 Shopee视频技术落地产品
Shopee视频技术落地产品
东南亚各市场的网络环境复杂多变、差异极大,如何在有限网络条件下提供稳定、高清的视频体验是我们面临的一大挑战。基于此,本次分享将介绍 Shopee 在东南亚视频业务落地上的方案,在画质提升上做出的努力,以及一些性能提升成本控制方面的优化。
在 8 月 6 日举办的 LiveVideoStackCon 2022 上海站大会中,Shopee 视频技术团队负责人 Zhixing 分享了 Shopee 视频处理技术的后台应用,本文根据演讲内容整理而成。
1. 背景
随着 Shopee 电商业务在东南亚等市场展开,视频和电商结合的应用迅速落地。然而,当地许多用户使用的手机配置有限,这些手机在视频编解码、图像处理方面存在不小的性能瓶颈。
并且,当地网络基础设施建设还不太完善,在这样的网络条件下,如何稳定且高质量地传输媒体数据成为一大挑战。
另外,海量的视频文件和直播视频处理也给 Shopee 后台带来了巨大的压力。那么 Shopee 是如何通过技术手段来解决这一系列问题的呢?
本次分享的内容大致分为四个部分:第一部分是 Shopee 视频相关的产品介绍;第二部分是 Shopee 视频业务后台的技术方案;第三部分是 Shopee 高清低码转码技术,以及 RTC 场景视频编码技术;第四部分是我们在性能提升和节省算力成本上做的一些优化。
2. Shopee 视频技术落地产品
先来看看 Shopee 有哪些与视频相关的产品。
作为电商平台,Shopee App 是我们的主要业务,涵盖了 feeds 流、直播带货、点播等视频类服务。其中,短视频服务 Shopee Video 目前也已经在东南亚个别市场上线。
Shopee 的数字银行业务 SeaBank 在部分场景下也用到了视频服务,例如在线开户环节。用户发起开户请求,客服接听,通过视频画面在线认证身份信息。
此外,公司内部的通讯工具 SeaTalk 也计划在语音通信功能的基础上,新增视频会议能力。
3. Shopee 视频相关后台服务
针对上述应用,我们开发了哪些视频相关的后台服务呢?
3.1 直播/点播转码
首先是 Shopee App 的转码服务,涉及点播和直播转码两个转码平台。有一些 AI 增强类的前置处理,一帧耗时比较长,对于点播业务来说,这不是什么问题,只是转码耗时增长。而对于直播业务来说,就需要考虑效率问题了,比如帧率 30,最多一帧只能耗时 33ms,如果串行进行所有前置处理,就会使得出帧帧率小于输入帧率,导致视频帧堆积的问题。
于是,我们设计了流水线的视频处理架构,将耗时较短、不影响主流程的处理节点放在同一个 region 中,串行处理,耗时长的节点单独一个 region,region 与 region 之间并行执行,中间通过队列通信。这样,只需要任意一个处理节点耗时保证在帧 duration 范围内,就能满足业务要求。
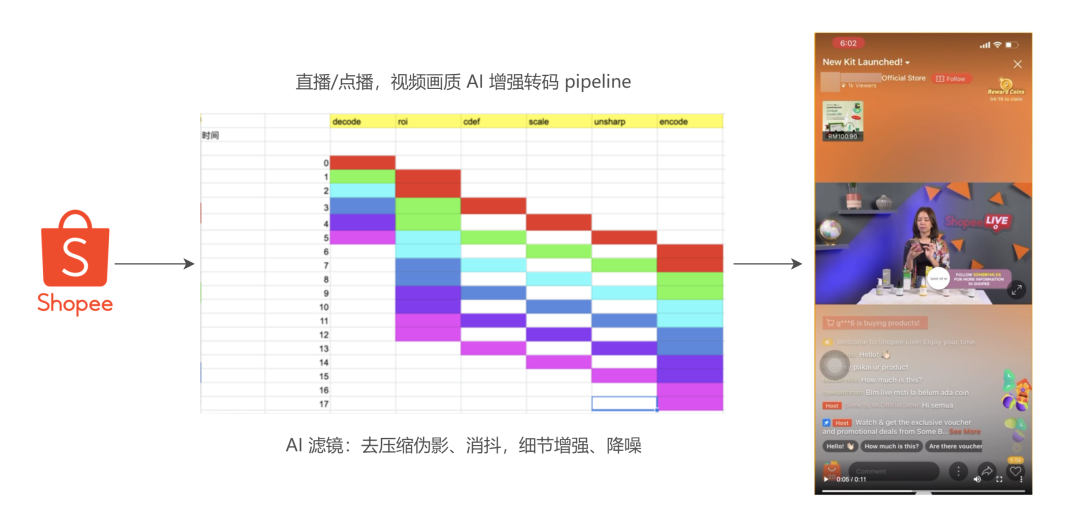
我们可以看到中间这张彩色的示意图,如果是串行处理,每一帧的耗时就等于每一个节点耗时相加。然而流水线处理的话,每一帧的耗时取决于耗时最大的处理节点。
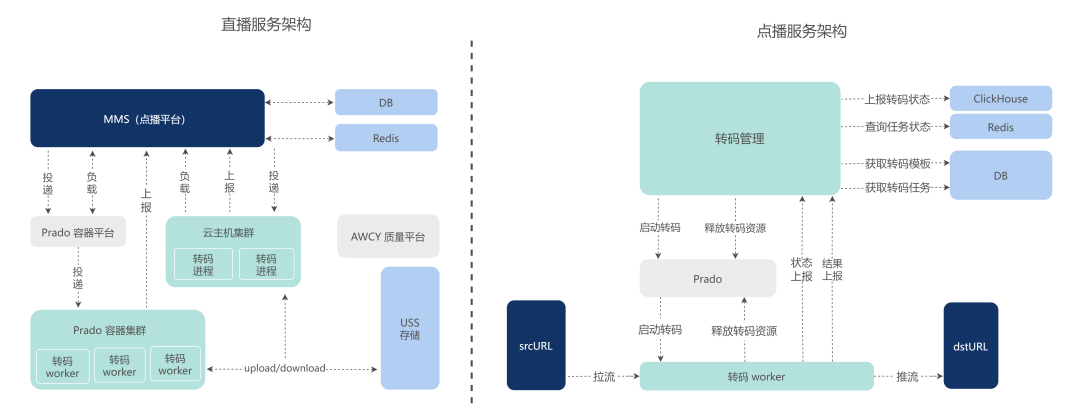
上图为 Shopee 的直播/点播转码服务架构图。点播转码集群分为内部 Prado 容器集群和云主机集群,MMS 点播平台是我们的上游服务,该平台可以根据负载自由调度,选择使用 Prado 转码或是云主机转码。
说个题外话,为什么这里会有两种集群?近两年因为疫情,服务器采购比较困难,于是公司的 SRE 建议我们,这类对数据安全性要求没有特别高的服务可以切到云主机,以加快业务落地。
对于转码后的视频画面质量,我们也有内部的画质数据平台 AWCY,提供编码画质监控能力。
3.2 直播连麦
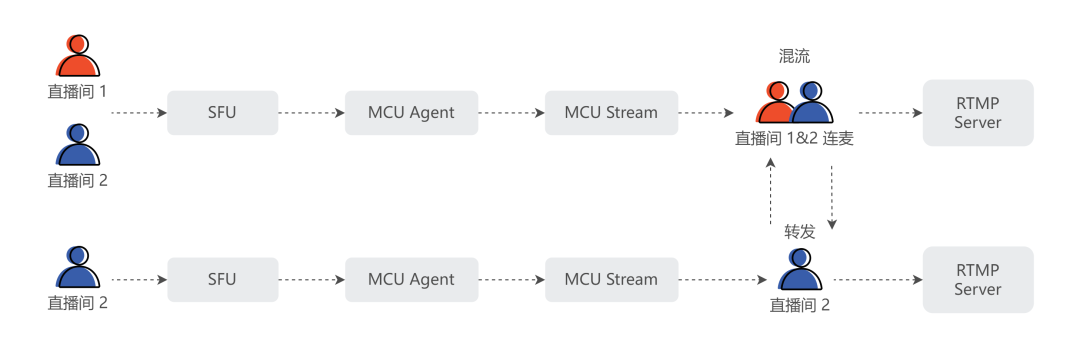
上图是 Shopee App 的直播连麦服务架构。连麦双方通过 RTC-SFU 服务通信,观众通过 HTTP-FLV 观看直播。
这里值得注意的是,通常云厂商为了后台的稳定性,将连麦服务的逻辑简单化了,不管房间是否有连麦主播,都采用转码的方式处理视频流。而既然有转码,就涉及到视频编码环节,若只有一路主播的时候也转码,会浪费大量算力资源。
为了节省计算资源,Shopee 主播视频采用了 H.264 编码。在单个主播的时候,我们采用直接转封装的方式处理主播的视频;当有连麦者接入的时候,采用混流转码的方式处理视频;连麦者离开后,再次返回到转封模式。
而 MCU 后台处理了这种模式之间交替切换的问题,通过缓存 GOP 的方式解决从单主播切换到连麦模式的场景,通过等待新的 GOP 的方式解决从连麦模式切换到单人模式的场景。
线上大部分时候,在房间只有单个主播的场景下,CPU 的平均负载较低,大大提高了集群的并发能力。单台机器如果进行转码,最多支持 20 路主播;如果不进行转码,目前通过压测数据来看,至少支持 200 路主播转发。
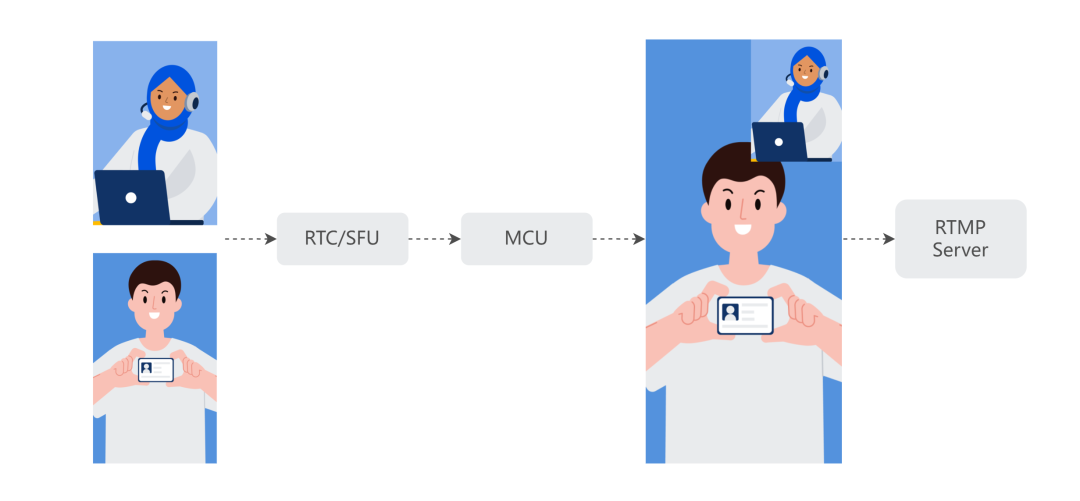
这一套方案也用于 SeaBank 在线开户系统,对开户通话过程进行录制。区别在于 SeaBank 系统只有混流模式。
3.3 多人会议混流
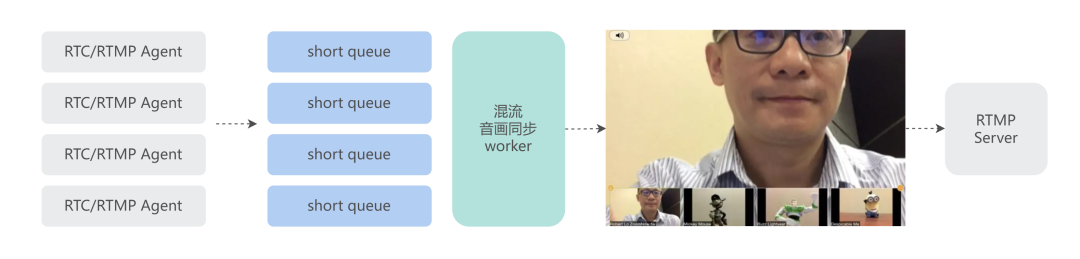
对于 Shopee 内部通讯软件 SeaTalk,我们提供了多人会议混流服务作为技术能力储备(目前该功能还未上线),混流模块中嵌入了开源软件 OWT 和 mediasoupclient 的核心模块,并且在 OWT 模块上增加了 3 帧的缓存队列,以平滑混流视频帧。会议混流系统支持 RTMP 和 WebRTC 接入。
3.4 视频后台编辑
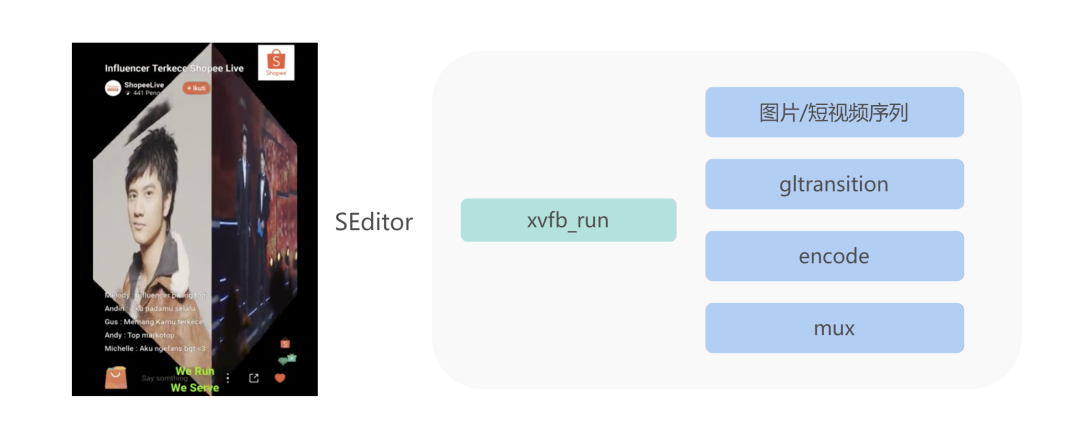
针对 Shopee 的短视频产品 Shopee Video,我们开发了一套后台编辑服务,用于完成一些 2D 特效,例如图片序列转视频、添加背景音乐、画面切割、文字动画、视频转场、背景模糊等。目前通过 CPU 执行 Xvfb 虚拟显存的方式完成 gltransition 的转场效果。
4. 高清低码
随着 Shopee App 中带货直播业务量逐渐增长,提升直播用户画质体验的需求也日益强烈。另一方面,在东南亚的网络条件下,直播分辨率很多还是 360p 或 270p,码率 300-500k。
起初,大部分 Shopee 带货主播流没有转码,为了适配直播观众下行参差不同的网络情况,主播甚至用更低的分辨率和码率开播,来提高观众侧的流畅度,当然这种做法以牺牲清晰度为代价。
在考虑用户观看体验,并综合视频转码成本等多种因素后,Shopee 决定投入自研视频转码业务。与业界常见做法类似,Shopee 的直播转码也分为普通转码和高清低码转码。
普通直播转码集群用 NVIDIA T4 显卡硬编码,来支持更多直播转码。测试数据显示,直播带货场景下,一张 NVIDIA T4 显卡能编码 30 路,相较于 CPU 成本有一定优势。另外一部分是高清低码转码,使用 CPU 转码,编码器是基于 x264 优化后的版本。

上图是 Shopee 直播高清低码和云厂商高清低码的画质对比,左边可以看出来 Shopee 转码画质明显优于云厂商 A,和右边的云厂商 B 相比,在块效应的处理上也有细微优势。那么 Shopee 的高清低码转码是如何做到的呢?
4.1 视频处理的一般流程
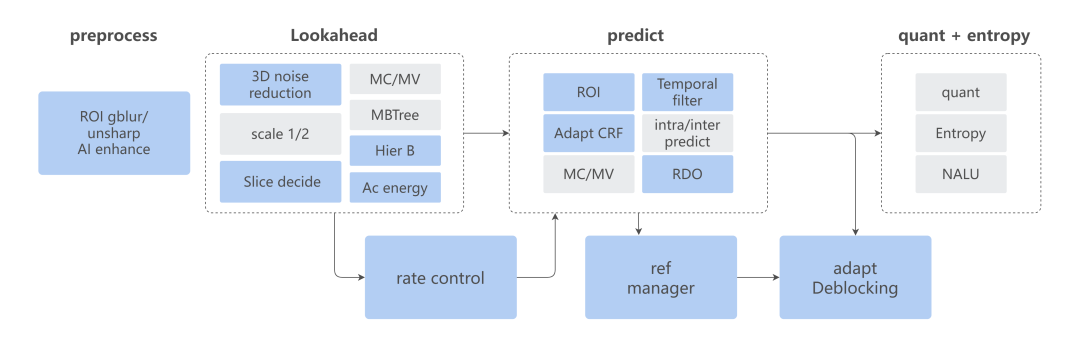
先来大概了解一下视频转码需要经过哪些环节:
第一步解码得到 YUV 画面数据;
然后经过前置处理,包含了 ROI 背景 gblur 滤波、锐化、AI 增强;
接着将 YUV 数据送进编码器,进入预编码环节,主要步骤是下采样、Scenecut 关键帧判断,帧类型决策、AC 能量值计算、MBTree 等;
下一步进入编码环节,包括帧内/帧间预测编码、RDO、Deblocking、参考帧管理等步骤;
最后就是进入量化和熵编码环节,最终输出 NALU 单元。
上面步骤中蓝色部分是 Shopee 在 x264 基础上做过优化的节点,接下来会一一讲解。
4.2 Shopee 高清低码优化方案
4.2.1 前置处理
1)CDEF 算法

在前置处理时,参考 AV1 中实现的 CDEF 算法,抽出来作为一个 FFmpeg 滤镜,该算法主要用于解决由于过度压缩导致的物体边缘振铃效应。通过该滤波算法之后,画面中的物体边缘会更加平滑。
CDEF 大致可以理解为首先计算当前 8x8 的块在预设的八个方向块上的残差,选择残差最小的作为确定的角度方向,然后找到对应的角度方向矩阵进行滤波。图中最右边是滤波后的效果,可以看到树枝的边缘更加平滑了。
2)3D 降噪

常见的传统降噪算法 FFmpeg 中也有一些滤镜实现,比如 hqdn3d、bm3d 等。hqdn3d 参考的点较少,运动剧烈时效果不佳。bm3d 需要额外计算运动向量,速度极慢。
我们在编码器内置的 3D 降噪算法通过复用运动向量的方法规避了效果差和速度慢的缺点。利用前后帧的预测信息,在预编码中得到的运动向量作为依据,找到被参考帧对应的块,作为滤波的参考块,然后通过双边滤波算法,对当前块进行滤波。
这样一来,因为复用了运动向量,从而能够较好地对当前的块进行降噪滤波,也减少了计算复杂度。我们在 x265 也实现了同样的算法。
4.2.2 分类参数

常见的分类编码参数往往通过人为主观分类,例如游戏、UGC 视频、影视剧等。而考虑到主观分类对于编码器提高 BD-rate 不一定是最佳的,Shopee 采用了一种逆向的思维方法,先抽出来几个不增加编码复杂度,主要影响画质的参数:B 帧个数、B 帧决策算法、B-pyramid、B 帧层次结构、QComp 等。
首先将这些参数分成性价比最高的八组(当然这八组是通过我们线上的视频跑出来的结论),然后分别得出图中几组参数的最佳 SSIM BD-rate 收益——这里的收益是相对于我们线上统一的编码参数而言,把最佳 BD-rate 视频,相同参数的作为一组,然后针对这一组视频提取特征,进行训练,使用训练完的模型对线上视频进行分类。
手动参数分类测试 BD-rate 收益最大 2.6%,模型分类 BD-rate 提升取决于模型分类的准确性,目前通过模型分类收益 1.4% 左右,模型还在进一步改进中,预期是接近手动分类 BD-rate 收益最大 2.6% 的目标。
4.2.3 编码器优化
1)VBV - Adapt CRF
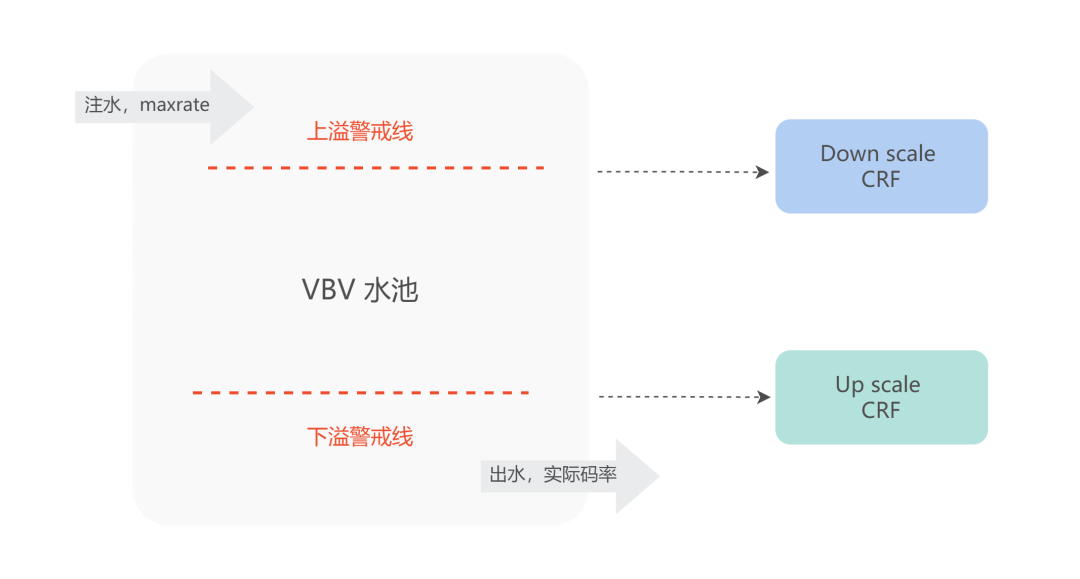
在编码器码控方面,我们也做出了一些优化。如图,这是 VBV + CRF 码控模型示意图,一边注水,注水速度为 maxrate*帧duration;一边放水,放水速度为实际编码码率。
当水位过低时,发生下溢,增大 QP 值,降低编码码率。当水位过高,发生上溢,减小 QP 值,增大编码码率。实际编码档位的 maxrate、bufsize 参数限制了水池的大小,使得复杂视频画面为了达到目标 CRF 画质,经常发生下溢,当码率不足时,大幅度降低了高复杂度画面的画质,比如出现严重块效应。
我们通过动态调整 CRF 值的方式,让平均画质始终处于 VBV 限制范围内。当发生下溢时,增大 CRF 值,降低目标画质;当发生上溢时,减小 CRF 值,提高目标画质,以此达到提升视频平均质量的目的。通过线上大量视频测试,BD-rate 提升了 1.2%。
2)Hierarchy B + 时域滤波
Shopee 编码器对 BD-rate 提升最多的优化是分层 B 帧结构。
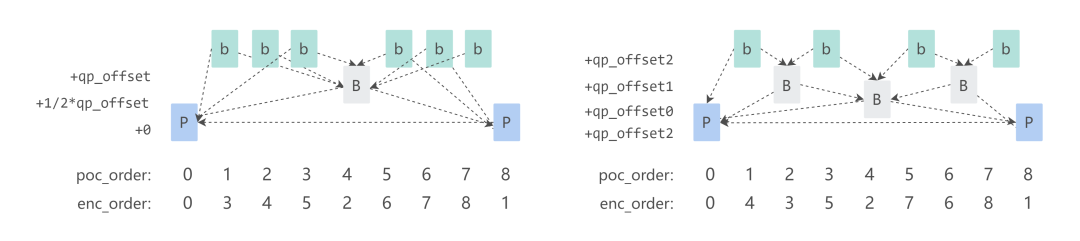
如图所示,左边是社区版本 x264 编码出来的 B 帧结构,右边是优化后的 B 帧结构。由于右边的 B 帧分了更多层,从图上可以很直观地看出来,参考帧和被参考帧的距离更近,参考关系更优。
另外,分层 B 帧使用先确定 miniGOP,然后二分的方式决策参考关系和层次,相较于社区版的 Adapt B 和 Viterbi B 帧决策,速度更快。以下是我们测试的 BD-rate 提升和帧率提升收益。
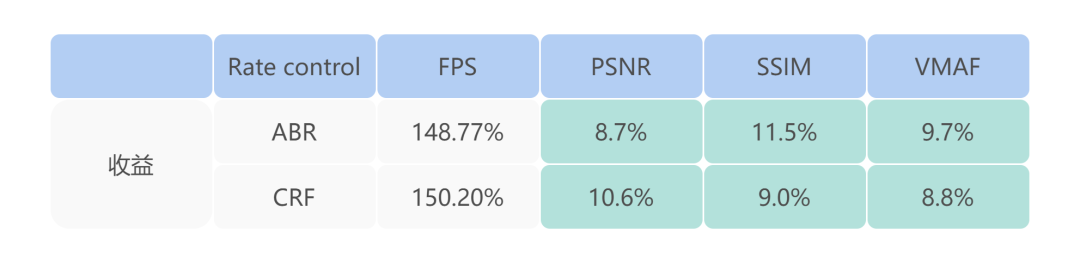
另外,决策完参考关系之后,还可以通过对编码帧进行时域滤波,让编码帧更接近参考帧,减小残差,以提高 BD-rate,收益大概在 2% 左右。
3)ROI(GBlur 背景)
为了适配东南亚的网络质量,Shopee 转码服务提出了一种 ROI 转码档位。以往常见的 ROI 编码,单纯通过增大非 ROI 区域的 QP 值来降低非 ROI 区域的画质,然后把 bits 节省下来,减小 ROI 区域 QP 值来提高画质。
但是这样带来一个问题,非 ROI 区域看起来块效应非常明显,和 ROI 区域有明显割裂感。于是,我们对非 ROI 区域进行高斯模糊滤波之后再 ROI 编码,效果看起来比原来的 ROI 编码好很多。
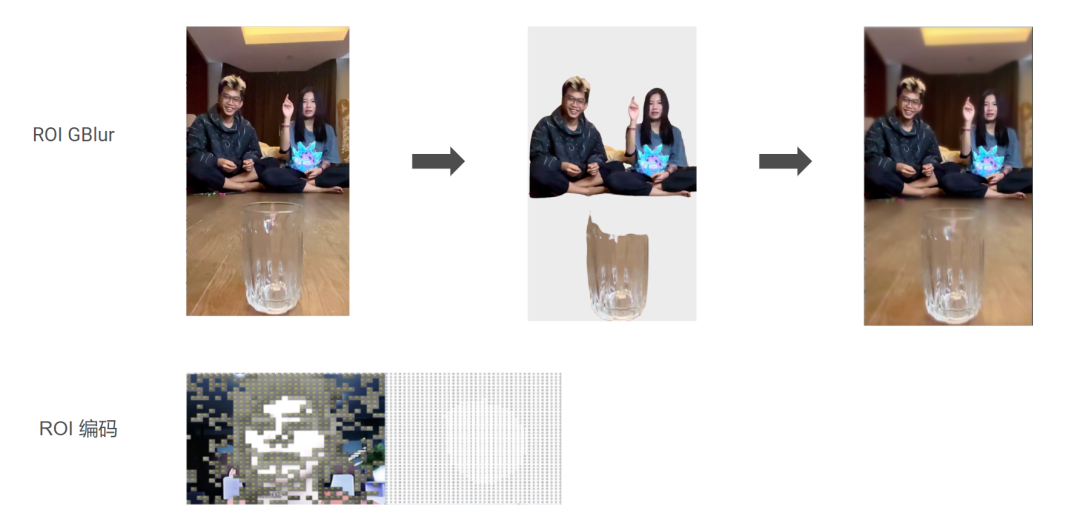
如图所示,左边是原图,中间是扣下来的 ROI 区域,右图是高斯模糊之后 ROI 编码的效果。
4)长期参考帧
为了支持后台视频编辑的服务,我们在编辑服务编码器中增加了长期参考帧。
在剪辑视频的时候,可能会出现一段节目中间要植入广告的场景,如果按照原生的 x264 帧类型决策策略,会发生 scenecut,决策为 IDR 帧,然而我们可以看到,这里中间植入的广告的前后画面很有关联性。

于是我们把发生 scenecut 前额视频帧缓存在编码器参考帧队列中,并标记为长期参考帧,当后面的视频帧出现 scenecut 的时候,再和队列中的长期参考帧 scenecut 决策一次,如果决策结果均为发生 scenecut,则标记为 IDR,反之编码为 P 帧。如此优化后,BD-rate 提升 6% 左右,不过该策略仅适用于视频剪辑的场景。
5)分级 RDO
另外,我们还在 RDO 方面做了一些优化。
RDO 是编码器进行二次编码,把重建块和原画之间的残差作为失真,为了尽量减小失真,对帧内/帧间预测模式、运动向量、QP 值重新决策的过程。它们的决策强度都是依次递增的,意思是如果要打开 QP RD,就一定要开运动向量,模式决策 refine。
/*mbrd==1->RDmodedecision*/ /*mbrd==2->RDrefinementsatdcost*/ /*mbrd==3->QPRD*/
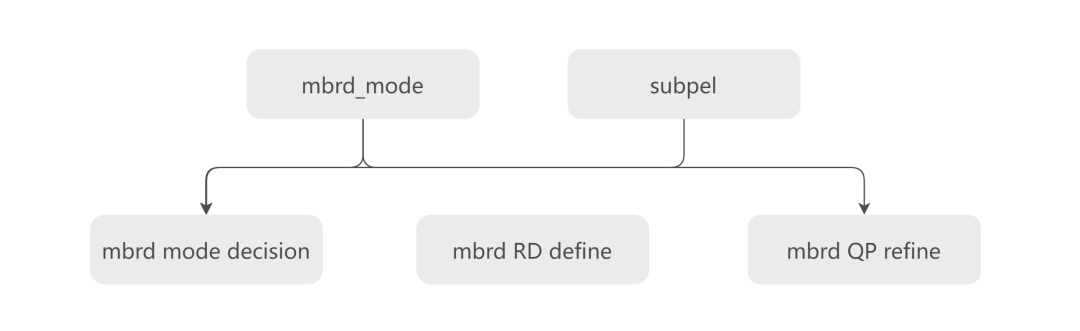
于是我们把 QP RD 单独拿出来,通过新增的参数控制开关,在牺牲了一定速度的条件下,达到了 BD-rate 3% 的收益。
6)时域 SVC
针对 RTC 场景,我们也做了一些编码侧的优化。

RTC 一般是没有 B 帧的,为了解决群组会议用户网络质量参差不齐的问题。我们将 P 帧也进行了分层。层级之间的参考关系如图所示,上层的 P 帧永远参考下层的帧。
这样一来,我们在传输过程中可以任意丢弃上一层的 P 帧,而不影响解码播放。下行带宽不足的时候, 在一个 miniGOP 内部,上层的 P 帧可以根据实际网络情况丢弃,以降低带宽,从而保证视频的流畅性。
5. 性能优化
5.1 编码器端上优化
在线上视频业务中,我们曾遇到过一些问题。有一些配置较低的手机,在光线不是很好的情况下,拍出来的画面无法看清画面中必要的的文字信息。于是我们对手机上采集到的画面进行了锐化,让文字看起来更清晰一些。
然而测试发现,对于东南亚的手机配置,这样的算法发热太严重,即便锐化算法是参考了 FFmpeg 的 USM,已经是通过横纵向状态机复用和多线程优化过的版本,锐化一帧 720p 普遍耗时还是有 15-20ms,而且手机发热严重。
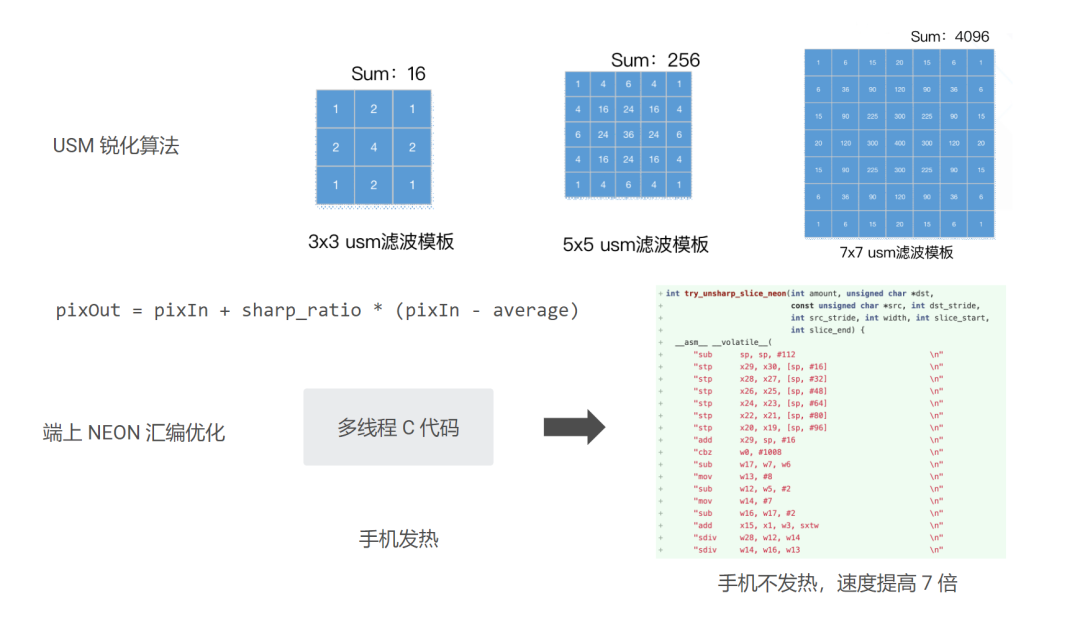
于是我们针对 3x3 的 USM 模版,用 NEON 汇编指令优化了锐化函数,把一些点积、累加运算通过 SIMD 指令并行处理,锐化处理的帧率提高了 7 倍,手机也不再发热。
5.2 一入多出编码
东南亚的机房机器成本同样很高,为了节省服务器机器资源,在点播后台转码服务中,我们也做了一些成本优化。
Shopee App 需要将一个点播视频转码 6 个档位,不同的分辨率和码率。我们通过对一些转码中间数据复用的方式很大程度上降低了转码服务集群的成本,首先我们复用了前置处理,包括 AI 增强,把同一个视频文件转码多个档位的请求调度到同一台主机上,以复用前置处理结果。
其次,我们通过复用编码器 lookahead 帧决策、MBTree 等信息。针对同一个视频文件的转码,我们通常只需要对其中一个档位的视频做帧决策,其他的档位直接复用帧类型信息。在编码环节中复用运动向量,skip 块等信息来减少运算量。
经过测试,有参考信息的转码档位能节省 50% 的运算量。复用的转码档位越多,节省的 CPU 算力也越多。
以上就是本次分享的主要内容。接下来我们还会发布在 x265 编码器上的一些优化,在一些视频业务上支持 H.265 编码能力,进一步提高视频用户体验。
审核编辑 :李倩
-
编码器
+关注
关注
45文章
3647浏览量
134714 -
视频处理
+关注
关注
2文章
98浏览量
18829
原文标题:5. 性能优化
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
成都微光集电发布全新MIS20S1视频产品
德力西电气荣获2024中国房地产产业链战略诚信供应商
NFC支付全面落地,智能物联模组助力金融支付场景再拓展

视频超分技术是指什么?

RISC-V Summit China 2024 | 青稞RISC-V+接口PHY,赋能RISC-V高效落地
从10个地产客户案例里,我们发现智能语音电子工牌在提升案场转化中的价值

数字EDA赋能RISC-V落地演进技术研讨会成功举办







 工商网监
工商网监
评论