 通过分布式分解优化边缘
通过分布式分解优化边缘
在边缘扩展坚固的任务关键型处理资源的范例正在迅速发展。分解处理现在正在通过高速以太网连接在边缘实现低延迟、网络连接的所有内容,从 GPU 服务器到 NVMe 结构存储设备。
随着技术的不断创新,处理和存储性能呈指数级增长,以满足数字世界的需求,必须考虑新的计算架构。随着边缘环境限制功耗、占用空间和延迟的要求,分解计算资源正在成为构建边缘处理的新方法。
对于国防和航空航天领域的边缘计算应用,任务平台通常需要保持活动时间远远超过底层处理组件。考虑到 CPU 制造商(如英特尔)每两到三年发布一次新一代 x86 服务器级处理器。为了在给定平台上保持最先进的计算能力,系统集成商采用的默认技术更新方法是使用最新的处理器重新指定新的服务器配置,这意味着每隔几年更换一次设备机架。
每一代处理器都会推出新的创新,包括 PCIe 带宽翻倍、更多 PCIe 通道以获得更好的硬件支持、更快的内存速度和更新的安全功能。然而,每次新的处理刷新都会带来越来越大的热挑战。例如,英特尔服务器级 CPU 的散热设计功耗 (TDP) 等级在过去四代更新中翻了一番——从 Broadwell 处理器一代的 50 至 145 W 范围到第三代至强可扩展处理器的当前 105 至 300 W 范围。因此,将旧服务器与更新的替换服务器交换可能会与有限的功率预算发生冲突。
处理被推到边缘
尽管存在这些挑战,但高级计算资源继续从数据中心转移到部署的边缘平台,从而为雷达信号处理等应用提高效率和新功能。这种高性能边缘系统必须能够快速分配和重新分配并行处理资源,以通过各种类型的算法处理来自多个传感器源的数据流,例如用于人工智能 (AI) 的深度学习/机器学习 (ML) 神经网络。
为了优化架构,某些计算任务与其他硬件(如图形处理单元 (GPU))一起分配给传统 CPU,给定数学密集型任务,其中并行处理非常适合。值得注意的是,GPU已被证明在涉及推理和训练的计算和数据密集型用例中超过了通用处理器的能力。
一个示例用例是认知雷达,它应用 AI 技术从接收到的返回信号中提取信息,然后使用该信息来改进发射参数,例如频率、波形形状和脉冲重复频率。为了有效,认知雷达必须近乎实时地执行这些人工智能算法。反过来,这需要在处理链中使用强大的 GPU。在 NVIDIA 执行的 AI 推理基准测试中,A100 GPU 的性能比 CPU 高出 249 倍。通过将推理和训练等任务卸载到 GPU,不再需要过度指定 CPU,这反过来又提供了降低 TDP 的机会。
使命需要跟上
将任务从 CPU 卸载到 GPU 所带来的增量功耗改进加起来,但不足以跟上边缘环境的需求。在 2022 年 NVIDIA GTC 活动中,洛克希德·马丁公司副研究员本·卢克(Ben Luke)描述了边缘功耗、延迟和传感器数据的这个问题:“现代传感器的一大挑战是数据速率不断提高。..。..还有强烈的愿望移动该处理。..更接近边缘,这会导致尺寸、重量和功率限制,这些限制正在推动该架构。
尽管技术更新最初可能会由于 CPU 生命周期障碍而出现,但很明显,通过更新到最新硬件可以获得固有的优势。每一代处理都有关键的改进,使系统能够跟上传感器数据的加速增长,并减轻对手的进步。与Ben Luke的评论直接相关的是硬件提供减少延迟和决策时间的能力。
在关于边缘计算和人工智能未来的 datacenterHawk 播客中,NVIDIA 解决方案架构总监 Rama Darba 表示:“你不能通过实时在云中做出人工智能或计算决策;存在延迟问题,存在计算挑战。非最新信息不再与做出明智决策相关。特别是在边缘,通过以推理为中心的硬件做出实时决策,利用经过训练的模型,在很大程度上依赖于对低延迟的需求。
分布式处理使能因素
边缘坚固耐用的数据中心可以通过采用数据处理单元 (DPU) 等硬件立即从分解中受益。DPU,例如NVIDIA Bluefield,有时被描述为智能 NIC [网络接口卡],具有额外的集成功能,例如 CPU 处理内核、高速数据包处理、内存和高速连接(例如,100 Gb/sec/200 Gb/s 以太网)。这些元素协同工作,使 DPU 能够执行网络数据路径加速引擎的多种功能。
对边缘应用非常重要的一项功能是能够使用直接内存访问 (DMA) 将网络数据直接馈送到 GPU,而无需系统 CPU 参与。DPU 不仅仅是一个智能网卡,还可以用作独立的嵌入式处理器,使用 PCIe 交换机架构作为 GPU、NVMe 存储和其他 PCIe 设备的根或端点运行。这样做可以改变系统架构:DPU 现在允许在最需要的地方共享 GPU 资源,而不是指定配备 GPU 和通用计算服务器的某种预定组合。
进入分解分布式处理范例
理解从现状到新启用的系统架构的范式转变的一种功能性方法是将数据中心视为整个资源处理池,而不是服务器子集,每个服务器都有专用功能。换句话说,现状是让单独的服务器执行任务 - 一些用于存储,另一些用于并行处理,另一些用于一般服务。虽然此模型基本上是按功能分解的,但缺少的关键要素是这些功能在多个系统中的分布不足。
考虑分布式分解传感器处理架构的框图(图 2)。传感器数据等关键任务信息的并行处理在支持 GPU 的系统上发送和执行,通过高速网络中继到 DPU,并共享到任何联网服务器以采取行动。

[图2 |框图显示了平台中数据处理单元的用例。
这种架构还可以保持从传感器到 GPU 再到联网服务器的端到端低延迟,无论服务器堆栈中的 CPU 代次如何。为了促进这种新架构,Mercury 坚固耐用的分布式处理 1U 服务器等产品分解 GPU 资源,并将见解直接分发到网络上,而无需独立的 x86 主机 CPU。(图 3。

[图3 |框图显示了Mercury坚固耐用的分布式处理服务器的构成。
通过跨网络分布,可以使用大部分资源。与其在每个系统中指定 GPU 并使用每个 GPU 的一定百分比,可以使用更少的 GPU 并将其分发到更多数量的系统,从而缓解热增加的趋势。与使用更少的GPU有关,NVIDIA的Darba将降低成本确定为这种架构的另一个关键改进:“最大的优势之一是,现在,因为你不在你知道你被锁定的地方,必须在这台服务器上运行这个应用程序,你实际上可以大大降低服务器成本和服务器大小。
DPU 用例不仅限于 GPU 和并行处理。例如,GPU卡可以是一个驱动器池,联网并显示为任何系统的本地存储。无论是并行处理还是存储,拥有可用于网络的资源都可以实现未来的可扩展性,并更新到更新、功能更强大的硬件,而无需对现有系统进行彻底检修或牺牲功率预算或低延迟。
硬件不仅可以进行分解,还可以实现资源分配,它提供了一个机会,通过创新的系统架构方法,使坚固的任务关键型平台的需求与最新技术保持一致。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
10816浏览量
210961 -
服务器
+关注
关注
12文章
8988浏览量
85124 -
数据中心
+关注
关注
16文章
4652浏览量
71921
发布评论请先 登录
相关推荐

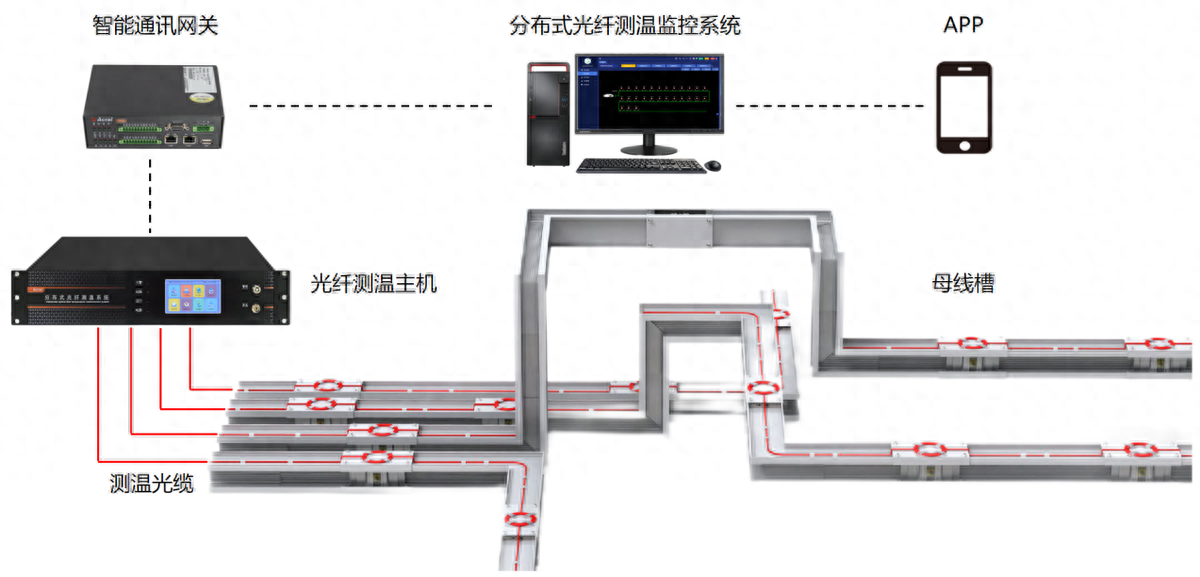
分布式光纤测温是什么?应用领域是?
分布式工业物联网平台:引领智能制造的新篇章
鸿蒙开发接口数据管理:【@ohos.data.distributedData (分布式数据管理)】

HarmonyOS实战案例:【分布式账本】
分布式控制系统的七个功能和应用
鸿蒙OS 分布式任务调度
什么是分布式架构?
分布式IO工业自动化数据采集与分析的核心
分布式锁的三种实现方式
鸿蒙原生应用开发——分布式数据对象
分布式系统硬件资源池原理和接入实践
redis分布式锁三个方法
zookeeper分布式原理
分布式通信是什么 分布式网络搭建






 工商网监
工商网监
评论