 AMD ZEN 4架构的前端内存子系统及AVX-512的深度解读
AMD ZEN 4架构的前端内存子系统及AVX-512的深度解读

AMD 的 Zen 4 架构在科技领域备受期待。因此,在其发布之前,许多关于其性能提升的谣言四处流传。在本文中,我们将对 Zen 4 的无序执行引擎的前端内存子系统,以及 AVX-512等进行深入解读。
希望这个分析让大家对AMD的最新架构有更深入的了解。
概述和框图
从 1000 英尺高处看,Zen 4 看起来很像 Zen 3,但升级分散在整个pipeline中。我们可以将 Zen 4 的情况与 Zen 2 的情况进行比较。在这两种情况下,AMD 在将其移植到新的工艺节点的同时,都在发展一个坚实的架构。
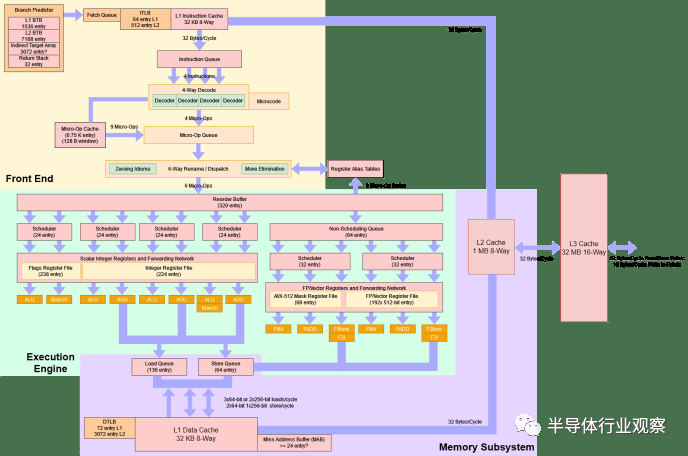
迁移到新的制程节点涉及工作量和风险。英特尔通过众所周知的“Tick-Tock”策略降低了这种风险。每个“Tick”代表一个主要的微架构更改,而每个“Tock”是一个新制程节点的端口,具有非常小的更改。
与 2010 年代初的英特尔不同,AMD 大约需要两年时间才能迁移到新的工艺节点。Zen 2 于 2019 年中期问世,距 Zen 1 于 2017 年初发布大约两年后,从 14 nm 升级到 7 nm。Zen 4 于 2022 年末发布,距 Zen 3 于 2020 年末发布大约两年,并从 7 nm 移动到 5 nm。因此,AMD 的策略可以被描述为“Tick-Nothing-TickTock”。
这是 Zen 3 的比较:
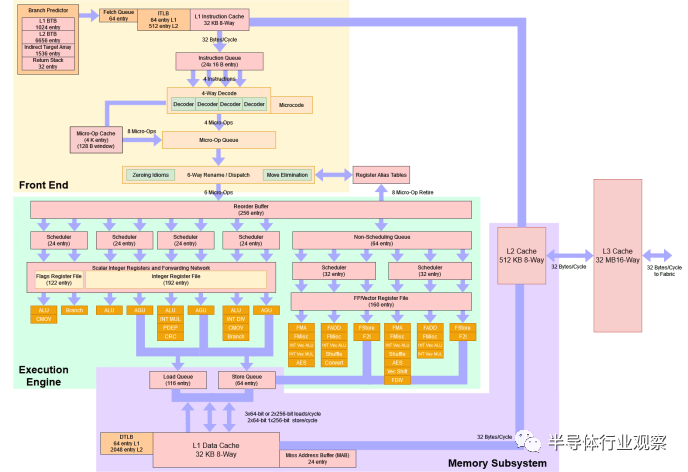
因为数据是公开的,所以为 Zen 3 绘制了更多的执行单元,而为 Zen 4 测试所有这些需要太长时间
前端:分支预测器
CPU 的分支预测器负责将pipeline引导到正确的方向。准确的分支预测器将减少浪费的工作,从而提高性能和电源效率。随着 CPU 增加其重新排序能力,分支预测的准确性变得更加重要,因为在错误预测的分支之后排队的任何工作都是无用的。
一、方向预测
与 Zen 系列中的其他 CPU 一样,Zen 4 的方向预测器有两个overriding levels。制作一个既非常快速又非常准确的预测器可能具有挑战性,因此设计人员通常必须在速度和准确性之间进行权衡。一个压倒一切的预测器试图通过速度优化的 L1 预测器和一个精度优化的 L2 来实现两全其美,如果预测不一致,它会覆盖它。
Zen 4 和 Zen 3 似乎具有类似功能的 L1 预测器,但 AMD 显着增强了 Zen 4 的 L2 预测器。Zen 3 的第二级预测器已经毫不逊色,但 Zen 4 将事情提升到了一个新的水平。它可以识别极长的模式,并且有足够的存储空间来很好地执行,即使有很多分支在运行。
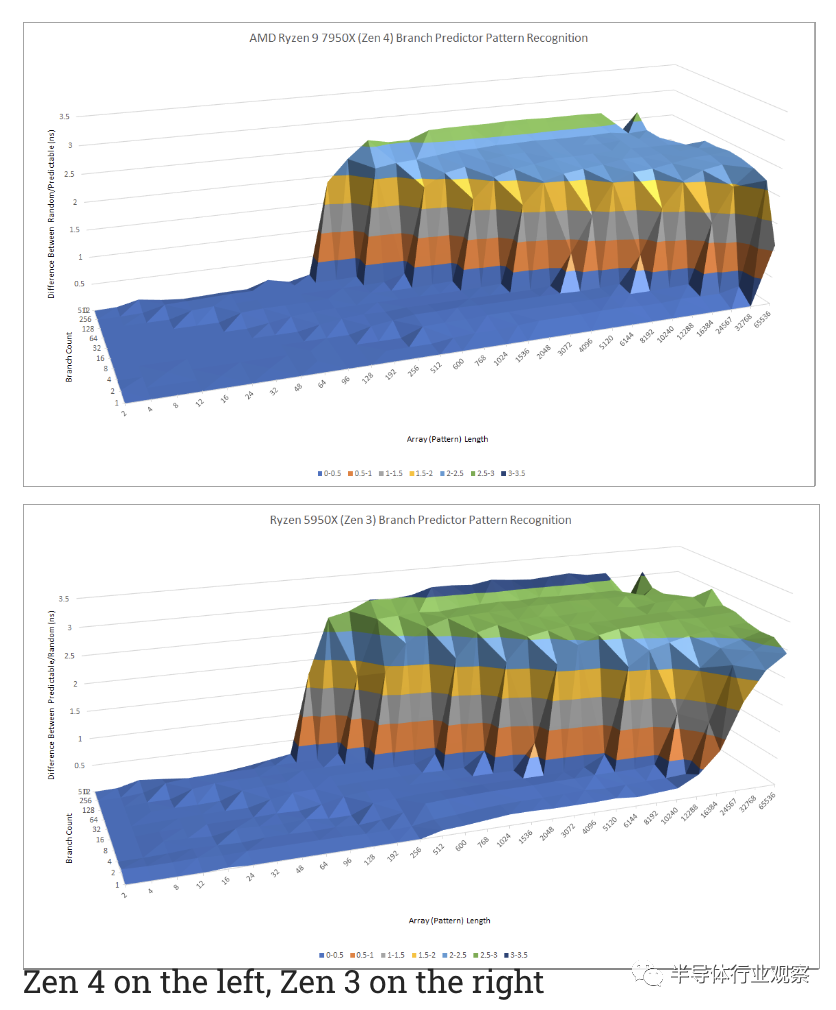
英特尔的 Golden Cove 采取了不同的方法。与早期的英特尔大内核一样,它使用单级方向预测器。Golden Cove 的模式识别能力介于 Zen 4 的 L1 和 L2 预测器之间。
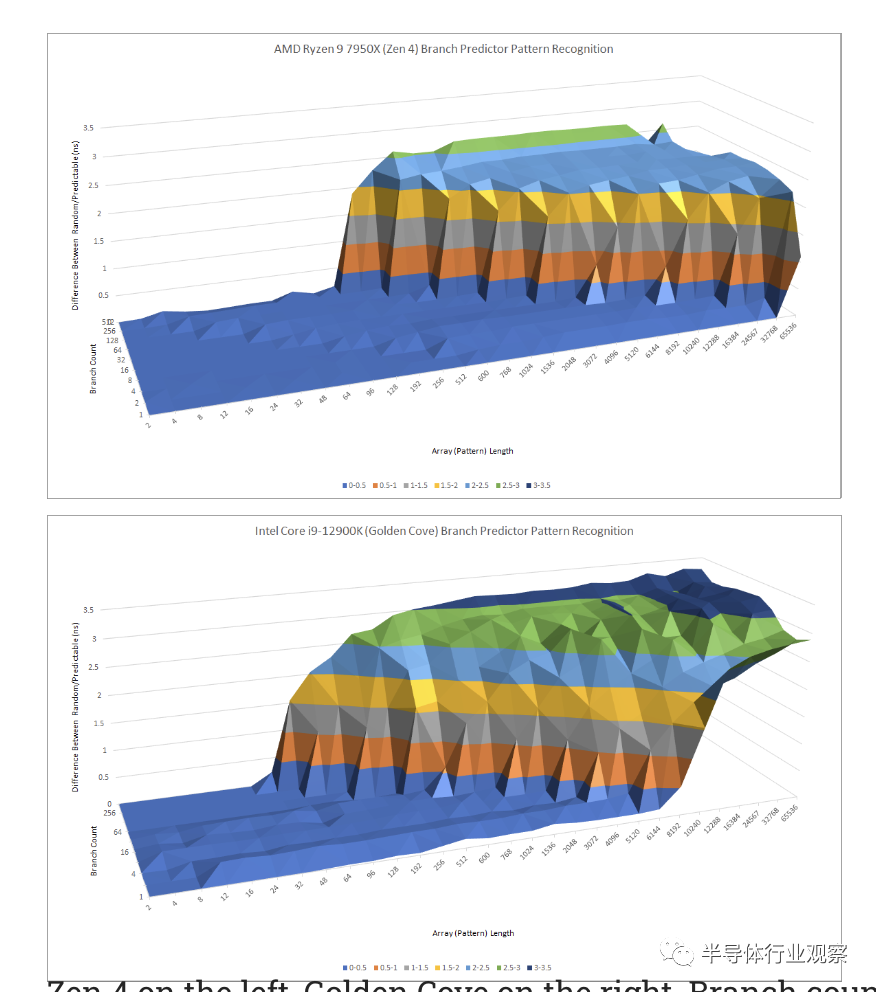
左边是 Zen 4,右边是 Golden Cove。两者的分支数都高达 512
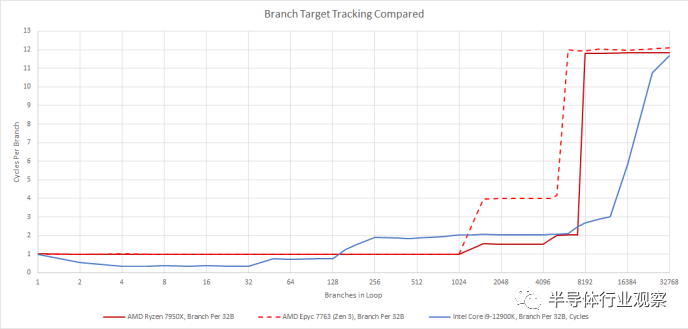
Golden Cove 可能会在难度适中的分支中享有优势,可以由其预测器处理,但不能由 AMD 的 L1 预测器处理。然后,Zen 4 将失去 L2 覆盖的前端带宽。如果一个程序有很多难以预测的分支,Zen 4 将具有显着的优势;Golden Cove 将遭受更昂贵的错误预测。在 Golden Cove 上,错误预测的代价可能特别高,它依赖于保持更多指令在运行中以应对其更高的缓存延迟。如果您遭受错误预测并最终将它们丢弃,那么在您的核心中跟踪大量指令将无济于事。
二、分支目标跟踪
有一个准确的分支预测器很好,但速度也很重要。您不希望过于频繁地停止pipeline,因为您正在等待分支预测器提供下一个提取目标。与 Zen 3 一样,Zen 4 具有两级分支目标缓冲区 (BTB):branch target buffer 设置,第一级非常大且速度快。Zen 3 的 L1 BTB 可以跟踪 1024 个分支目标,并以 1 个周期延迟处理它们,这意味着如果目标来自 L1 BTB,则前端不需要在执行分支后停止。Zen 4 的 L1 BTB 保持相同的 1 个周期延迟,但提高了容量。根据分支密度,Zen 4 的 L1 BTB 最多可以跟踪 3072 个分支目标,但实际上它可能能够跟踪 1024 到 2048 个目标。
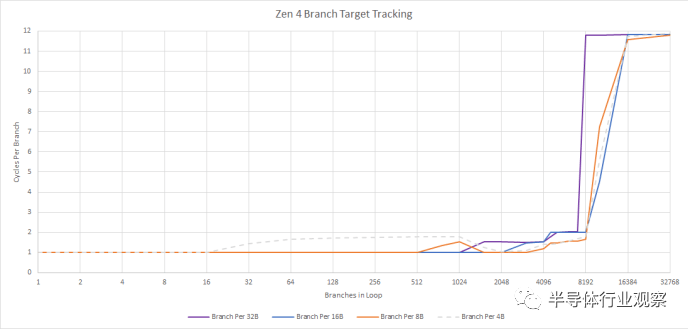
我们已经看到网上声称 Zen 4 具有 1.5K 入口 L1 BTB。在我们的测试中,Zen 4 可能偶尔能够在每个 BTB 条目中存储两个分支目标。先前 Zen CPU 的优化手册详细介绍了此机制。
“如果分支位于同一个 64 字节对齐的高速缓存行中并且第一个分支是条件分支,则每个 BTB 条目最多可以容纳两个分支。”——AMD 系列 17h 处理器的软件优化指南
我们的测试在以前的 Zen CPU 上没有显示这种行为,因为我们只使用了无条件分支。Zen 4 可能使 BTB 条目共享方案更加灵活,解释了当分支间隔为 8 个字节时我们如何看到跟踪的 3072 个分支目标。
Zen 4 的 L2 BTB 大小也略有增加,容量从 Zen 3 上的 6656 个条目增加到 Zen 4 上的 8192 个。更重要的是,Zen 4 的 L2 BTB 更快:Zen 3 在需要来自其 L2 BTB的分支目标时遭受了三个周期的penalty,Zen 4 将penalty降低到一个周期。
三、间接分支预测
间接分支可以到达多个目标。将它们视为实现 switch-case 语句的选项。它们为分支预测增加了另一个难度维度,因为预测器必须在几个可能的目标之间进行选择。AMD 的 CPU 有一个单独的间接目标数组,用于处理指向多个目标的分支。在我们的测试中,Zen 4 似乎能够跟踪多达 3072 个分支目标而没有明显的损失。对于单个分支,Zen 4 看到随着目标数量超过 32 个而增加 penalties ,但此后没有明显的飙升表明预测错误。
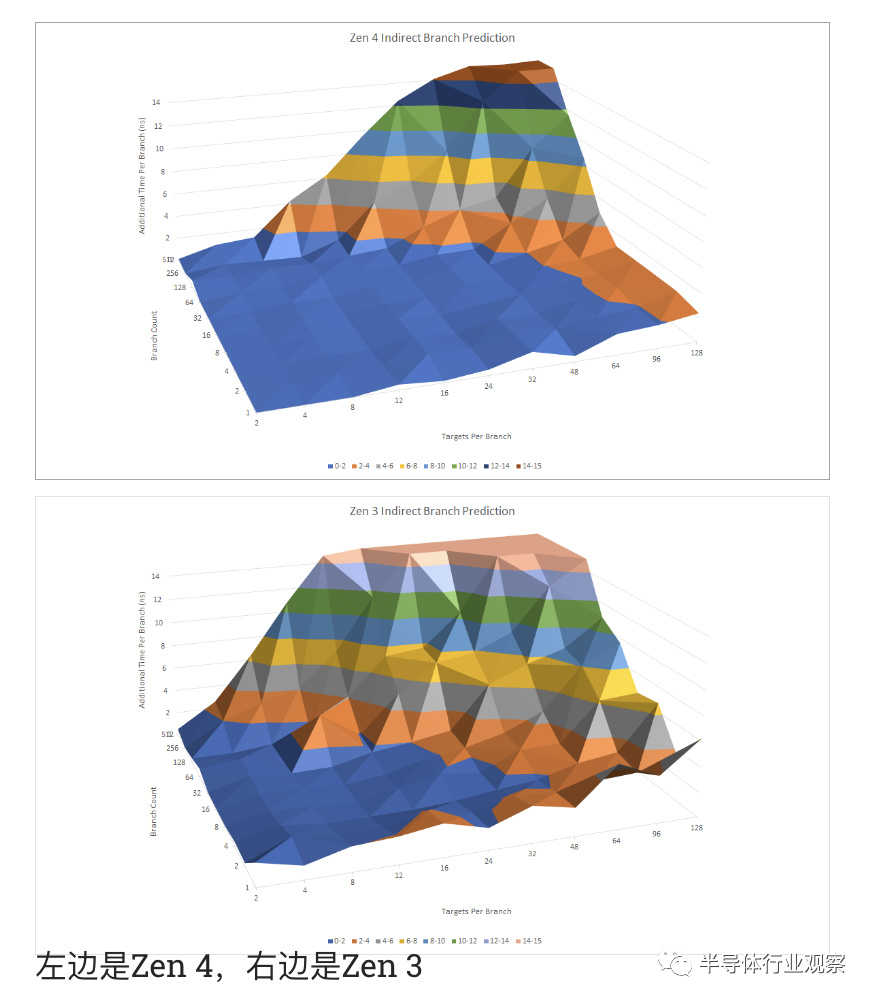
相比 Zen 3,Zen 4 对间接分支的追踪能力显然更好。从间接目标数组中获取目标的 penalties 也较低。
Zen 4 在有很多间接分支的情况下比 Golden Cove 做得更好,但是当少数分支到达很多目标时,Golden Cove 可以更好地应对。当必须在大量目标之间进行选择时,两种架构似乎都会受到某种penalty,但分支的行为仍在预测器的跟踪能力范围内。
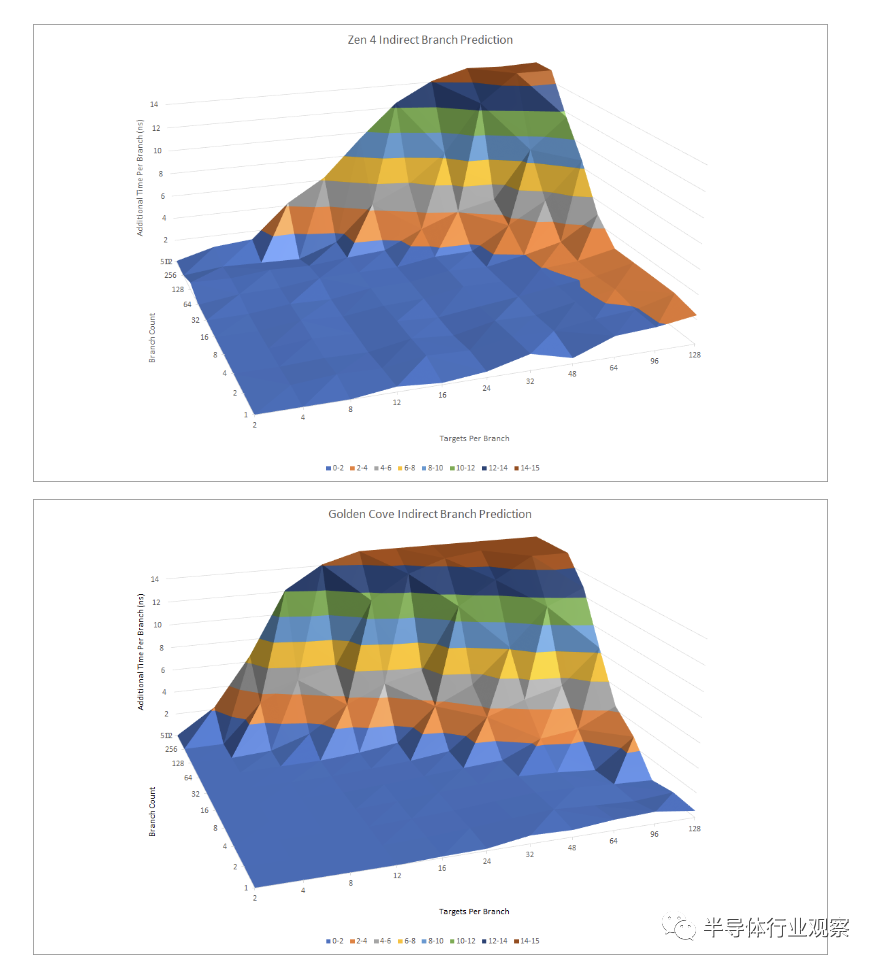
一种猜测是 Zen 4 有一个更大但更慢的间接目标数组。前几代 Zen 的优化手册表明,间接目标数组可用作压倒一切的预测器。如果分支碰巧去了上次去的同一个地方,Zen 可以使用其更快的主 BTB 来提供目标,这意味着间接分支的延迟与其拥有的目标数量相关联。随着 Golden Cove 上目标数量的增加,我们看到分支延迟的增加较少,这表明英特尔正在使用不同的机制。
四、回报预测(Return Prediction)
调用和返回对是间接分支的一种特殊情况,因为返回通常会返回到调用函数的位置。CPU 使用特殊的返回堆栈来利用此行为。在调用时,CPU 将下一条连续指令的地址压入堆栈。当有返回时,它会从返回堆栈中弹出地址。这种非常简单的机制为返回提供了非常准确的预测,因为调用和返回对通常是匹配的。但是,非常深的调用序列可能会溢出堆栈。
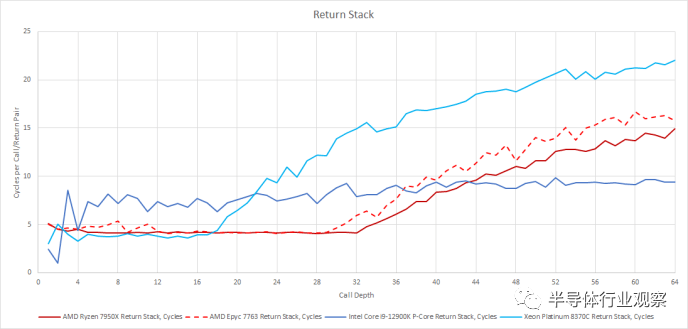
与前几代 Zen 一样,Zen 4 有一个包含 32 个条目(entries)的返回堆栈。不过,AMD 似乎做了一些改进,使得单个线程可以使用所有 32 个条目。英特尔的 Golden Cove 可能有一个返回堆栈,因为这是一种预测返回的有效方法,但与此处测试的其他 CPU 不同。当调用只有两个深度时速度非常快,但随后会减慢并且之后每个调用/返回对的时间不会急剧增加。如果返回堆栈溢出,英特尔可能会顺利过渡到在返回上使用其间接预测器。
前端:获取带宽
一旦分支预测器确定下一步要去哪里,就该获取指令了。Zen 4 与前几代 Zen 一样,可以通过大型微操作缓存加速这一过程。与 Zen 3 相比,Zen 4 将微操作缓存的大小从 4K 增加到 6.75K 条目。我们对 8B NOP 的测试并没有显示出微操作缓存容量增加太多,因为在 32 KB 之后获取带宽会下降。L1i 很可能包含微操作缓存。
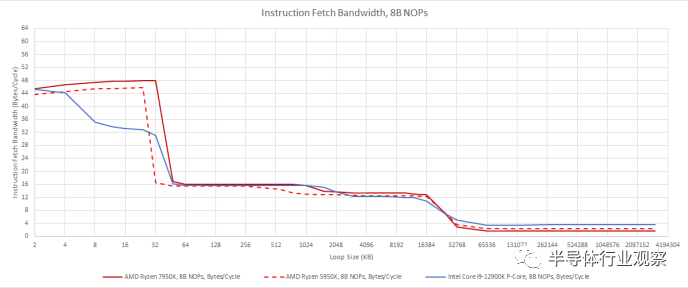
除了微操作缓存和 L1i 之外,指令获取带宽下降但仍然非常不错。Zen 4、Zen 3 和 Golden Cove 都可以从 L2 每个周期维持大约 16 个字节,从 L3 每个周期可以维持略高于 10 个字节。这应该足以防止除了具有大指令占用空间的最高 IPC 代码之外的所有指令带宽瓶颈,因为即使在矢量化代码中,平均指令长度通常也低于 8 个字节。
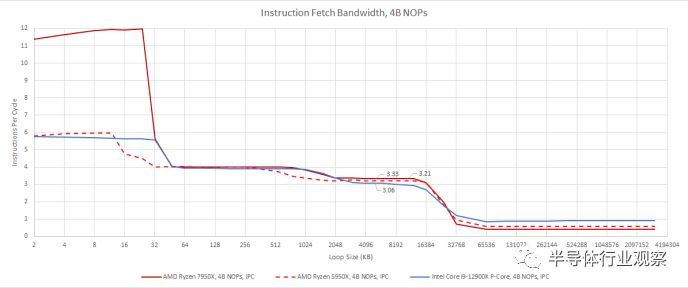
为了使微基准测试复杂化,Zen 4 似乎成对处理 NOP,就像Graviton 3一样。我们每个周期从微操作缓存中获得了荒谬的 12 个 NOP。AMD 表示,微操作缓存每个周期提供 9 个操作,但吞吐量受到下游 6 宽重命名器(renamer)的限制。可能发生的情况是每个重命名器插槽每个周期可以处理两个 NOP。为了解决这个问题,我们使用了一条指令,将寄存器与自身进行异或(XORs )。将寄存器与自身进行异或是一种将寄存器归零的常用方法,大多数重命名器都会消除这种情况。
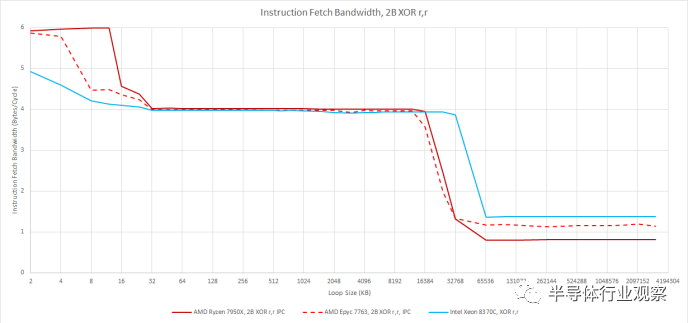
但重要的部分是,XOR r,r 的行为就像一条正常指令,一直到重命名器(renamer)。我们现在还可以看到微操作缓存和 L1i 吞吐量之间的差异。一旦 Zen 4 错过 op 缓存,吞吐量就会受到 4-wide 解码器的限制。与前几代 Zen 一样,L1i 可能比较低的缓存级别提供更多的指令获取带宽。但是 Zen 4 的运算缓存的大小意味着它可能可以处理需要大量指令带宽的大多数情况。如果一个程序有足够大的代码足迹溢出操作缓存,并且有很多长指令,它也可能会溢出 L1i。
重命名/分配(Rename/Allocate)
在无序执行的 CPU 上,重命名器(renamer)充当有序前端和无序后端之间的桥梁。它的主要工作是分配后端资源以跟踪运行中的操作,以便它们可以按程序顺序正确提交。重命名器也是一个方便的地方,它可以使后端操作更高效。Zen 4 的重命名器能够打破 zeroing idioms和register to register MOVs之间的依赖关系,其行为与 Zen 3 非常相似。
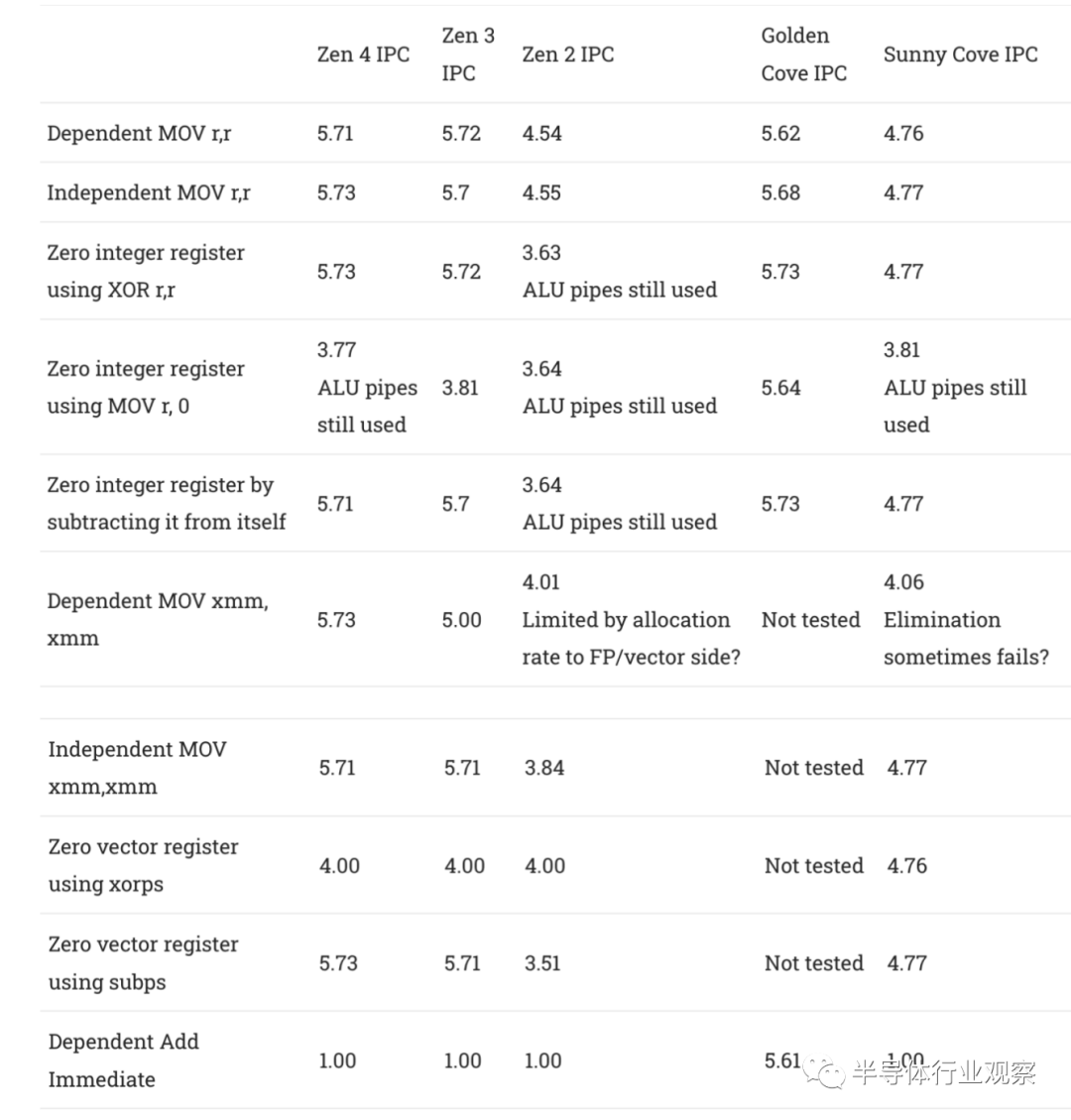
Golden Cove 的重命名器功能稍强一些,也可以消除 MOV r,0 情况。它还可以在不使用下游 ALU 的情况下处理添加小的立即数(small immediate values :即指令中提供的值,而不是来自寄存器的值)。
Renamer技巧可以更进一步,通过不为这些情况分配寄存器来节省后端资源。消除的 MOV 可以通过将多个架构寄存器指向同一个物理寄存器来处理,这意味着不必为此类 MOV 分配额外的物理寄存器。如果Renamer知道寄存器的值必须为零,它可以通过在寄存器别名表中设置一个位而不是分配一个实整数寄存器来记住这一点。Zen 4 的Renamer也是这样做的,它继承了前几代 Zen 的特点,尤其是 Zen 3。
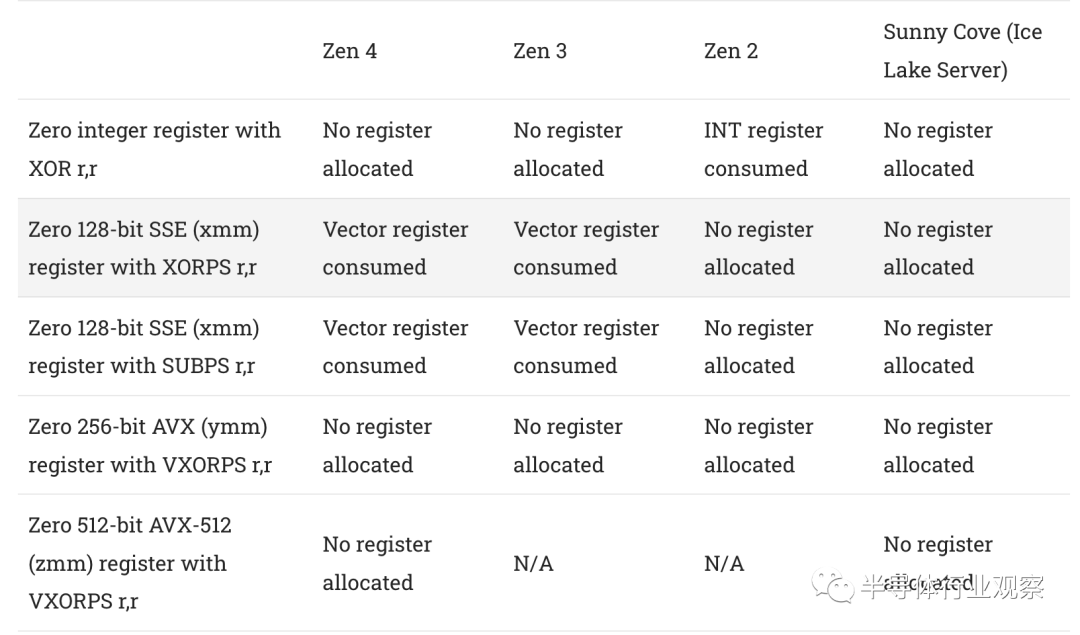
在大多数情况下,Zen 4 可以避免在识别zeroing idiom时分配物理寄存器。但是,128 位 XMM 寄存器是一个例外。从 Zen 3 开始,使用 XORPS 或 SUBPS 将 1 归零会占用一个向量寄存器。这有点令人惊讶,因为 Zen 2 在这些情况下可以避免寄存器分配。也许 Zen 2 独立跟踪其 256 位向量寄存器的 128 位一半,但 Zen 3 和 Zen 4 以 256 位粒度(granularity)进行跟踪。在测试序列之前执行 VZEROUPPER 指令没有任何区别。
在我们测试的所有情况下,英特尔都可以避免分配寄存器,而且这种能力至少可以追溯到 Skylake。即使在 2022 年,AMD 仍在迎头赶上,尽管这些都是相对次要的细节。
乱序资源
与前几代 Zen 一样,Zen 4 对无序缓冲区大小进行了增量改进。结构大小的变化范围从 ROB 容量增加 25% 到存储队列完全没有变化。对于发生变化的结构,条目数通常会增加 10-20%。总的来说,这些变化比我们看到的从 Zen 1 到 Zen 2 的变化要大一些。
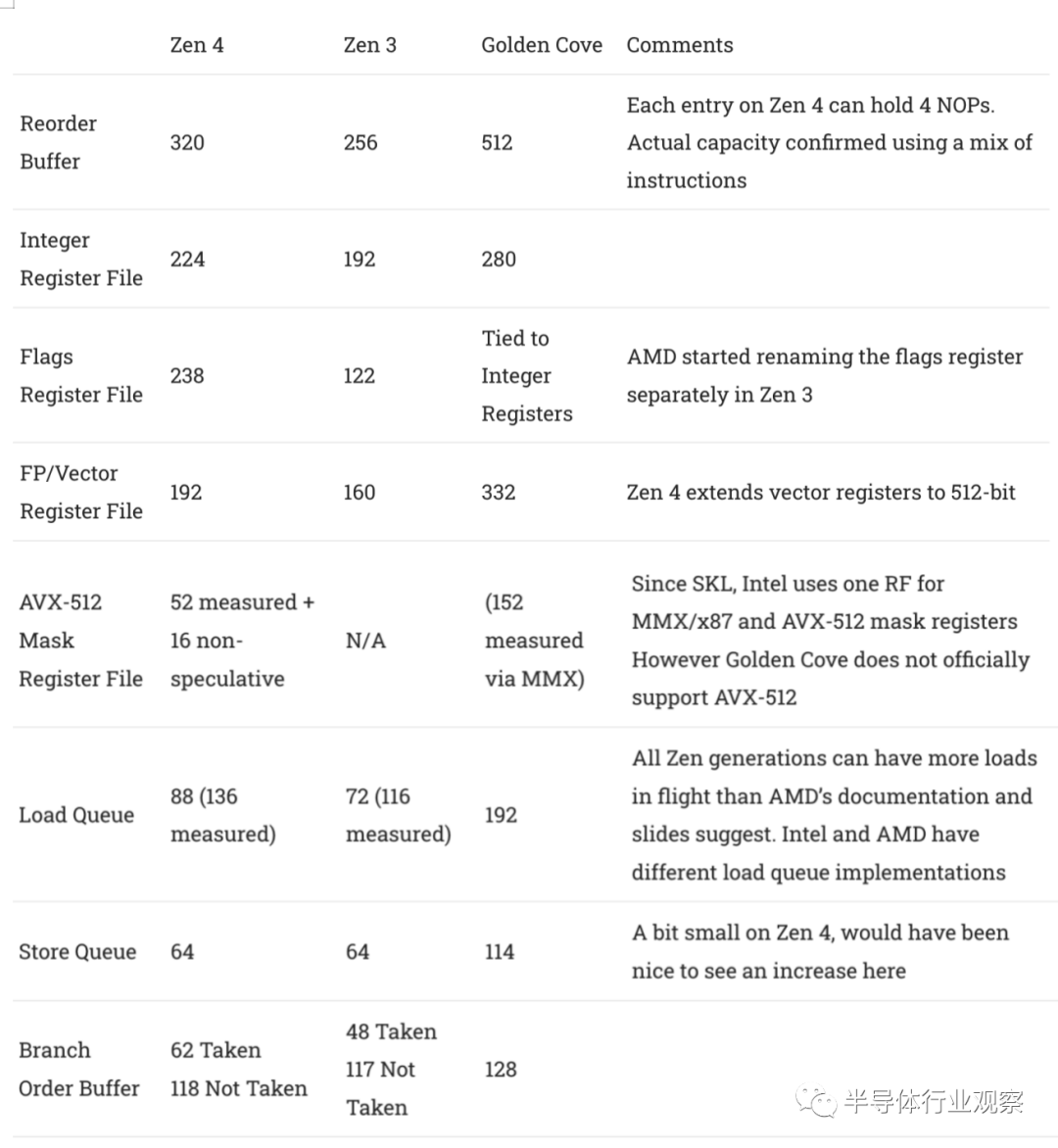
与其主要的竞争对手英特尔相比,Zen 4 在重新排序能力方面仍然是一个相当小的核心。许多关键架构甚至比 Sunny Cove 的还要小,更不用说 Golden Cove 的了。但正如我们所知道的那样,英特尔需要更多的重新排序能力来处理其更高延迟的缓存设置。
在某些领域,Zen 4 的冲击力也比其headline重新排序缓冲区容量所暗示的要大一些。我们测量了 202 个整数寄存器(共 224 个)可用于保存推测结果,覆盖了 ROB 容量的 63%。在 Golden Cove,我们测量了大约 242 个整数寄存器,即 ROB 容量的 47.2%。因此,Golden Cove 的重新排序能力更有可能因缺少整数寄存器而受到限制,而且情况更糟,因为 Golden Cove 在使用其物理寄存器文件时似乎效率较低。对于 Zen 4,测得的 202 个整数加法的重新排序容量意味着使用 22 个物理整数寄存器来保存非推测结果。假设英特尔没有减少 Sunny Cove 和 Golden Cove 之间的整数寄存器文件大小,
Zen 4 的重新排序缓冲区也很特别,因为每个条目( entry)最多可以容纳 4 个 NOP。解码器可能会融合成对的 NOP,并且在重命名阶段再次融合成对的 NOP。虽然这不太可能对实际代码产生重大影响,但测量 1265 个 NOP 的重新排序能力很有趣。我们使用了一个自定义测试,最多包含 128 个整数加法、128 个浮点加法、40 个存储和 55 个分支(按此顺序),以确认 AMD 公布的 320 条目 ROB 容量。
调度和执行
调度程序和执行pipe布局与 Zen 3 相比没有变化。Zen 3 的调度程序设置是 Zen 2 的重大升级,通过在 ALU 和 AGU 端口之间共享调度队列,在整数方面提供了很大的灵活性。在浮点和向量执行方面,Zen 3 和 Zen 4 保留了前几代 Zen 中发现的大型非调度队列,但从统一的四端口调度器转移到两个三端口调度器。在实践中,这应该很像一个统一的调度器,因为两个调度器都有类似的管道连接到它们。
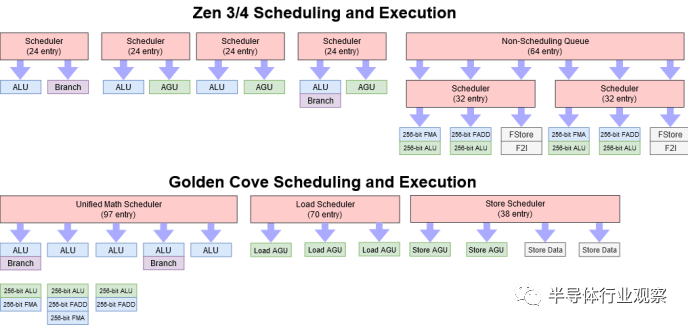
调度器结构在功率和面积方面往往很昂贵。调度队列可能必须在每个周期检查每个条目,以查看它是否已准备好执行。为了使事情变得更加困难,它必须能够在标记为就绪的同一周期发送执行指令。即使延迟一个周期也会导致毁灭性的 10% IPC 下降,这一切都是由其本身造成的。所有这些都变得越来越难在高时钟下实现。
AMD 可能选择专注于提高时钟速度,而不是提高调度程序的容量。增加调度队列大小会导致收益递减。另一方面,性能通常与时钟速度非常吻合。也就是说,只要您的缓存设置足以防止内存瓶颈,IPC 通常不会随着时钟速度的增加而出现太大的下降。AMD 的工程师可能看到,通过在更高的时钟频率下运行内核,他们可以获得更大的整体性能提升,而不是通过加强调度程序设置来增加 IPC。
AVX-512 实施
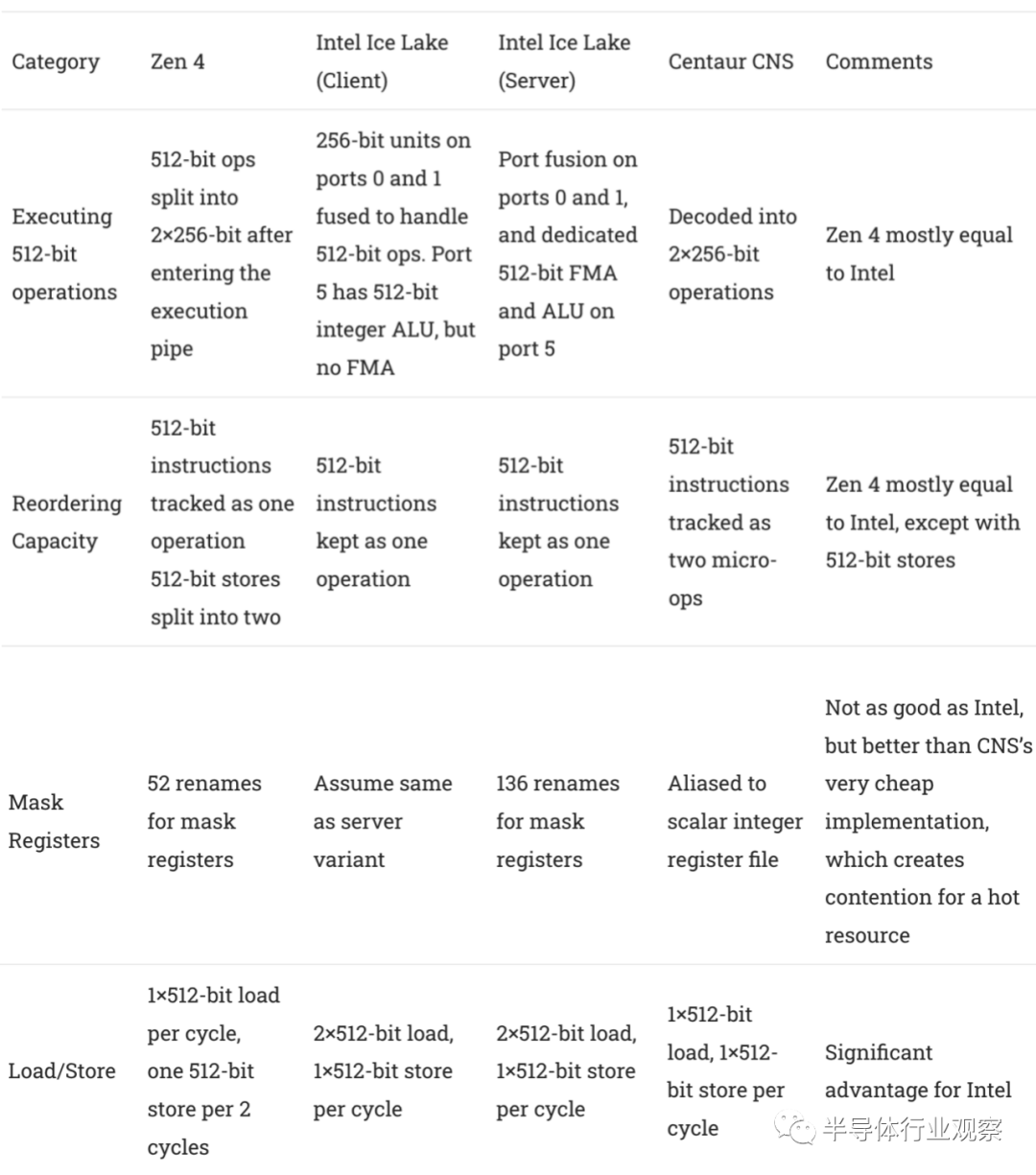
Zen 4 是第一个实现 AVX-512 指令集扩展的 AMD 架构。Zen 4 在 AVX-512 功能支持方面与 Ice Lake 差不多。在实施方面,Zen 4 旨在实现 Centaur CNS 和英特尔服务器芯片之间的功率、面积和性能平衡。

AMD 通过将向量解码为两个微操作来支持更长的向量长度的悠久传统。
Bulldozer 通过将 256 位操作分解为两个 128 位微操作来支持 AVX。K8 也做了同样的事情,将 128 位 SSE 操作分解为两个 64 位操作。这种策略让 AMD 能够以极少的功耗和面积开销支持新的指令集扩展,但也意味着当应用程序确实利用更广泛的向量时,它们并没有太多好处。相比之下,英特尔在 Sandy Bridge 推出时带来了full-width AVX 执行。Server Skylake 对 AVX-512 做了同样的事情。
Zen 4 部分打破了这一传统,将在 512 位向量上运行的指令作为一个微操作保留在大部分流水线中。因此,每条 AVX-512 指令仅消耗相关无序执行缓冲区中的一个条目。我假设它们在进入 256 位执行pipe后被分解为两个操作,这意味着指令在管道中尽可能晚地分成两个 256 位半。我还假设这就是 AMD 的“double pumping”所指的。与 Bulldozer 和 K8 的方法相比,这是一个巨大的优势。为每条 256 位或 128 位指令跟踪两个微操作意味着那些较旧的架构无法使用更宽的向量来保持更多工作在进行中。不过,Zen 4 的做法在面积和功耗方面略贵一些,
512 位存储是该规则的一个例外。它们仍然被解码为两个微操作,这意味着它们消耗了两个有价值的存储队列条目。存储队列可能是一个非常热门的结构,特别是因为存储必须留在那里直到退休,因为只有已知良好的数据才能提交到缓存。AMD 的存储队列比 Intel 的要小很多,因此如果 Zen 4 的 AVX-512 实施存在一个严重缺陷,那就是存储的处理方式。
这可能是因为 AMD 没有为 L1 数据缓存实现更宽的总线。Zen 4 的 L1D 每个周期可以处理两个 256 位加载和一个 256 位存储,这意味着向量加载/存储带宽与 Zen 2 保持不变。技嘉泄漏建议对齐更改为 512 位,但这显然不是申请门店。
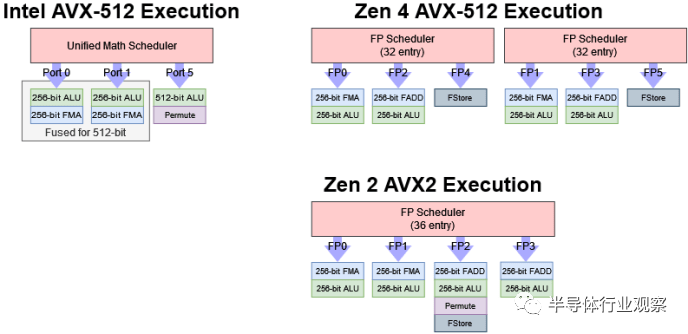
自 Zen 2 以来,最常见操作的向量执行吞吐量也基本没有变化,Zen 2 是第一个带来full-width AVX 执行的 AMD 架构。Zen 2、3 和 4 都有两个 256 位 FMA 单元和四个 256 位 ALU。起初,这似乎并不令人兴奋。但在很多工作负载中,提供执行单元比拥有大量执行单元更重要。与英特尔相比,Zen 4 已经具有具有竞争力的矢量吞吐量。除非我们查看其架构的服务器变体,否则英特尔并没有显着的吞吐量优势,它们在端口 5 上有一个额外的 512 位 FMA 单元。
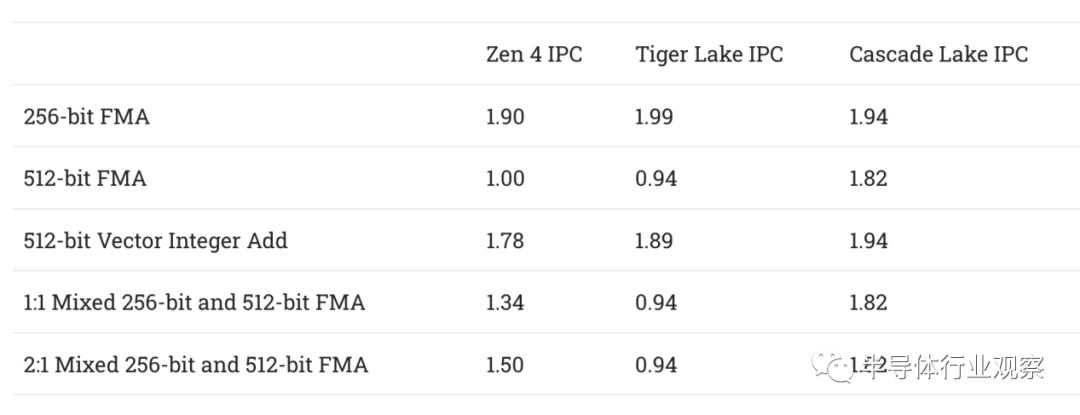
虽然英特尔的客户端架构具有与 Zen 4 相当的向量吞吐量,但通过 256 位piles的 512 位操作的处理方式不同。英特尔在端口 0 和 1 上融合了两个 256 位单元来处理 512 位操作。当将 256 位 FMA 指令与 512 位指令混合时,这会导致一些有趣的特性。Intel 卡在每个周期一个向量操作,可能是因为端口 0 和 1 上的 256 位 FMA 单元必须设置为 1×512 位或 2×256 位模式,但不能同时处于两种模式。
AVX-512 还允许通过一组 K (mask)寄存器来masking 大多数操作。为了处理这个问题,Zen 4 添加了一个相对较小的掩码寄存器(mask register)文件。掩码寄存器有大约 52 个重命名(renames ),这个寄存器文件比我们在 Skylake-X 或 Ice Lake 上看到的要小得多。在最大重排量(maximum reordering capacity)方面,Zen 4 比 Skylake-X 更接近 Ice Lake,因此 AMD 并没有对这个结构给予太多重视。
总结各种 AVX-512 实施决策:
Zen 4 从 AVX-512 获得了比 Centaur CNS 更大的收益,后者以最小的裸片面积开销实现 AVX-512 支持。反过来,英特尔看到了比 Zen 4 更大的收益。启用 AVX-512 的 Golden Cove 在此基准测试中实际上在扩展和绝对性能方面都优于 Zen 4。但这可能是这一代人的争论点,因为英特尔无法在其混合客户端芯片中启用 AVX-512 支持。
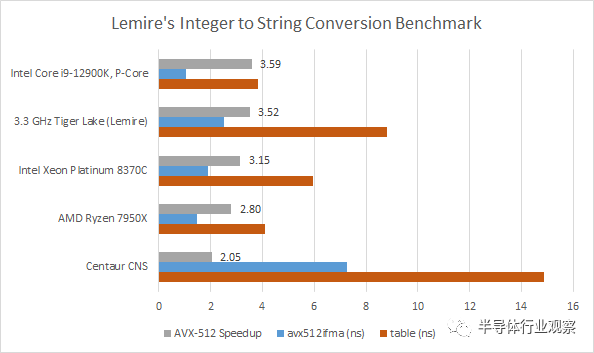
总而言之,AMD 的 AVX-512 实施专注于更好地满足现有执行能力,并且只在其产生最大影响的地方使用额外的芯片面积和功率。最昂贵的更改可能与扩展向量寄存器文件以使每个寄存器为 512 位宽有关。AMD 还必须在整个流水线中添加掩码寄存器文件和其他逻辑来处理新指令。与 Intel 的客户端实现一样,AMD 避免添加额外的浮点执行单元,这会很昂贵。与 Intel 不同的是,AMD 也保持 L1D 和 L2 带宽不变,并将 512 位存储拆分为两个操作。
结果是非常可信的第一轮 AVX-512 实施。与 Intel 相比,AMD 在一些关键领域仍然存在不足,如果 AVX-512 代码需要大量加载/存储带宽并适合核心专用缓存,则尤其处于劣势。但是,虽然 Zen 4 的目标没有英特尔那么高,但它仍然可以从 AVX-512 中以与客户端英特尔架构相同的许多方式受益。AMD 对 512 位向量的支持也强于最初在 K8 Athlon 中对 128 位向量的支持,或者从 Bulldozer 到 Zen 1 的 256 位向量。Zen 4 在可以利用 AVX-512 的应用程序中应该会看到明显的好处,无需花费大量功率或die面积。
Zen 4还引入了大量的前端和执行引擎改进。分支预测器和微操作缓存改进让前端更快地将指令带入核心,并建立在 Zen 3 已经强大的前端之上。后端增加的重新排序能力让 Zen 4 更好地吸收缓存和执行延迟。
然而,AMD 几乎没有改变执行单元和调度程序的设置。执行单元没什么大不了的,因为 Zen 3 已经有足够的执行能力了,提供执行单元比增加更多更重要。然而,没有增加任何调度队列有点令人惊讶。AMD 提高了调度能力,并且在之前的每一代 Zen 中至少对调度器布局进行了微小的更改。Zen 3 在灵活的布局中已经具备了充足的调度能力,因此 Zen 4 的相同设置无论如何也不弱。但随着其他组件的改进,调度能力可能会成为更多的限制因素。Zen 4 通常会在整数代码方面表现出色,尽管 IPC 的增加在时钟速度提升方面处于次要地位。
Zen 4 在加载和存储带宽方面也落后了。它的 L1D 每个周期可以提供 512 位的加载带宽和 256 位的存储带宽。这使得 Zen 4 的 L1D 带宽与 AMD 方面的 Zen 2 和 Zen 3 或英特尔方面的 Haswell 和客户端 Skylake 保持一致。Zen 4 在使用 256 位向量(或更小)的代码方面仍然表现出色,尽管可能达不到 Golden Cove 的水平。
但是,AMD 在支持 AVX-512 方面拥有优势。如果代码使用新的 AVX-512 指令和功能,这些指令和功能在 Zen 4 上具有优化的路径,但没有直接的 AVX2 等效项,英特尔将发现自己处于不利的不利地位。Zen 4 可能没有全面的 AVX-512 实施。但如果应用正确,它仍然足以击败缺乏 AVX-512 支持的竞争对手。
当然,这假设两个处理器都没有受到内存子系统的瓶颈。在线程良好的矢量化应用程序中,缓存和内存性能可能非常重要。这是一个复杂的话题,我们将在后续文章中介绍 Zen 4 的加载/存储子系统和数据端内存层次结构。
内存执行
与 Zen 3 一样,Zen 4 使用三个 AGU 来计算加载和存储指令的地址。这些地址以及存储数据(如果适用)被传递到加载/存储单元。然后,加载/存储单元必须面对确保内存访问看起来按照程序顺序执行的复杂工作,同时尽可能多地提取性能。
高性能意味着保持大量操作处于运行状态以隐藏内存访问延迟,加载/存储单元必须通过跟踪待处理的内存操作来发挥其作用。为此,Zen 4 实现了一个大型加载队列(large load queue)。自 Zen 1 以来,AMD 的加载队列的工作方式与 Intel 的不同。在加载操作接收到数据后,加载队列可以自由地释放它。一个单独的、更大的结构用于跟踪装载操作直至退出(retirement)。为了区分这些结构,我们将较大的结构称为“加载验证队列”(load validation queue),将发布的加载队列称为“加载执行队列”(load execution queue)。分离出这些结构让 AMD 可以保持 136 次加载操作,远远超过他们公布的加载队列大小所暗示的。
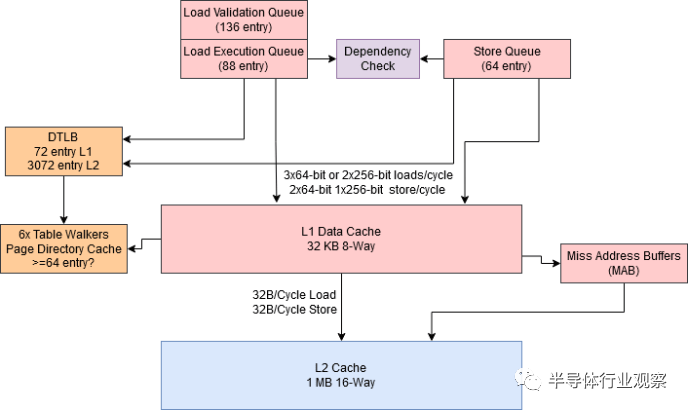
Zen 4 上的存储必须缓冲在一个相对较小的 64 条目存储队列中。这个存储队列对 AVX-512 代码的压力更大,因为 512 位存储将消耗两个存储队列条目。
一旦内存操作在各自的队列中,加载/存储单元必须确保保留内存顺序。如果动态存储的地址与较新加载的地址重叠,则可以将存储的数据转发给加载。与 Zen 3 一样,Zen 4 可以无延迟地进行存储转发。也就是说,依赖加载和存储的链将在 2 个 IPC 上执行。
但是,这有适用的不同条款和条件。加载和存储地址必须完全匹配。如果存储跨越 32 字节对齐边界(aligned boundary),则会评估额外的 1 个周期延迟损失。如果存储跨越 4 KB 对齐的pages边界( page boundary),该机制将完全失败。

Zen 4 的存储到加载转发特性,使用Henry Wong 的测试方法
负载完全包含在存储中的部分重叠情况以 6-7 个周期的延迟处理,这比 Zen 3 的 7-8 个周期略有改进。如果加载和存储重叠,则两代 Zen 的存储转发都会失败,但仅使用存储中的数据无法完成加载。Zen 4 在这种情况下需要 19 个周期的惩罚(cycle penalty),这可能对应于等待 store 退出并从 L1D 读取数据。相比之下,Zen 3 可以在 18 个周期内处理故障情况,但前提是存储地址与 4 字节边界(byte boundary)对齐。否则,Zen 3 将遭受 25 个周期的惩罚,而 Zen 4 避免了这一点。对于所有测试的存储转发案例,总结依赖于存储的负载的互惠吞吐量:
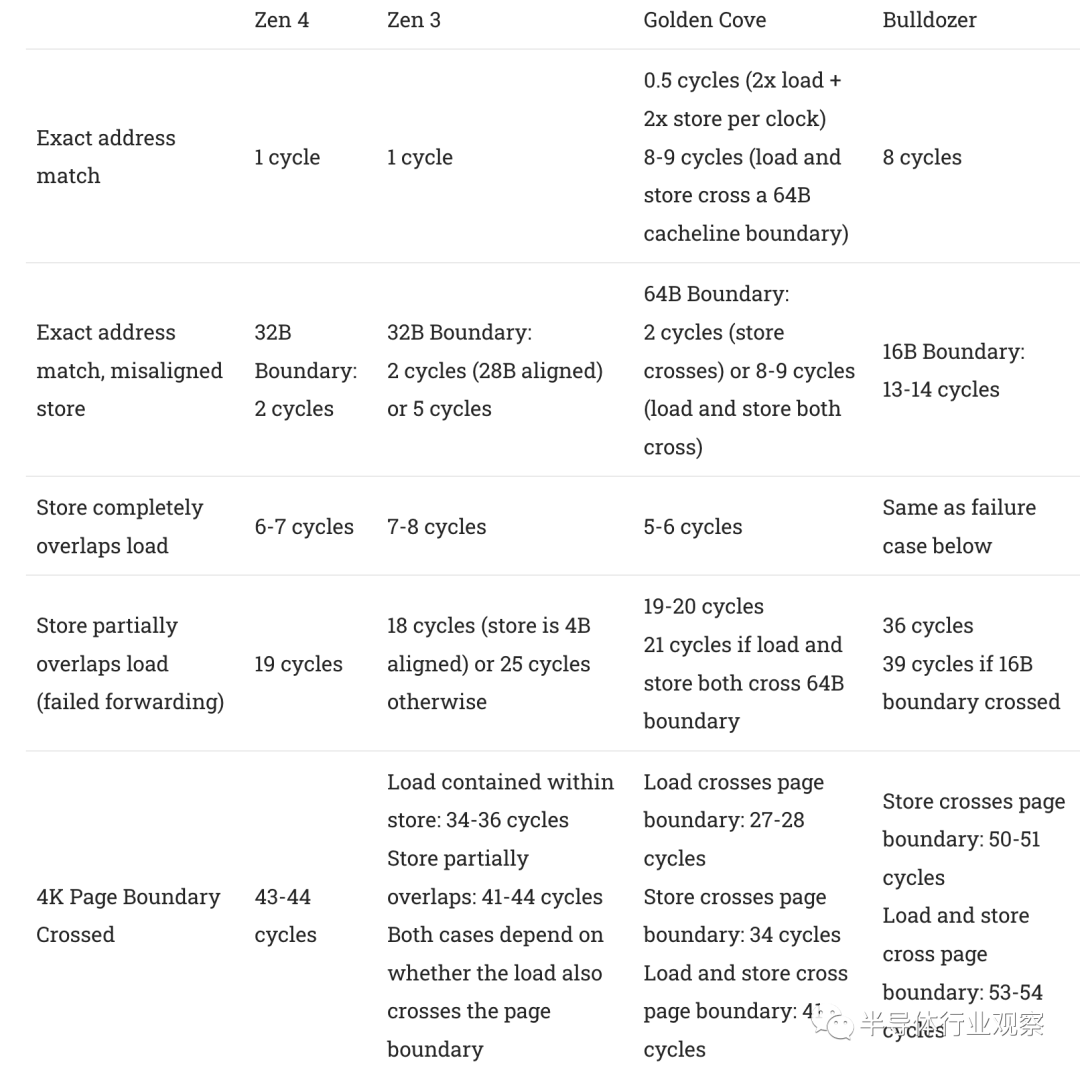
Zen 4 保留了 Zen 3 的大部分存储转发(store forwarding )特性,并在最常见的情况下略有改进。不太常见的pages边界交叉情况略有回归。在两种架构上,在处理存储转发案例时跨越pages边界都非常昂贵。它比 Zen 1 和 Zen 2 还要贵,最好避免使用。
在大多数情况下,Golden Cove 的存储转发延迟比 Zen 4 略低,除非加载和存储都跨越 64B 缓存线边界。对于精确地址匹配的情况,Golden Cove 享有吞吐量优势而不是延迟优势。使用四个 AGU,Golden Cove 可以为每个周期的两个加载和两个存储生成地址。
对于更常见的非重叠负载,Golden Cove 继续具有优势,因为 L1D 以更大的块访问,并且将遭受更少的未对齐访问。我们喜欢将内存访问视为可字节寻址(byte addressable)且完全随机的。但在实践中,缓存是在更大的、对齐的块中寻址的。这里的“对齐”意味着内存地址是特定大小的倍数。例如,32 字节对齐的内存地址的低 5 位将为零。“未对齐”访问跨越对齐边界,迫使加载/存储单元进行两次 L1D 查找以满足请求。
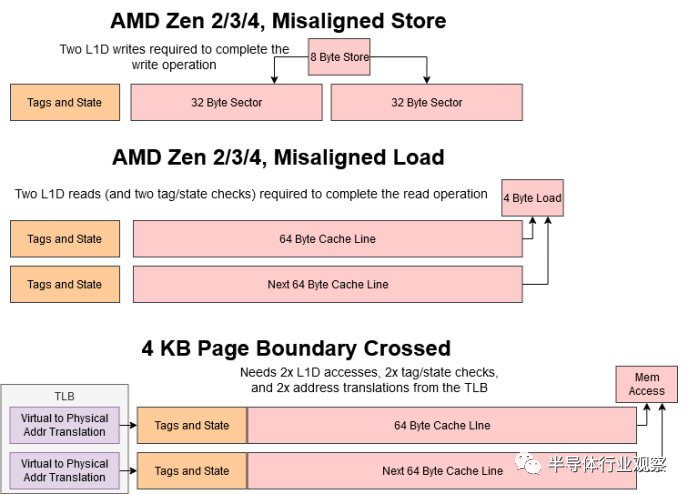
Golden Cove 的 L1D 以 64 字节、缓存线大小的块处理加载和存储。相比之下,AMD 的 L1D 以 32 字节块的形式处理写入,从 Zen 2 开始。跨越 Zen 4 上的两个 32B 块或 Golden Cove 上的 64B 块之间边界的写入需要两个周期才能完成。Zen 4 比 Zen 3 有所改进,后者可能需要 5 个周期来处理这种未对齐的负载,并且如果存储也是 4B 对齐的,则只能获得 2 个周期的情况。Golden Cove、Zen 3 和 Zen 4 也发现超过 64B 边界的负载吞吐量降低,但这种情况处理得更好,因为负载吞吐量首先更高。
跨越 4 KB 边界的访问会带来更多复杂性,因为虚拟地址到物理地址的转换通常在 4 KB pages中处理。处理这样的访问也需要访问两个 TLB 条目。所有 Zen 世代都比常规的未对齐负载情况更容易处理这种情况,这表明他们的 TLB 可以在每个周期服务多个查找。在处理跨越 4K 边界的负载时,英特尔的 Golden Cove 和 Ice Lake 架构确实会产生轻微的损失。
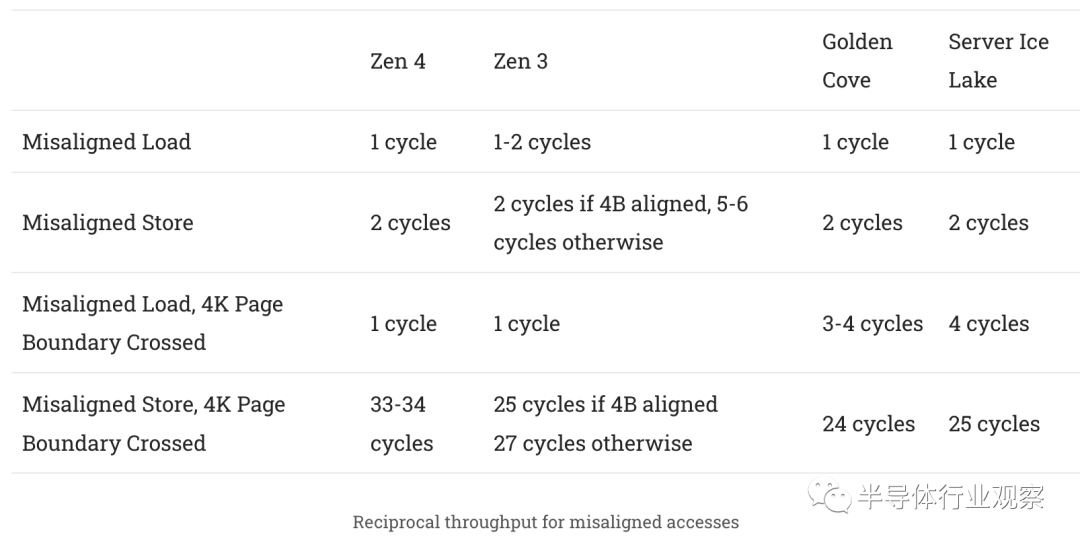
在所有经过测试的架构中,写入都会带来巨大的损失。即使与前几代 Zen 相比,它们对 Zen 4 的关注度也很高。我想知道 AMD 是否发现分页访问非常罕见,以至于可以接受更高的惩罚来换取更高的时钟速度。
缓存和内存性能
在过去的三十年里,计算能力一直在稳步超过内存性能。作为响应,CPU 使用越来越复杂的缓存设置来不断提高性能。英特尔和 AMD 的高性能内核已采用三级缓存方案。每个内核都有一个小型 L1 缓存和一个中等大小的 L2 缓存,以使其免受 L3 延迟的影响。L3 缓存大小为数兆字节,并在一组内核之间共享。
一、2 MB Pages的延迟
让我们从测试2 MB Pages的内存延迟开始,从单核的角度了解缓存层次结构。使用 2 MB Pages并不能代表大多数应用程序将如何访问内存,但它确实更有效地利用了 TLB 容量,并且让我们分别查看缓存延迟和 TLB 损失。
Zen 4 的缓存与 Zen 3 非常相似。最大的变化是将 L2 大小翻倍至 1 MB,代价是 2 个周期的延迟。这反过来也将 L3 延迟推高了两个周期。
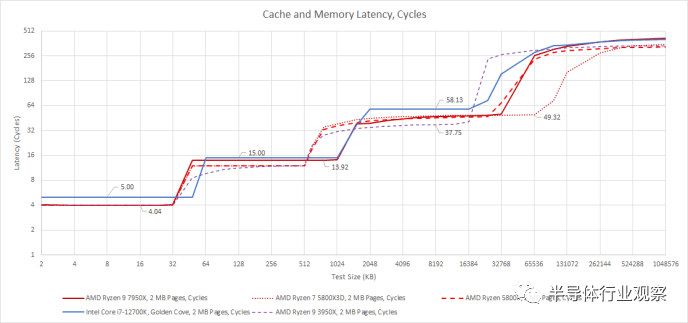
英特尔的 Golden Cove 在所有缓存级别都有更高的延迟,尽管英特尔的核心私有缓存稍大一些。Golden Cove 的 L1D 有 5 个延迟周期,或者比 Zen 4 的 4 个周期多一个周期。一个周期可能看起来不多,但这代表着比 AMD 增加了 25% 的延迟,并且 L1D 缓存将位于所有内存访问的路径中。L2 的延迟差异较小,其中 Intel 的 1280 KB 缓存与 AMD 的 1024 KB 的延迟为 15 个周期,为 14 个周期。L2 将看到比 L1 少得多的访问,这里 1 个周期的差异是一个小得多的差异百分比明智。
在 L3 中,延迟存在巨大差异。英特尔不会在核心时钟上运行环,而是有一个更长的环,为两个 E-Core 集群和一个 iGPU 提供服务。Golden Cove 从其 L3 获取数据的周期比 Zen 3 和 Zen 4 多近 20 个周期。因此,英特尔使用更大的 L2 来保护内核免受 L3 延迟的影响,并赋予 Golden Cove 巨大的重新排序能力以隐藏 L3 延迟。
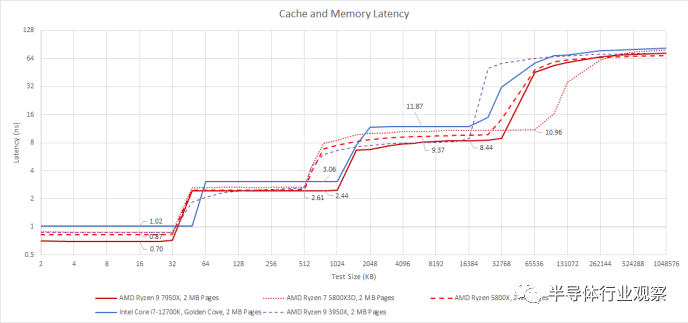
如果我们看看真正的延迟,Zen 4 的 5.7 GHz 非常高的时钟速度就会发挥作用。我们看到 L1D 延迟极低,仅为 0.7 ns。L1D hitrate通常超过 80-90%,因此大多数内存访问将享受这种非常低的延迟。AMD 的新 L2 同样令人印象深刻。Zen 4 的时钟速度提高意味着其 L2 的延迟比前几代 Zen 的 L2 略低。
最后,AMD 将 Zen 4 的 L3 延迟降至 8-9 ns 范围。Zen 3 通过在 8 个内核和 8 个 L3 片上统一 L3 缓存,增加了单个内核可访问的 L3 数量,但这样做会产生延迟损失。随着 Zen 4 的时钟速度,L3 延迟恢复到 Zen 2 的水平,但容量增加了一倍。Zen 4 的 L3 延迟也领先于 Zen 3 的 V-Cache 延迟。然而,Zen 3 的 V-Cache 变体在缓存容量方面拥有 3 倍的优势。
在内存中,我们看到 1 GB test size的合理延迟为 73.35 ns。我们不会过多关注这一点,因为内存延迟高度依赖于用户与 CPU 配对的特定 DDR 设置,而且我们测试的分布式特性意味着即使平台支持相同的内存也无法匹配内存设置类型。我们的 Ryzen 7950X 测试台使用 DDR5-6000 设置,与使用 JEDEC DDR5-4800 的 i7-12700K Golden Cove 结果相比,它具有更好的内存延迟。反过来,我的个人 Ryzen 3950X 使用 DDR4-3333 16-18-18-38 在 72.76 ns 时实现了稍低的延迟。在延迟方面,没有什么不寻常的。
二、4 KB Pages的延迟
虽然 2 MB pages有助于有效地使用 TLB 容量,但大多数应用程序使用 4 KB pages来减少碎片和浪费的内存。例如,如果您正在缓冲大小小于 2 KB 的数据包,或者缓存一个小文件,则将内存映射为 2 MB 块可能会非常浪费。但是以 4 KB 的粒度跟踪地址转换会给 TLB 容量带来更大的压力。为了提高性能,Zen 4 将 L1 DTLB 的大小从 64 个条目增加到 72 个。L2 TLB 的条目数从 2048 个增加到 3072 个。因此 Zen 4 能够缓存 288 KB 内存的地址转换而没有延迟开销,或者12 MB,有轻微的 7-8 个周期损失。
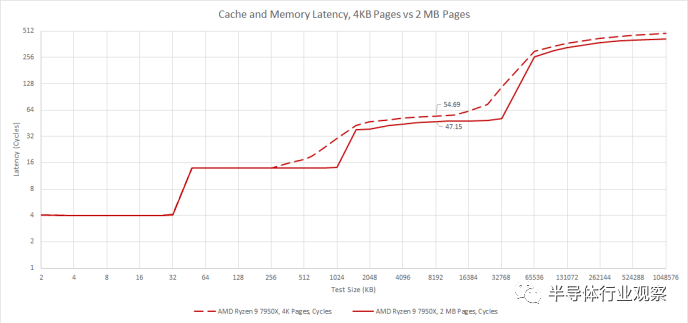
与 Zen 3 和 Zen 2 一样,英特尔的 Golden Cove 也有一个 2048 入口的 L2 TLB。因此,Zen 4 在更大的测试规模下具有更大的延迟优势。如果我们使用 4 KB pages访问 Zen 4、Zen 3 和 Golden Cove 上的 L3 缓存但不超过 L2 TLB 容量,我们会看到延迟分别约为 9.47 ns、10.44 ns 和 13.72 ns。Zen 4 和 Zen 3 都已经大大领先于 Golden Cove,但我们主要在这里看到了原始 L3 延迟的差异。
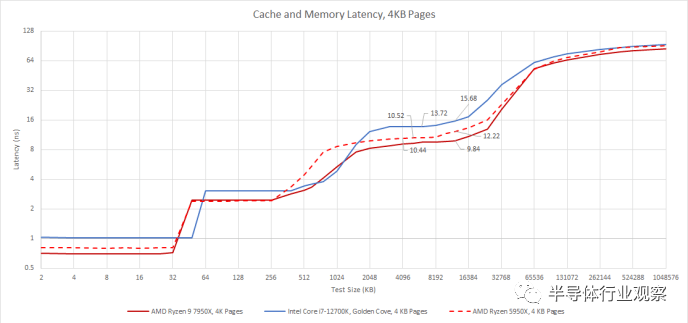
在 12 MB 或更大的测试大小时,我们开始看到 Zen 4 更大的 L2 TLB 开始发挥作用。Zen 3 和 Golden Cove 都必须开始进行page walks,因为访问会溢出 L2 TLB,这可能会导致多达 4 次额外的内存访问来计算物理地址。这三种架构在它们的page walkers中都有单独的page directory caches,这些缓存在更高级别的分页结构中缓存条目,因此它们可能不会在几乎不会溢出 L2 TLB 的测试大小下进行太多额外的访问。
尽管如此,即使是快速的page walk 也比直接从 L2 TLB 中获取翻译更糟糕,因此区别很明显。Zen 3 的 L3 延迟在 12 MB 测试大小时上升到 12 ns 以上,而 Zen 4 保持在略低于 10 ns。Golden Cove 遭受的损失更大,延迟超过 15 ns,尽管我们仍然在 12700K 的 25 MB L3 容量范围内。
因此,AMD 在改善缓存访问延迟方面做得非常出色,而标题周期计数数字并未完全捕捉到这一点。Zen 4 更高的时钟速度意味着 L1 和 L3 缓存的实际延迟得到了改善,而 L2 缓存的容量翻了一番,延迟回归极小(7950X 为 2.44 ns,5950X 为 2.4 ns)。通过减少典型应用程序的虚拟到物理地址转换开销,改进的 TLB 容量进一步改善了实践中的延迟。所有这些结合在一起,使 Zen 4 在所有缓存级别上都比 Golden Cove 具有显着的延迟优势。
带宽,单核
虽然内存访问延迟很重要,但带宽也很重要。矢量化代码可能特别需要内存带宽。尽管增加了对 AVX-512 的支持,AMD 并没有对核心私有缓存进行重大调整。每个周期的负载带宽与 Zen 3 和 Zen 2 相似。Zen 4 更大的 L2 是一个受欢迎的补充,因为它应该减少对共享 L3 的带宽需求。但 L1 和 L2 带宽的改进归结为 Zen 4 的时钟速度提高。
Zen 4 的单核 L3 带宽有所改善,平均每周期 27 字节,而 Zen 3 的每周期 24 字节。这非常接近从每个内核到 L3 的接口的理论带宽。AMD 可能已经增加了 L2 和 L3 之间的队列大小,以至于它几乎大到足以完全吸收 L3 延迟。
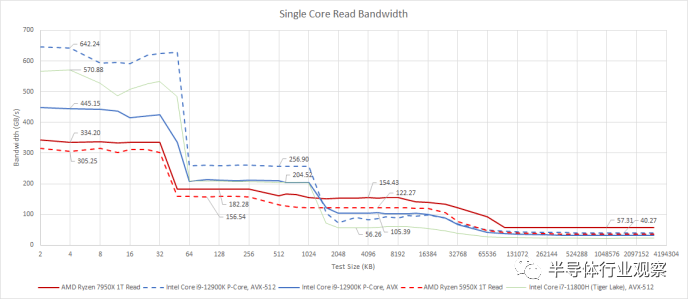
使用了不同的内存设置,所以不要比较 DRAM 带宽。TGL数据由cha0s提供,Golden Cove AVX-512数据来自CapFrameX
英特尔非常重视矢量性能,这表明了这一点。Golden Cove 的核心私有缓存可以提供出色的带宽,L1D 每个周期处理三个 256 位负载,或每个周期两个 512 位负载。后者仅适用于 AVX-512,但即使使用 AVX,Golden Cove 也拥有显着的 L1D 带宽优势。这一优势在 L2 中仍然存在,英特尔在 L1D 和 L2 之间有一个每周期 64 字节的接口。使用 AVX-512,Golden Cove 在 L2 大小的区域中比 Zen 4 具有惊人的 40% 带宽优势。AMD 无法达到与 AVX 相同的性能水平,因为L1D 没有足够的端口来处理来自 L2 的填充请求并同时向内核提供全带宽。尽管如此,Golden Cove 仍然可以仅用 AVX 击败 Zen 4。
L3 的情况发生了逆转,AMD 出色的 L3 设计可以提供几乎与 L2 一样多的带宽。相比之下,英特尔的带宽下降了。Golden Cove 从 L3 平均每个周期仅 20 字节,没有来自其他内核的争用。
当测试大小溢出到 DRAM 中时,Zen 4 保持非常高的每核带宽。这表明每个 Zen 4 内核都能够跟踪大量未决的 L3 misses,或者更具体地说,L2 misses。AMD 仅使用从 L2 驱逐的行(因此称为“victim cache”)填充其 L3 缓存,这意味着它不会预取到 L3。这使得 Zen 4 的 L2 成为能够生成预取请求的最后一个缓存级别。通过能够根据从 L1 misses中看到的访问模式生成对 L3 及更高级别的请求,L2 可以在其级别上利用更多可用的内存级别并行性,而不受 L1 misses生成的内存级别并行性的限制。
我们甚至可以使用 Little 定律估计 L2 misses队列的大小:

显然,这个计算并不完美,因为我们测试了 4 KB pages到非常大的测试大小,并且没有尝试估计pages walk会导致对 L3 及更高级别的请求的频率。但它确实表明 Zen 4 在 L2 有更积极的预取,在 L2 和 L3 之间有更深的队列,或两者兼而有之。
多线程带宽
加载所有线程后,Zen 4 实现了非常高的总带宽。这主要是因为它能够保持超过 4.8 GHz 的非常高的时钟速度,从实现的 L1D 带宽来看。由于 Zen 4 缓存层次结构的所有级别都以核心时钟运行,或者至少以集群中最快核心的速度运行,7950X 还享有增加的 L2 和 L3 带宽,即使每个缓存级别之间的总线宽度没有在禅宗世代之间发生了变化。
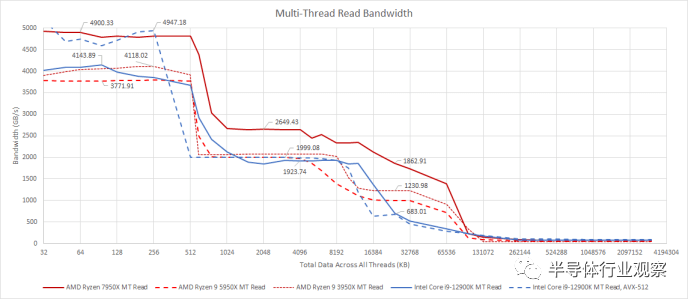
英特尔的 Alder Lake 与前几代 AMD 16 核台式机 CPU 具有竞争力。AMD 有更多的“大”核心,但 Golden Cove 有更宽的总线连接到它的 L1D 和 L2 缓存。但是 Zen 4 更高的时钟改变了这一点。如果 AVX-512 正在运行,Alder Lake 只能匹配 AMD 的 L1D 带宽,但该功能当然没有启用。无论有没有 AVX-512,Alder Lake 都无法匹敌 Zen 4 的 L2 带宽。
通过将 L3 拆分为集群,AMD 牺牲了一些缓存容量效率,使带宽和延迟问题更容易解决。在过去的几代 Zen 中,AMD 在 L3 性能上比 Intel 拥有了巨大的优势。Zen 4 进一步扩展了这一点。
内存带宽
Zen 4 也迁移到 DDR5,这极大地增加了内存子系统的理论带宽。我们看到使用配备 DDR4-3600 的 5950X 的读取带宽略高于 50 GB/s,或略高于理论 DRAM 带宽的 88%。我们配备 DDR5-6000 的 7950X 平台在相同的 3 GB 测试大小下实现了 72.85 GB/s。一方面,内存带宽显着增加了 43%。另一方面,Zen 4 实际上发现内存带宽效率有所下降。128 位 DDR5-6000 总线理论上可以达到 96 GB/s,而我们只达到了 76%。
一种理论是 Zen 4 的 DRAM 带宽受到内存控制器和结构之间的链接的限制。AMD 的图表显示,链路在两个方向上每个周期宽 32 字节。
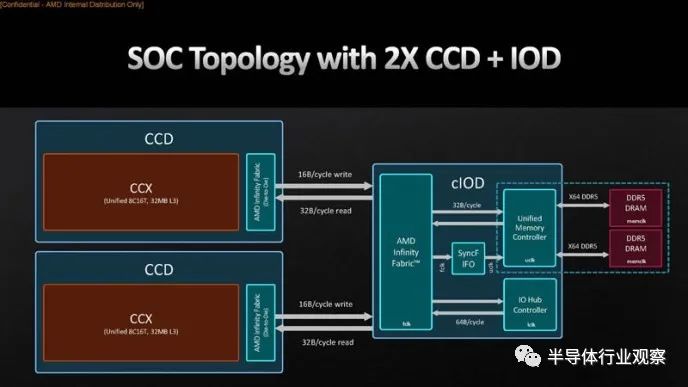
然而,这不太可能。我们测试中的 FCLK 设置为 2000 MHz。在 2000 MHz 下,每个周期 32 字节可以达到 64 GB/s,这远低于我们能够达到的水平。UCLK 以 3000 MHz 运行,或 DDR 传输速率的一半。3000 MHz 时每个周期 32 字节意味着可以在任一方向上实现完整的 DDR 带宽。这并不排除 Infinity Fabric 和内存控制器之间链路的带宽限制,但它确实表明与结构的链路比 AMD 图表所暗示的要宽。
另一个相关理论是,如果我们以 1:1 的比例混合读取和写入,可以提高带宽,因为链路可以在每个方向上传输 32 个字节。然而,混合读取和写入在 DRAM 级别引入了不同的问题。与高速缓存链接不同,DRAM 总线不是双向的,必须在读取和写入模式之间显式切换。这些开关不是空闲的,并且会强制内存总线空闲多个周期,从而减少实现的带宽。因此,当使用混合读取和写入的访问模式时,我们没有看到显着的带宽增加。
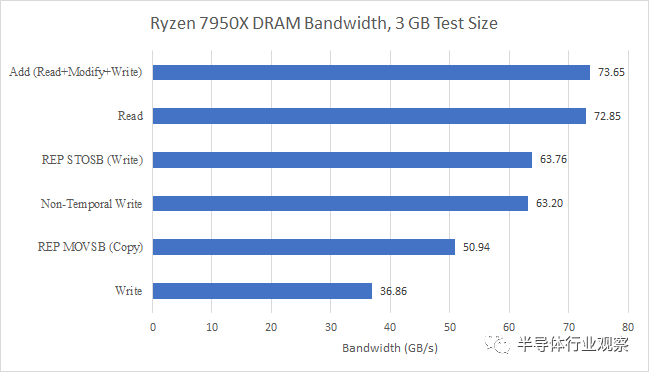
使用各种访问模式和 128 位 DDR5-6000 设置实现的内存带宽。“添加”和“复制”测试使用 1:1 的读取和写入混合。
使用读-修改-写访问模式,我们看到带宽增加了 1%,这几乎不值得讨论。写入模式实际上也是读取和写入的 1:1 混合,因为每个写入操作(特殊情况除外)也需要读取缓存线。这是因为指令可能只修改了部分缓存线,而 CPU 需要将写入与现有缓存线内容合并。这种读取被称为“所有权读取”或 RFO,因为这意味着读取核心拥有缓存线,并保证没有其他人可以写入它。如果我们将 36.86 GB/s 的写入带宽乘以 2 来考虑这一点,我们得到 73.72 GB/s,这与纯读取带宽并没有太大区别。
其他访问模式出现显着下降,包括使用 REP MOVSB 的复制模式。该测试使用微编码字符串复制指令,该指令准确告诉 CPU 它需要移动多少数据,从而避免 RFO。因此,它还具有 1:1 的读取和写入混合。
我们确实看到了一些证据表明写入带宽可能受到 CCD 和 IO 芯片之间的链接的限制。AMD 的图表显示这些链接每个周期宽 16 个字节。在两个 CCD 上,在 2000 MHz FCLK 下的速度可达 64 GB/s。通过避免 RFO 的特殊写入指令,我们可以非常接近 64 GB/s,但不会更高。REP STOSB 指令预先告诉 CPU 将多少数据设置为特定值,让它在知道整个缓存行将被覆盖时避免 RFO。非临时写入(使用 MOVNTPS)使用写入组合内存协议,该协议也避免了 RFO,并绕过缓存。两种方法都达到理论 CCD 到 IO 芯片写入带宽的 1% 以内。在大多数应用程序中,这不太可能成为限制,其中内存读取远远超过内存写入。
就 Zen 4 的读取内存带宽而言,不太可能存在结构带宽限制。取而代之的是,新的 DDR5 内存控制器在提取带宽的最后一点方面似乎不如旧的 DDR4 有效。也许它也不是调度请求,而是更多地进入次要时间。但总体而言,得益于 DDR5 内存,Zen 4 与前几代 Zen 相比具有显着的带宽优势。AMD 的 16 核台式机 Ryzen 芯片可能会受到内存带宽的限制,如果给定线程良好的矢量化负载。即使有合理的缓存命中率,16 核也可以消耗大量带宽,因此 DDR5 的带宽提升值得赞赏。甚至 DDR5 带宽也不足以支持 16 个内核,因此 AMD 继续依靠有效的缓存来保持线程良好的工作负载的性能优势。
结论
顾名思义,Zen 4 是 AMD Zen 架构系列的第四款。与 Zen 2 一样,Zen 4 将架构更改与改进的制程节点相结合,以提供代际性能提升。同时,AMD 在尝试过渡到新工艺节点时通过避免更剧烈的变化来降低风险。因此,在很多领域看到类似的变化也就不足为奇了,特别是在缓存和寄存器文件方面,提高密度使得更大的容量变得可行。

但是,Zen 4 确实跳过了某些领域,尤其是在涉及向量执行的方面。与 Zen 3 甚至 Zen 2 相比,Zen 4 并没有增加原生向量执行宽度,也没有提升最大 L1D 带宽。Zen 2 还对 Zen 1 进行了较小的执行和调度更改,而 Zen 4 保留了 Zen 3 的配置。结果是声称 IPC 增加了 13%。与前两代禅宗相比,这似乎令人印象深刻。但 13% 与Ivy Bridge 和 Haswell之间的增幅相当,Anandtech 将其定为 11.2%。我们还必须在上下文中考虑每时钟性能随时钟速度的增加。

性能提升绝不仅仅是 IPC 的提升,因为时钟速度也很重要。性能通常随着时钟速度的增加几乎呈线性增长,前提是您的缓存性能足够好,可以避免 DRAM 瓶颈。如果您可以在将某些结构大小增加 5% 或将内核时钟频率提高 5% 之间做出选择,则几乎可以保证通过选择后一个选项获得更高的整体性能。AMD 的工程师可能避免加强某些结构,例如调度程序和存储队列,而是支持让内核时钟频率更高。Zen 4 的时钟频率确实更高,幅度很大。最终结果是整体性能改进应该与我们从前几代 Zen 获得的一致。Zen 4 将这种时钟速度优势带到了多线程工作负载中。每一代 Zen 都提供了强大的全核性能,Zen 4 也不例外。英特尔还对 Raptor Lake 采取了类似的策略,避免了重大的架构变化。取而代之的是,使用 Thermal Velocity Boost 将最大时钟推至 5.8 GHz,或使用常规 Turbo Boost 3.0 将最大时钟推至 5.7 GHz。
在大量工作负载中平均 IPC 也掩盖了 Zen 4 的 AVX-512 优势。使用 AVX-512 的程序可以用更少的指令完成相同数量的工作,从而实现更低的 IPC,但更高的每时钟性能。我假设当 AMD 说 IPC 时,它们的意思是每时钟的性能,而不是每时钟的具体指令。在可以利用 AVX-512 的特定工作负载中,我预计 Zen 4 比 Zen 3 有很大的优势。如果使用 512 位向量,即使调度程序队列的大小保持不变,Zen 4 也会有更有效的调度能力同样,因为每个调度程序条目将跟踪 512 位的工作。即使不使用更长的向量,AVX-512 也提供了新的指令,再次让 CPU 用更少的指令完成相同数量的工作。
Zen 4 的其他变化同样侧重于更好地利用现有的执行能力。从 Zen 2 到 Zen 4,每个周期的原始执行吞吐量并没有真正改变,缓存带宽也没有增加。这是因为 AMD 在前几代产品中已经拥有大量的原始吞吐量,并且稳态执行吞吐量并不是大多数应用程序的瓶颈。
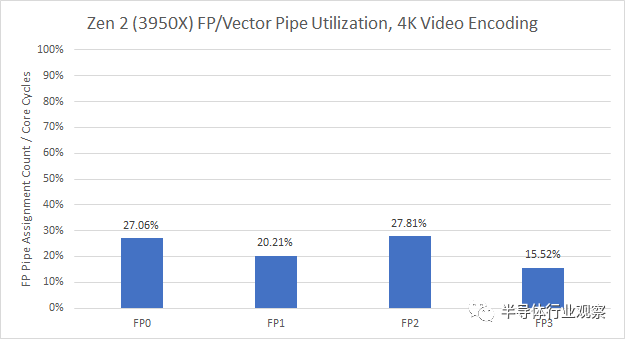
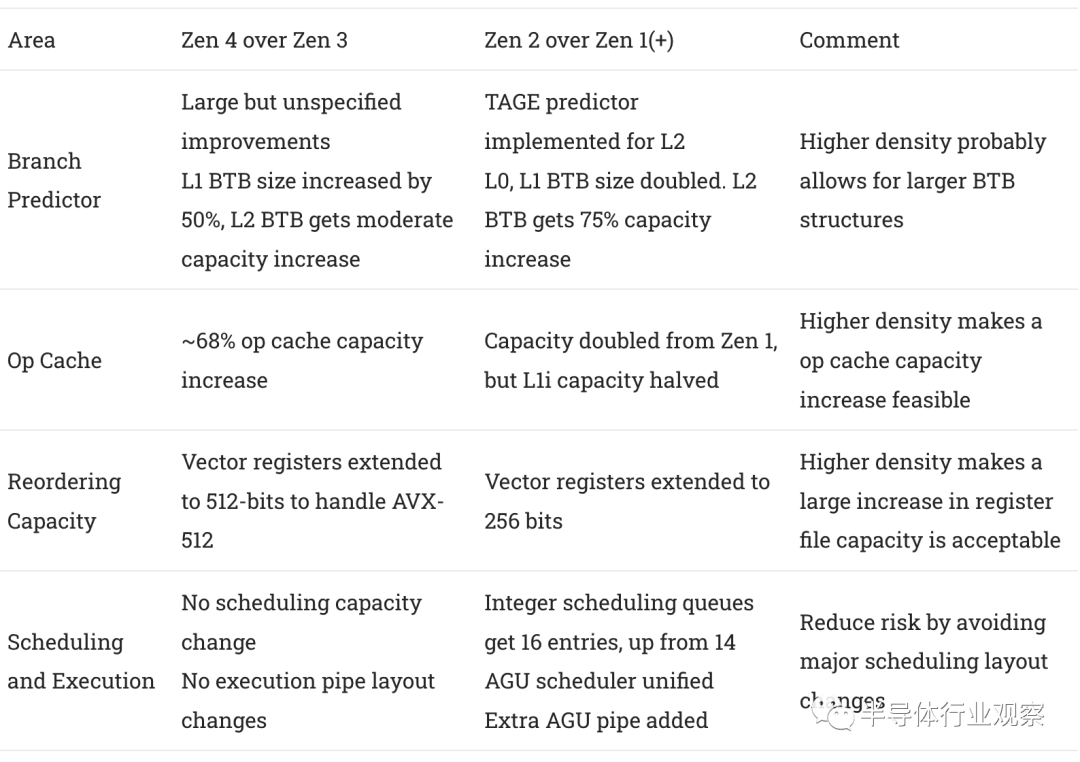
执行单元容量不是 libx264 的瓶颈,即使在峰值时(FP 调度程序填满的停顿很少),但 ROB 和整数寄存器确实填满并导致后端停顿
因此,Zen 4 提高了重新排序能力,以帮助吸收对执行单元的需求激增。改进的分支预测通过减少工作浪费,有助于更好地利用重新排序容量和执行单元吞吐量。Zen 4 还尝试通过切换到 DDR5 来更好地为执行单元提供服务,这提供了比 DDR4 更大的带宽提升。同时,AMD 赋予了每个核心更多的内存级并行能力。单核可实现的 DRAM 带宽量增加到超过 57 GB/s,表明非常深的缓冲区可以跟踪未决缓存misses。这些深缓冲区有助于吸收对高速缓存和内存带宽的需求峰值。另一方面,Zen 4 更大的 L2 TLB 和 L2 缓存有助于减少访问内存的指令的平均延迟。英特尔也采取了类似的策略Raptor Lake,其中 P 核 L2 大小从 1.25 MB 增加到 2 MB,代价是仅仅一个延迟周期。
Zen 4 还旨在提高前端宽度利用率,而不是让一切变得更宽。Zen 3 已经有一个非常快速的分支预测器,但 Zen 4 更进一步。具有更高命中率的更大 L1 BTB 意味着前端在执行分支后空闲的周期更少,从而提高了前端宽度利用率。与前几代 Zen 和许多英特尔架构一样,Zen 4 在renamer上最窄,仍然是 6 宽。我猜 AMD 发现他们可以通过增加时钟而不是增加核心宽度来提高性能。重命名器可能是一个对时间非常敏感的电路。进入的每条指令都可能需要从寄存器别名表中读取两次或多次,并且必须立即反映对寄存器映射的修改,以便稍后进入同一个 6 宽组内的指令。
您如何真正衡量宽度利用率?
考虑到所有这些,我想知道 AMD 可以从某个核心宽度和一组执行资源中挤出多少。与竞争对手的英特尔内核相比,Zen 4 内核的某些区域看起来非常轻巧。例如,向量加载和存储的 L1D 带宽只有英特尔使用 AVX-512 可以实现的一半。即使使用 AVX 限制为 256 位访问,Golden Cove 仍然可以实现比 Zen 4 更多的每个周期的带宽。当然,英特尔无法将 16 个 Golden Cove 内核封装到一个芯片中并在高时钟下运行它们。此外,英特尔设法在 Conroe 和 Skylake 之间以荒谬的数量增加了 IPC,尽管这两种架构(以及介于两者之间的所有架构)都是 4 宽。我期待看到 AMD 和英特尔在后续将带来怎样的产品。
审核编辑:郭婷
-
amd
+关注
关注
25文章
5707浏览量
140414 -
英特尔
+关注
关注
61文章
10321浏览量
181084
原文标题:万字详解AMD ZEN 4架构
文章出处:【微信号:ZYNQ,微信公众号:ZYNQ】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
探索PN512:全方位NFC前端的卓越之选
AD9864中频数字化子系统数据手册解读
Infineon XC2734X微控制器:16/32位架构的强劲之选

深度剖析PN512:全NFC论坛兼容前端芯片的卓越性能与应用
NXP PN512:全方位NFC前端芯片的深度解析与应用指南
PN512:高性能NFC前端芯片的深度解析与应用指南
深度剖析PN512:高性能NFC前端芯片的全方位解读
基于蜂鸟E203架构的指令集K扩展
江波龙企业级DDR5 RDIMM率先完成AMD Threadripper PRO 9000WX系列兼容性认证

瑞萨365 深度解读



评论