 基于性别的暴力(GBV)的语言表达如何影响责任认知
基于性别的暴力(GBV)的语言表达如何影响责任认知
主要贡献
论文详细分析了意大利关于GBV的新闻报道中人类的责任观念,证明了特定语法结构和语义框架的会引发不同的责任认知,并且可以被自动建模。
-01-
摘要
不同的语言表达可以通过强调某些部分从不同的角度来概念化同一事件。该论文调查了一个具有社会后果的案例:基于性别的暴力(GBV)的语言表达如何影响责任认知。文章建立在这一领域先前的心理语言学研究的基础上,并对从意大利报纸的语料库中自动提取的GBV描述进行了大规模的感知调查。
然后,训练回归模型,预测GBV参与者对不同的感知责任维度的显著性。文章最好的模型(微调后的BERT)显示了稳健的整体表现,在维度和参与者之间有很大的差异:显著的关注比显著的指责更可预测,犯罪者的显著性比受害者的显著性更可预测。
使用不同表示的岭回归模型的实验表明,基于语言学理论的特征与基于单词的特征相似。文章表明不同的语言选择确实会引发不同的责任认知,而且这种感知可以自动建模。这项工作可以成为提高公众和新闻制作人对不同视角所产生的后果认识的核心工具。
-02-
简介及背景
同样的事件可以用许多不同的方式来描述,这取决于报告者和他们所做的选择。通过选择一些特定的词,可以为读者提供一个关于发生了什么的具体视角。
一篇新闻的写作方式,严重影响了读者感知所描述事件中责任归因的方式。
图1:“骑自行车的人撞上车门”
图1:“汽车司机打开车门撞到骑自行车的人”
图1:“骑自行车的人在第五街的交通事故中受伤”
图1:“自行车和汽车的碰撞”
使用不同的标题来说明当相同的事件从不同的角度的描述时,可以导致不同的对参与者责任归属的看法。
图1说明了如何从不同的角度报告同一事件其方式确实会影响对参与者责任的感知。文章研究在基于性别的暴力(GBV)这一社会相关现象的背景下,使用NLP工具来解开责任归因。针对妇女的暴力行为是令人担忧的普遍现象,因此经常在新闻中被报道。
Pinelli和Zanchi在意大利新闻中观察到,在对杀害女性的描述中,具有不同及物性水平的句法结构——也就是及物主动结构,到被动和反使役结构,对应于归因于(男性)犯罪者的不同程度的响应性。
例如,当“he killed her(他杀了她)”(主动/及物)完全明确表达了主动行为者的参与,但“she was killed (by him)她是(被他)杀死的”(被动),这种表达方式就将注意力从主动行为者上转移开来;再比如“themurder(谋杀)”或者是“the event(事件)”的表达方式,就将重点从两个参与者转移到事件的背景中。
在一篇相关的文章中,Meluzzi等人通过对意大利语中人工构建的GBV报告的调查,研究了论证结构构建对责任归因的影响。他们的研究结果进一步证实了Pinelli和Zanchi关于读者对犯罪者和受害者的能动性和责任影响的发现。这两项研究的结果与之前的心理语言学研究结果一致,表明在任何层面上涉及暴力的事件中,行为人的语言背景阻碍了他们的责任,并促进了对受害者的指责。
基于这样的框架选择,普通读者将如何看待所描述的事件?我们能自动模拟这种感知吗?
本文回答上述问题,仍然基于意大利新闻中对杀害女性的描述,并利用框架语义作为一种理论和实践工具,以及最新的NLP方法。
使用特定的预先选择的语义框架,使用最先进的语义解析器自动提取,文章从意大利报纸中识别出对GBV事件的描述,通过大规模的调查来收集人类的判断,要求参与者阅读文本,并将一定程度的责任归属于犯罪者、受害者,或一些更抽象的概念(例如,“嫉妒”、“愤怒”)。更多细节见2。
文章开发一系列回归模型(从头开始以及预先训练的transformer模型),利用从表面到框架的各种语言线索来自动建模责任感知。模型的训练目标是预测人类的感知分数。文章实现了与基于Transformer model的模型的强相关性。调查和结果分析的细粒度特征也允许各个方面的预测复杂性的差异。第3节中讨论建模和评价。
结果表明,不同的语言选择确实触发了不同的责任感知,而且这种感知可以自动建模。这一发现不仅证实了以前(人工)在小规模上进行的研究,而且也为文本进行大规模分析及其效果提供了可能。
-03-
构建【谋害女性感知数据集】
为了构建这个数据集,作者采用众包的方式,设计了一个在线的问卷调研。具体来说,作者收集了关于2015至2017年间,意大利发生的937起杀害女性案件的新闻报道,从中抽取句子展示给众包人员并要求其对句子所表达的责任程度进行打分。问卷结果表明,语义信息和句法结构明显影响读者对“谋害女性事件”的看法。下面将详细说明作者如何设计调研问题。
3.1问题设定
对案件采取不同的描述方式,会导致读者对“案件参与者应承担多大责任?”这一问题产生不同的看法。作者首先将“责任”这一复杂的概念拆解成三个维度:
- FOCUS:句子关注的是否是加害人?
- CAUSE:句子所描述的事件是否主要由人引起?
- BLAME:句子是否将责任归咎于加害人?
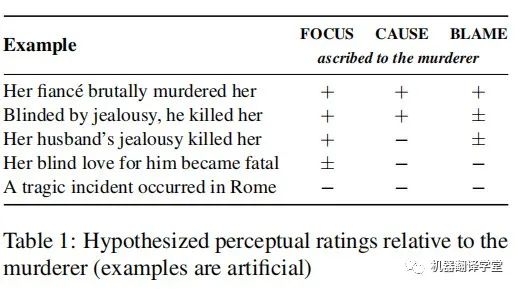
表1用人工构造的句子展示了这三个维度的区别。针对上述三个问题,表中+、-、±代表句子可能如何被读者解读。例如,第一、第二个句子都更加关注凶手(FOCUS +)并且强调他的行为致使案件发生(CAUSE +),但是第二句话将凶手描述为“被嫉妒蒙蔽了双眼”,暗示凶手不必为其行为承担全部责任(BLAME ±)。注意读者的看法本质上是主观的,因此这些例子不该被视为任何形式的“黄金准则”。
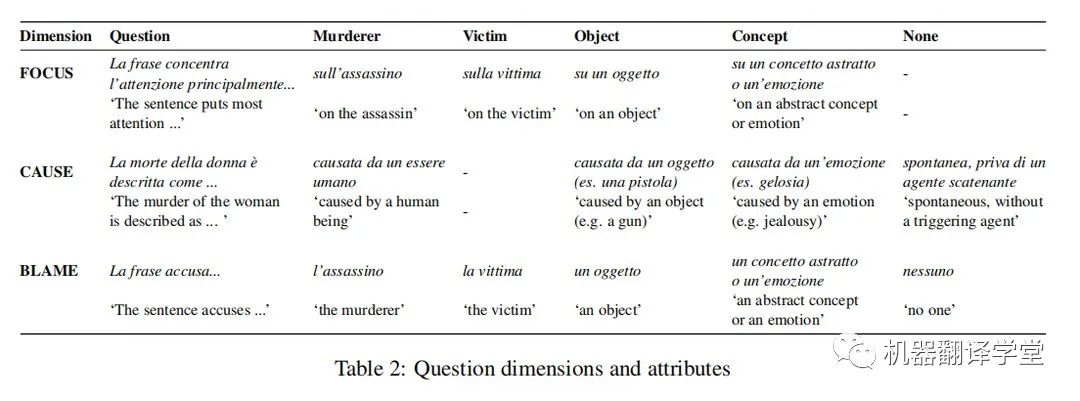
为了正确判断读者认为凶手应承担责任的程度,作者还分别针对victim(受害人)、object(如武器)、concept(抽象概念)、emotion(如嫉妒)或nothing(不追究)设计了上述三个维度的问题。作者要求众包人员按照五分制对每一类问题进行打分,参与者也可以认为句子与谋杀案无关直接跳过它。根据试点实验的初步结果,作者对每个类别的问题做了些轻微的调整:例如因为句子总是关注某事(FOCUS),所以省略了FOCUS中的none类别,等等。表2展示了完整的调研问题。
3.2句子选择
交给众包人员进行评分的句子分两步选出:首先使用LOME解析器自动抽取语义信息,这些信息与SpaCy自动依赖解析工具结合,对句法结构进行分类。例如,“he murdered her”将被分类为“KILLING/active”,代表“杀人”的语义和主动的句法表达;“she died”被分类为“DEATH/intransitive”;“the tragedy”被分类为“CATASTROPHE/nonverbal”。
第二步,作者设计了在不同程度上强调谋杀案件的典型语义集合,并在至少包含一个典型语义的句子中进行随机采样。具体来讲,作者使用FrameNet框架手动注释Pinelli和Zanchi中的例句,并选择那些表述“受害者死亡事件”词语(如killed、died、dead、incident等)的语义来构造典型语义集。
最终得到的语义集合为{KILLING,DEATH,DEAD_OR_ALIVE,EVENT,CATASTROPHE},所有语义都可以用来描述完全相同的事件,只是具有不同的动态性(已经死亡或者将要死亡)、能动性(凶手杀人或者受害人死亡)和普遍性(某人死亡或者某事发生)。作者使用这种方法为每一个“语义信息/句法结构”类别采样了相同数目的句子。
3.3众包实现细节
作者考虑到众包人员分析复杂句子的认知负荷,以及阅读一个主题沉重且痛苦的文本的情感负荷,每个参与人员只需在一组句子(50句)的三个维度之一上打分。为了平衡“每句话注释的数量”和“注释的总句子数”,作者为每句话每个维度安排10个众包人员。这意味着完整的注释一组句子需要30个众包人员。
为了在事先不知道反馈率(众包人员质量)的情况下,将众包人员均匀的分配在每组句子和每个维度之间,作者创建了60个众包小组(注释20组句子,每组50句,因此共1000个句子且每个句子三个维度)并将参与者分配到滚动的小组中:每次开放一个组,一旦达到要求的参与者数量小组就会自动关闭,然后打开下一个组。一旦一个组被填满就手动检查响应的完整性和质量。
由于标注任务的主观性,注释没有错误的回答,作者设定如果注释至少满足以下三个标准中的一个,则认为其质量较低:(i)参与者完成问卷的速度快得令人难以置信;(ii)参与者连续将句子标记为不相关并跳过;(iii)参与者总是给每句话同样的评分;作者在意大利几所大学不同专业的本科和硕士学生中分发调查平台的链接,并匿名收集回答,仅要求参与者说明他们的性别、年龄和职业。
3.4结果
作者最终的数据集涵盖了400个句子,共有240名参与者对其进行了评级(153名女性,86名男性,1名非二元性别;平均年龄23.4)。表3给出了跨句子的评价得分汇总。作者给出了所有参与者和所有句子的平均分(绿色部分,在0~5的范围内),以及句子间平均分的标准差。总的来说,对应于行凶者的属性往往有更高的平均分,但方差也比其他属性更高。由于任务固有的主观性,并且结果与之前关于感知规范的研究一致,作者没有计算注释者之间的一致性分数。
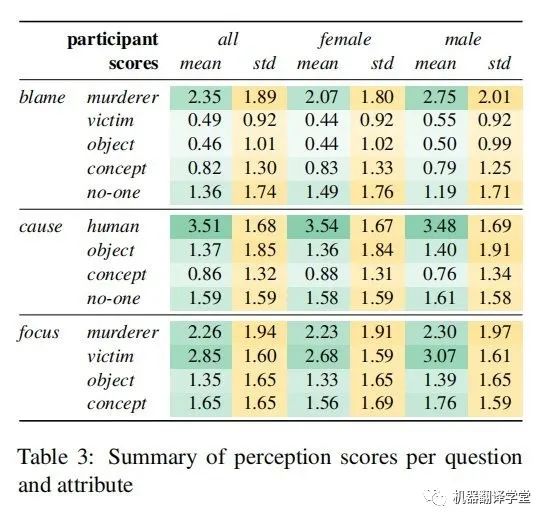
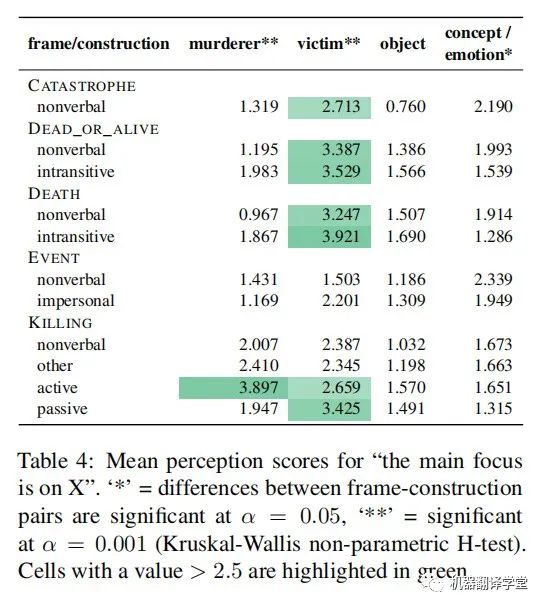
表4按语义信息和句法结构划分,显示了FOCUS问题的平均得分。这显示出了显著的效果:包含KILLING语义的句子倾向于将更高的FOCUS放在凶手身上,当使用主动结构时更是如此。同时,在主动或被动结构中包含CATASTROPHE, DEAD_OR_ALIVE、DEATH和KILLING语义,会增加受害者的FOCUS。
另一方面,object的FOCUS得分上没有显著差异,concept或emotion的FOCUS得分上有显著但较小的差异。在每一种情况下,研究结果都符合作者基于语言学理论的预期:如果一个事件参与者在谓词中进行了词汇编码,并且需要在语法上进行表达,那么这个参与者更有可能被认为处于关注状态。基于句子的内容,以及在词汇上编码了受害者或杀手的几个典型语义(如KILLING),人们会更多地关注凶手和受害者,而无生命的concept或emotion是非必要的。
-04-
感知分数预测
在本文中,作者将该任务建模为一个多输出回归任务:给定一个句子,作者希望预测一个感知向量,其中该向量每一维代表问卷中一个特定的Likert维的值。
4.1 参与者聚合
作者首先对每句话和每个参与者的感知值计算z-score(也叫标准分数,是一个数与平均数的差再除以标准差的过程。在统计学中,标准分数是一个观测或数据点的值高于被观测值或测量值的平均值的标准偏差的符号数。),然后取参与者的平均值。分别计算每个Likert维度和参与者的z-score,以考虑两种类型的变异性:
1)维度内偏好,指的是不同的参与者对分数范围的不同使用:根据自信程度和其他因素,参与者可能会选择大量使用范围的端点(例如,经常分配“0”或“5”)或集中在范围的特定部分(例如,在中心附近或靠近高点或低点)。
2)维度间偏好,指的是参与者总是倾向于给特定维度分配更高或更低的分数的可能性。例如,一些参与者可能总是给“blame on the murderer”和“blame on the victim”更高的分数。
通过对z-score的感知值进行回归,作者希望模型预测出句子中是否存在明显偏见(例如,这个句子是否将高于平均水平的责任推给了受害者?对凶手的关注低于平均水平?)
4.2 评价方法
作者从多个角度对此多输出回归问题进行评价。
1)Root Mean Squared Error (均方根误差,RMSE)和{R^2}(均方误差),它估计了由回归模型解释的感知分数变化的比例。作者分别计算了每一个维度和维度平均值的{R^2}。
2)Cosine (余弦相似度,COS),它度量了答案和预测结果之间的余弦相似度,并提供在映射中保存维度之间关系的程度的估计。
3)Most Salient Attribute (MSA),作者将回归评估为预测哪个Likert维度对每个问题具有最高(z-score)感知值的分类任务的准确性(实现为简单地计算argmax对每个问题对应的输出维度)。例如,对于一个特定的句子,“concept”是责备问题得分最高的维度,这意味着“blame on a concept”在这个句子中比其他句子更突出。
注意,每个维度的z-score是独立计算的,因此,具有最高z-score的维度不一定也具有最高的绝对值。类似于给特定维度分配更高或更低分数的风险,在这种情况下,参与者在指责问题上给“杀人犯”的分可能比“concept”多,即使在“concept”非常突出的句子中也是如此。在这种情况下,“concept”的绝对值总是比“murderer”低,但在“concept”得分相对较高、“murderer”得分相对较低的句子中,“concept”的z-score可能会更高。
4.3 模型
作者比较了两种模型,分别是岭回归模型(一种使用L2正则的线性回归模型)和预训练transformer模型。前者在不同类型的输入特征上面进行训练,后者则经过微调后回归预测多输出。
特征(用作岭回归模型的输入)
特征分为三类:
1)表面特征:代表输入句子的词法级别的特征,分别使用bag-of-words (bow)模型和FastText (ft)模型的输出特征。
2)框架语义特征:通过frame semantic parser配合bow模型得到的在语义级别上略高于表面特征的表示,包括f1、f2、f1+、f2+。
3)句子特征:transformer模型产生的句子级别的表示,分别使用了SentenceBERT (sb)、XLM-R、BERT-IT Mean (bm) 和 XLM-R Mean (xm)提取特征。
预训练transformer模型
作者在预训练transformer编码器的后面接上了有一个简单的线性层构成的神经回归模型。作者分别实验了不同的BERT变体。包括Italian BERT XXL Base (BERT-IT)、BERTino、Multilingual BERT Base、Multilingual DistilBERT、XLM-RoBERTa Base。
4.4结果
表5显示了RMSE、COS和{R^2}指标测试集的主要结果。作者列出如下观察结论:
经过微调的单语BERT模型在所有测试中表现最好,其总体{R^2}分数约为0.45,这意味着模型成功预测了感知分数中近一半的方差。
多语言BERT模型(mBERT和XLM-R)的表现均较差,平均{R^2}为0.38或更低。
有趣的是,普通的蒸馏版BERT对比原始BERT性能有所下降,但意大利语版蒸馏的BERT(BERTino)的性能没有下降,甚至比原始模型略好。
{R^2}的下降并不总是与余弦分数的下降一致:例如,XLM-R分数比BERT-IT/base低0.06 {R^2}分,但余弦分数只下降0.01,而mBERT/dist在{R^2}上损失0.10分,在COS上损失0.09分。因此,似乎有些模型(如XLM-R)在预测每个异常得分的确切大小方面不太准确,但在捕捉跨维度的总体得分模式方面相对较好。
另外,虽然岭回归模型的表现比transformer差很多,但比较不同特征之间的结果对于理解预测感知需要什么信息是有帮助的:
基于表面和框架特征的回归模型表现相似,{R^2}分数在0.20左右(f2为负离群值),而具有神经特征的模型更好({R^2} 0.28-0.33)。
对于那些基于transformer提取得到的特征训练的脊模型,作者发现意大利语版本的BERT (bm)的平均最后一层表示的结果最好,而基于XLM-R (sb和xm)的两种模型得分略低。
通过比较不同问题和属性的{R^2}分数,还可以发现预测难度的巨大差异:
例如,在各个模型中,blame on murderer得到了很好的分数,而blame on victim的分数相对较低,即使是最强的模型(例如BERTino的0.24),而在基线(或更低)分数较弱的模型——特别是蒸馏mBERT,它在其他属性上表现不错。
Caused by no-one 是最难预测的,没有模型得分在0.10以上。
Focus问题具有总体上最好和最一致的性能,特别是对于意大利语版本的BERT模型,对于四个属性中的每一个都实现了不错的性能(0.46- 0.66 {R^2})。
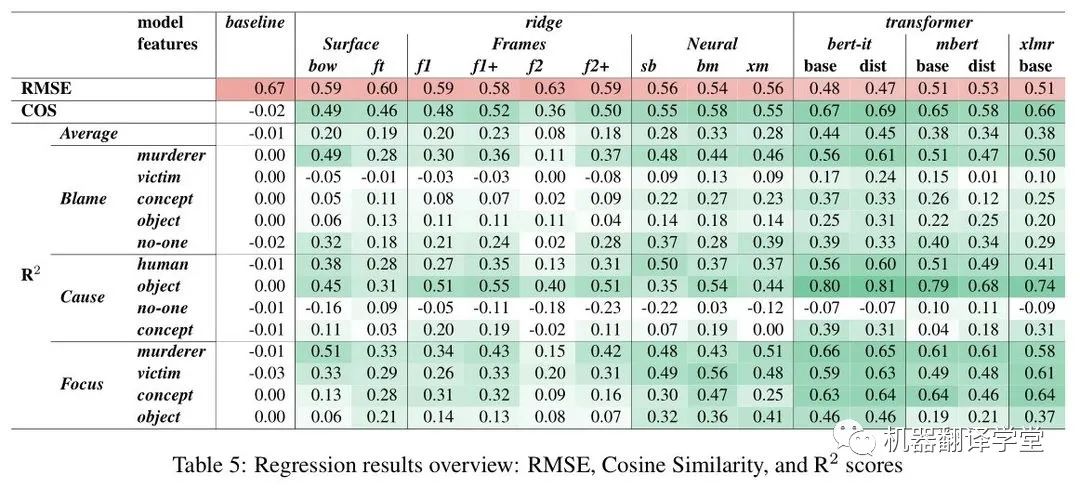
这种模式也反映在MSA中(表6):对于focus类别,它基本上更容易预测的维度与最高的得分比Blame和Cause。然而,对于每个问题,所有模型的表现都好于概率水平,其中BERTino的综合得分最高(56-72%)。
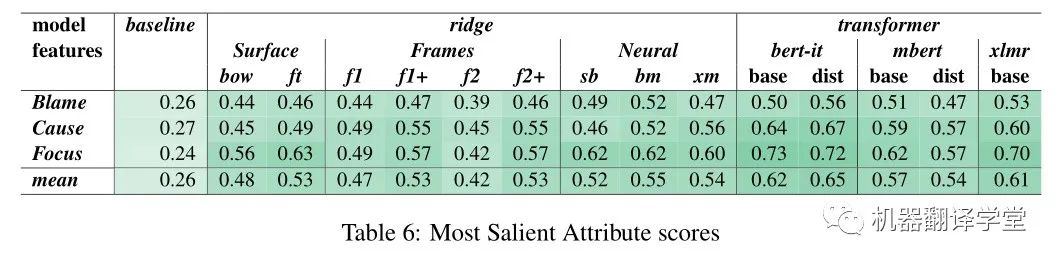
在岭回归模型中,相对于基于表面特征的模型,基于BERT特征的模型的性能增益(BERT特征比表面特征的增益)在属性之间有很大差异。例如,bow模型有一个令人惊讶的高得分的指责杀人犯({R^2} 0.49),只有适度的收益从BERT-IT 和 BERTino模型(resp.+0.06和+0.12分)。相比之下,bow在专注概念上得分较低({R^2} 0.13),而BERT-IT和BERTino得分较高({R^2} 0.63/0.64)。
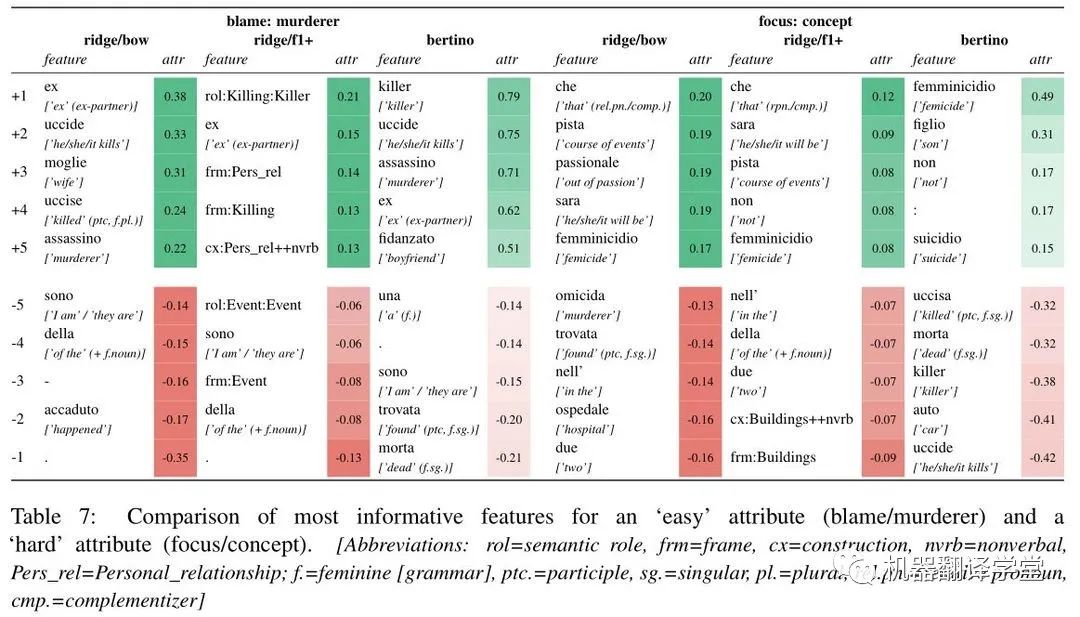
为了进一步了解模型之间的差异,作者进行了特征归因分析。blame on murderer 和 focus on concept的结果如表7所示。对于杀人犯的责任,三种模型似乎都聚焦于相似的词汇项:例如,“uccide”(“(he) kills”)在脊回归和微调BERTino模型中都有很高的正归因值,在f1+中作者发现KILLING框架的正归因值,这是对杀人相关词汇的抽象。
作者还发现,个人关系(‘wife’, ‘ex’, PER-SONAL_RELATIONSHIP )在所有三种模型中都得到了积极的归因。相比之下,作者发现了“accaduto”(“happened”)的负归因值以及bow和f1中相应的EVENT框架,这与§2.4中讨论的观察结果完全吻合。由于对概念的关注,三种模型之间没有明显的深刻区别。
作者确实在每个模型中发现了几个直观的相关特征:"passionale"("out of passion")和"femminicidio"("femicide")可以测试句子可以聚焦的概念的集合,而"omicida"("murderer/murderous’")和"killer"可以被视为强调人类主体的作用,而不是一个抽象的概念。
-05-
结论与未来工作
论文详细分析了意大利关于GBV的新闻报道中人类的责任观念。文章收集的判断证实了之前关于特定语法结构和语义框架的影响以及它们在读者中引发的感知。
文章研究了不同的NLP架构在多大程度上可以预测人类的感知判断。微调单语transformer获得在多个评估措施的最佳结果,为集成能够识别潜在感知效应的系统作为媒体专业人员的支持工具提供了可能性。
未来,文章也计划对数据进行更详细的分析,考虑受访者在个人和人口统计方面的差异。除此之外,后续实验将侧重于将该方法应用于其他语言和文化背景,既针对基于性别的暴力,也针对其他社会相关主题,如车祸等。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3645浏览量
134569 -
MSA
+关注
关注
0文章
31浏览量
8855 -
nlp
+关注
关注
1文章
488浏览量
22041
原文标题:AACL'22 Best Paper | 不同的表达可能会引发读者不同的想法,可以通过模型自动模拟这种语言“偏见”
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深圳市德上光电科技有限公司招聘LED封装业务员
请问一下,用AVR studio 5如何用C语言表达attiny85的进入睡眠?
招聘照明设计师
招聘销售代表
基于情绪特征用户性别识别

简单的gcc内嵌汇编例分析
AI打LeetCode周赛进入前10%!秘诀:自然语言编程

如何解决LLMs的规则遵循问题呢?






 工商网监
工商网监
评论