 基于Transformer架构的文档图像自监督预训练技术
基于Transformer架构的文档图像自监督预训练技术
本文简要介绍ACM MM 2022录用论文“DiT: Self-supervised Pre-training for Document Image Transformer”[1]的主要工作。该论文是2022年微软亚研院发表的LayoutLM V3[2]的前身工作,主要解决了文档领域中标注数据稀少和以视觉为中心的文档智能任务骨干网络的预训练问题。
一、研究背景
近年来自监督预训练技术已在文档智能领域进行了许多的实践,大多数技术是将图片、文本、布局结构信息一起输入统一的Transformer架构中。在这些技术中,经典的流程是先经过一个视觉模型提取额外文档图片信息,例如OCR引擎或版面分析模型,这些模型通常依赖于有标注数据训练的视觉骨干网络。已有的工作已经证明一些视觉模型在实际应用中的性能经常受到域迁移、数据分布不一致等问题的影响。而且现有的文档有标注数据集稀少、样式单一,训练出来的骨干网络并非最适用于文档任务。因此,有必要研究如何利用自监督预训练技术训练一个专用于文档智能领域的骨干网络。本文针对上述问题,利用离散变分编码器和NLP领域的常用预训练方式实现了文档图像的预训练。

图1具有不同布局和格式的视觉丰富的业务文档,用于预培训DiT
二、DiT原理简述
2.1总体结构
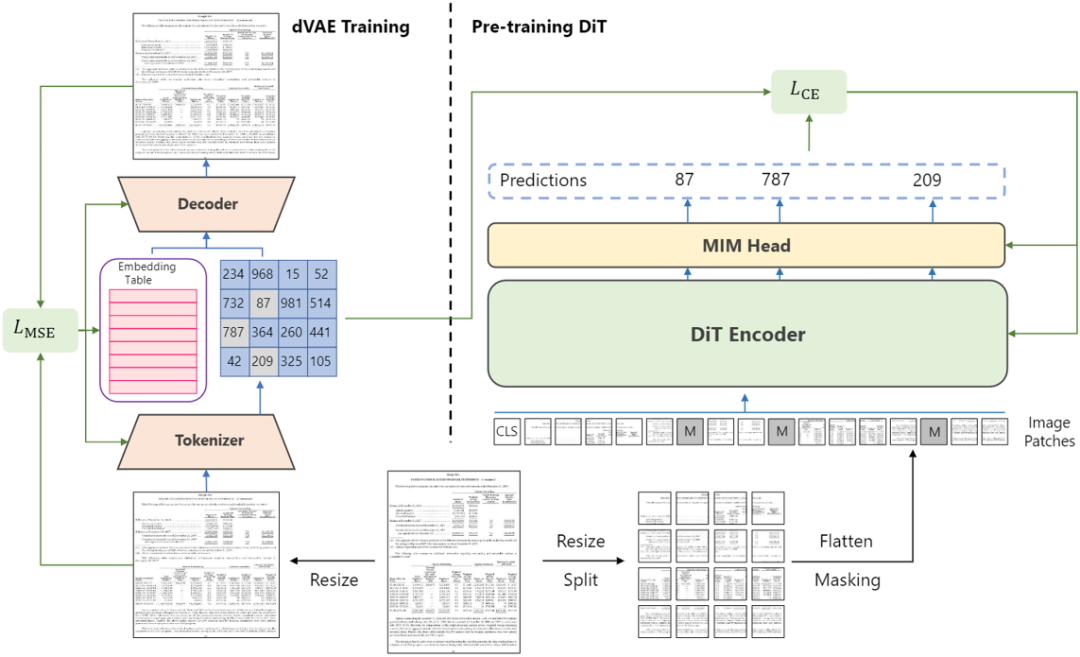
图2 DiT的总体架构
Fig 2是DiT的整体结构。DiT使用ViT[3]作为预训练的骨干网络,模型的输入是图像Patch化后的Embedding特征向量,Patch的数量和离散变分编码器的下采样比例有关。输入经过ViT后输出到线性层进行图像分类,分类层的大小是8192。预训练任务和NLP领域的完型填空任务一致,先对输入的Patch随机掩膜,在模型输出处预测被遮盖的Patch对应的Token,Token由Fig 2 中左侧的离散变分编码器生成,作为每个Patch的Label,预训练过程使用CE Loss监督。
2.2 离散变分编码器dVAE
离散变分编码器作为Image Tokenizer,将输入的Patch Token化,来源于论文DALL-E[4],在预训练任务开始前需要额外训练。本文使用数据集IIT-CDIP[5]重新训练了DALL-E中的离散变分编码器以适用于文档任务。在预训练任务中只使用到编码器的部分,解码器不参与预训练,编码器将输入图片下采样到原来的1/8,例如输入尺度为112*112,那编码后的Token Map为14*14,此时的Map大小,应与ViT输入Patch数保持一致。
2.3 模型微调
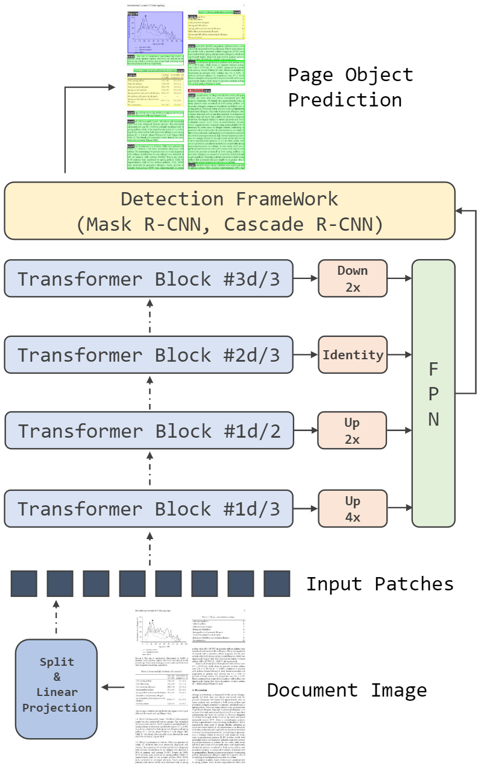
图3在不同检测框架中应用DiT作为骨干网络的图示
模型预训练完成后,需针对下游任务进行微小的结构改动,针对分类任务,输入经过平均池化和线性层进行分类。针对检测任务,如Fig 3所示,在ViT的特定层进行下采样或上采样,然后输入到FPN和后续的检测框架中。
三、主要实验结果及可视化效果
表1.RVL-CDIP上的文档图像分类精度(%),其中所有模型都使用224×224分辨率的纯图像信息(无文本信息)。
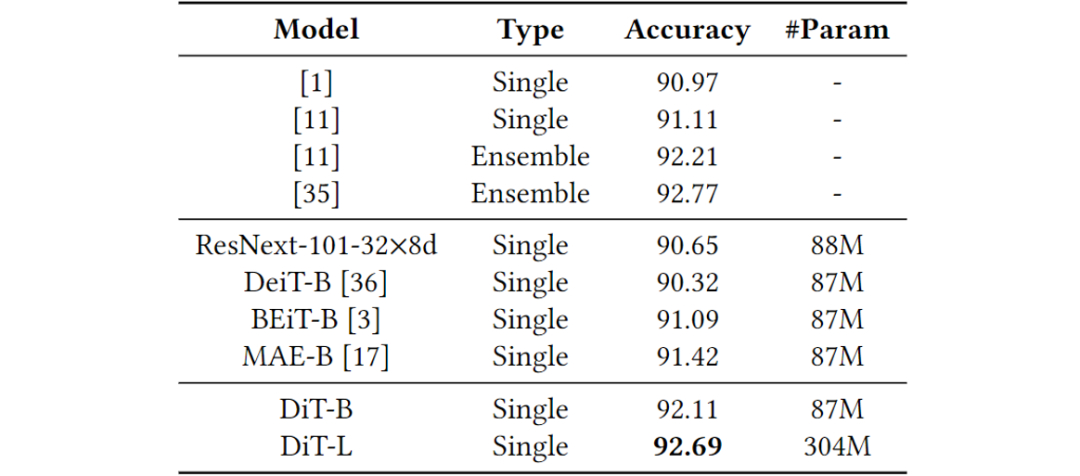
表2.PubLayNet验证集上的文档布局分析mAP@IOU[0.50:0.95]。ResNext-101-32×8d缩短为ResNext,级联为C。
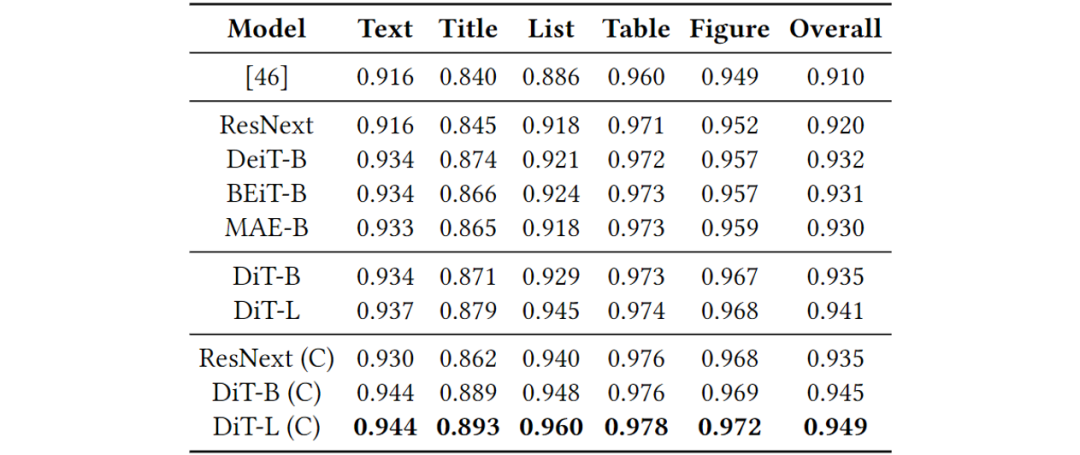
表3.ICDAR 2019 cTDaR的表检测精度(F1)
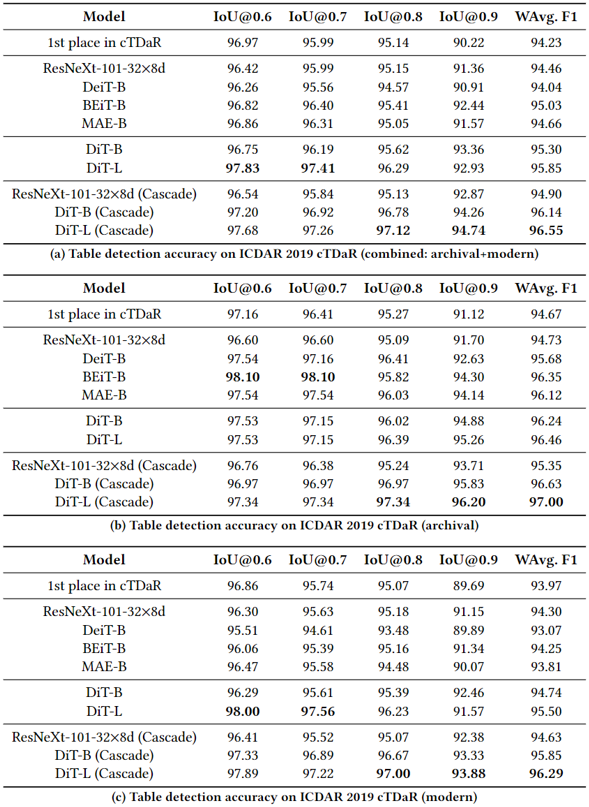
表4.文本检测精度(IoU@0.5)在FUNSD任务#1中,掩码R-CNN与不同的主干(ResNeXt、DeiT、BEiT、MAE和DiT)一起使用。“+syn”表示使用包含1M文档图像的合成数据集训练DiT,然后使用FUNSD训练数据进行微调。

图4使用不同标记器进行图像重建
从左到右:原始文档图像,使用自训练dVAE标记器进行图像重建,使用DALL-E标记器进行的图像重建从表1、表2、表3、表4
来看,文章所提方法在各种下游任务中取得了state-of-the-art的结果,验证了该方法在文档领域的有效性。Fig 4中展示了重新训练的离散变分编码器的可视化输出,结果显示本文中的离散变分编码器效果更好。
四、总结及讨论
本文设计了一个利用大量无标签文档图像预训练ViT的自监督方法,该方法的核心是利用离散变分编码器对图像Patch进行Token化,再使用NLP领域的掩码重建任务进行预训练。从实验结果可以看出,该方法在多个下游任务的有效性,探索了自监督任务在文档领域的可能性。
审核编辑:郭婷
-
编码器
+关注
关注
45文章
3651浏览量
134793 -
数据
+关注
关注
8文章
7085浏览量
89234
原文标题:上交&微软提出DiT:一种基于Transformer的文档图像自监督预训练方法 | ACM MM 2022
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Transformer是机器人技术的基础吗
时空引导下的时间序列自监督学习框架






 工商网监
工商网监
评论