称的性能,尤其是多线程性能大幅提升,真正加速了最繁重的工作负载效率。
具体地,The Verge 在英特尔酷睿 i9-13900K 和 AMD 锐龙 9 7950X 处理器上测试了各种工作负载、综合基础测试和游戏。所有的测试均在最新的 Windows 11 2022 Update 上运行,并关闭了安全性,启用了 Resizable BAR,所有游戏都在 1080p 分辨率设置下运行。
2. 谷歌3D全息电话亭,颠覆现有视频通话!宛如真人面对面
原文:
https://mp.weixin.qq.com/s/TMhMjFZbw96n4CUkVQ_z1w
在近日的Google Cloud Next 2022上,桑达尔·皮查伊表示,Starline 项目已经在谷歌内部进行了数千小时的测试,并在其美国办公室每天使用,而100多个横跨媒体、医疗和零售的企业合作伙伴已经收到了演示。
谷歌还宣布Project Starline正在进入下一个测试阶段,计划是在选定的合作伙伴办公室部署设备进行定期测试,谷歌提到的合作伙伴包括Salesforce、WeWork、T-Mobile和Hackensack Meridian Health,这些设备预计将在今年年底前完成安装,开启初试。
谷歌为什么花费大量时间开展Project Starline呢?根据项目组给出的答案,就是让人在通话的时候,感觉你是和一个真正的人在一起。在如今的社会中,人们通常会相隔千里,尤其是近两年疫情频繁发生,人们不得不通过Zoom等远程会议软件,进行联系、沟通工作。
然而当下视频会议给人的感觉并不好,根据微软一份关于视频会议对工作效率的影响的报告,人们在视频会议中会比显示沟通更容易分析,这是人们在面对高压力的视频会议下的自然应对反应。而谷歌认为,能提供真人对话体验的Project Starline,似乎能够消除这种压力感。
谷歌的研究员做了对比实验,他们发现相比传统视频沟通,使用Project Starline沟通的参会者会有更多眼神接触和肢体语言,在沟通结束后能够回忆的内容也要多出28%。
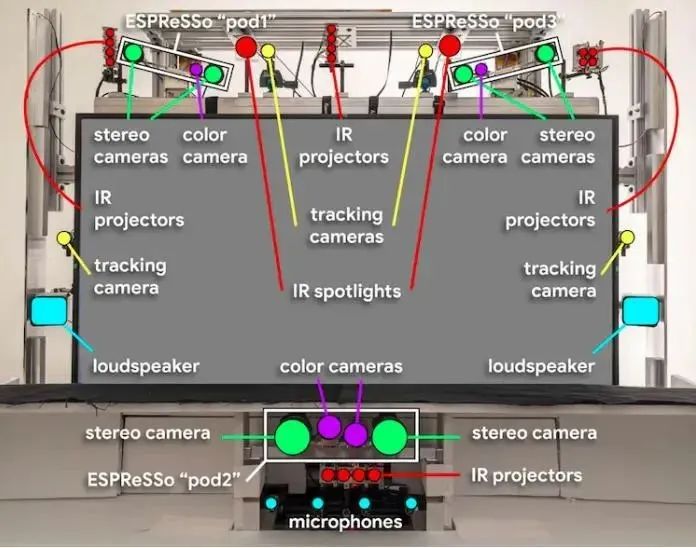
更为重要的是,装配一套Project Starline,成本相当高,光场显示器和各种光学摄像头都非常昂贵,这使得Project Starline短期内只能停留在实验室,而进入消费者市场的可能性很小。Project Starline的产品管理总监Andrew Nartker称,目前它还很难称得上是一件产品。
整体而言,Project Starline是一个全新技术的探索,谷歌也会继续对其进行优化改进。未来,它能否成为一个真正的产品还未可知。不过无论怎样,任何一项新技术的探索都值得被关注。
3. 通用计算仍有差距,RISC-V可靠矢量处理弯道超车
原文:
https://mp.weixin.qq.com/s/mM9Drv8r2QGSD7Hm8i8HWA
对于高效的数据并行负载处理来说,矢量架构的吸引力越来越大,主流ISA都开始注意到这一点。就拿我们熟悉的前超算王者——日本的富岳来说,其处理器富士通A64FX就是基于Arm可伸缩矢量扩展(SVE)的。
Arm也在随后推出的Armv9架构中提出了改良版的SVE2,并在其中加入了对NEON的兼容,SVE2在HPC之外的市场应用中做出了指令优化,甚至可以用于手机、汽车等智能设备中。
正是因为有了SVE的存在,富岳才得以单靠通用处理器完成高性能的大数据运算,而不是像其他主流超算一样,还要靠堆积GPU、FPGA和AI加速器等片外加速器才能实现可观的性能,我国的神威太湖之光同样运用了这样的矢量设计思路。但以上这些都是专有架构,微架构不透明的同时也限制了开源和定制化方案的出现,而这些均可以在RISC-V上一一实现。
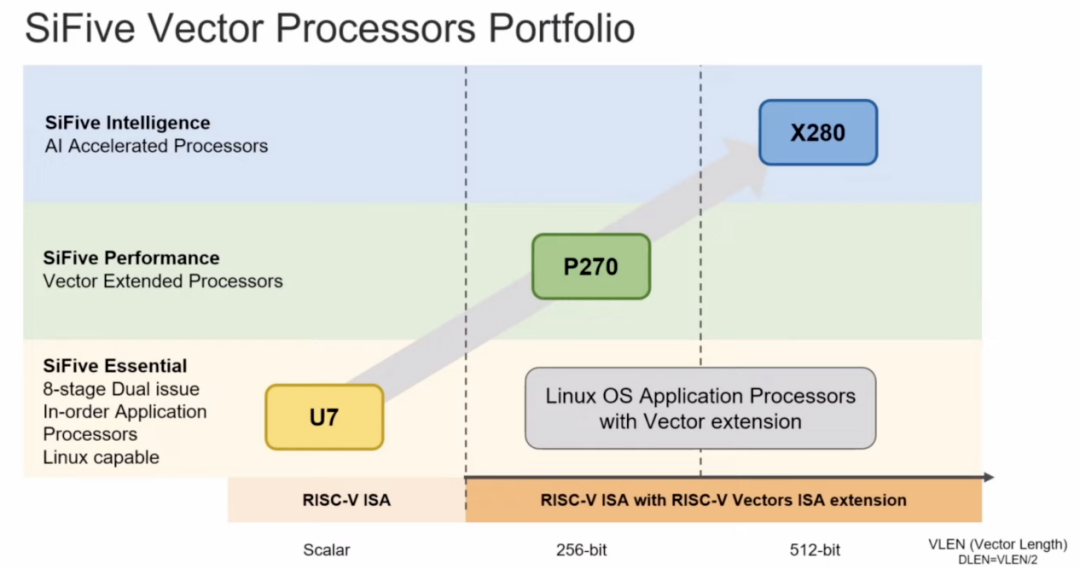
RISC-V的矢量扩展RVV自2015年提出以来,已经有了长足的进展,也有了正式的1.0版本规范。与传统的SIMD指令相比,RVV提供动态的矢量长度修改,做到了更高的效率、更小的代码体积和更简单的循环结束。我们近期已经看到了不少RISC-V处理器被广泛使用的新闻,比如谷歌选择在其TPU上加入SiFive的X280处理器,其实看重的就是它在矢量处理上的优势。
所以我们看到在SiFive的处理器产品中,像Performance P270和Intelligence X280都拥有优秀的矢量处理能力,后者更是引入了一个512位矢量寄存器长度的架构,在完全支持矢量扩展标准的同时,还支持动态可变矢量长度的运算。SiFive也在其矢量扩展上做出了改进,称其为SiFive智能扩展,与直接基于RV64GCV架构的设计相比,X280的智能扩展在INT8格式下的矩阵乘法运算时可将执行速度提高12倍。
而且这不仅仅造福的是数据中心,还有受制于功耗却又需要高吞吐量和单线程性能的边缘应用,比如AR/VR、数码相机等等。SiFive同样测试了可用于移动端或嵌入式设备的轻量级神经网络MobileNet,相较基于RISC-V标量的架构,SiFive智能扩展可以将速度提升144倍。
AI时代下,矢量处理的应用场景已经远超我们的现象,包括深度学习、推荐系统、键值存储和HPC等,都已经广泛利用了矢量计算。但如何做到高效高性能,才是未来所有ISA的努力方向,而RISC-V作为后来者,反而能在这上面找到弯道超车的机会。
4. 移动端部署推荐系统:快手获数据挖掘顶会CIKM 2022最佳论文
原文:
https://mp.weixin.qq.com/s/x3dnkBF7BKDMEU_rt8QmDg
10 月 20 日,信息检索和数据挖掘领域的顶级会议之一 CIKM 2022 公布论文奖项,快手社区科学团队获得了应用研究方向「最佳论文奖」。

获奖论文《Real-time Short Video Recommendation on Mobile Devices》针对短视频推荐场景,传统服务端部署的推荐系统在决策时机和实时特征利用方面的不足问题,通过在移动客户端部署推荐系统来实时响应用户反馈,提高推荐结果的精准度,从而提升用户体验。论文提出的方案 100% 流量部署到了快手短视频推荐生产环境,影响了日均超过 3.4 亿用户的体验,是端上智能在大规模推荐场景落地的创新实践。

论文链接:
https://dl.acm.org/doi/10.1145/3511808.3557065
5. 致敬Metaformer!图像超分多尺度注意网络MAN开源:大核分解与注意力机制的巧妙结合
原文:
https://mp.weixin.qq.com/s/DF73mR6U4MstHeAHOZTGBw
论文链接:
https://arxiv.org/abs/2209.14145
代码地址:
https://github.com/icandle/MAN
本文基于大核分解和注意机制,提出应用于图像超分的多尺度注意网络MAN。通过可解释的门控空间注意单元来汇总上下文信息,利用多尺度大核注意模块获得丰富注意特征图,并聚合局部-全局信息。本文方法与现有流行方法进行了详细的实验对比,获得了竞争性的对比结果。
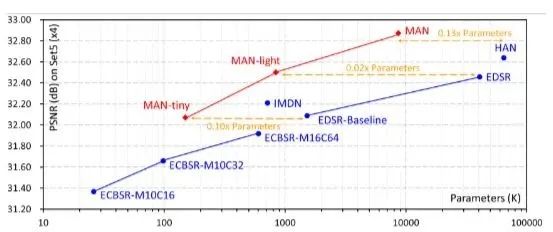
图像超分旨在从低分辨率输入重建高分辨输出。然而基于CNN的方法要么通过更大数据集来提高性能,要么引入了更复杂的网络设计,这些无疑都增加了计算成本消耗。
还记得今年2月份出炉的那篇VAN吗,VAN通过详细实验证明了大核的卷积可以被有效分解为三种卷积的组合,分别为:深度卷积、含膨胀的深度卷积、逐点卷积。这里给出VAN的分解示意图:
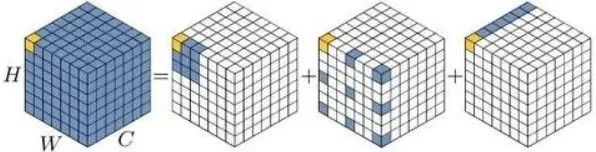
VAN的作者在文末提到,未来对VAN的改进可能包含多分支或多尺度设计的应用。在本文中,作者等人在图像超分任务中对VAN进行可行性考察,发现了一个很重要的问题:VAN的分解过程中,含膨胀的深度卷积会为超分任务带来“块状伪影(blocking artifacts)”。在损害性能的同时,固定的核大小无法充分局部-全局特征。
综上,作者将多尺度机制与大核注意机制结合来解决上述问题,并采用门控机制校准注意图,避免含膨胀的深度卷积带来的块状伪影。
6. 一个Trick 搞定 CNN与Transformer,即插即涨点即提速
原文:
https://mp.weixin.qq.com/s/jRfWEgQ6cqVz5hcm6WOa2g
论文链接:
https://arxiv.org/abs/2210.04020
近年来,Transformer模型在各个领域都取得了巨大的进展。在计算机视觉领域,视觉Transformer(ViTs)也成为卷积神经网络(ConvNets)的有力替代品,但它们还无法取代ConvNet,因为两者都有各自的优点。例如,ViT善于利用注意力机制提取全局特征,而ConvNets由于其强烈的归纳偏差,在建模局部关系时更有效。

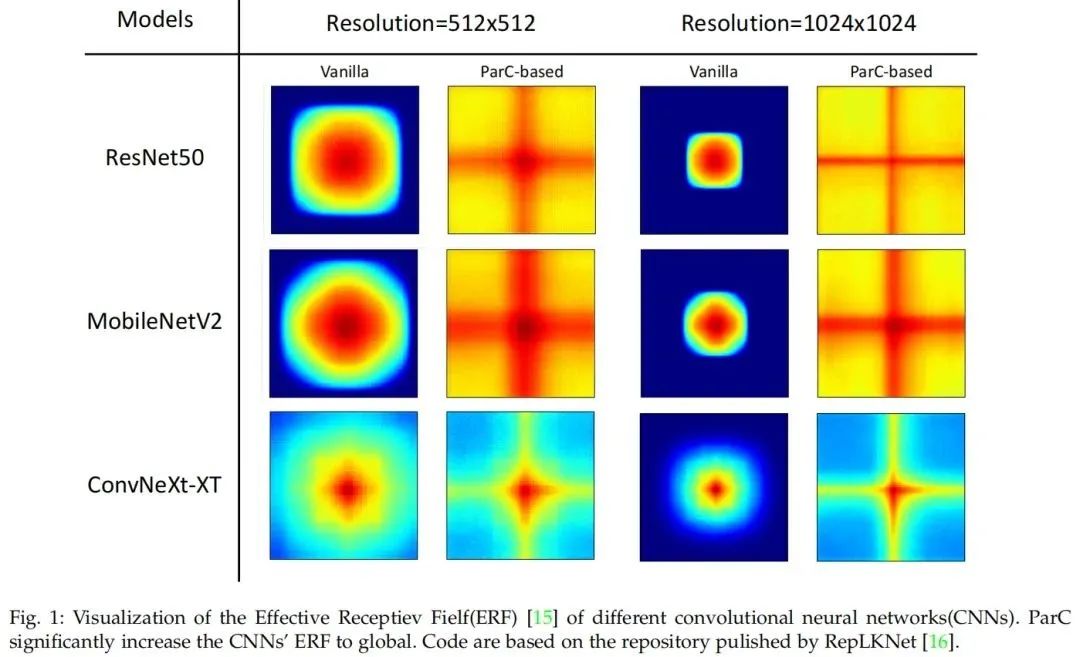
一个自然的想法是结合ConvNets和ViT的优势来设计新的结构。本文提出了一种新的基本神经网络算子,称为位置感知循环卷积(ParC)及其加速版本Fast-ParC。ParC算子通过使用全局核和循环卷积来捕获全局特征,同时通过位置嵌入来保持位置敏感性。
Fast-ParC使用快速傅里叶变换将ParC的O(n2)时间复杂度进一步降低为O(n log n)。这种加速使得在具有大型特征映射的模型的早期阶段使用全局卷积成为可能,但仍保持与使用3x3或7x7内核相当的总体计算成本。所提出的操作可以以即插即用的方式使用:
1)将ViT转换为纯ConvNet架构,以获得更广泛的硬件支持和更高的推理速度;
2)在ConvNets的深层替换传统的卷积,通过扩大有效感受野来提高准确性。实验结果表明,ParC操作可以有效地扩大传统ConvNets的感受野,并且在所有三种流行的视觉任务(图像分类、目标检测和语义分割)中,采用所提出的操作都有利于ViT和ConvNet模型。
7. 只需一次向前推导,深度神经网络可视化方法来了!
原文:
https://mp.weixin.qq.com/s/rzle3EYD4atj9oJ0Xy43aw
论文地址:
https://arxiv.org/abs/2209.11189

写在前面的话
类激活图(CAM)致力于解释卷积神经网络的“黑盒”属性。本文首次提出可学习的类激活方法,通过设计适当损失来迫使注意机制学习有效CAM输出,并只需一次前向推理。在ImageNet上与流行类激活方法比较,取得了优异且有趣的实验结果。最后针对分类错误的情况,作者等人进行了细致而全面的分析。
类激活方法与Motivation简述
深度卷积神经网络对相关决策的可解释性不强,这种“黑盒”属性影响了该技术在安全、医疗等领域的商业应用。由类激活图(CAM)生成的显著图SM(saliency map)描述了对模型决策贡献最大的图像区域,因此是一种为“黑盒”提供可解释理论的方法。
以往的CAM方法分为基于梯度和基于扰动两种,如下图所示:
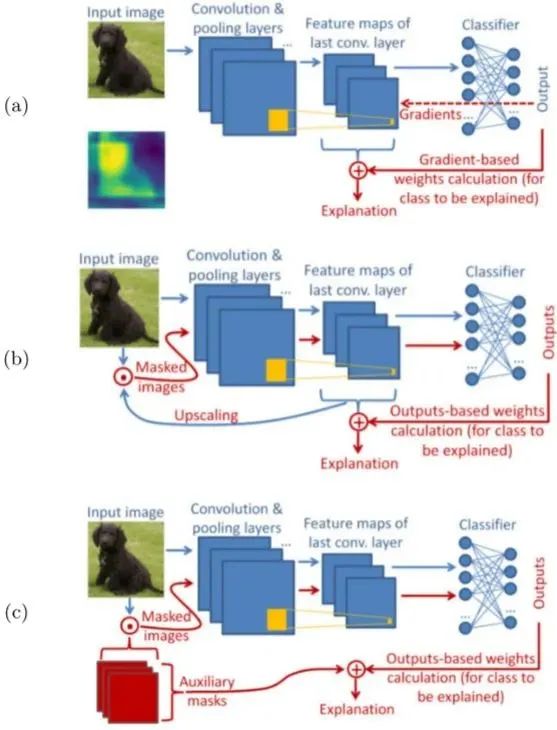
在图1 (a) 中,基于梯度的方法使用从outputs反向传播的梯度计算最后一个卷积层中特征权重,并将特征图加权聚合得到CAM,explanation代表由CAM产生的SM。(常见的有Grad-CAM、GradCAM++)
在图1 (b) 中,基于扰动的方法通常选取模型中不同深度的特征图,或随机扰动图(图1 (c) ),作为掩码与输入图像点乘,得到扰动输入,最后通过前向传递扰动输入来生成SM。(常见方法有SIDU、Score-CAM、SISE、ADA-SISE、RISE)
然而这些方法要么基于反向传播梯度,要么在推理阶段需要多次前向传递,因此引入了大量的计算开销。另外,这些方法在关注模型解释的同时,忽略了对训练集的有效利用。
因此本文提出了一种仅需一次前向传递的方法,同时引入注意机制,用可学习的方法,使训练集得到了充分利用。
一些可能的思考与总结
本文为进一步解释“黑盒”模型,提出了一种可学习的CAM方法,并产生了具有竞争性的实验结果。但是有两个问题笔者不得其解。
第一个问题就是,本文方法通过训练集大量训练获得四个经验下的正则化参数,那么相比其他方法,是否存在额外增加了实现成本?另外,如果将此参数应用于其他数据集上是否能保持原有性能,到时候如果不能是不是又要重新从训练集中获取呢?
第二,对于ImageNet中的某些包含多标签图像,错误分类的原因是分类器已经对某些类别形成既定的学习认知。那么假如没有训练这个环节,是不是就能减少对某些已确定类别的错误识别呢,或者说,有没有其他方法能减少这种情况的发生呢。
8. AI框架历史演进和趋势探索
原文:
https://mp.weixin.qq.com/s/a3GaHwBNq7KJO0Dex-xOUg
AI框架是一种底层开发工具,是集深度学习核心训练和推理框架、基础模型库、端到端开发套件、丰富的工具组件于一体的平台。
有了AI框架,工程师在工作时调试算法,就可以更快速、更高效。通俗一点讲,AI框架相当于是AI时代的操作系统,如同PC时代Windows,移动互联网时代的iOS和安卓。
AI框架发展现状和趋势
AI框架的历史并不算长,从2010年诞生的Theano算起,至今不过十二年时间。2017年后,早期的Theano、Caffe、Torch等框架逐渐销声匿迹,2016年前后出现的TensorFlow(谷歌)、PyTorch(Facebook)、飞桨(百度)逐渐占据市场。
从目前市场占有情况看,产业界以TensorFlow为主,学术界以PyTorch为主。与TensorFlow过于注重工业,PyTorch专注学界不同,飞桨的特性在于工业学界两手抓,通过动态图自动解析编译静态图的技术,兼顾了学界的灵活,同时也实现了产业界希望的高效。
除了TensorFlow、PyTorch、飞桨,深度学习框架还包括由Amazon设计研发并开源的MXNet、微软在github上开源的CNTK、华为推出的MindSpore、北京一流科技有限公司开发的OneFlow,以及清华大学自研的Jittor,和腾讯、字节跳动、360开源的Angel、BytePS、TensorNet。
过去这些年,AI框架已形成较为完整的技术体系,当前主流AI框架的核心技术演化出三大层次,分为基础层、组件层和生态层,其中基础层实现AI框架最基础核心的功能,具体包括编程开发、编译优化以及硬件使能三个子层。
从技术生态体系中的功能定位看,AI框架对下调用底层硬件计算资源,对上支撑AI应用算法模型搭建,提供算法工程化实现的标准环境,是AI技术体系的关键核心。
AI框架技术持续演进,历经萌芽阶段、成长阶段、稳定阶段,当前已进入深化阶段。AI框架正向着超大规模AI、全场景支持、安全可信等技术特性深化探索。
AI框架面临的挑战
然而在这个探索的过程中,面临诸多挑战。在超大规模AI方面,当前超大规模AI成为新的深度学习范式。OpenAI于2020年5月发布GPT-3模型,包含1750亿参数,数据集达到45T,在多项NLP任务中超越了人类水平。这种超大规模的模型参数及超大规模的数据集的AI大模型范式,实现了深度学习新的突破。
产业界和学术界看到这种新型范式的潜力后纷纷入局,继OpenAI后,华为基于MindSpore框架发布了盘古大模型、智源发布了悟道模型、阿里发布了M6模型、百度发布了文心模型等。超大规模AI正成为下一代人工智能的突破口,也是最有潜力的强人工智能技术。
超大规模AI需要大模型、大数据、大算力的三重支持,这就对AI框架提出了新的挑战,比如内存墙,大模型训练过程中需要存储参数、激活、梯度、优化器状态,鹏程 盘古一个模型的训练就需要近4TB的内存。算力墙,以鹏程 . 盘古2000亿参数量的大模型为例,需要3.6EFLOPS的算力支持,要求必须构建大规模的异构AI计算集群才能满足这样的算力需求,同时算力平台要满足智能调度来提升算力资源的利用率。还有通信墙、调优墙、部署墙等。
在全场景支持方面,随着云服务器、边缘设备、终端设备等人工智能硬件运算设备的不断涌现,以及各类人工智能运算库、中间表示工具以及编程框架的快速发展,人工智能软硬件生态呈现多样化发展趋势。但主流框架训练出来的模型却不能通用,学术科研项目间难以合作延伸,造成了深度学习框架的“碎片化”。
目前业界并没有统一的中间表示层标准,导致各硬件厂商解决方案存在一定差异,以致应用模型迁移不畅,增加了应用部署难度。因此,基于AI框架训练出来的模型进行标准化互通将是未来的挑战。
然而即使面临诸多挑战,过去两年,行业一直在持续探索,并取得一定突破,如2020年华为推出昇思MindSpore,在全场景协同、可信赖方面有一定的突破;旷视推出天元MegEngine,在训练推理一体化方面深度布局等。
整体而言,在人工智能体系中,AI框架处于贯通上下的腰部位置,下接芯片、上承应用,是一个关键枢纽,是推动AI应用大规模落地的关键力量。因此对于企业来说,克服AI框架当前面临的挑战,不断探索新趋势,进行技术创新,完善技术、功能和生态是关键。
- END -

原文标题:【AI简报20221021期】英特尔i9-13900K重夺PC性能桂冠、RISC-V可靠矢量处理弯道超车
-
RT-Thread
+关注
关注
31文章
1272浏览量
39908
原文标题:【AI简报20221021期】英特尔i9-13900K重夺PC性能桂冠、RISC-V可靠矢量处理弯道超车
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
RISC-V,即将进入应用的爆发期
英特尔计划明年AI PC出货一亿台
RISC-V拥有巨大市场潜力的原因
AI PC市场爆发,英特尔、高通相继推出新一代AI PC芯片,战况火热升级
高通Copilot+ PC独占期将尽,英特尔与AMD笔记本11月迎AI新纪元
risc-v多核芯片在AI方面的应用
AI PC市场争霸:英特尔、AMD、高通芯片算力谁主沉浮?
英特尔澎湃动力驱动商用AI PC,打造AI+时代的新质生产工具
英特尔酷睿Ultra通过全新英特尔vPro平台将AI PC惠及企业
英特尔推出全新vPro平台,将AI PC的优势延伸至商用领域
英特尔:2025年将为1亿AI PC提供核心处理器
英特尔vPro让AI PC造福企业
开启AI PC新纪元!英特尔酷睿Ultra重磅发布,胜任200亿参数大语言模型






 工商网监
工商网监
评论