 如何通过在CI/CD中实现断路器来防止内部级联故障的发生呢
如何通过在CI/CD中实现断路器来防止内部级联故障的发生呢
译者按:本文介绍了Slack公司如何通过在CI/CD中实现编排级的断路器(orchestration-level circuit breakers)来提高开发人员的生产力并防止内部级联故障的发生。断路器:类似于电路的保险丝,可以将需要保护的远程服务用“断路器” 封装起来,在内部监听失败次数, 一旦失败次数达到某阀值后,所有后续对该服务的调用被断路器截获,并直接返回错误到调用方,而不会继续调用已经出问题的服务, 从而达到保护调用方的目的, 整个系统也就不会出现因为超时而产生的瀑布式连锁反应。
当一个分布式的服务系统面对海量内部请求的挑战时,会发生什么情况?如何防止内部服务之间的级联故障?当我们对系统进行简单的水平扩展或垂直扩展并分别达到极限时,应该如何重新构建开发的工作流(workflow)? 回到2020年,以上这些都是Slack公司的工程师们在开发工作流中经常面临的挑战。
工程师们使用的多个内部服务被拉伸到了极限,导致服务之间出现级联故障。级联故障是正反馈回路,如果系统的某个部分规模化地出现故障,就会导致相邻系统的请求排队,从而导致该系统规模化地出现故障。几年以来,由于两个因素,我们的内部工具和服务团队很难应对每月10%的CI/CD请求增长:第一,内部人员数量的增长;第二,服务和测试的复杂性。当故障发生时,整个开发团队的开发速度会变得缓慢,内部工具开发工程师和基础设施工程师不得不想办法尽快恢复服务。为了实现这个目标,这些工程师们一般采用以下方式:
将Github Enterprise等设备扩展到AWS中可提供的最大硬件容量(限制了未来的垂直扩展)。
使用更多的节点来扩展一项服务以应对新的峰值负载(但却发现这会导致基础设施中另一项服务的失败)。
当然,这些解决方案只能在我们的内部服务达到一个新的峰值负载之前发挥作用。我们需要一种新的方式来思考这个问题。
本文介绍了Slack的工程师如何通过在内部工具中实施编排级的断路器机制帮助开发人员提高生产力。Checkpoint是一个CI/CD的编排服务。开发者生产力团队中的工程师们采用了断路器让Checkpoint中的请求被推迟或放弃。
CI/CD编排和Webapp中复杂性和规模化带来的挑战
回到2020年,我们看到两类相互关联的问题:规模化和复杂性。工程师们建立并采用了持续集成流水线(CI)进行开发,使用了持续交付流水线(CD)将Slack系统部署和发布到生产环境中。Checkpoint是我们的内部平台,用于调度代码的构建、测试、部署和发布。随着时间的推移,Slack的开发人员和功能发布的数量都不断增加,这也转化为CI/CD的额外负载。随着更多功能的发布,工程师们还编写了自动化测试脚本以支持新功能的测试。
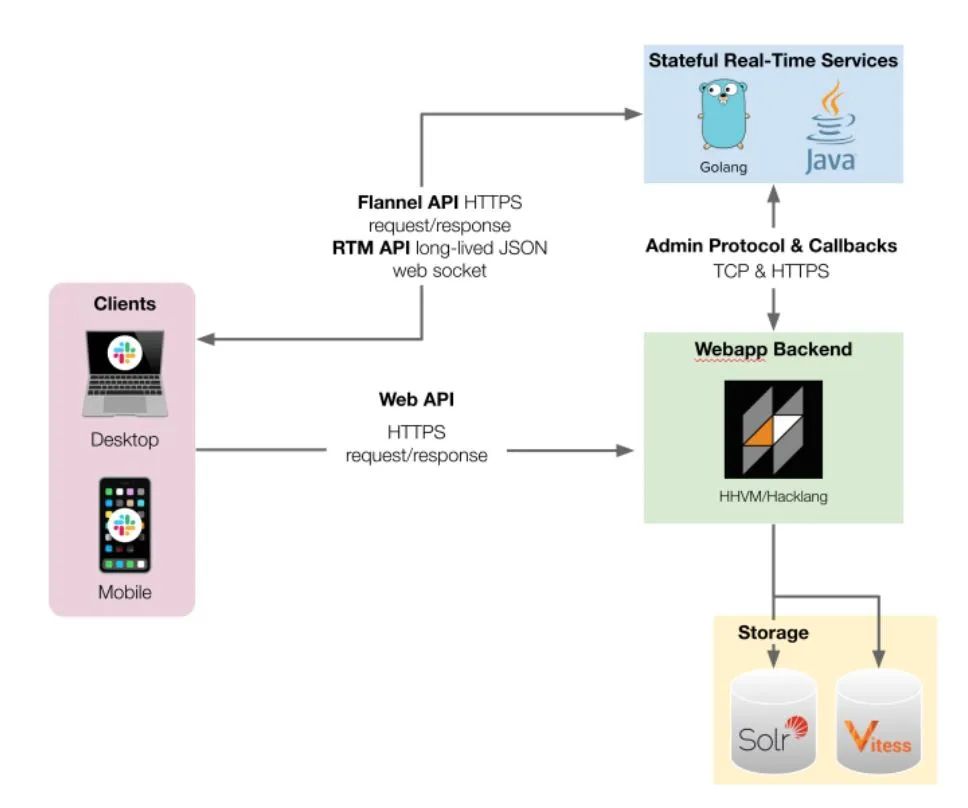
图1 Slack Webapp架构图。客户端连接到三个不同的API,以便实时有效地呈现用户看到的内容
开发人员数量和功能发布数量这两个增长矢量导致了定期发生的新的负载高峰,也会导致个别服务出现新的故障模式,然后发生级联故障(内部服务之间)和事故。每个服务都以不同的速度在演进,不一定能通过水平或垂直扩展轻松适应新的峰值(下面的例子)。
当故障发生时,工程师们被召集起来处理大规模的内部事故,解决这些级联故障。尽管这些事故没有影响到Slack的客户,但仍然占用了工程师们的工作时间,而且往往涉及多个团队并持续多天。在事故发生时,Slack的开发人员需要忍受持续集成流水线中测试执行的速度下降甚至是停止,以及持续交付流水线的可用性受到限制等问题。
CI测试/CD工作流会出现Git错误,当每天的峰值测试数量超过了Git应用程序可以提供的服务,就导致Checkpoint(异步作业处理)中用于调度测试的任务增加,让Checkpoint和Jenkins中执行测试的队列变长。工程师们在测试受限的情况下继续进行开发,让任务队列变得越来越长。
Git是CI流水线和开发者工具的基础工具。Git的规模化问题在建立抽象(如谷歌的Piper)或替代源控制(如Facebook的Mercurial)的大型组织中被充分的记录下来。2019年,Slack内部工具采用Git LFS来处理大文件。在这段时间里,Git设备一直在垂直方向上扩展。Git中大型 repo的增长对开发人员一直是一个挑战,可以通过定制的源码控制系统(如Piper或Github的monorepo维护)来解决。
Checkpoint有一个内部异步任务队列(使用自我托管的main-main MySQL,现在使用的是AWS的RDS Aurora),以保持CI/CD编排的状态。这个任务队列和调度器会重试失败的请求。调度器限制了并发任务,以减少负载和数据库上的失败请求。当一个队列中有太多的任务(如测试请求任务)时,这种有限的并发性造成滞后,导致CI/CD的用户重复请求同一个任务,从而引发正反馈循环和更长的队列。
在过去,为了应对开发人员数量的持续增长,Slack公司的内部工具工程师需要定期增加测试执行器(test executor)和测试环境的数量。如果没有注意负载极限,来自测试(即测试执行器)和Slack环境(即待测试代码)的大规模请求,会导致更多的请求超过CI中的搜索集群可以处理的上限,从而引入错误,当然,更多的是增加了对CI/CD流水线的负载。
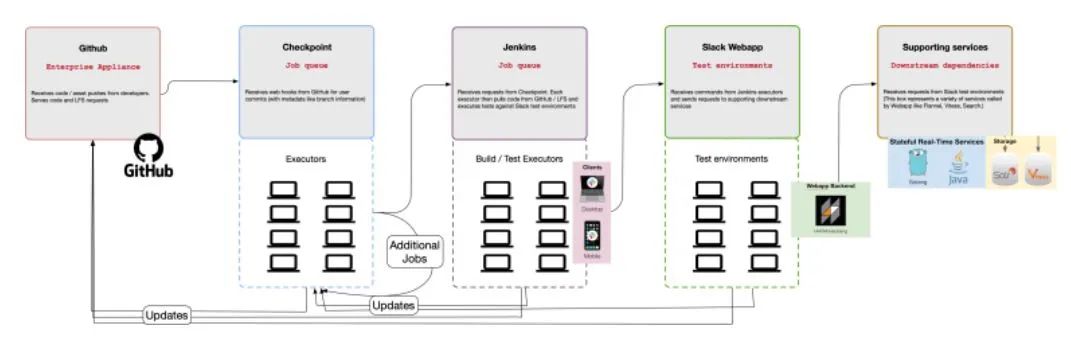
图2CI服务和工具之间级联故障的工作流程实例
为什么复杂性很重要
在Slack公司中,我们通过集成测试和端到端的测试来验证多个服务重叠的复杂工作流的正确性。虽然在开始时公司只有一个服务(Webapp),但目前已经发展成多个支持用户体验的服务。Slack客户端连接到三个不同的API,向用户实时呈现内容(见图1中简化的架构图)。Slack公司的Webapp是一个复杂的应用程序,包括许多配置(如团队、企业和跨企业信息)。为了测试复杂的代码路径,产品和测试工程师专注于编写自动化测试,这依赖于大量的移动部件(见图2)。
断路器
软件断路器是一个从系统工程中借用的概念,它用来检测外部系统的故障并中断对已知故障系统的调用。客户端是采用断路器的典型位置。由于我们的CI/CD编排层调节了请求在系统中的流动,因此,在将请求发送给下一个系统之前,我们在编排器消费者服务中实现了具有断路器功能的客户端,同时有多个并发的任务调用客户端。
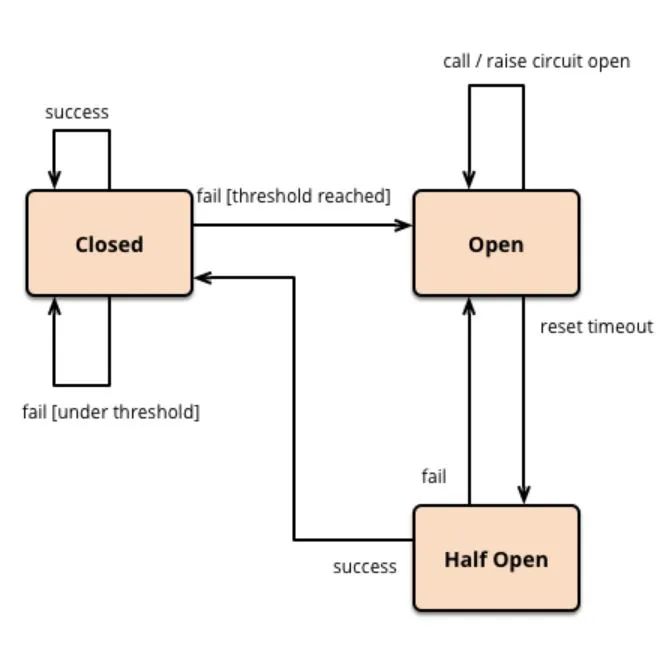
图3断路器控制流程图
我们有一个假设,即断路器可以最大限度地减少级联故障,并提高多个服务的程序化度量查询的利用率,而不是基于单个客户端或服务的方法。与单个服务中的传统断路器不同,编排级系统的断路器可以调节系统间的请求接口。
当系统所依赖的服务遇到负载增加的情况或由于负载增加而显示错误时,断路器就会打开。Checkpoint以编程方式从多个依赖服务中检索健康指标。如果下游系统不能为这些请求提供服务,那么请求将被推迟或放弃。当依赖服务显示恢复时,断路器将关闭,这些被推迟的请求将再次开始执行。这种对已知故障请求的管理减少了影响构建、测试、部署和发布代码能力的级联故障事件,并减少了CI中的故障执行。
实现方法
让我们从一个用Hacklang实现的抽象类开始,以此为基础进行讨论,并为这个新的工作流创建原型。这里我们讨论的重点不是构建或测试客户端,而是Checkpoint,即编排服务,Checkpoint负责协调CI/CD工作流,其后台工作系统代表了Slack的构建、测试、部署和发布的命脉。
Checkpoint有一个API端点,当一个新的commit被创建时,API端点可以接收GitHub的webhook。从这个commit中,Checkpoint会排入多个后台任务,触发Jenkins构建或测试,然后更新数据库中的测试结果。
我们选择在Checkpoint后台任务中关注带有延迟和减载的断路。虽然断路器可以存在于客户端逻辑中(例如,等待恢复或阻止工作),但Checkpoint的后台任务系统提供了一个独特的机会,因为它是多个系统之间的调度程序的中介。
我们使用Trickster在几个使用PromQL的Prometheus集群中对依赖性服务指标进行编程式查询。这个服务是对多个Prometheus群进行查询的前端、代理和缓存。
由于内部后台任务重试和使用延迟的CI请求,Checkpoint不需要半开放状态(half-open state)。半开放状态对于单独的客户端请求和提示这些客户端的恢复非常重要。但由于Checkpoint的后台任务系统提供重试功能,而且这个断路器包含了Prometheus查询的TTL,一旦一个开放的断路器恢复,Checkpoint就会随时恢复工作。
namespace CheckpointCircuitBreaker; use type SlackCheckpointPromClient; /* * Generic interface for Circuit Breakers in Checkpoint. * Downstream actions include deferral mechanisms or load shedding. * @see https://martinfowler.com/bliki/CircuitBreaker.html */ enum CircuitBreakerState: string { CLOSED = 'closed'; OPEN = 'open'; } abstract class CircuitBreaker { /** * Get the state of this circuit breaker. Note the return value is intentionally * not a `Result图4CircuitBreaker类的简化代码`. In the case of internal errors, this must * decide if the breaker fails open/closed. */ abstract protected function getState(): CircuitBreakerState; /** * Allow for bypassing a circuit breaker. Used as a circuit breaker for circuit breakers. * In a subsequent class, add the following to always allow the request to pass through * <<__Override, __Memoize>> * public function bypass(): bool { return true; } */ public function bypass(): bool { return false; } public function allowRequest(): bool { $state = $this->getState(); PromClient::circuit_breaker_requests()->inc(1, darray[ 'breaker_type' => (string)static::class, 'breaker_state' => (string)$state, ]); if ($this->bypass()) return true; return $state === CircuitBreakerState::CLOSED; } }
在第一个代码实现的sprint中,我们实现了编排服务健康的断路器。
当Checkpoint和Jenkins队列达到一定阈值时,推迟测试任务。
当所有Slack测试环境都很忙时,推迟端到端的测试任务。
为分支上的较早的commit消减测试执行的负载。
对于任何有持续失败的套件,消减测试重试的负载。
在第二个sprint中,我们实现了共享依赖服务的断路器。
Flannel :在全球多个地区的边缘缓存,返回经常获取的团队范围的数据。
Vitess:所有客户数据的真实来源(采用MySQL语法)。Vitess是一个数据库解决方案,用于部署、扩展和管理大型数据库实例集群。
搜索:提供信息、文件和人的索引的服务,计算实时集合(通过工作队列实时提供)和每周集合(用从时间开始的信息进行离线计算)。
Flannel的简化实现代码如图5所示,包括:缓存中的查询(连同TTL),Prometheus范围查询,用户信息传递,以及使用Prometheus范围查询对Trickster的调用。安全性在这里很重要,如果Trickster/Prometheus集群返回一个错误,我们让断路器保持关闭,允许请求流过。同样地,我们为异步任务之间一致的客户请求缓存响应。
namespace CheckpointCIBotCircuitBreaker;
use namespace Checkpoint{CIIssue, Trickster};
use type CheckpointCIBotDelta{DeltaAnomalyType, DeltaDimensionType};
use type CheckpointCIIssueServiceDepCircuitBreakerType;
use type CheckpointCircuitBreaker{Cacheable, CircuitBreaker, CircuitBreakerState};
use type SlackCheckpointPromClient;
type flannel_callback_error_rate_cache_t = shape(
'ts' => int,
'error_rate' => int,
);
final class FlannelServiceDepCircuitBreaker extends CircuitBreaker {
use Cacheable;
const int TTL = 60; // Time-to-Live for cached value
const int FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD = 5;
const string PROM_FLANNEL_CLUSTER = 'flannel';
const string PROM_FLANNEL_QUERY_GLOBAL = 'sum(dcirate1m{error!~"org_login_required"})';
const string ISSUE_MESSAGE_OPEN = ' Flannel Circuit Breaker is open. Tests are deferred';
const string ISSUE_MESSAGE_CLOSE = 'This circuit breaker is closed. Tests are starting again';
const string ISSUE_KEY = ServiceDepCircuitBreakerType::FLANNEL;
public function __construct(private ?github_repos_t $repo = null, private ?TSlackjsonValidatorPropertiesCheckpointPropertiesTestsItems $test = null) {}
<<__Override, __Memoize>>
public function getState(): CircuitBreakerState {
$cached_key = $this->getCacheKey(self::class, 'flannel_callback_errors');
$cached_data = cache_get($cached_key);
$existing_error_rate = 0;
// If the cache exists, and is fresh enough, use it. Default to Closed
$result = type_assert_type($cached_data, flannel_callback_error_rate_cache_t::class);
if ($result->is_error()) { return CircuitBreakerState::CLOSED; }
$data = $result->get();
$existing_error_rate = $data['error_rate'];
if ($this->isValidCache($data['ts'], static::TTL)) {
if ($existing_error_rate < static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
return CircuitBreakerState::CLOSED;
} else {
return CircuitBreakerState::OPEN;
}
}
// Lets fetch the current error rate (and compare against the former one)
$result = $this->getFlannelCallbackErrorRate();
if ($result->is_error()) {
return CircuitBreakerState::CLOSED;
}
$error_rate = $result->get();
$cached_value = shape('ts' => time(), 'error_rate' => $error_rate);
cache_set($cached_key, $cached_value);
if ($error_rate >= static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
PromClient::cibot_service_dependency_error_rate_above_threshold()->inc(1, darray[
'breaker_type' => (string)static::class,
]);
if ($existing_error_rate < static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
CIIssuesend(static::ISSUE_MESSAGE_OPEN, DeltaDimensionType::CIRCUIT_BREAKER, DeltaAnomalyType::CIRCUIT_BREAKER_OPEN, static::ISSUE_KEY);
}
return CircuitBreakerState::OPEN;
}
// If our circuit breaker was previously open (and now closed), track this new state and mark it in our issues dataset
if ($existing_error_rate >= static::FLANNEL_CALLBACK_ERROR_RATE_THRESHOLD) {
CIIssueend(static::ISSUE_MESSAGE_CLOSE, DeltaDimensionType::CIRCUIT_BREAKER, DeltaAnomalyType::CIRCUIT_BREAKER_OPEN, static::ISSUE_KEY);
}
return CircuitBreakerState::CLOSED;
}
图5 FlannelServiceDepCircuitBreaker类的简化代码
用户交互
每一个断路器中都会获取数据,并在通道检测到问题时发出警报。断路器打开后将从不同的角度呈现故障。一个典型的工作流程是:我们团队的成员注意到断路器打开,然后向对应的团队通道汇报详细信息。
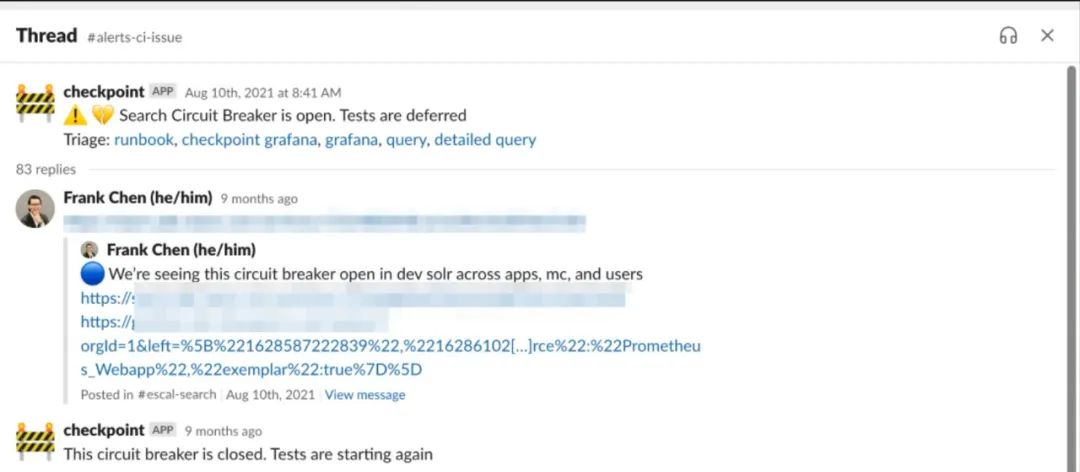
图6. #alerts-ci-issue中的自动断路器信息的截图,导致错误率激增而将问题报告给搜索团队
在自动断路信息中,每个环节都会显示对同一问题的不同看法。类似的递延信息也会显示在Checkpoint的客户端,如图7所示:

图7自动断路器信息截图:Checkpoint的PR/测试视图中显示服务问题和测试状态("Jenkins队列目前很高,队列下降后测试将继续")
我们之前提到,Checkpoint对不同的服务错误率进行查询,我们创建了一个小型的内部问题库向Slack报告处于打开状态的断路器。评估这些特定的问题(而不是看到无差别的错误峰值)逐步提高了我们对断路器的推断能力。此外,我们扩展了这个问题库,以便在测试执行器、测试环境和测试集中进行异常检测(例如,高于预期的失败、错误率、持续时间或失误率)。这些反过来又为开发人员提供了更流畅的体验。
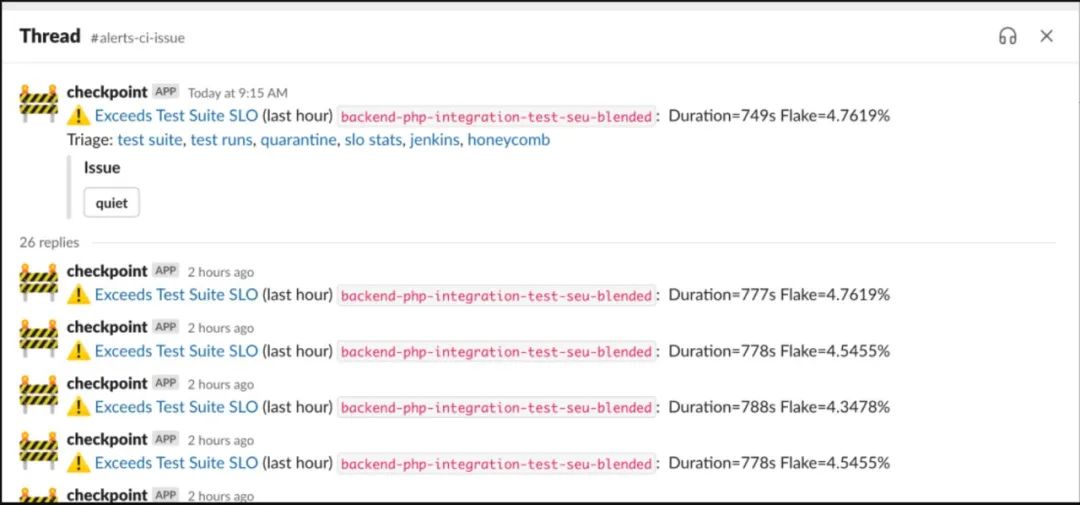
图8 测试集执行异常检测的屏幕截图
对开发者的影响
自从引入两套基础设施和依赖性服务断路器以来,我们已经通过延迟测试任务减少了级联故障的面积,并通过负载消减让测试执行的吞吐量变得平滑。
带来的结果是大大改善了开发人员的体验。在过去的两年里,内部工具的级联故障事件为零,并且,关键服务的负载大大降低,这有利于提升CI/CD的用户体验。
而这些事故在2020年之前是很常见的。我们定期对CI编排中的依赖服务负载进行编程式查询来遇到新的峰值负载。在最近的Git LFS事件中,虽然症状与早期的事故相似,但情况会被定位到测试执行器,团队能够修复和隔离故障,而不会出现级联故障。
现在,当工程师的测试被推迟到系统恢复时,他们会从Checkpoint的客户端得到反馈。在使用断路器之前,这些测试会因为下游系统的过载而出现故障。推迟测试总体上降低了自动化测试的不稳定性,同时也降低了多个测试执行任务之间的相关性。
图9显示了测试请求的巨大变化,这些测试请求与最初commit测试请求的工程师不再相关(例如,更新的提交),这些测试请求需要多次重复测试来解决不稳定性。注意每个断路器实现期(2020年3月和2020年8月)后的两条曲线变化。
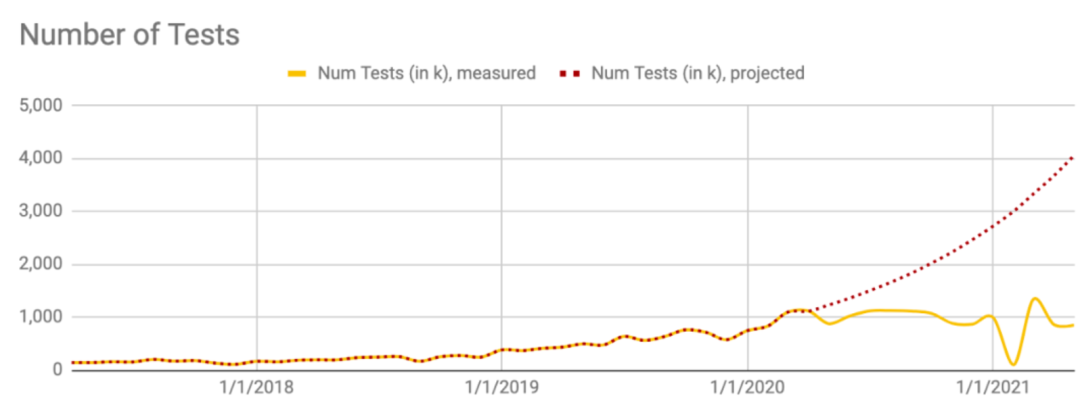
图9基于10%增长的已执行测试集的预测(红色),以及消减负载并延迟任务后的曲线变化(黄色)
最后,为了了解测试的反馈回路,使用CI流水线的团队已经统一了一个业务指标 "测试结果获取时间"(time to test results)。这个指标考察的是开发人员从CI中执行的构建和测试任务中获得结果所需要的实际。团队成员担心的是,添加断路器以推迟或减轻负载与快速获得持续集成结果是背道而驰的。在过去的几年里,这个指标并没有向错误的方向发展(更慢),而是一直很稳定,因为许多相同的测试都会失败,然后向用户显示的是测试不稳定的结果。
结语
本文分享了Slack公司的内部CI/CD编排系统Checkpoint的编排级断路器的决策要点和结果。
在这个项目之前,Slack的工程师们看到了挑战,因为内部工具的请求达到了新的峰值,当一个系统出现故障,就可能将故障级联到其他系统。断路器位于CI流水线中的各系统之间的接口,可以最大限度地减少级联故障。
自从该项目在2020年完成后,工程师们在使用内部工具链时不再遇到系统间的级联故障。工程师们还看到了服务可用性的提高,Checkpoint的整体吞吐量的提升,以及更少的不良开发者体验,如失败的服务带来的测试不稳定。断路器的实现对整个Slack的工程师的生产力产生了实质性影响。
现在,多个团队正在尝试使用这个程序化指标查询框架,通过自动构建、测试、部署、发布和回滚,帮助Slack实现持续部署。
审核编辑:刘清
-
断路器
+关注
关注
23文章
1952浏览量
51834 -
MYSQL数据库
+关注
关注
0文章
96浏览量
9402 -
API串口
+关注
关注
0文章
13浏览量
4848
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论