 基于激光雷达的全稀疏3D物体检测器
基于激光雷达的全稀疏3D物体检测器
介绍一下我们组前段时间的一个微小工作

Fully Sparse 3D Object Detection (NeurIPS 2022)
Authors:Lue Fan,王峰, 王乃岩,Zhaoxiang Zhang
论文:https://arxiv.org/abs/2207.10035
代码已经开源在:
https://github.com/tusen-ai/SST
长话短说,我们提出了一种基于激光雷达的全稀疏3D物体检测器,在Waymo数据集和Argoverse 2数据集上都达到了不错的精度和速度。下面是一个简要的介绍。
一、导言
目前以SECOND,PointPillars以及CenterPoint为代表的主流一阶段点云物体检测器都或多或少依赖致密特征图(dense feature map)。这些方法基本都会把稀疏体素特征“拍成“dense BEV feature map。这样做可以沿用2D检测器的很多套路,取得了非常不错的性能。但是由于dense feature map的计算量和检测范围的平方成正比,使得这些检测器很难scale up到大范围long-range检测场景中。比如新出的Argoverse 2数据集具有[-200, 200] x [-200, 200]的理论检测范围,比常用的不超过[-75. 75] x [-75, 75]的范围大了许多。于是便引出了本文想解决的一个痛点问题:
如何去掉这些dense feature map,把检测器做成fully sparse的,以此高效地实现 long-range LiDAR detection?
这里补一句:全稀疏其实并不是一个新概念,在点云物体检测发展的早期,以PointRCNN为代表的众多纯point-based 方法天生就是全稀疏的。但由于Neighborhood query和FPS的存在,纯point-based方法在大规模点云数据上的效率不是很理想。这就导致纯point-based方法在点云规模较大的benchmark上性能表现不佳(没办法用较大的模型和分辨率。)
而去掉dense feature map的一个直接问题就是会导致物体中心特征的缺失(center feature missing)。这是由于点云常常分布在物体的侧表面,对于大物体尤其如此。在dense detector中,多层的卷积会把物体边缘的有效特征扩散到物体中心,因此这些检测器不存在直接的中心特征缺失问题,可以使用已被证明非常有效的center assignment。下图展示了特征扩散的过程:
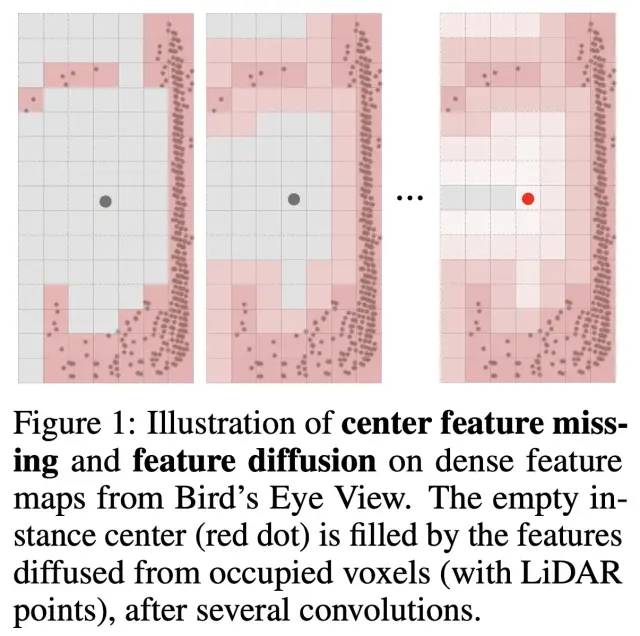
为了解决在全稀疏结构下中心特征缺失的问题,我们有一个基本想法:
既然中心特征缺失了,那么就不依靠中心特征做预测,而是依靠物体整体的有效特征做预测。
二、方法
顺着上面的基本想法,一个具体的思路就是先把物体分割出来,再将物体当作一个整体,并用稀疏的方式提取特征。第一步的分割在全稀疏的结构下很好实现,接下来物体特征的提取也可以通过众多成熟的point-based方法实现。那么我们的方法就呼之欲出了:
sparse voxel encoder作为backbone和segmentor来分割物体并预测每个点所对应的物体中心
对预测出来的众多中心点进行聚类,得到一个一个的instance。这一步类似VoteNet,但我们采用了connected component labeling的方式来聚类,这一点其实对大物体性能挺重要的。
对于每一个instance用稀疏的方式提取整体特征,并进行该instance外接框的reasoning。
前两步都很简单直接,但第三步稍有麻烦。对instance提取特征最常用的选择就是在instance内部做point-based operation, 但是之前提到这类方法效率较低。因此我们试图规避其中诸如neighborhood query和FPS这种比较耗时的操作。我们的想法是,既然已经得到了一个个instance,何不直接将instance作为一个一个独立neighborhood group,扔掉进一步的ball query或者KNN操作。
这样做实质上是把instance当成了“voxel”来处理,因为instance和voxel本质上都属于对整个点云的一种non-overlapping划分。那么我们就可以直接套用提取单个体素特征那一套方案来提取instance特征,比如Dynamic VFE。具体而言,就是对instance内的每个点做MLP,再做instance-wise的pooling得到instance feature。instance feature又可以重新assign到instance内部的每个point上,这一过程可以不断重复。这本质上是多个简单的PointNet叠加,也可以换成其他更强力的操作。值得强调的是,由于3D空间里instance之间天然不会重叠(正如同voxel),以上的pooling操作可以通过torch中scatter operation来高效地动态实现(无需对每个组进行padding或者设置点数上限)。
得到最终的instance feature之后,直接预测对应instance的外接框和类别即可,我们将整个对instance进行处理的模块称之为 Sparse Instance Recognition (SIR)。
方法总体框架如下图所示:
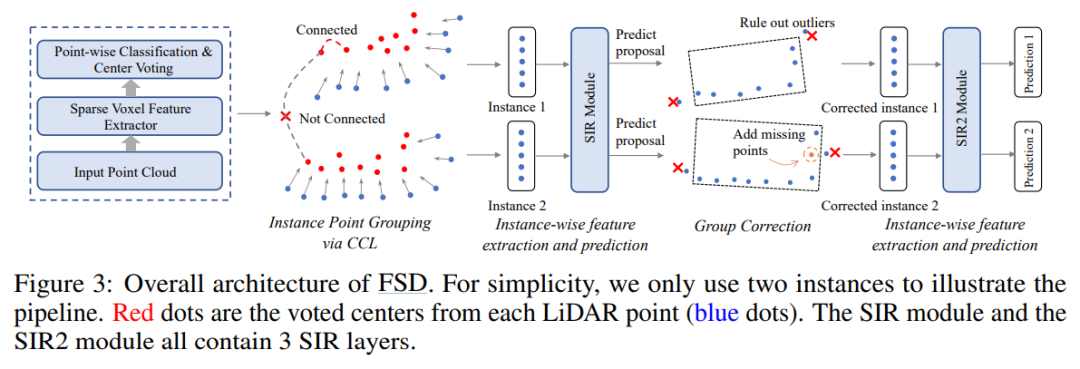
Overall Pipeline
这其中还包含着一些后续操作,比如对重新分割出比聚类得到的更准确的instance,感兴趣的读者可以查看原文。
三、结果
提出的方法在Waymo的单帧单模型标准赛道上达到了SOTA的性能
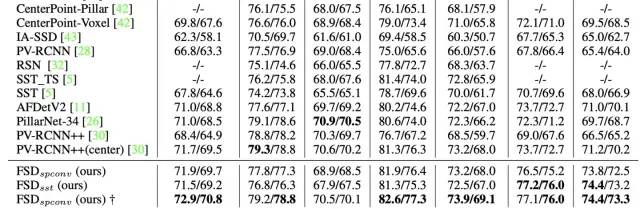
Waymo validation 上的性能,截图不全,感兴趣的读者可查看原论文
同时也在新出的Argoverse 2数据集上超越了主流的CenterPoint(虽然还没几个人刷。。)。
值得多提一嘴的是我们的方法在长距离检测上有巨大的效率优势,如下图所示
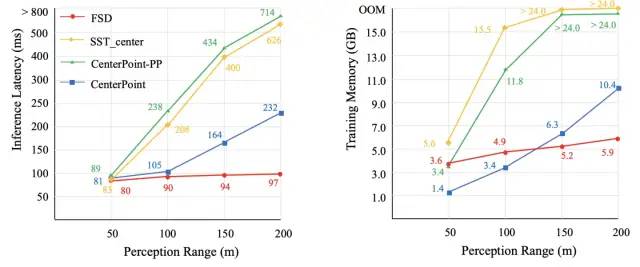
这是用SST backbone测的,用SparseConv的backbone效果更佳
四、一些特性
我们的方法不受sparse backbone的类型限制,比如文中我们就使用了sparse transformer和sparse conv两种结构。这一点使得FSD可以作为sparse backbone方面研究的一个strong baseline。
该方法虽然暂时聚焦在检测任务,但已经有了multi task的影子,可以把segmentation和detection一体化。
前向速度很快,再加上收敛也极快,Waymo上训练6个epoch就可以达到准sota水平。这在8 x 3090上只需要不到半天时间,其他方法达到相同性能可能需要至少2天的训练时间。这应该会给大家的快速实验迭代提供很大便利。
我们相信稀疏化是将来的一个趋势。在很多场景下,sparse feature都比相比笨重的dense feature map具有更高的可操作性和灵活性,欢迎大家试用我们的模型。
审核编辑 :李倩
-
检测器
+关注
关注
1文章
866浏览量
47722 -
激光雷达
+关注
关注
968文章
3989浏览量
190075
原文标题:NeurIPS 2022 | 中科院&图森未来提出FSD:全稀疏的3D目标检测器
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
全场景适用!TS Spectrum高速数字化仪在激光雷达系统中的应用

激光雷达技术或可助力防御无人机

激光雷达在SLAM算法中的应用综述
产品介绍 满足功能安全认证要求:SIL 2安全防护型激光雷达GS1-5
激光雷达技术的基于深度学习的进步
激光雷达技术的发展趋势
TS高速数字化仪在激光雷达系统中的应用

lidar激光雷达扫描仪有什么用
晶振在激光雷达系统中的作用有哪些
Hokuyo Automatic发布新款3D激光雷达(LiDAR)传感器YLM-10LX
机载单光子激光雷达系统用于实现高分辨率3D成像
LG Innotek发布高性能激光雷达,可检测250米外物体
大陆集团的3D Flash激光雷达有何优势?

激光雷达LIDAR基本工作原理






 工商网监
工商网监
评论