 MySQL中的utf8并不是真正的UTF-8编码
MySQL中的utf8并不是真正的UTF-8编码
一、报错回顾
将emoji文字直接写入SQL中,执行insert语句报错;
INSERTINTO`csjdemo`.`student`(`ID`,`NAME`,`SEX`,`AGE`,`CLASS`,`GRADE`,`HOBBY`)
VALUES('20','陈哈哈','男','20','181班','9年级','看片儿');
[Err] 1366 - Incorrect string value: 'xF0x9Fx98x93' for column 'NAME' at row 1
改了数据库编码、系统编码以及表字段的编码格式 → utf8mb4 之后,就可以了:
INSERTINTO`student`(`ID`,`NAME`,`SEX`,`AGE`,`CLASS`,`GRADE`,`HOBBY`) VALUES(null,'陈哈哈','男','20','181班','9年级','看片儿');
二、MySQL中utf8的趣事
MySQL 的“utf8”实际上不是真正的 UTF-8。
在MySQL中,“utf8”编码只支持每个字符最多三个字节,而真正的 UTF-8 是每个字符最多四个字节。
在utf8编码中,中文是占3个字节,其他数字、英文、符号占一个字节。
但emoji符号占4个字节,一些较复杂的文字、繁体字也是4个字节。所以导致写入失败,应该改成utf8mb4。
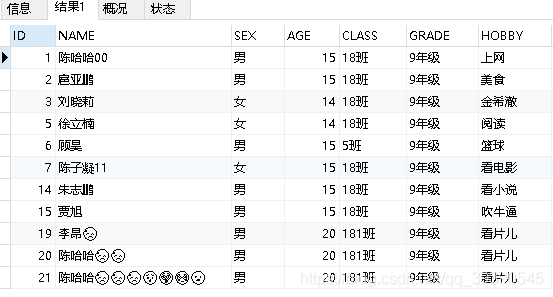
如上图中所示,这是编码改成utf8mb4后入库的数据,大家可以清晰的对比一下所占的字符数、字节数。正因如此,4字节的内容往utf8编码中插入,肯定是不行的,插不进去啊,是吧。
MySQL 一直没有修复这个 bug,他们在 2010 年发布了一个叫作“utf8mb4”的字符集,巧妙的绕过了这个问题。
当然,他们并没有对新的字符集广而告之(可能是因为这个 bug 让他们觉得很尴尬),以致于现在网络上仍然在建议开发者使用“utf8”,但这些建议都是错误的。
1. utf8mb4 才是真正的UTF-8
是的,MySQL 的“utf8mb4”才是真正的“UTF-8”。
MySQL 的“utf8”是一种“专属的编码”,它能够编码的 Unicode 字符并不多。
在这里Mark一下:所有在使用“utf8”的 MySQL 和 MariaDB 用户都应该改用“utf8mb4”,永远都不要再使用“utf8”。
那么什么是编码?什么是 UTF-8?
我们都知道,计算机使用 0 和 1 来存储文本。比如字符“C”被存成“01000011”,那么计算机在显示这个字符时需要经过两个步骤:
计算机读取“01000011”,得到数字 67,因为 67 被编码成“01000011”。
计算机在 Unicode 字符集中查找 67,找到了“C”。
同样的:
我的电脑将“C”映射成 Unicode 字符集中的 67。
我的电脑将 67 编码成“01000011”,并发送给 Web 服务器。
几乎所有的网络应用都使用了 Unicode 字符集,因为没有理由使用其他字符集。
Unicode 字符集包含了上百万个字符。最简单的编码是 UTF-32,每个字符使用 32 位。这样做最简单,因为一直以来,计算机将 32 位视为数字,而计算机最在行的就是处理数字。但问题是,这样太浪费空间了。
UTF-8 可以节省空间,在 UTF-8 中,字符“C”只需要 8 位,一些不常用的字符,比如“”需要 32 位。其他的字符可能使用 16 位或 24 位。一篇类似本文这样的文章,如果使用 UTF-8 编码,占用的空间只有 UTF-32 的四分之一左右。
2. utf8 的简史
为什么 MySQL 开发者会让“utf8”失效?我们或许可以从MySQL版本提交日志中寻找答案。
MySQL 从 4.1 版本开始支持 UTF-8,也就是 2003 年,而今天使用的 UTF-8 标准(RFC 3629)是随后才出现的。
旧版的 UTF-8 标准(RFC 2279)最多支持每个字符 6 个字节。2002 年 3 月 28 日,MySQL 开发者在第一个 MySQL 4.1 预览版中使用了 RFC 2279。
同年 9 月,他们对 MySQL 源代码进行了一次调整:“UTF8 现在最多只支持 3 个字节的序列”。
是谁提交了这些代码?他为什么要这样做?这个问题不得而知。在迁移到 Git 后(MySQL 最开始使用的是 BitKeeper),MySQL 代码库中的很多提交者的名字都丢失了。2003 年 9 月的邮件列表中也找不到可以解释这一变更的线索。
不过我们可以试着猜测一下:
2002年,MySQL做出了一个决定:如果用户可以保证数据表的每一行都使用相同的字节数,那么 MySQL 就可以在性能方面来一个大提升。为此,用户需要将文本列定义为“CHAR”,每个“CHAR”列总是拥有相同数量的字符。如果插入的字符少于定义的数量,MySQL 就会在后面填充空格,如果插入的字符超过了定义的数量,后面超出部分会被截断。
MySQL 开发者在最开始尝试 UTF-8 时使用了每个字符6个字节,CHAR(1) 使用6个字节,CHAR(2)使用12个字节,并以此类推。
应该说,他们最初的行为才是正确的,可惜这一版本一直没有发布。但是文档上却这么写了,而且广为流传,所有了解 UTF-8 的人都认同文档里写的东西。
不过很显然,MySQL 开发者或厂商担心会有用户做这两件事:
使用 CHAR 定义列(在现在看来,CHAR 已经是老古董了,但在那时,在 MySQL 中使用 CHAR 会更快,不过从 2005 年以后就不是这样子了)。
将 CHAR 列的编码设置为“utf8”。
我的猜测是 MySQL 开发者本来想帮助那些希望在空间和速度上双赢的用户,但他们搞砸了“utf8”编码。
所以结果就是没有赢家。那些希望在空间和速度上双赢的用户,当他们在使用“utf8”的 CHAR 列时,实际上使用的空间比预期的更大,速度也比预期的慢。而想要正确性的用户,当他们使用“utf8”编码时,却无法保存像“”这样的字符,因为“”是4个字节的。
在这个不合法的字符集发布了之后,MySQL 就无法修复它,因为这样需要要求所有用户重新构建他们的数据库。最终,MySQL 在 2010 年重新发布了“utf8mb4”来支持真正的 UTF-8。
三、总结
主要是目前网络上几乎所有的文章都把 “utf8” 当成是真正的 UTF-8,包括之前我写的文章以及做的项目(捂脸);因此希望更多的朋友能够看到这篇文章。
相信还有很多跟我在同一条船上的人,这是必然的。
所以,大家以后再搭建MySQL、MariaDB数据库时,记得将数据库相应编码都改为utf8mb4。终有一天,接你班儿的程序员发或你的领导现这个问题后,一定会在心里默默感到你的技术牛B。
审核编辑:汤梓红
-
数据库
+关注
关注
7文章
3857浏览量
64809 -
MySQL
+关注
关注
1文章
831浏览量
26784 -
UTF8
+关注
关注
0文章
6浏览量
7058
原文标题:MySQL中的 utf8 并不是真正的UTF-8编码 ! !
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
采用UTF8或UTF16都无法使用中文SSID怎么解决?
LABVIEW字符串转换为UTF-8编码字符串
怎么在MDB中将编码设置为UTF-8
如何将文件编码更改为UTF-8?
RT-Thread Studio的GBK编码版本如何改为UTF-8呢
请问如何在TouchGFX的TextArea通配符中显示UTF-8文本?
IAR中UTF-8中文字符串不显示怎么解决?
ascii和utf8的区别_ASCII编码与UTF-8的关系

MySQL中utf8和utf8mb4有什么区别
UTF8String是如何编码的?






 工商网监
工商网监
评论