 AMD和Intel叫板英伟达,先后发布新芯片
AMD和Intel叫板英伟达,先后发布新芯片
编者按:因为拥有强悍的GPU,英伟达在多个领域拥有强悍的竞争力,这就吸引了更多的厂商进去其专注的市场,英特尔和AMD就虎视眈眈。
我们知道,Nvidia 并不是唯一一家创建了专门计算单元的公司,这些计算单元擅长支持 AI 训练的矩阵数学和张量处理,并且可以重新用于运行 AI 推理。英特尔已经收购了两家这样的公司——Nervana Systems,紧随其后的是 Habana Labs,这都是他们叫板Nvidia 的 “武器”。
英特尔是一家优秀的公司,正在追逐该公司认为在未来五年内将产生 500 亿美元的人工智能计算机会(用于训练和推理),从现在到 2027 年以 25% 的复合年增长率增长,以达到这一水平。鉴于“Ponte Vecchio”Xe HPC GPU 加速器中的大量矩阵和矢量数学,以及即将推出的“Sapphire Rapids”Xeon SP CPU 中的 AMX 矩阵数学单元中很可能有足够的推理能力,有理由想知道有多少英特尔预计出售的Gaudi训练和Goya 推理芯片。
我们知道,英特尔在 2016 年 8 月完成 3.5 亿美元的 Nervana Systems 交易和 2019 年 12 月以 20 亿美元收购 Habana Labs时,是在追求知识产权和人才,当然,因为这就是这场 IT 战争的打法,但我们一直想知道如果这些设备以及来自竞争对手 GraphCore、Cerebras、SambaNova Systems 和 Groq 的非常优雅和有趣的设计能够部署在类似于主流的东西中。私募股权投资者一直渴望搭上这辆 AI 芯汁列车,并进行了大量投资,上述四家公司迄今共筹集了 28.7 亿美元。
陪审团仍未出局,所有这些产品都刚刚起步,这就是为什么英特尔在 Nervana 和 Habana 上对冲它的赌注,就像它对数据中心中的 FPGA 感到害怕(主要归功于 Microsoft Azure)并于2015 年 6 月斥资 167 亿美元收购 Altera。在 2015 年到 2020 年间,当英特尔在数据中心计算领域占据主导地位时,它试图通过 Xeon CPU 计算来消除对其霸权地位的所有可能威胁,并且它有能力购买一些竞争对手。
现在,既然它想起了自己需要再次成为代工厂,它就不能再做出如此昂贵的进攻演习了,这些进攻实际上既是防守又是进攻。现在是时候尝试将其支付给 Nervana 和 Habana 的部分钱赚回来了。目前尚不清楚英特尔是否能够收回所有资金,即使它做出了 23.5 亿美元的投资,但正如我们所说,也许这不是重点。也许关键是要对 GraphCore、Cerebras、SambaNova Systems 和 Groq 进行反驳,因为英特尔在其 Xeon SP CPU 中添加了 AI 功能,并在今年推出了其独立 GPU。(Wave Computing 筹集了 2.033 亿美元用于开发其 AI 芯片,于 2020 年 4 月破产,一年后成为 MIPS 芯片技术的供应商,因此我们不再将其视为 AI 芯片的竞争者。)
在本周举行的 Intel Vision 2022 大会上,Gaudi2 AI 训练芯片是这家芯片制造商推出的新的大型计算引擎,顺便说一下,它并不是英特尔实际制造的芯片,而是与其前身Gaudi1一样,由竞争对手台积电制造。
与 Nervana Systems 一样,Habana Labs 非常认真地创建了一组芯片,为 AI 工作负载提供最佳性价比和最佳性能。Habana Goya HL-1000 推理芯片于 2019 年初发布,Gaudi1 AI 训练芯片,也称为 HL-2000,于当年夏天晚些时候首次亮相。
Gaudi1 架构有一个通用矩阵乘法 (GEMM) 前端,后端有 10 个张量处理器内核或 TPC,该芯片仅向用户公开了其中的 8 个,以帮助提高封装的良率。(显然,在英特尔收购 Habana Labs 后的某个时候,额外的两个张量核心暴露出来了。)
Gaudi1 使用了第二代 TPC,而 Goya HL-1000 AI 推理芯片使用了不那么强大和不那么复杂的原始 TPC 设计。Gadui1 芯片中的 TPC 可使用 C 编程语言直接寻址,具有张量寻址,并支持 BF16 和 FP32 浮点以及 INT8、INT16 和 INT32 整数格式。TPC 指令集具有加速 Sigmoid、GeLU、Tanh 和其他特殊功能的电路。
Gaudi1 采用 TSMC 的 16 纳米工艺实现,具有 24 MB 片上 SRAM、四组 HBM2 内存,容量为 32 GB,带宽为 1 TB/秒。Gaudi1 插入 PCI-Express 4.0 x16 插槽并消耗 350 瓦的电量,并将几乎所有的电量都转化为热量,就像芯片一样。(少量能量用于操作和存储信息。)
一个由 8 个 Gaudi2 服务器组成的集群,每个服务器有 8 个 Gaudi2 卡。
英特尔尚未透露对 Gaudi2 架构的深入了解,但这就是我们所知道的。
借助 Gaudi2,英特尔正在转向台积电的 7 纳米工艺,随着这种微缩,它能够将芯片上的 TPC 数量从 10 个增加到 24 个,并增加了对 Nvidia 新的 8 位 FP8 数据格式的支持。使用 FP8 格式,开发者现在可以拥有相同格式的低分辨率推理数据和高分辨率训练数据,并且在从训练转移到推理时不必在浮点和整数之间转换模型。这对 AI 来说是一个真正的福音,尽管较低精度的整数格式可能会在矩阵和矢量计算引擎中保留多年,以支持遗留代码和其他类型的应用程序。
Gaudi2 芯片有 48 MB 的 SRAM——如果它与 TPC 数量成线性比例,您会期望 2.4 倍而不是 2 倍的 SRAM,或 57.6 MB。
挂在 Gaudi2 芯片上的是 HBM2e 内存组,它提供 2.45 TB/秒的带宽,是 Gaudi1 芯片的 2.45 倍。HBM2e 内存组的数量没有透露,但 Gaudi2 有 6 个 16 GB HBM2e 组,而 Gaudi1 有 4 个 8 GB HBM2 组。仅增加两个 HBM2e 内存控制器就可以将带宽提高 1.33 倍,而剩余的带宽增加来自于提高内存速度。
Gaudi1 芯片有十个支持 RoCE 直接内存访问协议的 100 Gb/秒以太网端口——事实证明,每个 TPC 一个,但我们当时并不知道,因为只显示了八个。但 Gaudi2 有 24 个以太网端口,以 100 Gb/秒的速度运行,每个 TPC 也有一个。它的功率为 650 瓦。我们假设该设备插入 PCI-Express 5.0 插槽,但英特尔尚未证实这一点。
假设没有重大的架构变化和工艺从 16 纳米缩小到 7 纳米并没有带来时钟速度适度提升,我们预计 Gaudi2 芯片将提供大约 2.5 倍的 Gaudi2 性能。(还假设任何给定应用程序的处理精度相同。)但英特尔实际上并没有说明是否有任何架构变化(除了添加了一些媒体处理功能)以及时钟速度如何变化,所以我们有来推断。
我们通过查看这张关于 ResNet-50 机器视觉训练操作的图表来做到这一点,该图表将 Gaudi1 和 Gaudi2 与过去两代 Nvidia GPU 加速器进行对比:
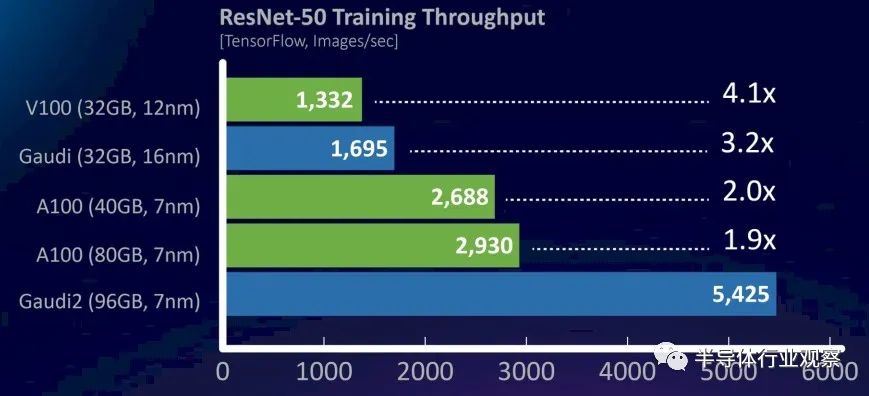
根据这个 ResNet-50 比较,Gaudi2 的性能是 Gaudi1 的 3.2 倍,但很难估计性能有多少是由于芯片容量的增加。这个特定的测试运行 TensorFlow 框架来进行图像识别训练,显示的数据是每秒处理的图像数量。
没有显示但很重要的一件事是 Gaudi2 加速器将如何叠加到 Hopper GPU,但 Nvidia 尚未透露任何特定测试的性能结果。但由于 H100 中的 HBM3 内存运行速度比 A100 加速器中使用的 HBM2e 内存快 1.5 倍,而 FP16、TF32 和 FP64 在新张量核心上提供 3 倍的性能,因此可以合理地预期 H100 将提供介于在 ResNet-50 视觉训练工作负载上的性能是 1.5 倍和 3 倍,因此 H100 在 ResNet-50 测试中每秒可提供 4,395 到 8,790 张图像的性能。我们的猜测是,它将比前者更接近后者,并且比英特尔可以通过 Gaudi2 提供的优势有相当大的优势。
与使用 BERT 模型的自然语言处理相比,图像识别和视频处理相对容易。以下是 Gaudi2 与 Nvidia V100 和 A100 的对比,请注意 Gaudi1 的缺失:
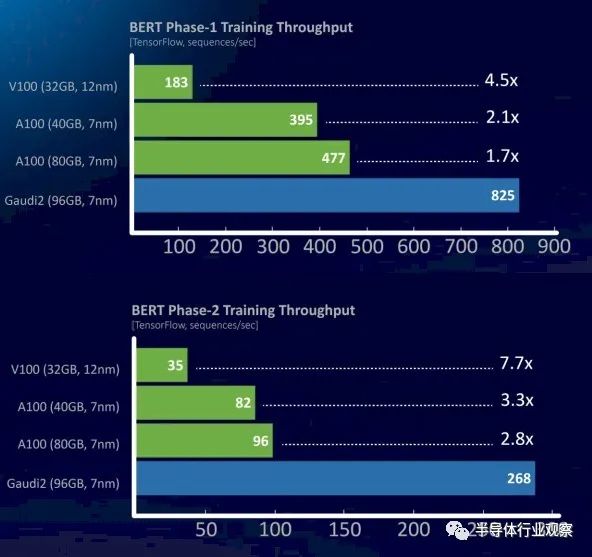
BERT 模型也在 TensorFlow 框架之上运行,该数据显示了在两个不同的训练阶段中每秒吞吐量的序列数。Habana Labs 部门的首席商务官 Eitan Medina 在一次简报中表示,Gaudi2 的性能几乎是 A100 的 2 倍。但 H100 拥有自己的 FP8 格式和 Transformer 引擎,可以动态地改变 AI 训练工作流程不同部分的数据和处理精度,可以做得更好。我们不知道多少,但我们强烈怀疑 Nvidia 至少可以缩小与 Gaudi2 的差距,并且很有可能超越它。
为了让事情变得有趣,英特尔在 Amazon Web Services 上启动了 DL1 Gaudi1 实例,然后分别基于 A100 和 V100 GPU 启动了 p4d 和 p3 实例,并进行了一些性价比分析以计算在 ResNet 中识别的每张图像的成本-50 基准。看看这个:
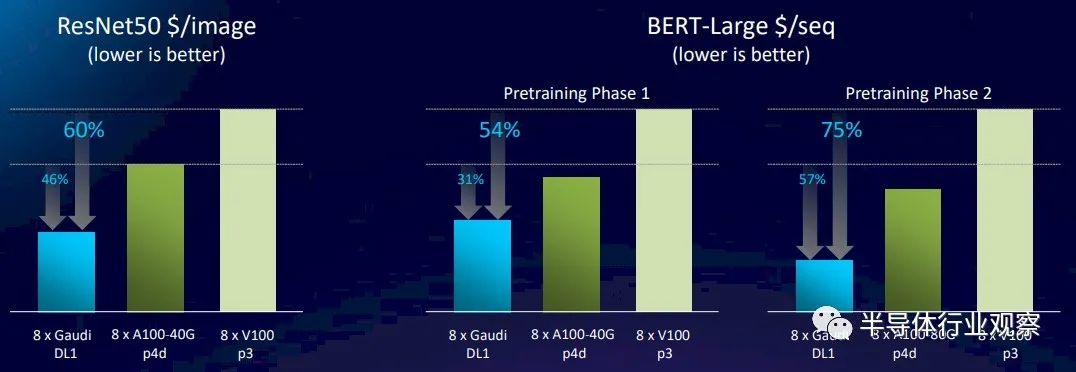
这张图表的意思是,Gaudi1 的性能略好于 V100——使用英特尔在上图中针对 ResNet-50 的性能数据显示了 27.3%——而且性价比高了大约 60%,这意味着 DL1 实例的成本大大低于使用 V100 的 p3 实例。随着迁移到具有 40 GB HBM2e 内存的基于 A100 的 p4d 实例,Nvidia 设备在 ResNet-50 上的吞吐量比 Gaudi1 高 58.6%,但 Gaudi1 处理每个图像的成本降低了 46%。这意味着 A100 实例确实要贵一些。如果我们对 Hopper GPU 加速器定价的猜测是正确的,而 Nvidia 对大约 3 倍的性能收取大约 2 倍的费用,英特尔将不得不将出售给 AWS 的 Gaudi2 芯片的价格保持在 AWS 仍然可以显示出比运行 AI 训练的 H100 实例更好的性价比的地方。
而在这一切中,Trainium 在哪里?
无论如何,英特尔在其实验室中运行了超过 1,000 个 Gaudi2,因此它可以调整 SynapseAI 软件堆栈,其中包括在 Habana 的图形编译器、内核库和通信库上运行的 PyTorch 和 TensorFlow 框架。值得一提的是,Gaudi2 芯片现已发货。
除了 Gaudi2 芯片,英特尔还在预览其 Goya 后续的 Greco 推理引擎,该引擎也在台积电制造。

Greco 推理卡具有 16 GB 的 LPDDR5 主内存,提供 204 GB/秒的内存带宽,而之前的 Goya 推理引擎使用 16 GB 的 DDR4 内存块提供 40 GB/秒的内存带宽。Habana 架构的这种 Greco 变体支持 INT4、BF16 和 FP16 格式,功耗为 75 瓦,大大低于 2019 年初宣布的 HL-1000 设备的 200 瓦。如上图所示,它被压缩到更紧凑的半高、半长 PCI-Express 卡。目前还没有关于这款产品的性能或价格的消息。
除了英特尔以外,AMD也更新了GPU产品线,以挑战英伟达。
AMD 发布 Radeon RX 6950 XT、6750 XT 和 6650 XT
AMD 今天早上揭开了三款新的 Radeon RX 6000 系列显卡的面纱,以完善其产品堆栈。新的产品涵盖了从中端到旗舰市场的所有市场,其中, Radeon RX 6950 XT、RX 6750 XT 和 RX 6650 XT 将作为 Radeon 系列的中代产品发布,为 AMD 最重要的显卡提供最后的性能提升. 利用更新的 18Gbps GDDR6 内存以及略微改进的时钟速度,今天发布的新卡承诺适度的性能提升,同时让 AMD 有机会展示他们的 RDNA2 GPU 架构在经过近 18 个月的改进后可以做什么。
从高层次上看,这三款新卡都是对 AMD 现有 Radeon RX 6900 XT、RX 6700 XT 和 RX 6600 XT 部件的小更新。为了利用 18Gbps GDDR6 不断增加的可用性,AMD 选择将其配备到 RX 6000 系列中的三款最重要的卡上,以便为它们提供适度的内存带宽提升。与此同时,AMD 也在利用这个机会来提高性能——无论是形象上还是字面上——稍微提高显卡的 TDP 以允许稍微更高的 GPU 时钟速度。
如前所述,整体变化很小,无论是在性能还是卡片构造方面。除了换成 18Gbps GDDR6 内存外,这些更新的规格都可以通过当前的卡设计来实现,并且没有其他硬件变化。与此同时,AMD 自己对新卡性能提升的估计约为 5% 到 6%——内存带宽的增加受到 GPU 时钟速度的小幅提升的影响。
尽管如此,对于 AMD 来说,这是一个进一步提高他们在一些最重要的视频卡上的竞争定位的机会。在当前这一代显卡的最后六个月左右,领先于 NVIDIA。NVIDIA 早就展示了他们自己的中代产品,如 3080Ti/3070TI 和 3080 12GB,因此 AMD 获得了可能成为最后一步的优势(至少在性能上层) 。
更新的 Radeon RX 6000 产品堆栈:扩展和退役
这一切发生的时机确实让 AMD 无意中抓住了一把落下的刀,然而,在经历了 18 个月的挫折之后,显卡市场终于回归常态。由于加密货币挖矿盈利能力大幅下降且供应情况有所改善,零售视频卡价格正在接近其最初的建议零售价。这对于游戏玩家、计算机科学家和其他任何想要以(更)合理的价格购买显卡的人来说都是个好消息,但对于 AMD 在尝试定价和定位他们的新部件时会遇到更多问题。AMD 甚至在推出新卡之前就已经需要重新定价一次,而现在这些被设计为优质、高价产品的卡将面临更大的市场压力。
除了将 RX 6950 XT、RX 6750 XT 和 RX 6650 XT 添加到 AMD 庞大的 Radeon RX 6000 系列产品堆栈之外,AMD 还利用这个机会淘汰了显卡Radeon RX 6600 XT——原本最快的 Navi 23 卡,以及 AMD 中端显卡努力的基石,最终将不复存在。该卡在市场上的地位正在被最快的 RX 6650 XT 所取代。

除此之外,RX 6900 XT 和 RX 6700 XT 将继续生产。尽管最便宜的 6900XT 已经达到 950 美元,但 AMD 及其合作伙伴可能很快就会发现自己不得不让他们的新卡与其他产品堆栈一起降价。
顺便说一句,我很高兴看到 AMD 对这些新部件使用了合理的命名系统。将所有新卡指定为 xx50 可以很容易地判断它们与现有卡有明显的不同,并且可以很容易地判断它们在更大的产品堆栈中的位置。AMD 有 4 位数字,很高兴看到 AMD 至少使用了 3 个数字,而不是添加更多的后缀或完全用多种变体重载产品名称。
Radeon RX 6950 XT、RX 9750 XT 和 RX 6650 XT
深入了解规格,让我们开始研究新卡。
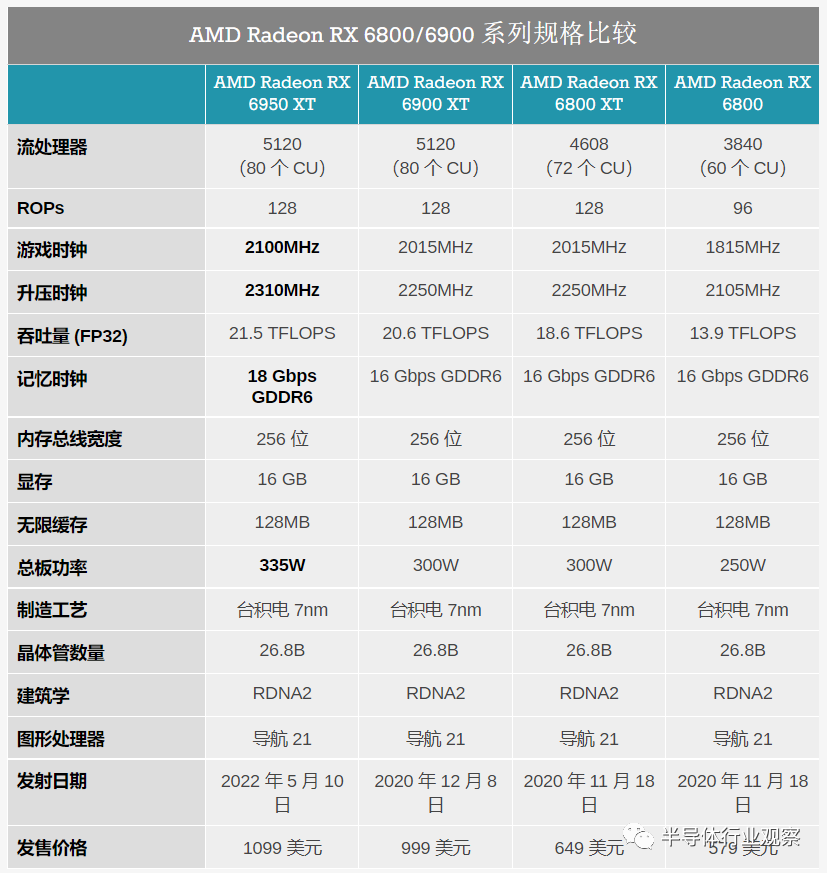
从顶部开始,我们拥有 AMD 的新旗舰 Radeon RX 6950 XT。这是原始 RX 6900 XT 的增强版,现在是 AMD 产品堆栈中功能最强大的显卡,也是最昂贵的显卡。

鉴于最初的 RX 6900 XT 已经基于具有 40 个 CU 和 128MB 无限缓存的完全启用的 Navi 21 GPU,AMD 除了提高 GPU 和内存时钟速度之外,几乎没有其他途径来提高性能,所以这正是他们的目标,且已经完成了。
除了将显卡与 16GB 最新的 18Gbps GDDR6 内存配对外,显卡的 GPU 时钟速度也得到了提升;官方游戏时钟现在是 2100MHz (+10%),最大加速时钟是 2310MHz (+3%)。这使 RX 6950 XT 的内存带宽增加了 12.5%,并且整个 GPU 本身的吞吐量平均提高了几个百分点。
为了为这种改进的性能买单,AMD 还提高了 TBP。最初的 RX 6900 XT 是 300W 卡,而 RX 6950 XT 在参考规格下是 335W 卡,董事会合作伙伴可以随时进一步提高。AMD 在这一点上处于电压/频率曲线的远端,虽然提高 TBP 确实可以通过让卡更频繁地接近其最大 GPU 时钟速度来提高性能,但它们正在逐渐减少此时返回。所有这些都进一步反映在 AMD 的官方性能数据中,RX 6950 XT 的着陆速度比原始的 RX 6900 快了约 4%。
关于这一点,值得指出的是,新的 18Gbps GDDR6 也可能是这些新卡 TBP 增加的一个因素。虽然最新 GDDR6 的电压保持在 1.35v,但由于支持如此高的信号速率的电力成本,总体功耗仍会上升。AMD 没有正式公布其显卡的 GPU 和 DRAM 功耗,但如果在所有其他条件相同的情况下,RX 6950 XT 的 DRAM 功耗比 RX 更高,我一点也不感到惊讶6900 XT。在这一点上,如果 AMD 无论如何都需要增加 TBP(以保持时钟速度恒定),为什么不增加一点以从 GPU 本身中挤出一些额外的空间。
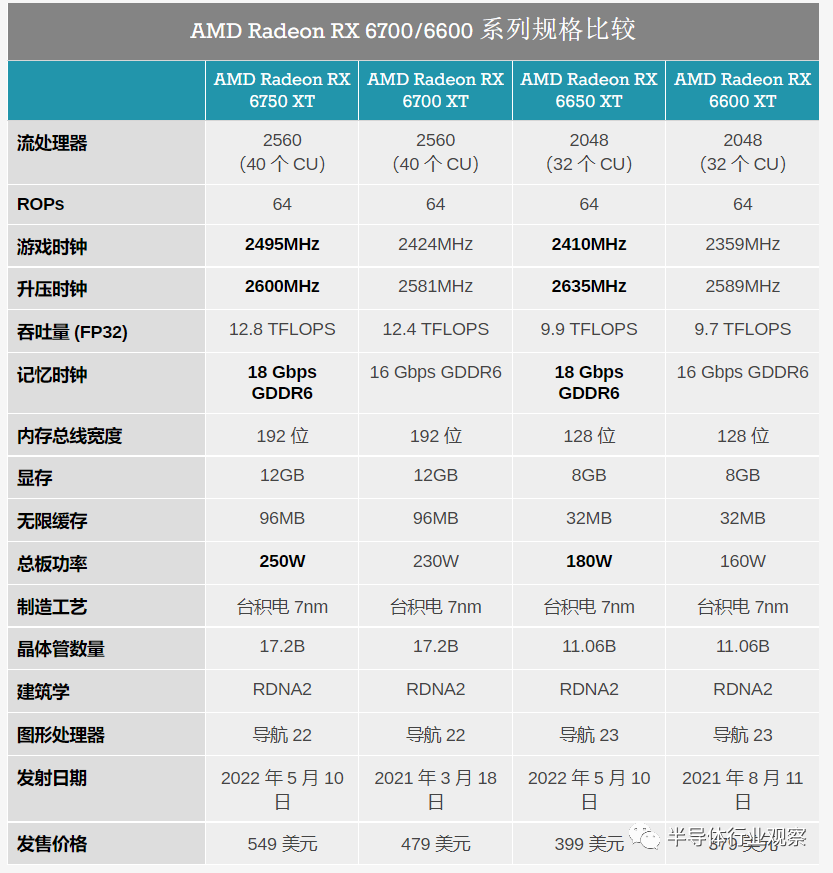
同时,在 AMD Radeon 产品堆栈的中间位置,我们有 RX 6750 XT 和 RX 6650 XT。与 RX 6950 XT 一样,这些卡的前身已经基于完全启用的 Navi GPU——分别为 Navi 22 和 Navi 23——因此 AMD 正在转向提高时钟速度以提高性能。

对于 RX 6750 XT,与最初的 RX 6700 XT 相比,其最大时钟速度已提升至 2600MHz (+
同时,RX 6650 XT 完全取代了原始的 RX 6600 XT,最大时钟速度为 2635MHz,游戏时钟为 2410MHz,两者都比原始卡快 2% 左右。而且,尽管 TBP 增加了,内存带宽增加了 12.5%,但它在 AMD 的官方数据中显示出最小的增益,只有 2% 的性能提升。在这种情况下,AMD 不保留原始的 RX 6600 XT 是可以理解的,因为 RX 6650 XT 的速度不够快,无法将自己与旧卡有意义地分开。
一旦这些卡开始出货,我们将看到第三方基准测试如何发挥作用,但假设 AMD 的数据在这里是准确的,这证明了他们的片上 Infinity Cache 的价值。虽然内存带宽几乎不会随着 1 对 1 性能的提高而增加,但值得注意的是,额外带宽所增加的性能是多么少 - 或者相反,Navi 23 GPU 已经被 16Gbps GDDR6 在 128位内存总线。即使只有 32MB 的缓存也在做大量工作来限制 1080p 的 DRAM 带宽需求。
最后,与 RX 6950 XT 一样,这两张卡的 TBP 也在增加。RX 6750 XT 将搭载 250W 参考 TBP,比原始 RX 6700 XT 高 20W。同时,RX 6650 XT 将调整为 180W,这也比其前身 RX 6600 XT 高 20W。
驱动程序新闻:隐私视图和 AMD 超级分辨率 1.1
在今天的产品公告中,还有一个关于 AMD 产品生态系统驱动程序方面的简短更新。
AMD 的 GPU 加速隐私视图功能,原定于第一季度推出,终于接近发布,应该在本月的驱动程序下降中。同时,根据 AMD 的说法,他们基于驱动程序的 AMD 超分辨率技术的更新版本正在开发中。尽管此时他们没有透露将针对 Super Resolution 1.1 调整或添加哪些功能。
合作伙伴卡和产品定位
鉴于今天的发布是对一些 AMD 现有卡的相对较小的更新,AMD 及其董事会合作伙伴正在开始使用新卡。除了合作伙伴自己的工作外,AMD 还发布了 RX 6950 XT 和 RX 6750 XT 参考卡的更新版本。因此,喜欢 AMD 参考设计的游戏玩家——甚至只是直接从 AMD 购买——将能够这样做。

与此同时,董事会合伙人将一如既往地做自己的事情。期望看到库存时钟和工厂超频卡的通常组合,董事会合作伙伴希望从 AMD 的最新硬件中榨取更多。
除了今天发布的信息之外,AMD 并没有向我们提供太多关于可用性的信息。但考虑到底层 GPU 的生产时间——以及最近几周 6900XT/6700XT/6600XT 的可用性——这不应该是一个特别疯狂或供应受限的发布。在过去的 18 个月之后,所有这些都是一个不错的变化。
尽管当原始显卡最终降到更合理的价格时,整个显卡市场对新的高价 Radeon 显卡有多大的胃口还有待观察。由于 RX 6800 或 RX 6600 以外的任何产品的供应在这一点上基本上不受限制,因此新卡的大部分价值来自其略高的性能,这意味着生态系统没有太多回旋余地来提供更高的性能和价格。或许 AMD 已经在采取进一步措施来支撑视频卡价格也就不足为奇了,包括即将推出的游戏捆绑优惠,尽管它实际上还没有上线,但它今天就开始了。
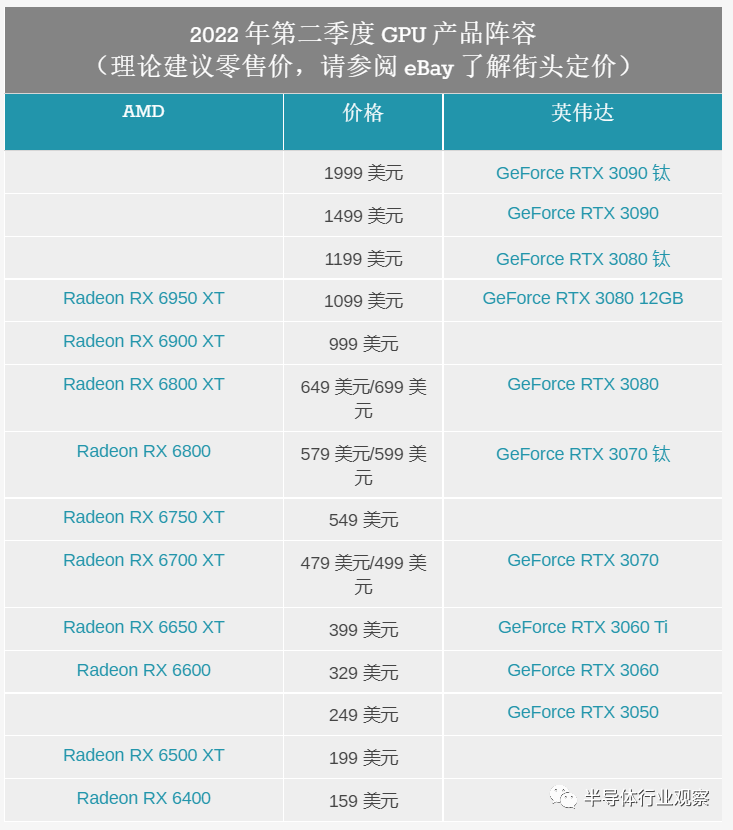
值得庆幸的是 ,AMD的竞争对手不是他们自己,而是市场领导者 NVIDIA。尽管 GeForce 卡的价格也有所下降,但对挖矿更友好的卡的降价速度较慢,因此其中许多卡的售价仍然比原来的建议零售价高出不少。因此,AMD 拥有庞大且现在甚至更大的产品堆栈,可以与 NVIDIA 堆栈中的所有产品相媲美——而且就目前而言,它通常具有显着的价格优势。
AMD 认为它们也具有性能优势,虽然我非常怀疑 RX 6950 XT 是否会始终胜过 RTX 3090(AMD 选择的竞争对手),但 RX 6750 XT 和 RX 6650 XT 相对于 NVIDIA 的基线表现更好分别是 RTX 3070 和 3060 卡。这次发布的重点之一是让事情更上一层楼:让 AMD 全力以赴,提供新的硬件素材来展示他们与 NVIDIA 的对比。

总结一下,期待今天早上在零售货架上看到新的 Radeon 卡——如果不是更早的话。
编辑:黄飞
-
FPGA
+关注
关注
1628文章
21706浏览量
602680 -
amd
+关注
关注
25文章
5460浏览量
134031 -
intel
+关注
关注
19文章
3481浏览量
185854 -
机器视觉
+关注
关注
161文章
4354浏览量
120226 -
英伟达
+关注
关注
22文章
3759浏览量
90940
原文标题:AMD和Intel发新芯片,再次挑战英伟达
文章出处:【微信号:AI_Architect,微信公众号:智能计算芯世界】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AMD最强AI芯片,性能强过英伟达H200,但市场仍不买账,生态是最大短板?


AMD发布英伟达竞品AI芯片,预期市场规模将大幅增长
英伟达Blackwell芯片量产加速,Q4预计出货达45万片






 工商网监
工商网监
评论