 sql优化常用的几种方法
sql优化常用的几种方法
前言
1.慢SQL优化思路。
1.1 慢查询日志记录慢SQL
1.2 explain查看分析SQL的执行计划
1.3 profile 分析执行耗时
1.5 确定问题并采用相应的措施
2. 慢查询经典案例分析
2.1 案例1:隐式转换
2.2 案例2:最左匹配
2.3 案例3:深分页问题
2.4 案例4:in元素过多
2.5 order by 走文件排序导致的慢查询
2.6 索引字段上使用is null, is not null,索引可能失效
2.7 索引字段上使用(!= 或者 < >),索引可能失效
2.8 左右连接,关联的字段编码格式不一样
2.9 group by使用临时表
2.10 delete + in子查询不走索引!
前言
SQL调优这块呢,大厂面试必问的。最近金九银十嘛,所以整理了SQL的调优思路,并且附几个经典案例分析。
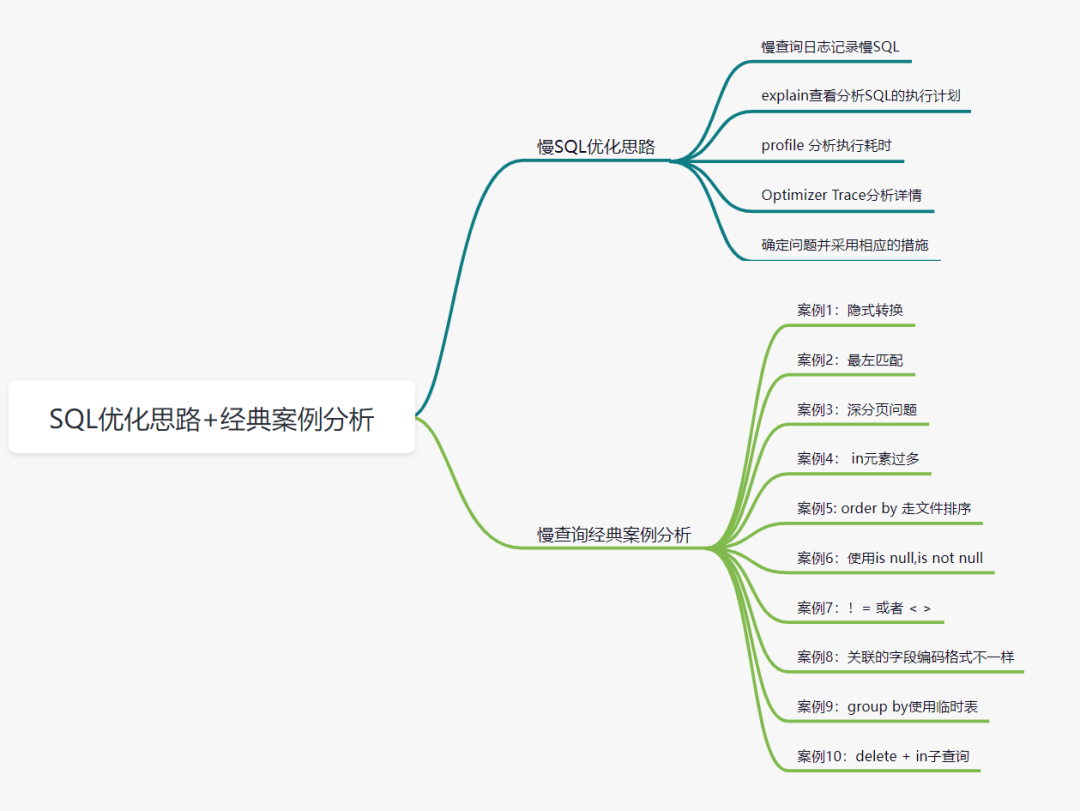
1.慢SQL优化思路。
慢查询日志记录慢SQL
explain分析SQL的执行计划
profile 分析执行耗时
Optimizer Trace分析详情
确定问题并采用相应的措施
1.1 慢查询日志记录慢SQL
如何定位慢SQL呢、我们可以通过慢查询日志 来查看慢SQL。默认的情况下呢,MySQL数据库是不开启慢查询日志(slow query log)呢。所以我们需要手动把它打开。
查看下慢查询日志配置,我们可以使用show variables like 'slow_query_log%'命令,如下:
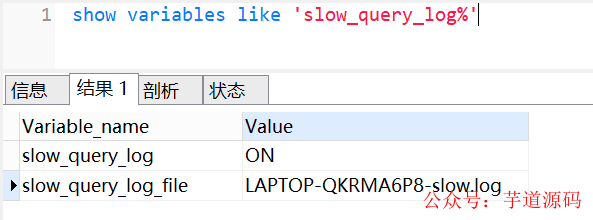
slow query log 表示慢查询开启的状态
slow_query_log_file 表示慢查询日志存放的位置
我们还可以使用show variables like 'long_query_time'命令,查看超过多少时间,才记录到慢查询日志,如下:
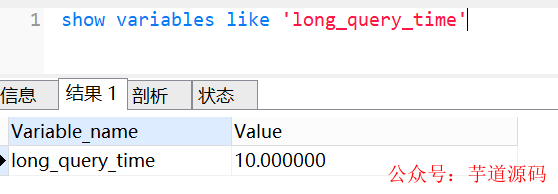
long_query_time 表示查询超过多少秒才记录到慢查询日志。
我们可以通过慢查日志,定位那些执行效率较低的SQL语句,重点关注分析。
1.2 explain查看分析SQL的执行计划
当定位出查询效率低的SQL后,可以使用explain查看SQL的执行计划。
当explain与SQL一起使用时,MySQL将显示来自优化器的有关语句执行计划的信息。即MySQL解释了它将如何处理该语句,包括有关如何连接表以及以何种顺序连接表等信息。
一条简单SQL,使用了explain的效果如下:

一般来说,我们需要重点关注type、rows、filtered、extra、key。
1.2.1 type
type表示连接类型 ,查看索引执行情况的一个重要指标。以下性能从好到坏依次:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system:这种类型要求数据库表中只有一条数据,是const类型的一个特例,一般情况下是不会出现的。
const:通过一次索引就能找到数据,一般用于主键或唯一索引作为条件,这类扫描效率极高,,速度非常快。
eq_ref:常用于主键或唯一索引扫描,一般指使用主键的关联查询
ref : 常用于非主键和唯一索引扫描。
ref_or_null:这种连接类型类似于ref,区别在于MySQL会额外搜索包含NULL值的行
index_merge:使用了索引合并优化方法,查询使用了两个以上的索引。
unique_subquery:类似于eq_ref,条件用了in子查询
index_subquery:区别于unique_subquery,用于非唯一索引,可以返回重复值。
range:常用于范围查询,比如:between ... and 或 In 等操作
index:全索引扫描
ALL:全表扫描
1.2.2 rows
该列表示MySQL估算要找到我们所需的记录,需要读取的行数。对于InnoDB表,此数字是估计值,并非一定是个准确值。
1.2.3 filtered
该列是一个百分比的值,表里符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
1.2.4 extra
该字段包含有关MySQL如何解析查询的其他信息,它一般会出现这几个值:
Using filesort:表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现。一般见于order by语句
Using index :表示是否用了覆盖索引。
Using temporary: 表示是否使用了临时表,性能特别差,需要重点优化。一般多见于group by语句,或者union语句。
Using where : 表示使用了where条件过滤.
Using index condition:MySQL5.6之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
1.2.5 key
该列表示实际用到的索引。一般配合possible_keys列一起看。
注意 :有时候,explain配合show WARNINGS; (可以查看优化后,最终执行的sql),效果更佳哦。
1.3 profile 分析执行耗时
explain只是看到SQL的预估执行计划,如果要了解SQL真正的执行线程状态及消耗的时间 ,需要使用profiling。开启profiling参数后,后续执行的SQL语句都会记录其资源开销,包括IO,上下文切换,CPU,内存等等,我们可以根据这些开销进一步分析当前慢SQL的瓶颈再进一步进行优化。
profiling默认是关闭,我们可以使用show variables like '%profil%'查看是否开启,如下:
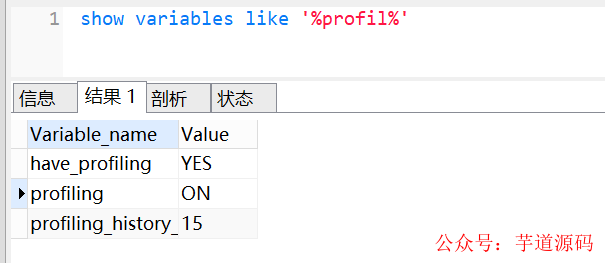
可以使用set profiling=ON开启。开启后,可以运行几条SQL,然后使用show profiles查看一下。
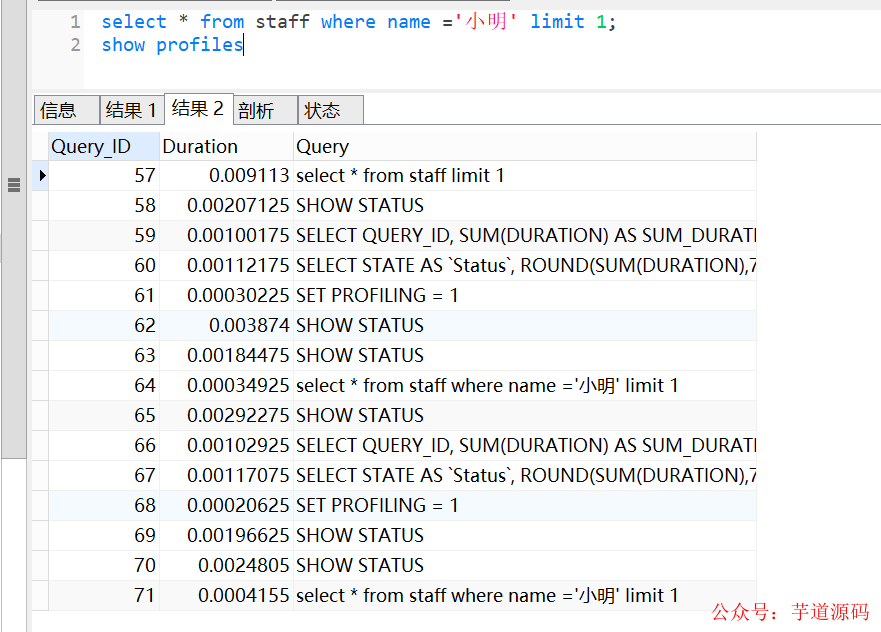
show profiles会显示最近发给服务器的多条语句,条数由变量profiling_history_size定义,默认是15。如果我们需要看单独某条SQL的分析,可以show profile查看最近一条SQL的分析,也可以使用show profile for query id(其中id就是show profiles中的QUERY_ID)查看具体一条的SQL语句分析。
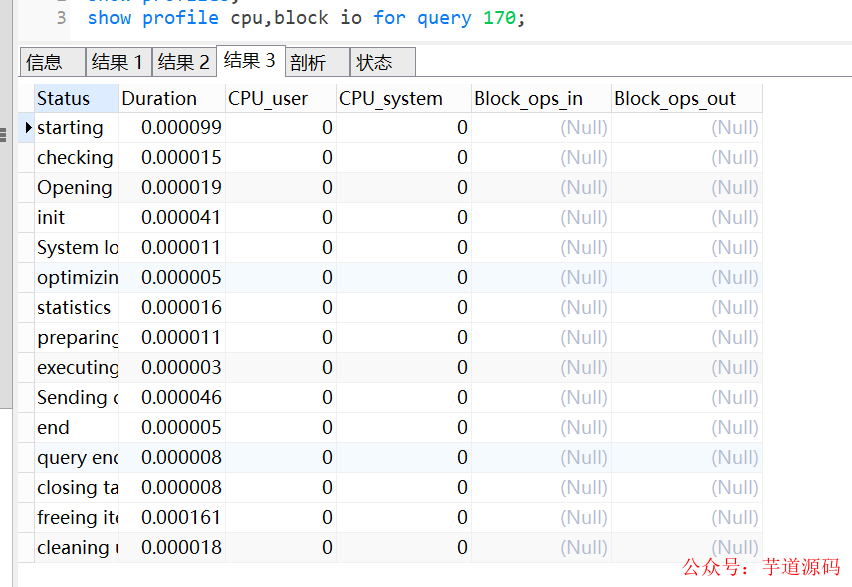
除了查看profile ,还可以查看cpu和io,如上图。
1.4 Optimizer Trace分析详情
profile只能查看到SQL的执行耗时,但是无法看到SQL真正执行的过程信息,即不知道MySQL优化器是如何选择执行计划。这时候,我们可以使用Optimizer Trace,它可以跟踪执行语句的解析优化执行的全过程。
我们可以使用set optimizer_trace="enabled=on"打开开关,接着执行要跟踪的SQL,最后执行select * from information_schema.optimizer_trace跟踪,如下:
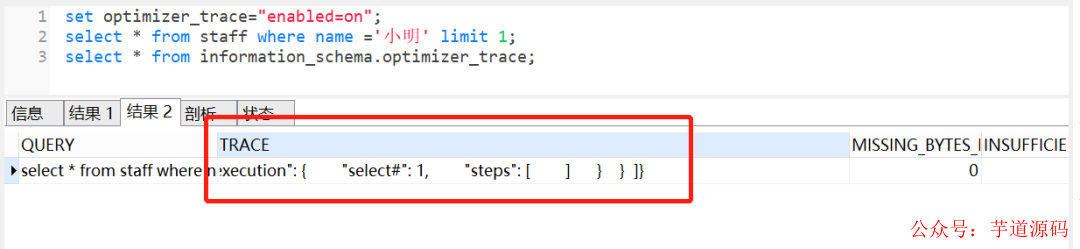
大家可以查看分析其执行树,会包括三个阶段:
join_preparation:准备阶段
join_optimization:分析阶段
join_execution:执行阶段

1.5 确定问题并采用相应的措施
最后确认问题,就采取对应的措施。
多数慢SQL都跟索引有关,比如不加索引,索引不生效、不合理等,这时候,我们可以优化索引 。
我们还可以优化SQL语句,比如一些in元素过多问题(分批),深分页问题(基于上一次数据过滤等),进行时间分段查询
SQl没办法很好优化,可以改用ES的方式,或者数仓。
如果单表数据量过大导致慢查询,则可以考虑分库分表
如果数据库在刷脏页导致慢查询,考虑是否可以优化一些参数,跟DBA讨论优化方案
如果存量数据量太大,考虑是否可以让部分数据归档
2. 慢查询经典案例分析
2.1 案例1:隐式转换
我们创建一个用户user表
CREATETABLEuser( idint(11)NOTNULLAUTO_INCREMENT, userIdvarchar(32)NOTNULL, agevarchar(16)NOTNULL, namevarchar(255)NOTNULL, PRIMARYKEY(id), KEYidx_userid(userId)USINGBTREE )ENGINE=InnoDBDEFAULTCHARSET=utf8;
userId字段为字串类型,是B+树的普通索引,如果查询条件传了一个数字过去,会导致索引失效。如下:
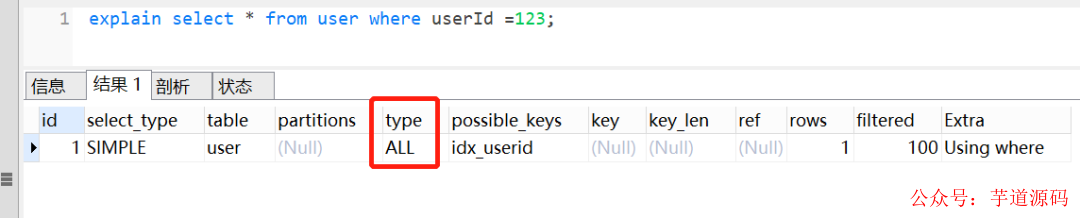
如果给数字加上'',也就是说,传的是一个字符串呢,当然是走索引,如下图:

为什么第一条语句未加单引号就不走索引了呢?这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。隐式的类型转换,索引会失效。
2.2 案例2:最左匹配
MySQl建立联合索引时,会遵循最左前缀匹配的原则,即最左优先。如果你建立一个(a,b,c)的联合索引,相当于建立了(a)、(a,b)、(a,b,c)三个索引。
假设有以下表结构:
CREATETABLEuser( idint(11)NOTNULLAUTO_INCREMENT, user_idvarchar(32)NOTNULL, agevarchar(16)NOTNULL, namevarchar(255)NOTNULL, PRIMARYKEY(id), KEYidx_userid_name(user_id,name)USINGBTREE )ENGINE=InnoDBDEFAULTCHARSET=utf8;
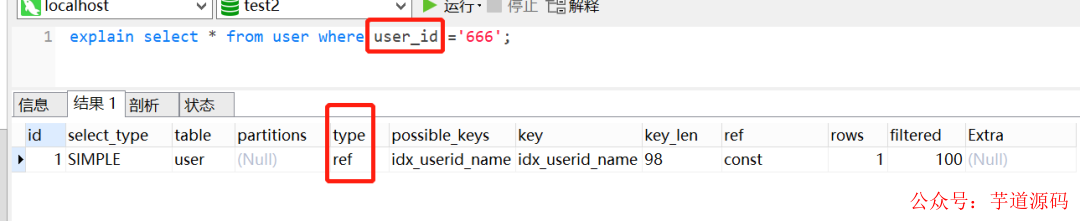
假设有一个联合索引idx_userid_name,我们现在执行以下SQL,如果查询列是name,索引是无效的:
explainselect*fromuserwherename='捡田螺的小男孩';

因为查询条件列name不是联合索引idx_userid_name中的第一个列,不满足最左匹配原则,所以索引不生效。在联合索引中,只有查询条件满足最左匹配原则时,索引才正常生效。如下,查询条件列是user_id
2.3 案例3:深分页问题
limit深分页问题,会导致慢查询,应该大家都司空见惯了吧。
limit深分页为什么会变慢呢? 假设有表结构如下:
CREATETABLEaccount( idint(11)NOTNULLAUTO_INCREMENTCOMMENT'主键Id', namevarchar(255)DEFAULTNULLCOMMENT'账户名', balanceint(11)DEFAULTNULLCOMMENT'余额', create_timedatetimeNOTNULLCOMMENT'创建时间', update_timedatetimeNOTNULLONUPDATECURRENT_TIMESTAMPCOMMENT'更新时间', PRIMARYKEY(id), KEYidx_name(name), KEYidx_create_time(create_time)//索引 )ENGINE=InnoDBAUTO_INCREMENT=1570068DEFAULTCHARSET=utf8ROW_FORMAT=REDUNDANTCOMMENT='账户表';
以下这个SQL,你知道执行过程是怎样的呢?
selectid,name,balancefromaccountwherecreate_time>'2020-09-19'limit100000,10;
这个SQL的执行流程酱紫:
通过普通二级索引树idx_create_time,过滤create_time条件,找到满足条件的主键id。
通过主键id,回到id主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程)
扫描满足条件的100010行,然后扔掉前100000行,返回。

因此,limit深分页,导致SQL变慢原因有两个:
limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。也就是说limit 100000,10,就会扫描100010行,而limit 0,10,只扫描10行。
limit 100000,10 扫描更多的行数,也意味着回表更多的次数。
如何优化深分页问题?
我们可以通过减少回表次数来优化。一般有标签记录法 和延迟关联法 。
标签记录法
就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦。
假设上一次记录到100000,则SQL可以修改为:
selectid,name,balanceFROMaccountwhereid>100000limit10;
这样的话,后面无论翻多少页,性能都会不错的,因为命中了id索引。但是这种方式有局限性:需要一种类似连续自增的字段。
延迟关联法
延迟关联法,就是把条件转移到主键索引树 ,然后减少回表。如下
selectacct1.id,acct1.name,acct1.balanceFROMaccountacct1INNERJOIN(SELECTa.idFROMaccountaWHEREa.create_time>'2020-09-19'limit100000,10)ASacct2onacct1.id=acct2.id;
优化思路 就是,先通过idx_create_time二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
2.4 案例4:in元素过多
如果使用了in,即使后面的条件加了索引,还是要注意in后面的元素不要过多哈。in元素一般建议不要超过200个,如果超过了,建议分组,每次200一组进行哈。
反例:
selectuser_id,namefromuserwhereuser_idin(1,2,3...1000000);
如果我们对in的条件不做任何限制的话,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。尤其有时候,我们是用的子查询,in后面的子查询 ,你都不知道数量有多少那种,更容易采坑.如下这种子查询:
select*fromuserwhereuser_idin(selectauthor_idfromartilcewheretype=1);
如果type = 1有1一千,甚至上万个呢?肯定是慢SQL。索引一般建议分批进行,一次200个,比如:
selectuser_id,namefromuserwhereuser_idin(1,2,3...200);
in查询为什么慢呢?
这是因为in查询在MySQL底层是通过n*m的方式去搜索,类似union。
in查询在进行cost代价计算时(代价 = 元组数 * IO平均值),是通过将in包含的数值,一条条去查询获取元组数的,因此这个计算过程会比较的慢,所以MySQL设置了个临界值(eq_range_index_dive_limit),5.6之后超过这个临界值后该列的cost就不参与计算了。因此会导致执行计划选择不准确。默认是200,即in条件超过了200个数据,会导致in的代价计算存在问题,可能会导致Mysql选择的索引不准确。
2.5 order by 走文件排序导致的慢查询
如果order by 使用到文件排序,则会可能会产生慢查询。我们来看下下面这个SQL:
selectname,age,cityfromstaffwherecity='深圳'orderbyagelimit10;
它表示的意思就是:查询前10个,来自深圳员工的姓名、年龄、城市,并且按照年龄小到大排序。

查看explain执行计划的时候,可以看到Extra这一列,有一个Using filesort,它表示用到文件排序。
order by文件排序效率为什么较低
大家可以看下这个下面这个图:
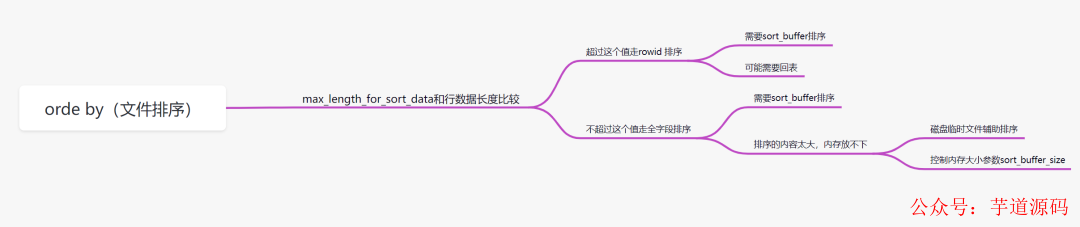
order by排序,分为全字段排序和rowid排序。它是拿max_length_for_sort_data和结果行数据长度对比,如果结果行数据长度超过max_length_for_sort_data这个值,就会走rowid排序,相反,则走全字段排序。
2.5.1 rowid排序
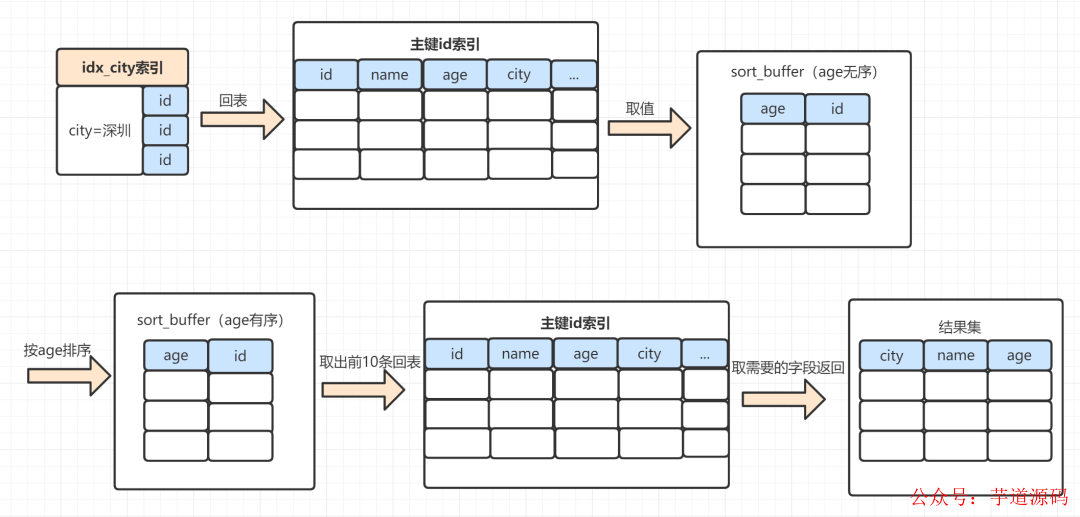
rowid排序,一般需要回表去找满足条件的数据,所以效率会慢一点。以下这个SQL,使用rowid排序,执行过程是这样:
selectname,age,cityfromstaffwherecity='深圳'orderbyagelimit10;
MySQL为对应的线程初始化sort_buffer,放入需要排序的age字段,以及主键id;
从索引树idx_city, 找到第一个满足 city='深圳’条件的主键id,假设id为X;
到主键id索引树拿到id=X的这一行数据, 取age和主键id的值,存到sort_buffer;
从索引树idx_city拿到下一个记录的主键id,假设id=Y;
重复步骤 3、4 直到city的值不等于深圳为止;
前面5步已经查找到了所有city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序;遍历排序结果,取前10行,并按照id的值回到原表中,取出city、name 和 age三个字段返回给客户端。
2.5.2 全字段排序
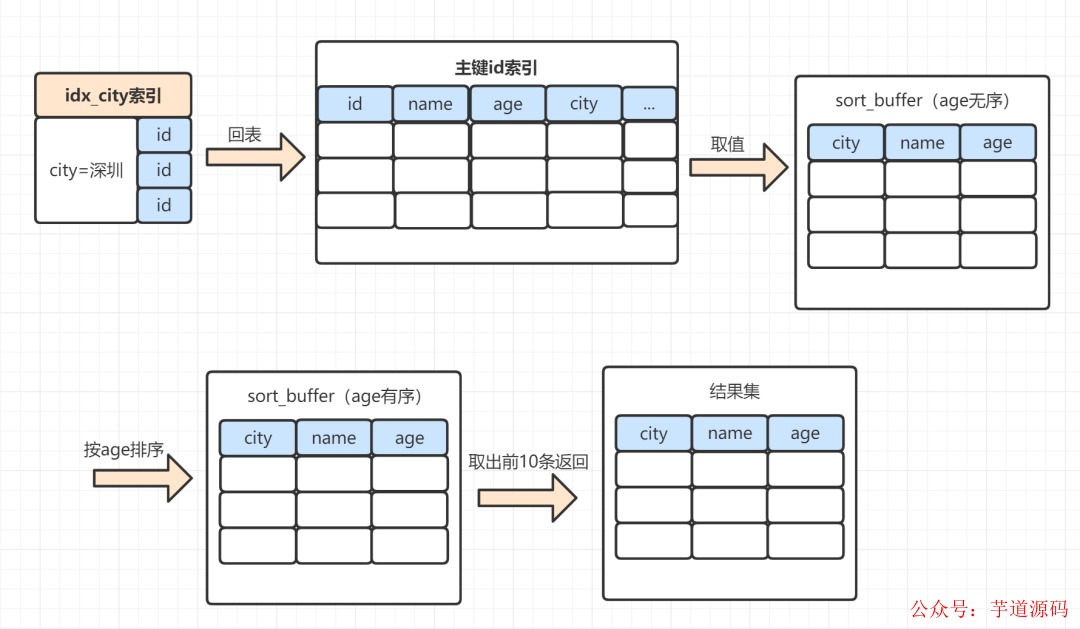
同样的SQL,如果是走全字段排序是这样的:
selectname,age,cityfromstaffwherecity='深圳'orderbyagelimit10;
MySQL 为对应的线程初始化sort_buffer,放入需要查询的name、age、city字段;
从索引树idx_city, 找到第一个满足 city='深圳’条件的主键 id,假设找到id=X;
到主键id索引树拿到id=X的这一行数据, 取name、age、city三个字段的值,存到sort_buffer;
从索引树idx_city 拿到下一个记录的主键id,假设id=Y;
重复步骤 3、4 直到city的值不等于深圳为止;
前面5步已经查找到了所有city为深圳的数据,在sort_buffer中,将所有数据根据age进行排序;
按照排序结果取前10行返回给客户端。
sort_buffer的大小是由一个参数控制的:sort_buffer_size。
如果要排序的数据小于sort_buffer_size,排序在sort_buffer内存中完成
如果要排序的数据大于sort_buffer_size,则借助磁盘文件来进行排序。
借助磁盘文件排序的话,效率就更慢一点。因为先把数据放入sort_buffer,当快要满时。会排一下序,然后把sort_buffer中的数据,放到临时磁盘文件,等到所有满足条件数据都查完排完,再用归并算法把磁盘的临时排好序的小文件,合并成一个有序的大文件。
2.5.3 如何优化order by的文件排序
order by使用文件排序,效率会低一点。我们怎么优化呢?
因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不会再用到文件排序啦。而索引数据本身是有序的,我们通过建立索引来优化order by语句。
我们还可以通过调整max_length_for_sort_data、sort_buffer_size等参数优化;
2.6 索引字段上使用is null, is not null,索引可能失效
假设有表结构:
CREATETABLE`user`( `id`int(11)NOTNULLAUTO_INCREMENT, `card`varchar(255)DEFAULTNULL, `name`varchar(255)DEFAULTNULL, PRIMARYKEY(`id`), KEY`idx_name`(`name`)USINGBTREE, KEY`idx_card`(`card`)USINGBTREE )ENGINE=InnoDBAUTO_INCREMENT=2DEFAULTCHARSET=utf8;
单个name字段加上索引,并查询name为非空的语句,其实会走索引的,如下:

单个card字段加上索引,并查询name为非空的语句,其实会走索引的,如下:
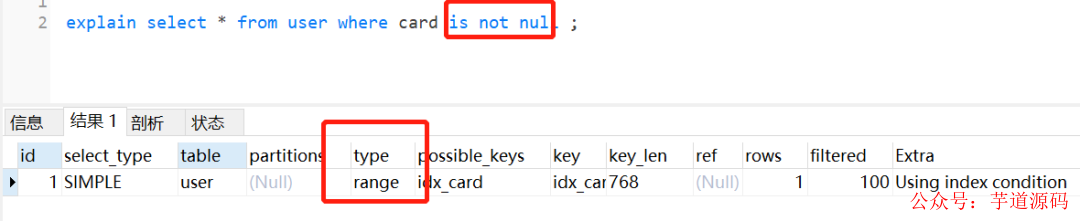
但是它两用or连接起来,索引就失效了,如下:
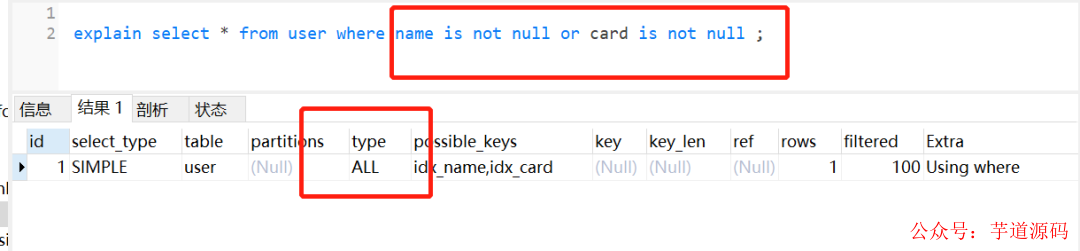
很多时候,也是因为数据量问题,导致了MySQL优化器放弃走索引。同时,平时我们用explain分析SQL的时候,如果type=range,要注意一下哈,因为这个可能因为数据量问题,导致索引无效。
2.7 索引字段上使用(!= 或者 < >),索引可能失效
假设有表结构:
CREATETABLE`user`( `id`int(11)NOTNULLAUTO_INCREMENT, `userId`int(11)NOTNULL, `age`int(11)DEFAULTNULL, `name`varchar(255)NOTNULL, PRIMARYKEY(`id`), KEY`idx_age`(`age`)USINGBTREE )ENGINE=InnoDBAUTO_INCREMENT=2DEFAULTCHARSET=utf8;
虽然age加了索引,但是使用了!= 或者< >,not in这些时,索引如同虚设。如下:

其实这个也是跟mySQL优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,不如直接不走索引。平时我们用!= 或者< >,not in的时候,留点心眼哈。
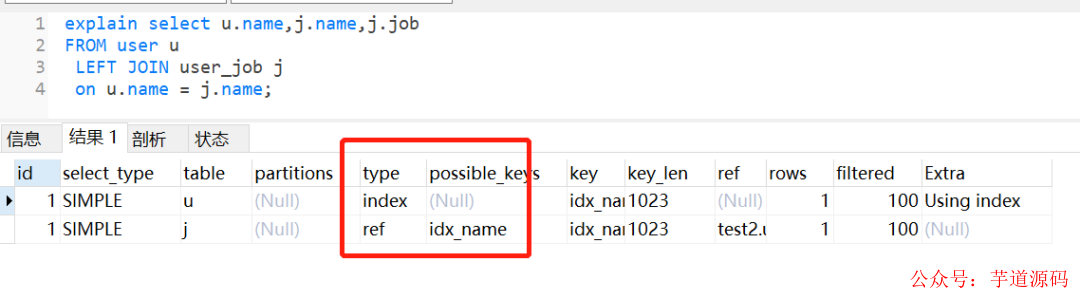
2.8 左右连接,关联的字段编码格式不一样
新建两个表,一个user,一个user_job
``
CREATETABLE`user`( `id`int(11)NOTNULLAUTO_INCREMENT, `name`varchar(255)CHARACTERSETutf8mb4DEFAULTNULL, `age`int(11)NOTNULL, PRIMARYKEY(`id`), KEY`idx_name`(`name`)USINGBTREE )ENGINE=InnoDBAUTO_INCREMENT=2DEFAULTCHARSET=utf8; CREATETABLE`user_job`( `id`int(11)NOTNULL, `userId`int(11)NOTNULL, `job`varchar(255)DEFAULTNULL, `name`varchar(255)DEFAULTNULL, PRIMARYKEY(`id`), KEY`idx_name`(`name`)USINGBTREE )ENGINE=InnoDBDEFAULTCHARSET=utf8;
user表的name字段编码是utf8mb4,而user_job表的name字段编码为utf8。
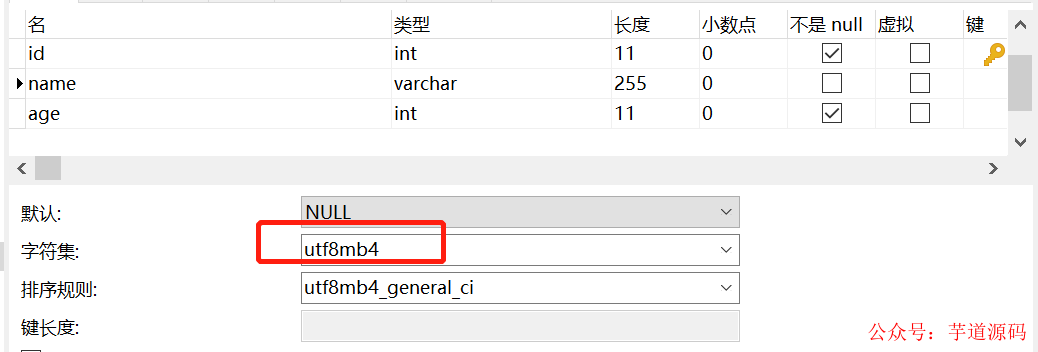
执行左外连接查询,user_job表还是走全表扫描,如下:
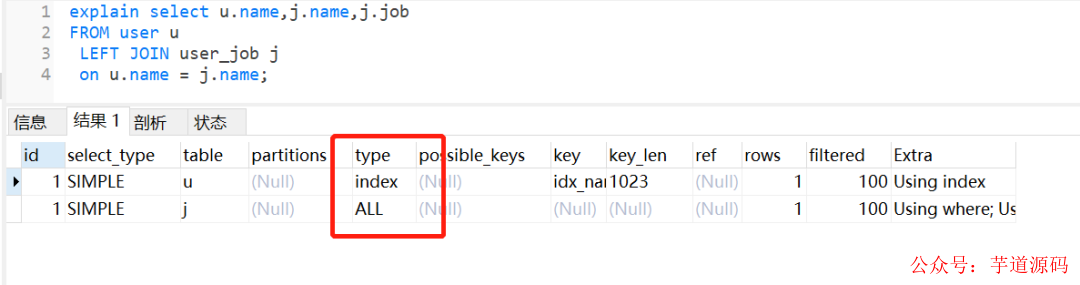
如果把它们的name字段改为编码一致,相同的SQL,还是会走索引。
2.9 group by使用临时表
group by一般用于分组统计,它表达的逻辑就是根据一定的规则,进行分组。日常开发中,我们使用得比较频繁。如果不注意,很容易产生慢SQL。
2.9.1 group by执行流程
假设有表结构:
CREATETABLE`staff`( `id`bigint(11)NOTNULLAUTO_INCREMENTCOMMENT'主键id', `id_card`varchar(20)NOTNULLCOMMENT'身份证号码', `name`varchar(64)NOTNULLCOMMENT'姓名', `age`int(4)NOTNULLCOMMENT'年龄', `city`varchar(64)NOTNULLCOMMENT'城市', PRIMARYKEY(`id`) )ENGINE=InnoDBAUTO_INCREMENT=15DEFAULTCHARSET=utf8COMMENT='员工表';
我们查看一下这个SQL的执行计划:
explainselectcity,count(*)asnumfromstaffgroupbycity;

Extra 这个字段的Using temporary表示在执行分组的时候使用了临时表
Extra 这个字段的Using filesort表示使用了文件排序
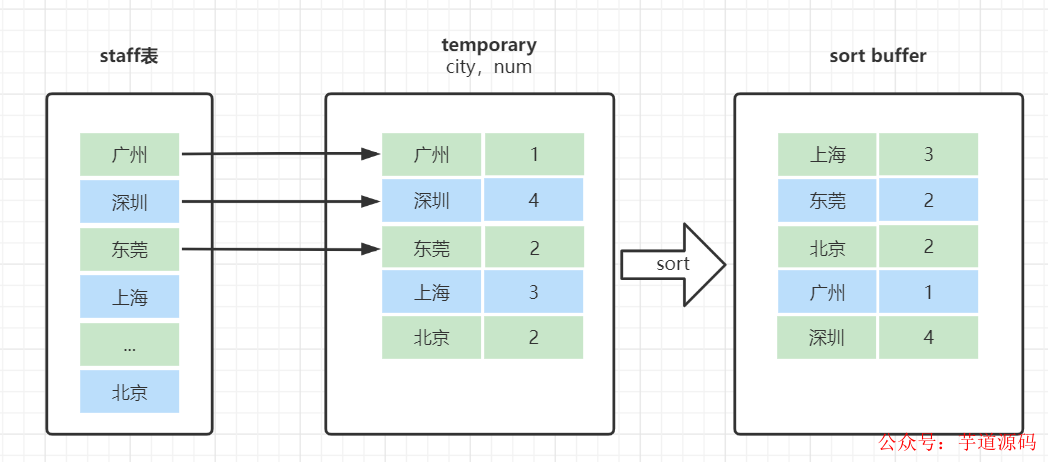
group by是怎么使用到临时表和排序了呢?我们来看下这个SQL的执行流程
selectcity,count(*)asnumfromstaffgroupbycity;
创建内存临时表,表里有两个字段city和num;
全表扫描staff的记录,依次取出city = 'X'的记录。
判断临时表中是否有为city='X'的行,没有就插入一个记录 (X,1);
如果临时表中有city='X'的行,就将X这一行的num值加 1;
遍历完成后,再根据字段city做排序,得到结果集返回给客户端。这个流程的执行图如下:
临时表的排序是怎样的呢?
就是把需要排序的字段,放到sort buffer,排完就返回。在这里注意一点哈,排序分全字段排序和rowid排序
如果是全字段排序,需要查询返回的字段,都放入sort buffer,根据排序字段排完,直接返回
如果是rowid排序,只是需要排序的字段放入sort buffer,然后多一次回表操作,再返回。
2.9.2 group by可能会慢在哪里?
group by使用不当,很容易就会产生慢SQL问题。因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表。
如果执行过程中,会发现内存临时表大小到达了上限(控制这个上限的参数就是tmp_table_size),会把内存临时表转成磁盘临时表。
如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间。
2.9.3 如何优化group by呢
从哪些方向去优化呢?
方向1:既然它默认会排序,我们不给它排是不是就行啦。
方向2:既然临时表是影响group by性能的X因素,我们是不是可以不用临时表?
我们一起来想下,执行group by语句为什么需要临时表呢?group by的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果啦?
可以有这些优化方案:
group by 后面的字段加索引
order by null 不用排序
尽量只使用内存临时表
使用SQL_BIG_RESULT
2.10 delete + in子查询不走索引!
之前见到过一个生产慢SQL问题,当delete遇到in子查询时,即使有索引,也是不走索引的。而对应的select + in子查询,却可以走索引。
MySQL版本是5.7,假设当前有两张表account和old_account,表结构如下:
CREATETABLE`old_account`( `id`int(11)NOTNULLAUTO_INCREMENTCOMMENT'主键Id', `name`varchar(255)DEFAULTNULLCOMMENT'账户名', `balance`int(11)DEFAULTNULLCOMMENT'余额', `create_time`datetimeNOTNULLCOMMENT'创建时间', `update_time`datetimeNOTNULLONUPDATECURRENT_TIMESTAMPCOMMENT'更新时间', PRIMARYKEY(`id`), KEY`idx_name`(`name`)USINGBTREE )ENGINE=InnoDBAUTO_INCREMENT=1570068DEFAULTCHARSET=utf8ROW_FORMAT=REDUNDANTCOMMENT='老的账户表'; CREATETABLE`account`( `id`int(11)NOTNULLAUTO_INCREMENTCOMMENT'主键Id', `name`varchar(255)DEFAULTNULLCOMMENT'账户名', `balance`int(11)DEFAULTNULLCOMMENT'余额', `create_time`datetimeNOTNULLCOMMENT'创建时间', `update_time`datetimeNOTNULLONUPDATECURRENT_TIMESTAMPCOMMENT'更新时间', PRIMARYKEY(`id`), KEY`idx_name`(`name`)USINGBTREE )ENGINE=InnoDBAUTO_INCREMENT=1570068DEFAULTCHARSET=utf8ROW_FORMAT=REDUNDANTCOMMENT='账户表';
执行的SQL如下:
deletefromaccountwherenamein(selectnamefromold_account);
查看执行计划,发现不走索引:

但是如果把delete换成select,就会走索引。如下:

为什么select + in子查询会走索引,delete + in子查询却不会走索引呢?
我们执行以下SQL看看:
explainselect*fromaccountwherenamein(selectnamefromold_account); showWARNINGS;//可以查看优化后,最终执行的sql
结果如下:
select`test2`.`account`.`id`AS`id`,`test2`.`account`.`name`AS`name`,`test2`.`account`.`balance`AS`balance`,`test2`.`account`.`create_time`AS`create_time`,`test2`.`account`.`update_time`AS`update_time`from`test2`.`account` semijoin(`test2`.`old_account`) where(`test2`.`account`.`name`=`test2`.`old_account`.`name`)
可以发现,实际执行的时候,MySQL对select in子查询做了优化,把子查询改成join的方式,所以可以走索引。但是很遗憾,对于delete in子查询,MySQL却没有对它做这个优化。
日常开发中,大家注意一下这个场景哈
[1] 慢SQL优化一点小思路:https://juejin.cn/post/7048974570228809741#heading-7[2] SQL优化万能公式:5 大步骤 + 10 个案例: https://developer.aliyun.com/article/980780
-
SQL
+关注
关注
1文章
777浏览量
44403
原文标题:公司25k招了一个程序员不会优化慢SQL,试用期没过就被开了!
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
焊接技术流程优化方法
浅谈SQL优化小技巧
常用SQL函数及其用法
Jtti:常用的网络质量监控方法有哪些
大数据从业者必知必会的Hive SQL调优技巧
环路测试方法有哪几种
直流无刷电机调速有几种方法及应用
stm32程序烧录的几种方法?
QPS提升10倍的sql优化
测量串联电路的Q值有几种方法
产生脉冲信号有几种方法





 工商网监
工商网监
评论